
The complexity of semantic search in native and foreign languages: an analysis of eye-movements
Abstract
The article discusses the central problems of word recognition in native and foreign languages. Russian-speaking and Azerbaijani-speaking subjects were solving the visual semantic search task and were looking for Russian words among randomly arranged Cyrillic letters. Words were hidden in the 15x15 letter matrix, they were not spaced, consisted of 6-7 letters, were arranged either horizontally or vertically; half of words included several identical letters, half of them did not. Each matrix had ten words and had an emotional valence index and a frequency index. The recorded indices were the number of found stimuli and eye metrics. The study showed the effects of language knowledge, the arrangement of words in the matrix, their frequency and the letter set. The subjects were more likely to detect horizontally arranged words that have a higher frequency and several identical letters; the established regularity had a similar effect for both groups. The effect of emotional valence was weak only for the Azerbaijani-speaking subjects. The search in the native language was more effective due to the use of more effective strategies for cognitive processing of verbal material. The Russian-speaking subjects employed a consciously controlled strategy, associated with the use of mental resources and reflected in longer fixations and short saccades; the Azerbaijani-speaking subjects used a more chaotic strategy, covering a larger search space, associated with longer saccades and shorter fixations. More complicated tasks (with lower-frequency lexemes) led to a change in strategies and the use of special skills of identifying words, which were different for both groups.
Keywords: Visual semantic search, Word recognition, Eye movements, Native and foreign language, Complexity of Cognitive Processing
Introduction
The problems of text complexity and text comprehension have given rise to two lines of research: the first is search for objective quantitative complexity indices, whereas the second is the analysis of subjective qualitative descriptions and complexity assessment (see Hiebert, Pearson, 2014). As the objective indices researchers employed the frequency of words, the syllable set, the length of sentences, the clarity of text parts, etc.; their number could reach 60 or even more (Klare, 1984). These ideas underpinned automatic text complexity assessment systems (Solovyev, Solnyshkina, McNamara, 2022), although many authors point out to their flaws. In particular, it has been repeatedly emphasized that the objective evaluation of difficulty does not coincide (or does not coincide exactly enough) with the subjective assessments by readers. That is why researchers are still trying to develop new subjective or qualitative criteria for text complexity based on expert assessments and special standardized questionnaires. Subjective indices, however, are often vague and not exact. For example, students are not always able to fill out text complexity assessment questionnaires without the help of teachers (Toyama, Hiebert, Pearson, 2016).
The cognitive approach has changed the view of this problem by linking the complexity of incoming information with human capabilities and nature of information processing (Gough, 1972). Task difficulty (its goals, content and context) is viewed through the prism of mental work. For example, the RAND model singles out as text comprehension factors a parameter of cognitive activity, which uses multilevel processing operations and is determined by the goals, in addition to the parameters of the text and the subject who reads it (Snow, 2002). The methods and techniques of such activity can be designated as execution strategies, whose effectiveness depends on the characteristics of the verbal material, on knowledge and experience, as well as on the motivational attitudes and mental states of the subject. The process of comprehension is also inseparable from the socio-cultural context, habitual social practices and ideas about the world.
This study used the analysis of eye movements to identify the features of mental work with lexical material in the native and foreign languages and to describe the nature of the difficulties that the subjects face. The task of the visual semantic search required detection and recognition of words of the Russian language in a chaotic set of Cyrillic characters. The methods and mechanisms of visual word recognition are some of the most discussed topics in modern cognitive science (Adelman, 2012; Yap, Balota, 2015; Snell, Grainger, 2019). The process is believed to include several stages of transition from the letter physical features to the lexico-semantic mental representation, from external form to meaning (Martin et al., 2017). With some limitations, word recognition can be considered as a unit of text comprehension. We are aware that working with text cannot be reduced to identifying words: Sometimes the text can be understood when not all words are recognized, and vice versa, recognition of all words does not always lead to complete comprehension of the text. However, revealing the cognitive processes of word recognition may give insight into the functional and computational mechanisms of text comprehension (Schotter, Payne, 2019), whereas the identification of word recognition strategies and involved difficulties can lay the foundation for further analysis of text complexity using eye movements.
Researchers are increasingly using eye tracking technologies to study word recognition (Holmqvist, Andersson, 2017). The bulk of the collected data tackled reading processes (Rayner, 2009; Leinenger, Rayner, 2017)[1]. Scholars, however, encountered a number of problems here, in particular, the fact that reading skills in literate adults are highly automated, and this hampers revealing of the cognitive architecture of recognition. On the contrary, recognition of the meanings of separate words usually limits the number of oculomotor indices considered (Blinnikova, Izmalkova, 2016). The task of detecting words in a noisy context creates an unusual situation and significantly complicates the processes of reading and recognizing lexemes. In particular, it is distinguished by a higher level of crowding[2], the bulk of letters competes for limited processing resources. All this makes it impossible for the reading process to be automatic (Falikman, 2017) and allows obtaining more information on the structure of verbal processing and employed strategies.
