
AN OVERVIEW OF THE TYPOLOGY OF THE MORPHOLOGICAL FEATURES OF THE ARABIC LANGUAGE BASED ON WALS DATABASE
Aннотация
К сожалению, текст статьи доступен только на Английском
An overview of the typology of the morphological features of the Arabic Language based on WALS database
Introduction
Several studies have been conducted on the typology of morphology with an an attempt to classify languages using certain features. We reviewed a number of these studies based on The World Atlas of Language Structures Online (hereafter WALS) database (http://wals.info/) and we limited our discussion to the morphological features: fusion and exponence of inflectional formatives, verb inflectional synthesis, locus of marking in the clause, possessive noun phrases and whole-language typology, prefixing vs. Suffixing in inflectional morphology, reduplication, case syncretism, syncretism in verbal person/number marking, and concluding with the characteristics of Arabic among these reviewed morphological features.
Three steps were followed to present the extracted data from WALS database. First, the morphological feature in briefly introduced. Second, the values of the morphological features are presented, the number of representing language for each value and then the percentage of these languages among the total included languages for each morphological feature. Each table is also followed by a line graph displaying the distribution of these languages among the values of each morphological feature.
Fusion of Selected Inflectional Formatives
Bickel and Nichols (2013) emphasise on the varying views resulting from the classical view in regard to the typology of morphology in regard to phonological fusion. Having started in 19th century, it views languages in terms of four aspects as illustrated below in (table 1). Based on this typology, a number of different variables could be further investigated, namely: phonological fusion, formatives exponence and flexivity.
Table 1.
Phonological fusion types based on WALS database

Fusion which has three types refers to ‘the degree to which grammatical markers (called formatives in the following) are phonologically connected to a host word or stem’ (ibid). The following tables show the three types with the characteristics and an example language for each.
Table 2.
Types and characteristics of fusion based on WALS database
Type | Characteristics | Sample language |
Isolating | full-fledged phonological words of their own | |
Concatenative | phonologically bound | Turkish |
Nonlinear:
| not realized by direct modification of their host tense is marked by complete affix-plus-stem pattern most tense-aspect opposition are expressed by tone |
Modern Hebrew |
The authors examined the typology of tense-aspect mood for such languages in terms of the below given values including 165 languages based on two values (tense-like and case-like).
Table 3.
Tense-aspect mood feature based on WALS database
Value | No. | (%) | Sample language(s) |
Exclusively concatenative | 125 | 76% | English, Turkish |
Exclusively isolating | 16 | 10% | Hausa, Indonesian |
Exclusively tonal | 3 | 2% | Kisi, Lango |
Tonal/isolating | 1 | 0% | Yoruba |
Tonal/concatenative | 2 | 1% | Nandi, Swahili |
Ablaut/concatenative | 5 | 3% | Arabic (Egyptian), Hebrew |
Isolating/concatenative | 13 | 8% | Mandarin, Thai |
Total | 165 | 100% |
|
Fig. 1. Distribution of 165 languages for tense-aspect mood feature
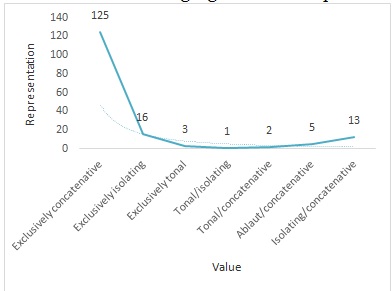
The data indicates that the highest percentages of the included languages lies within the exclusively concatenative value followed by exclusively isolating languages and isolating/ concatenative languages. It could be also noticed that in the last three types: tonal, ablaut, and isolating are features accompanied with concatenative. By this means, concatenative stands as a prominent feature in terms of phonological fusion in the morphological typology of languages.
Exponence of Selected Inflectional Formatives
According to Bickel and Nichols (2013) exponence is a morphological typological feature referring to ‘the number of categories that cumulate into a single formative’ that could be either monoexponential or polyexponential. Both of these types can be linked with any other fusion types. Besides, exponence is totally morphology-based feature. That is, ‘it is independent of the phonological connection between host and formative’.
Using the values (tense-like and aspect-like), the authors examined 162 languages in terms of case exponence. It should be noted that in this part tense-aspect-mode was referred to one category.
Table 4.