We assumed that finding native language lexemes would be much easier than searching in a foreign language, which would be expressed in a larger number of found words (Hypothesis 1). The study involved Russian and Azerbaijani students. The Azerbaijanis were trained in Russian at the Baku branch of Lomonosov Moscow State University and knew the Russian language quite well, although their level of language competences was lower than that of natives. However, the research goal was not only to establish the superiority of the native language over the foreign one, but also to identify how this advantage is achieved, which strategies, methods and techniques the subjects use. Therefore, we varied a number of test stimulus parameters, complicating the solution of the task, and analyzed how this changed the process of word detection and recognition. We also assumed that the factors would have different effects on the performance of the search and detection of words in the native and foreign languages (Hypothesis 2).
One of the factors affecting word recognition is the properties of their location on the page (Rabeson, Blinnikova, 2020). In our case, the words were arranged in the matrix either horizontally or vertically. The horizontal arrangement of words is common to all Indo-European and Turkic languages, so we assumed that for both groups of subjects it would be easier to read and recognize horizontal words. However, we thought that it would be easier for Russian-speaking subjects to detect vertically placed words, as this group has greater search potential in general.
Data from numerous sources link the speed and success of recognition with the frequency of words, their letter set and length (Kinoshita, 2015; Yap, Balota, 2015; Blinnikova, Rabeson, Izmalkova, 2019). Our study used words with different levels of frequency in written texts and assumed that this would have an impact on word detection. This impact, however, would be different for different groups of subjects. It was reasonable to assume that the search and recognition of words in a foreign language would be more sensitive to the stimulus frequency rate than the search for words in the native language. As for the length of words, the test stimuli included from 6 to 7 letters, but the matrices also contained short distracting words that could not be named by the subjects. We thought that the false naming of short stimuli would be more typical for searching in a foreign language. We also tested the assumption that the letter set would affect word detection. To do this, we used a fairly rare method of identical letters in a word (Norris, 1984), believing that the repeated use of the same letter in a word would facilitate its detection. In addition to objective physical properties, word recognition can hypothetically be influenced by semantics of words. Our study exploited words with different emotional connotations: positive, negative and neutral. We believed that positive emotionality would create additional activation for word detection and word recognition. This assumption relied on data on the influence of the emotional valence of words on the speed of their discovery (Kuperman et al., 2014; Gao, Shinkareva, Peelen, 2022).
There are several word recognition models (Norris, 2013; Rastle, 2016) but all the revealed identification mechanisms can be essentially grouped into three clusters. In the first of them, people construct and recognize words via the successive collection of letter chains; the second one presupposes the possibility of simultaneous identification of a holistic word representation[3]; whereas in the third cluster recognition relies on the identification of sublexical units (for example, syllables or different chunks). It can also be assumed that mastering written speech leads to a transition from letter-by-letter perception to reading syllables as elements of lexeme building, and further to identifying whole words as a kind of hieroglyphic symbols. In this case, those who are in the earlier stages of language acquisition will be more likely to use letter-by-letter reading strategies, while more advanced speakers are more likely to rely on holistic word perception. As a third hypothesis, we assumed that the search and detection of words in the native and foreign languages would use different strategies, which can be revealed by the analysis of eye movements (Hypothesis 3).
Main part
The purpose of the work is to compare the effectiveness and strategies of visual semantic search in native and foreign languages.
Materials and Methods
Sample: The study involved two groups of subjects: students of Russian and Azerbaijani universities, a total of 42 people aged 18 to 25 (the average age was 20). The group of Russian subjects consisted of 18 people (12 women and 6 men), and the group of Azerbaijani subjects consisted of 24 people (16 women and 8 men). The groups were equivalent in terms of age and level of education, while their culture (Russian or Azerbaijani) and their command of the Russian language was different. For the Russian subjects, Russian was their mother tongue. For the Azerbaijani subjects, Russian was a foreign language, which they studied at least from the first grade of school and knew at the level of B2, C1. It was also the language of their studies at university.
The experimental task was based on Hugo Münsterberg’s technique (see Falikman, 2017), which involves the search and identification of words hidden among many randomly arranged letters. A letter matrix was presented for a short time to the study participants, who were to find there meaningful lexical units. On the one hand, this task looks like a puzzle, and on the other hand, it represents a variation of information retrieval, which is of high importance for people today. Since the subjects did not know in advance words they were looking for, they had to constantly make (or identify) letter sequences and decide whether those letter strings were words.