Case exponence feature based on WALS database
Value | No. | (%) | Sample language(s) |
Monoexponential case | 71 | 44% | Turkish, Japanese |
Case + number | 8 | 5% | Finish, Russian |
Case + referentiality | 6 | 4% | Tagalog, Paiwan |
Case + TAM (tense-aspect-mood) | 2 | 1% | Lugbara, Kayardild |
No case | 75 | 46% | Arabic (Egyptian), English |
Total | 162 | 100% |
|
Fig. 2. Distribution of 162 languages for case exponence feature
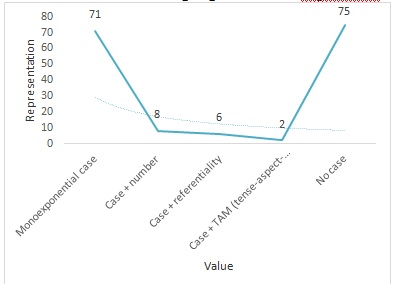
With reference to the above data, it could be seen that the highest percentage of languages is for (no case) followed by (monoexponential case). The percentages of the other values are very low and represent a few languages compared to the two major values: (monoexponential) and (no case).
Table 5.
Tense-aspect-mode (TAM) exponence feature based on WALS database
Value | No. | (%) | Sample language(s) |
monoexponential TAM | 127 | 79% | Turkish, English |
TAM+agreement | 19 | 12% | French, Spanish |
TAM+agreement+diathesis | 4 | 2.5% | Arabic (Egyptian), Hebrew (Modern) |
TAM+agreement+construct | 1 | 1% | Lango |
TAM+polarity | 5 | 3% | Maasai, Koyra |
no TAM | 4 | 2.5% | Sango, Bororo |
Total | 160 | 100% |
|
Fig. 3. Distribution of 160 languages for tense aspect mode exponence feature

This table which represents the tense-aspect-mode (TAM) exponence shows that the major value is that of monoexponential TAM. The difference between this value and the others is highly significant where the highest one among the others is (TAM+agreement) with only 12% and the lowest is (TAM+ agreement_ construct) with only less than 1%.
It could be concluded within this feature that certain values are shared by a certain number of languages that could be linked historically or in terms of family languages―indicating the possibility of historical relationships among such languages.
Inflectional Synthesis of the Verb
Synthesis reflects the situation when some words are added or suffixes are attached to the words to indicate features like tense, voice, agreement, etc. (Bickel & Nichols, 2013). Yet, synthesis can have two forms. The former occurs when the attachment is a suffix (English: play-ed) and the latter occurs when the attachment is a word (English: will play). The first one is referred to synthetic inflection and the second one is referred to analytic inflection (ibid). While the synthetic one is purely morphological, the analytic one is syntactic.
Generally, synthesis is independent of fusion i.e. phonological effect. The authors surveyed inflectional synthesis in terms of ‘…agreement, tense/aspect/mood, evidentials/miratives, status (realis, irrealis, etc.), polarity (negation), illocution (interrogative, declarative, imperative), and voice (including Austronesian-style verb orientation), … argument NPs in the case of agreement, sequence of tense rules in the case of tense, cross-clausal anaphora in the case of voice, etc.)’ (ibid).
Category per word (cpw) was used to measure synthesis in terms of more and less synthetic items―maximally inflected verb form. For instance, (English: play-ed) for the past tense is more synthetic than the future (English: will-paly). This results into English verb form having cpw=2 degree. With reference to the presented results below, the author emphasise on the sufficiency of such data as an indicator for the worldwide distribution of the degree of synthesis.
Table 6.
Category per word synthesis feature based on WALS database
Value | No. | (%) | Sample language(s) |
0-1 category per word | 5 | 3% | Mandarin, Sango |
2-3 categories per word | 24 | 17% | English, German |
4-5 categories per word | 52 | 36% | French, Spanish |
6-7 categories per word | 31 | 21% | Arabic (Egyptian), Turkish |
8-9 categories per word | 24 | 17% | Georgian, Lai |
10-11 categories per word | 7 | 5% | Abkhaz, Imonda |
12-13 categories per word | 2 | 1% | |
Total | 145 | 100% |
|
Fig. 4.
Distribution of 145 languages for category per word synthesis feature
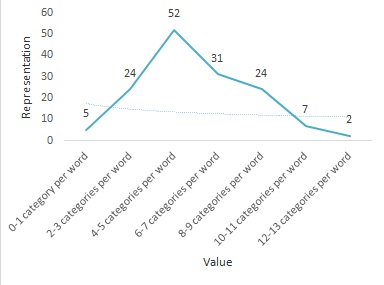
The table indicates clearly that the degree of synthesis among languages could vary from 0-13 with 4-5 cpw as the major category among the investigated number of languages. In other words, languages on the basis of such presented data could be divided into languages with high synthesis degree and those with less synthesis degree. Yet, a zero or weak degree of synthesis might be possible within the first category.