Figure 1. Example of a stimulus matrix with high-frequency emotionally positive words
Рисунок 1. Пример стимульной матрицы. Представлена матрица с высокочастотными позитивно эмоционально окрашенными словами

Stimuli: For the experiment, 15 x 15 matrices filled with Cyrillic letters were constructed, with 10 words of the Russian language placed in each table (see Fig. 1). The length of the test words was 6 or 7 characters, they could be arranged either horizontally or vertically and differed in frequency of use, in the number of identical letters in a word and in their semantic valence. In the matrices, one could sometimes find short words or abbreviations of two or three letters but the instructions forbade the subjects to name them. Half of the words had identical letters and the other half did not. The frequency of words was determined using the frequency dictionary of the modern Russian language[4]. The semantic valence was determined by the emotional valence indicator, which was assessed in a preliminary study (Blinnikova, Marchenko, Badalova, 2014). A total of 7 matrices were prepared: one was used for the training series, six for the experimental series. Each matrix had its own frequency index and emotional valence index, which were calculated as average values for the ten words included in it. The experimental sequence included two emotionally positive, two emotionally negative and two emotionally neutral matrices. One of the two matrices in each emotionally valenced block had a higher, and the other one had a lower frequency.
Study procedure: Each subject was tested individually. At the beginning of testing, the subjects filled out the protocol, where they indicated their name, age, educational background and agreed to participate in the experiment. Then the instruction on the display explained the purpose and conditions of the experiment. After that, the subjects performed a trial series, when they were looking for all the words in the presented matrix without any time limit. During the trial series, the program reminded the subjects that words could be arranged both horizontally and vertically, but not diagonally or stepwise. In addition, it was emphasized that they should look for “long words”, consisting of 6-7 letters, and not pay attention to short lexemes, which could sometimes be made out of presented set of letters. Next, the subjects received the main instruction, the equipment for recording eye movements was calibrated, and the subjects solved six matrices of the experimental series. The exposure time for each table was 40 seconds. Before each matrix, a masking stimulus as a fixation point was presented for one second. The sequence of matrices changed from subject to subject.
Equipment: The experiment was carried out using SMI Gaze & Eyetracking Systems hardware and software. We used the program for the development of experimental design and presentation of stimulus material “Experimenter Centre”, as well as a device for non-contact registration of eye movements from SMI RED (the system is based on the “dark pupil method”) with a frequency of 500 Hz. This equipment is designed to make environmentally valid experiments. During registration, the subject's head can move freely in a space of 40 cm x 40 cm x 70 cm. Distance to the monitor is 60 cm – 80 cm; accuracy reaches 0.4°; spatial resolution (RMS): 0.03°; possible delay up to 6 ms; fast automatic calibration <10 s. The behavior and verbal responses of the subjects were filmed and the audio was recorded.
Measured indices: The answers of the subjects were recorded: the number of correctly identified and named words, the number of errors, i.e. incorrectly identified words. Eye movement indices were also recorded: 1) duration and number of fixations, amplitude and direction of saccades for the entire matrix; 2) the number, total and average duration of fixations, the number of recurrent saccades in the areas of interest (AOI), which were identified as test words.
Raw data processing: Our statistical data analysis used the SPSS’22 package and the following methods: consistency test with a normal distribution (Kolmagorov-Smirnov test), ANOVA to compare the average values between the groups.
Results and discussion
Key performance indices of word search and word detection in two groups of subjects. The first stage consisted of the analysis of the number of detected words in the matrices. A total of 252 samples were analyzed for 42 subjects. The search performance in the native language was significantly higher than in a well-studied foreign language. On average, the Russian students found 2.99 (SD = 1.39) and the Azerbaijani students 1.84 (SD = 1.23) words in each matrix; the difference was more than one word and highly significant (F (1, 251) = 45.09; p<0.01). The probability of detecting each word was 0.29 for the Russian sample and 0.18 for the Azerbaijani sample. This result was expected: in most studies, quantitative and qualitative indices of verbal problems solutions in the native language were superior to those in a foreign language (see Rayner, 2009). The subjects were asked to find only long words consisting of 6 or 7 letters in the matrices. The length of the test words differed slightly and did not have a significant impact on their detection. In the Azerbaijani sample, the subjects found short distracting words now and then (on average 0.37 for the matrix), whereas in the Russian sample this almost never happened (on average 0.06 for the matrix).
We also compared the performance of the two groups of subjects depending on the characteristics and arrangement of words in the matrix. The results are in the Table 1. Differences between the detection of words in the native and foreign languages were significant for almost all experimental conditions. This suggests that the factor of the native language is significant, its influence is manifested regardless of the frequency, letter set, length and emotional coloring of words. An exception to this pattern was the detection of vertically arranged words, only in this case the differences between the groups were insignificant: both Azerbaijani and Russian subjects were approximately equally unsuccessful (data are highlighted in grey in the Table 1).
Table 1. Number of words reproduced on average in the matrix depending on their location, frequency of use, letter set and emotional valence in two groups of subjects (Insignificant differences are highlighted in grey)
Таблица 1. Количество воспроизведенных слов в среднем по матрице и в зависимости от их расположения, частотности употребления, состава и эмоциональной валентности в двух группах испытуемых (серым цветом выделены незначимые различия)
In addition to the native language factor, some other effects were identified. A significant influence on the search, detection and recognition of words is exerted by the factor of their location (F (2, 250) = 32.93; p<0.01). Horizontally arranged words are found much easier than vertically arranged ones. This can be explained by the habitual nature of reading words, since in Russian (as in all modern Indo-European languages) reading is carried out from top to bottom, line by line, one horizontal sequence of lexemes is read after another. Japanese subjects, solving a similar task, showed their superiority in this component (Rabeson, Blinnikova, 2020).
Another significant factor was the letter set: our study took into account the presence of identical letters in a word. The probability of detecting words that had identical letters was significantly higher than in words where this did not occur (F (2, 250) = 11.44; p<0.01). In general, this confirms the previously established effect of interaction between word recognition and identical letters in a word (Norris, 1984). The influence of frequency is consistently confirmed in word recognition experiments (Norris, 2013) and our data were no exception: in matrices with a higher word frequency index, stimuli were more likely to be found (F (2, 250) = 5.74; p<0 .05). None of these factors were found to interact with the native language factor. Subsequently, the arrangement of letters and identical letters, as well as the frequency of words had the same effect on the search and detection of words in both the native and foreign languages. Such results contradicted our second hypothesis.
The factor of emotional coloring of the word had no significant effect. Table 1 shows that the results of the Russian subjects for matrices with emotionally positive, negative and neutral words were almost the same. However, this was not entirely true for the Azerbaijani sample. In matrices containing words with positive connotations, Azerbaijani subjects found more words than in matrices with negative connotations. The differences were not significant and we can only consider them as a trend requiring further testing (F (1, 143) = 2.30; p<0.1); calculated only for the Azerbaijani sample). Apparently, the fundamental effect here is the sociocultural context, not the command of a language. A number of recent studies have shown that representatives of Azerbaijani culture are more context-oriented when perceiving various stimuli and solving problems (Arestova, Muslimzade, 2018; Blinnikova et al., 2021). In our case, the influence of the emotional factor could only have a contextual character. The detection of the first word “revealed” the features of the matrix to the subjects, and they could continue the search with more or less enthusiasm. For the Russian-speaking sample, this was not significant, but, albeit slightly, it influenced the Azerbaijani sample.
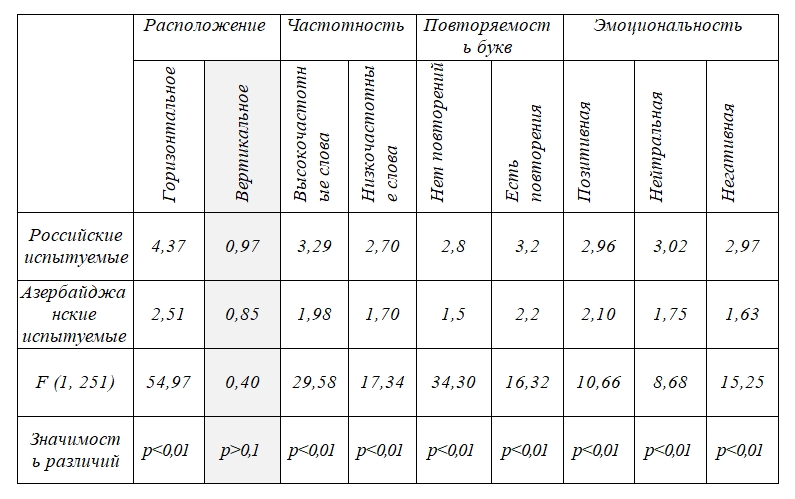
Eye movements of the subjects in the whole search matrix. The comparison of the main indices of eye movements in the groups of Russian and Azerbaijani subjects was surprising. The pattern of oculomotor activity of the Russian students had longer fixations and short saccades compared to the Azerbaijanis (see Fig. 2 a, b). At the same time, intergroup differences were significant both for the index of the average duration of fixations (F (1, 251) = 4.41; p<0.5) and for the amplitude of saccades (F (1, 251) = 77.57; p< 0.1). The data obtained did not comply with the established rule that the development of reading and language skills leads to a reduction in fixation time and an increase in the amplitude of saccades (Rayner, 1998). Our pattern was opposite: the subjects, who knew the language better, used longer fixations and short saccades. Taking into consideration that the detection performance of the Russian-speaking subjects was higher, and there was no doubt that the task was easier for them, these data could only be interpreted in one way: the Russian-speaking subjects used a special strategy[5] that brought them success.