Locus of Marking in the Clause
Nichols and Bickel (2013) presented locus in terms of three aspects: locus of marking in the clause, locus of marking in possessive noun phrases and locus of marking in whole-language typology. Each will be presented separately.
Generally speaking, locus reflects ‘overt morphosyntactic marking reflecting the syntactic relations within the phrase’ (ibid). It could be the head of a phrase (head-marked), not in the head (dependent-marked), in both positions (double-marked), or on none of the positions (no marking). The given table below shows the distribution of 236 languages on the basis of such features.
Table 7.
Locus of marking in clause feature based on WALS database
Value | No. | (%) | Sample language(s) |
P is head-marked | 71 | 30% | Fijian, Swahili |
P is dependent-marked | 63 | 26.5% | English, Turkish |
P is double-marked | 58 | 24.5% | Persian, Spanish |
P has no marking | 42 | 18% | Arabic (Egyptian), French |
Other types | 2 | 1% | Malakmalak, Yagua |
Total | 236 | 100% |
|
Fig. 5. Distribution of 236 languages for locus of marking in the clause feature

Among the five features, it could be clearly seen that (head-marking) is the major feature with 30% followed with (dependent-marking) over 26% and (double-marking) over 24%. The minor features are (other types) with only 1% and (no marking) 18%. Languages seems to be generally majored with a certain feature, that is, marking on the head, on another position or using both. An exemplar-based survey of marking types was used to reach the four types of locus marking: head-marking, dependent-marking, double-marking and no/zero marking.
Locus of Marking in Possessive Noun Phrases
In the earlier section, locus marking in the clause was introduced; in this section, locus in the possessive noun phrase is presented. Similar to locus marking in the clause having four types, here also there are four types where in the possessor is head-marked, dependent-marked, double-marked, not marked, or none of these features (other cases). These types are illustrated below.
Table 8.
Locus of marking in possessive noun phrases feature based on WALS database
Value | No. | (%) | Sample language(s) |
Possessor is head-marked | 78 | 33% | Fijian, Persian |
Possessor is dependent-marked | 98 | 41.5% | English, French |
Possessor is double-marked | 22 | 9% | Greek (Moder), Turkish |
Possessor has no marking | 32 | 13.5% | Arabic (Egyptian), Indonesian |
Other types | 6 | 2.5% | |
Total | 236 | 100% |
|
Fig. 6. Distribution of 236 languages for locus of marking in possessive noun phrases feature

Among 236 languages, this data shows the distribution of locus marking in the noun phrase. The major type is (dependent-marking) with a percentage over 41% followed by (head-marking) with the percentage of 33%. The difference between these two types and the other types is clearly significant where in the highest percentage for the other types is less than 14% (no marking) followed by (double-marking) with the percentage of 9%. The lowest percentage is less 3% for the other types of locus marking in the phrase where the other rules of morphosyntactic marking are applicable.
In comparison between locus marking in the clause and locus marking in the noun phrase, we can find some differences in terms of major and minor among these features. For instance, while head-marking is the major type in the case of locus marking in the clause, dependent-marking is instead the major type in the case of locus marking in the noun phrase. In both types of locus, (other cases) is the minor type of locus marking with an insignificant different in favour of the locus marking in the noun phrase about 3%, compared to exactly 1% in the case of the former.
Finally, it should be noted that the authors have used an exemplar-based survey to reach the above given distribution and/or classification of languages in terms of locus of marking in the noun phrase. This method is generally yet basically used on counting on the most typological features (default) of a certain language for the investigated area i.e. noun phrase, the least typological patterns.
Locus of Marking: Whole-language Typology
In the earlier two sections of locus; locus of marking in the clause and locus of marking in the noun phrase were introduced, in this section locus of marking in the whole language typology is examined. The table below illustrates the distribution of 236 languages in terms of this feature.
Table 9.
Locus of marking in whole-language typology feature based on WALS database
Value | No. | (%) | Sample language(s) |
Consistently head-marking | 47 | 20% | Abkhaz, Fijian |
Consistently dependent-marking | 46 | 19.5% | English, German |
Consistently double-marking | 16 | 7% | Greek (Modern), Hua |
Consistently zero-marking | 6 | 2.5% | Indonesian, Vietnamese |
Inconsistent marking or other type | 121 | 51% | Arabic, Turkish |
Total | 236 | 100% |
|
Fig. 7. Distribution of 236 languages for locus of marking in whole-language typology feature

Five types of locus in the whole-language typology are used in this section: consistently head-marking, consistently dependent marking, consistently double-marking, consistently zero-marking or inconsistent marking/other types. Over half of the included languages lie within the inconsistent marking/ other type. The other half of the include languages are distributed among the other four types with over yet nearly equal majority for both (consistently head marking) and (consistently dependent-marking) with about 20% for each.
Prefixing vs. Suffixing in Inflectional Morphology
In this section the author investigated the typology of a number of languages in terms affixation. In order to achieve this, Dryer (2013) set out a number of inflectional affixes which are shown below.
Table 10.
Inflectional affix forms
|
|
|
|
|
|
|
|
|
|
The next step was assigning languages a prefixing index and a suffixing index. This assignment works by summing the total value of given points for each of the above given affixational values. A language is given one point for the availability of each value, one point and half if the a language has both the prefix and the suffix feature with no dominance for each, and two points for the three first values which were considered as vital ones.
Table 11.
Affixation feature based on WALS database
Value | No. | (%) | Sample language(s) |
Little or no inflectional morphology | 141 | 14.5% | Fijian, Hausa |
Predominantly suffixing | 406 | 42% | Arabic (Modern Standard, Turkish |
Moderate preference for suffixing | 123 | 12.5% | Arabic (Gulf), Persian |
Approximately equal amounts of suffixing and prefixing | 147 | 15% | Arabic (Iraqi), Irish |
Moderate preference for prefixing | 94 | 9% | Amo, Swahili |
Predominantly prefixing | 58 | 6% | |
Total | 969 | 100% |
|
Fig. 8. Distribution of 969 languages for affixation feature
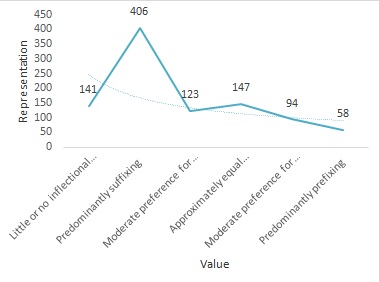
Table 12.
Indexing of affixation value based on WALS database
Feature | Prefixing index | Suffixing index |
Little or no inflectional morphology | ≤ 2* |
|
Predominantly suffixing |
| >80 |
Moderate preference for suffixing |
| >60 |
Approximately equal amounts of suffixing and prefixing | ≤60* | ≥40 |
Moderate preference for prefixing | >60 and ≤80* |
|
Predominantly prefixing | >80 |
|
*Refers to affixing index which represents both prefixing and suffixing index
It could be seen from the above data that the over majority of languages from among 969 are (predominantly suffixing) with the percentage 42%. The least type is with that feature of (predominantly prefixing) which has only 58 languages representing only 6%. This last point raises the question why suffixes are more frequent than prefixes!
Republication as ‘a widely used morphological device among a number of languages’ referring to ‘the repetition of phonological material within a word for semantic or grammatical purposes’ (Rubino, 2013).
Reduplication can have three forms: full reduplication, productive full and partial reduplication, or no productive reduplication. Full reduplication is ‘is the repetition of an entire word, word stem (root with one or more affixes), or root’ (ibid). In comparison, partial reduplication is that which can occur ‘in a variety of forms, from simple consonant gemination or vowel lengthening to a nearly complete copy of a base’ (ibid).
Table 13.
Reduplication feature based on WALS database
Value | No. | (%) | Sample language(s) |
Productive full and partial reduplication | 278 | 75.5% | Arabic (Syrian), Turkish |
Full reduplication only | 35 | 9.5% | Fijian, Japanese |
No productive reduplication | 55 | 15% | English, French |
Total | 368 | 100% |
|
Fig. 9. Distribution of 368 languages for reduplication feature
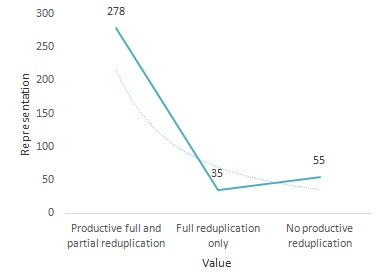
368 languages were examined in terms of reduplication with three values as shown above in the table. The over majority of languages are those with productive full and partial reduplication. They represent over 75%. The least type of reduplication is (full reduplication only) representing less than 10%.