Figure 2 a, b. Comparison of the average fixation duration (a) and the saccade amplitude (b) during search in matrices for two groups of subjects
Рисунок 2 а, b. Сравнение средней длительности фиксаций (a) и амплитуды саккад (b) в процессе поисковой активности на матрицах в двух группах испытуемых
These data are to be studied in the context of the used task. The proposed task prevented using automated reading skills[6]; it was necessary to switch to completely different ways of working with verbal material. Russian-speaking subjects, working with the material of their native language, began to use a slower, consciously controlled strategy, possibly resorting to working memory resources in order to store intermediate search results and detect words. This was reflected in shorter saccades and longer fixations. This is consistent with a number of previous data demonstrating that as the text becomes more complex, the field of attention narrows and verbal processing becomes more organized and consistent (Schad, Engbert, 2012). However, the subjects, when solving tasks in a foreign language, did not employ a conscious generate-and-test procedure. The Azerbaijani-speaking subjects chose a faster, more chaotic strategy with rather superficial cognitive processing, which led to longer saccades and shorter fixations. They seemed to strive for wider coverage hoping to “bump into” stimuli.
Previously, researchers already described cognitive strategies that are used in word recognition. D. Balota and D. Sieler (1999) identified two such strategies: one provides fast-acting familiar-based processing and the other is used in less familiar situations and relies on slow processing with the involvement of conscious attention. Our previous studies also identified two similar strategies that corresponded to the focal and ambient processing described by B.M. Velichkovsky. Focal processing provides access to deeper levels of information analysis and manifests itself in longer fixations in combination with shorter saccades. Ambient processing is more superficial and aimed at a wider coverage of available information; it manifests itself in a combination of shorter fixations with extended saccades (Velichkovsky et al., 2005). It is significant that we found similar differences in image processing strategies between the Azerbaijani and Russian samples (Blinnikov, Rabeson, Blinnikova, 2022).
Analysis of eye movements indices in areas of interest (AOI). Test words were selected as areas of interest. The analysis of oculomotor indices in those areas confirmed the choice of strategies by the subjects. The Azerbaijani-speaking subjects are distinguished by a smaller number of shorter fixations in areas of interest, their dwell time was shorter (1369,30 vs 1712,20; F (1, 251) = 44,27; p<0,01). Russian-speaking subjects continued to use a slower strategy of searching, detecting and recognizing words; they stayed longer in areas of interest, which led to better results. In addition to the duration of fixations, the groups also differed in the rate of returns to the area of interest, which was significantly higher in the Russian-speaking sample, regardless of whether the word was eventually found or not (see Table 2).
The fact that the Russian-speaking subjects persisted in returning to the areas where the test stimuli were located even before they were detected indicates that before the final identification of the word, subjects have a premonition of its existence, and this implicit feeling makes one return to the intuitively identified area[7]. Previosly, B. M. Velichkovsky and colleagues obtained similar data: When subjects were comparing elements located in two areas of the screen, they scanned the area without regressive eye movements until the moment they had detected the difference in stimuli they had been looking for. After that, the eyes repeatedly and sequentially began to analyze the same critical areas (Velichkovsky et al., 1995). Phenomena of this kind were also described in the rationale for the Target Acquisition model, which assumes that the control of eye movements depends on top-down knowledge and processes, in combination with the redistribution of spatial search zones. This highlights significant areas while ignoring those in which the probability of finding targets is low (Zelinsky, 2008).
Table 2. Main indices of eye movements of subjects in the areas of interest for detected and non-detected stimuli (Insignificant differences are highlighted in grey)
Таблица 2. Основные показатели движений глаз испытуемых в областях интереса для обнаруженных и необнаруженных стимулов (серым цветом выделены незначимые различия)

Russian native speakers seem to have more possibilities of relying on implicit representations of the object, creating "maps of potential targets" and using them to solve problems. The emergence of such anticipatory constructs leads, on the one hand, to a large time input (which is reflected in longer fixations), and, on the other hand, to a desire to return to the area of a potential stimulus (which leads to a greater number of regressive eye movements). This was confirmed by the fact that for the Russian-speaking subjects, the number of fixations in relation to each cell in these areas was significantly greater than the number of fixations in relation to matrix cells in which there were no words (0,62 vs 0,50; F (1, 107) = 29,44; p<0,01). No such regularities were found for the Azerbaijani-speaking subjects. The existence and mechanisms of using such implicit representations have been previously discussed in a number of works (Craik, Rose, Gopie, 2015; Flusser, Kautsky, Šroubek, 2007). It is possible that the mechanism for creating a kind of a probabilistic representation also operates in a more natural reading situation, creating a potential field for word recognition (see, for example, Hyönä, 2021).
Differences in eye movements indices depending on lexeme identification difficulty. Our finding based on the word recognition performance was that some conditions increased the difficulty of tasks while others decreased it. A higher frequency index, identical letters in words, horizontal arrangement increase the chances of word detection and word recognition.
These factors were also checked for the ability to impact eye movements indices of subjects as well as the ability to influence their performance. The most interesting results were obtained for the average duration (Fig.3) and number of fixations (Fig.4у) in the Areas of Interest that include identified words (527 words in total). Two-way ANOVA demonstrated effects of the native language factor and the word frequency factor on the average fixation duration in the area of interest with identified words as well as the interaction of the two factors.
Figure 3. Differences in the average fixation duration in the area of interest with identified words depending on the frequency factor and language knowledge
Рисунок 3. Различия в средней длительности фиксаций в области интереса идентифицированных слов в зависимости от фактора частотности и уровня знания языка

Fig. 3 illustrates that in a situation of recognizing less frequent words a greater task difficulty leads to a change in the nature of information processing in both groups of subjects. The results of two-way ANOVA demonstrated the significance of the language group factor (F (2, 525) = 4.84; p<0.05) and the interaction of the language group factor and word frequency (F (2, 525) = 6.74; p<0,01). The average fixation duration of the Azerbaijani students increased, while the number of fixations almost stayed the same. This result is typical in situations of more complicated task conditions and increased cognitive load (Rayner, 2009; Staub et al., 2010; Latanov, Anisimov, Chernorizov, 2016). In this case, when working with low-frequency words, the Azerbaijani subjects need more time to find a mental representation of a rarer stimulus.
Figure 4. Differences in the number of fixations in the area of interest with identified words depending on the frequency factor and language knowledge
Рисунок 4. Различия в количестве фиксаций в области интереса идентифицированных слов в зависимости от фактора частотности и уровня знания языка
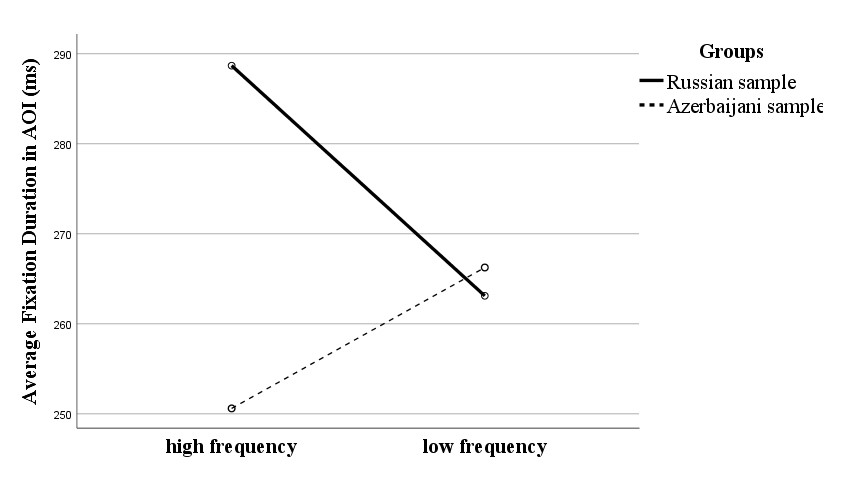
The results of the Russian sample are somewhat paradoxical: increasing complexity leads to shorter fixations and therefore faster processing. These results can only be understood and explained by taking into account the general strategy that the subjects are using and the ability to draw on preliminary vague representations. If confirmation of emerging assumptions about the presence of a high-frequency word makes Russian subjects use the so-called "chunks"[8] (information blocks based on letter strings), low-frequency words verification requires a letter-by-letter search. This is also confirmed in the Russian-speaking sample by the link between a decrease in the fixation duration and an increase in the number of fixations (see Fig. 4) when working in difficult conditions, although the level of differences was not very high (F (2, 525) = 2.21; p=0,1).
Conclusion
This study has established a number of significant facts. First, it obtained information about the possibilities of searching and detecting words among many randomly arranged letters, in native and foreign languages. The task that we offered to the subjects was very difficult mainly compared with reading tasks: in the word detection space, there were no usual markers for the beginning and end of a lexeme, the words were arranged both horizontally and vertically, and the pressure of interfering stimuli was high. Under such conditions, the success of the subjects was not very high. At the same time, the Russian-speaking subjects significantly outmatched the Azerbaijani-speaking ones in terms of the number of detected words.