According to Rubino (2013), the phonological nature of reduplication can vary among languages. That is to say, ‘reduplicative morphemes can be characterized by number of phonemes included in the copy, C, CV, CVC, V, CVCV, etc.; the number of syllables to be reduplicated; or the number of repeated morae’ (ibid).
Similarly, reduplicative constructions can be either simple, complex, or automatic. The first one is ‘in which the reduplicant matches the base from which it is copied without phoneme changes or additions’. Dissimilar to this is the complex construction which ‘involves reduplication with some different phonological material, such as a vowel or consonant change or addition, or morpheme order reversal’ (ibid). Comparatively, automatic reduplication ‘is [that] which is obligatory in combination with another affix, and which does not add meaning to the overall construction; the affix and reduplicated matter together are monomorphemic’ (ibid). Lastly, reduplication has a number of functions which could be briefly presented as follows:
Table 14.
Reduplication functions
Reduplicative morpheme | Function |
CVC- distributive prefix for nouns with number | Limitation |
With verbs (and adjectives) | number (plurality, distribution, collectivity), distribution of an argument, tense, aspect (continued or repeated occurrence; completion; inchoativity), attenuation, intensity, transitivity (valence, object defocusing), or reciprocity |
With nouns | denoting concepts such as number (see 1), case, distributivity, indefiniteness, reciprocity, size (diminutive or augmentative), and associative qualities |
With numbers | expressing various categories including collectives, distributives, multiplicatives, and limitatives |
Derivationally | altering word class |
According to Baerman and Brown (2013) case syncretism is realised ‘when a single inflected form corresponds to two or more case functions’. Four values are used: inflectional case marking is absent, inflectional case marking is syncretic for cases only, inflectional marking is syncretic for core and non-core cases and inflectional case marking is never syncretic.
Table 15.
Case syncretism feature based on WALS database
Value | No. | (%) | Sample language(s) |
Inflectional case marking is absent or minimal | 123 | 62% | Arabic (Egyptian), Japanese |
Inflectional case marking is syncretic for core cases only | 18 | 9% | English, Fijian |
Inflectional case marking is syncretic for core and non-core cases | 22 | 11% | French, German |
Inflectional case marking is never syncretic | 35 | 18% | Turkish, Hausa |
Total | 198 | 100% |
|
Fig. 10. Distribution of 198 languages for case syncretism feature
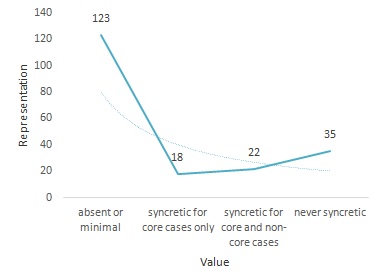
Over than half of the included number of languages have the value (inflectional case marking is absent or minimal) representing 62%. The minor value is for (inflectional case marking is syncretic for core cases only) representing less than 10%. In general, case marking syncretism is found only in 40 languages with less than half of them having this feature for only core cases. Thus, the above data raises a number of questions listed below:
- With reference to case semantics, if two or more functions can be explained in the same form, do they share some element(s) of meaning?
- In the case of core case syncretism, distinction between higher intimacy arguments (accusative form) and lower intimacy arguments (ergative form); and
- In the case of non-core case syncretism, cross-linguistic regularities: is it a matter of language-specific morphological or phonological idiosyncrasies or a matter of general principles?
Syncretism in Verbal Person/Number Marking
Baerman and Brown (2013) present ‘syncretism in the inflectional marking of subject person in verbs’. Three values were used: no subject person/ number marking, subject person/ number marking is syncretic and subject person/ number marking is never syncretic.
Table 16.
Syncretism in verbal person/number marking feature based on WALS database
Value | No. | (%) | Sample language(s) |
No subject person/number marking | 57 | 29% | Hausa, Fijian |
Subject person/number marking is syncretic | 60 | 30% | Arabic (Egyptian), English |
Subject person/number marking is never syncretic | 81 | 41% | Turkish, Russian |
Total | 198 | 100% |
|
Fig. 11. Distribution of 198 languages for syncretism in verbal person/number marking feature
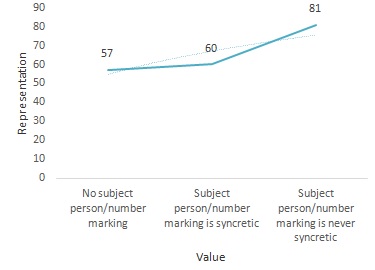
The examined data represents 198 languages where in the value (subject person/number marking is never syncretic) is the major one with the percentage 41%. The other two values are close with a minor difference of 1% in favour of the (subject person/number marking is syncretic). Syncretism has some common patterns including: number and scope (as limited or systematic). The reached results in regard to subject person syncretism led the researcher to inquire the possibility of morpho-semantic relationship in terms of the following theoretical implications and assumptions:
- Identity of form indicates identity of function [+ discourse participant] and [- speaker];
- the syncretic form could be construed as unspecified for person;
- The syncretic form actually “belongs” to one of its component values; and
- Syncretism could be the result of purely fortuitous homophony.