Additional factors of influence on the performance of visual semantic search were also identified. The word arrangement factor had the greatest effect: horizontally located words were identified with greater success than vertically located words. The detection of horizontally located words among the Russian-speaking subjects was almost twice as superior to that among the Azerbaijani-speaking subjects, whereas the detection of vertically located words did not differ significantly in both groups. Although the task did not allow the full use of reading skills, they nevertheless helped to organize the search. The effect of frequency was also relevant: it was easier to identify high-frequency words. This pattern was evident in the search for words both in the native and in the foreign language and testified to common mechanisms of word recognition in different conditions. In addition, our investigation indicated the influence of the identical letters factor: If the words had identical characters, they were more likely to be found. Apparently, in the proposed task, the location of two identical letters in sufficient proximity to each other is a good clue to detect test stimuli. It was not possible to establish the influence of emotional valence on word detection. We assumed that positively colored words would be more likely to be recognized, but this effect was very weakly manifested only for the Azerbaijani sample. For the Russian-speaking subjects, this factor was absolutely insignificant; the percentage of detected words for matrices with different emotional valences was approximately the same. Such differences may be related to cultural determinants. Eastern cultures, to which Azerbaijani culture allegedly gravitates, are more sensitive to context, in contrast to Western cultures, to which Russian subjects are closer. In our case, emotional valence could only have an impact creating a kind of an emotional context, and it turned out be important for representatives of Azerbaijani culture.
Our investigation found that under given complex conditions, subjects use different word recognition strategies for the search in the native and in the foreign language. This conclusion was based on the analysis of eye movements. Habitual reading skills here are challenged and, perhaps, the realization of this fact makes the Russian-speaking subjects switch to more consciously controlled slow strategies of isolating and identifying lexemes when working with their native language. The Azerbaijani-speaking subjects, when solving the problem in a foreign language, took a completely different approach: Their strategy was more spontaneous and superficial, and search movements were more chaotic. It is still difficult to answer the question why the studied samples turned to such different strategies, whether the factors of language knowledge or cultural traditions had an influence here. The answer to this question will have to be sought in future research.
The obtained results demonstrated that the detection of words among an array of randomly arranged letters involves the implicit processing of verbal stimuli and the creation of preliminary implicit representations of words that either take on an explicit form or not. This is manifested, in particular, in the fact that fixations and saccades "gravitate" to the areas of interest with the "hidden" words, even if subjects fail to recognize them. Our data demonstrated that such implicit processing is more accessible to subjects who solve the problem in their native language. A number of established regularities confirm this. In particular, the Russian-speaking subjects often returned to the area of hidden stimuli and eventually identified the words, which was largely the reason for their success. Besides, our data showed that before naming a word, Russian speakers double-checked preliminary assumptions rather than immediately named the words. The subjects who know Russian as a foreign language do not fully possess such possibilities. They try to “run into” and “grasp” words from a chaotic canvas of letters, but in most cases their gaze slips past the test stimuli, they fail to effectively use letter strings (“chunks”) and to rely on pre-created implicit representations, which ultimately limits their ability to detect and recognize letters.
[1] Some researchers claim that eye movements do not only accompany word recognition but are a vital for this process. When subjects cannot move their eyes, they need more time to name words and to make their final decision about the lexeme (Schotter, Payne, 2019).
[2] The processing information limitations caused by letter crowding have been lately considered as one of the central problems for determining the difficulty of reading and recognizing of lexical material (Grainger, Dufau, Ziegler, 2016).
[3] Contemporary models state that readers resort to parallel letter processing in this case (Grainger, Dufau, Ziegler,2016).
[4] Lyashevskaya, O. N., Sharov, S. A. (2009). Frequency Dictionary of the Modern Russian Language (based on the materials of the National Corpus of the Russian Language), Publishing center "Azbukovnik", Moscow, Russia.
[5] The approach that considers various cognitive and metacognitive strategies of word recognition, reading and text comprehension is becoming more popular (see McNamara, 2007).
[6] Other studies come to a similar conclusion. M. Falikman showed that the use of such a task disrupts automated systems of word recognition (Falikman, 2017).
[7] Our previous research showed that when subjects were solving the same task, their saccades and fixations of subjects were not distributed evenly across the matrix; they were grouped around both detected and undetected words (Grigorovich, Blinnikova, Izmalkova, 2014).
[8] On the role of chunks in remembering and recognizing words, see Norris, Kalm, 2021.