Features of Arabic
The Arabic Language is introduced on WALS as a Semitic language and the official language of 22 countries which are the official members of the Arab League per say. These countries in Alphabetical orders are: Algeria, Bahrain, Comoros, Djibouti, Egypt, Iraq, Jordon, Kuwait, Lebanon, Libya, Mauritania, Morocco, Oman, Palestine, Qatar, Saudi Arabia, Somalia, Sudan, Syria, Tunisia, United Arab Emirates and Yemen. Each of these countries has its own dialect when it comes to daily communication. However, when it comes to writing and media or say the official use of language, a unified language is used, namely referred to Modern Standard Arabic (MSA). The communication among Arabs is highly successful. Needless to say that the differences among dialects includes all linguistics levels: phonological, lexical, structural and pragmatic levels. In terms of sociolinguistics, the further the distance is, the more differences will be among the dialects of Arabic. This is of course in addition to the effect of media in terms of dominance where in Egyptian Arabic, Syrian Arabic seem to stand as the major ones.
Table 17.
Morphological features and assigned values for the Arabic language(s) based on WALS database
No. | Typological area | Feature | Arabic |
1 | Ablaut/concatenative | EA* | |
2 | No case | EA | |
TAM+ agreement+ diathesis | EA | ||
3 | 6-7 categories per word | EA | |
4 | P has no marking | EA | |
5 | Possessor has no marking | EA | |
6 | Inconsistent marking or other type | EA | |
7 | Zero marking of A and B arguments | No zero marking | EA |
8 | Predominantly suffixing | MSA* | |
Moderate preference for suffixing | GA* | ||
Approximately equal amounts of suffixing and prefixing | IA* | ||
Weakly suffixing | EA +GA+ MA*+ SA* | ||
9 | Productive full and partial reduplication | EA+ SA | |
10 | Inflectional case marking is absent or minimal | EA | |
11 | Subject person/number marking is syncretic | EA |
*EA: Egyptian Arabic, MSA: Modern Standard Arabic, GA: Gulf Arabic, IA: Iraqi Arabic, MA: Moroccan Arabic, SA: Syrian Arabic
The above table presents the 11 morphological features of Arabic according to WALS database. With reference to our introductory part, we can clearly notice that the representation of the varieties of Arabic is more than that of the Standard Arabic or even the Modern Standard Arabic. Egyptian Arabic is the major represented language in regard to these presented features in the WALS database. In one way or another, this does not mean the absence of these features in the other varieties of Arabic. There are two possible explanations for this result. First of all, it could be a sociolinguistic one moving towards social biasness (i.e. sociolinguistic biasness in the case of an insider researcher and intellectual/psychological biasness in the case of an outsider researcher) for one variety of the Arabic over the others. In other words, the researcher who conducted the studies on the Egyptian Arabic [preferred] presenting the diversity and power of the Egyptian Arabic instead of examining the Standard Arabic or the Modern Standard Arabic. And this also applies to the studies which examined Gulf Arabic, Moroccan Arabic and Syrian Arabic. Second, it could be attributed to the point that this area is under researched and the researchers [chose] to examine their own variety or the one they are familiar with—probably assuming that the spoken language is more effective than the written and formal spoken Arabic (i.e. referring to both Standard Arabic and Modern Standard Arabic).
Conclusions
The presented typological features of languages in WALS database seem to move the direction of the study of typology from the macro level to the micro level. It was clear that not only the Arabic language was presented, but Arabic languages, instead. This evidenced flexibility of the morphology of Arabic is a plus; however, a further evidence is needed for the reason(s) leading to this diversity especially when realising that the original spoken Arabic was the Standard Arabic when referring to the pre-Islamic and Islamic periods.
Информация о конфликте интересов: авторы не имеют конфликтов интересов для декларации.
Information of conflict of interests: authors have no conflicts of interests to declare.












Список литературы
Список использованной литературы появится позже.