Reference lists
Adelman, J. S. (ed.) (2012). Visual Word Recognition.Volume 2: Meaning and Context, Individuals and Development, Psychology Press, Hove, UK. (In English)
Arestova, O. N. and Muslimzade, P. Z. (2018). Cultural specifics of generalizations at the thinking activity (on the example of Azerbaijani-speaking and Russian-speaking residents of Baku), Voprosy Psikhologii, 3, 87–93. (In Russian)
Balota, D. A. and Spieler, D. H. (1999). Word frequency, repetition, and lexicality effects in word recognition tasks: Beyond measures of central tendency, Journal of Experimental Psychology: General, 128 (1), 32–55. https://doi.org/10.1037/0096-3445.128.1.32(In English)
Blinnikov, G., Rabeson, M. and Blinnikova, I. (2022). Cross-cultural differences in strategies of complex images visual search, Perception, 51 (1), 42. (In English)
Blinnikova, I. and Izmalkova, A. (2016). Eye movement evidence of cognitive strategies in SL vocabulary learning, Smart Innovation, Systems and Technologies, 57, 311–323. https://doi.org/10.1007/978-3-319-39627-9_27(In English)
Blinnikova, I., Blinnikov, G., Bobkov, A. and Alieva, H. (2021). Cross-cultural differences in emotive image assessment: Comparison between Russian and Azerbaijani samples, RSUH/RGGU Bulletin: Psyсhology. Pedagogics. Education, 1, 28–50. DOI: 10.28995/2073-6398-2021-1-28-50 (In Russian)
Blinnikova, I., Marchenko, O. and Badalova, F. (2014) Search for emotionally coloured words in the alphabetic matrix, in Soloviev, V. D., Poliakov, V. N. and Masalova, S. I. (eds.), Cognitive Modeling, Southern Federal University Press, Rostov-on-Don, Russia, 31–36. (In Russian)
Blinnikova, I., Rabeson, M. and Izmalkova, A. (2019). Eye movements and word recognition during visual semantic search: differences between expert and novice language, Psychology in Russia: State of the Art, 12 (1), 129–146. https://doi.org/10.11621/pir.2019.0110(In English)
Craik, F. I., Rose, N. S. and Gopie, N. (2015). Recognition without awareness: Encoding and retrieval factors, Journal of Experimental Psychology: Learning, Memory, and Cognition, 41 (5), 1271-81. DOI: 10.1037/xlm0000137 (In English)
Falikman, M. (2017). Visual search in large letter arrays containing words: Are words implicitly processed during letter search? Journal of Vision, 17 (10), 76-76. https://doi.org/10.1167/17.10.76(In English)
Flusser, J., Kautsky, J. and Šroubek, F. (2007). Object Recognition by Implicit Invariants, in Kropatsch, W. G., Kampel, M. and Hanbury, A. (eds.), Computer Analysis of Images and Patterns: Lecture Notes in Computer Science, 4673, Springer, Berlin, Heidelberg, 856-863. https://doi.org/10.1007/978-3-540-74272-2_106(In English)
Gao, C., Shinkareva, S. V. and Peelen M. V. (2022). Affective valence of words differentially affects visual and auditory word recognition, Journal of Experimental Psychology: General, 151 (9), 2144–2159. https://doi.org/10.1037/xge0001176(In English)
Gough, P. B. (1972). Theoretical models and processes of reading, in Kavanagh, J. F. and Mattingly, I. G. (eds.), Language by Ear and by Eye, MIT Press, Cambridge, MA, USA, 661-685. (In English)
Grainger, J., Dufau, S. and Ziegler, J. C. (2016). A Vision of Reading, Trends in Cognitive Sciences, 20 (3), 171–179. DOI: 10.1016/j.tics.2015.12.008 (In English)
Grigorovich, S., Blinnikova, I. and Izmalkova, A. (2014). Strategies of space scan in the process of visual semantic search, in Soloviev, V. D., Poliakov, V. N. and Masalova, S. I. (eds.), Cognitive Modeling, Southern Federal University Press, Rostov-on-Don, Russia, 49–53. (In English)
Hiebert, E. H. and Pearson, P. D. (2014). Understanding Text Complexity: Introduction to the Special Issue, The Elementary School Journal, 115 (2), 153–160. https://doi.org/10.1086/678446(In English)
Holmqvist, K. and Andersson, R. (2017) Eye tracking: A comprehensive guide to methods, paradigms and measures, Lund Eye-Tracking Research Institute, Lund, Sweden. (In English)
Hyönä, J., Heikkilä, T. T., Vainio, S. and Kliegl, R. (2021). Parafoveal access to word stem during reading: An eye movement study, Cognition, 208, Article 104547. https://doi.org/10.1016/j.cognition.2020.104547(In English)
Kinoshita, S. (2015). Visual word recognition in the Bayesian Reader framework, in Pollatsek, A., Treiman, R. (eds.), Oxford Handbook of Reading, Oxford University Press, Oxford, UK, 63–75. (In English)
Klare, G. R. (1984). Readability, in Pearson, P. D., Barr, R., Kamil, M. and Mosenthal, P. (eds.), Handbook of reading research, Volume 1, Longman, New York, NY, 681–744. (In English)
Kuperman, V., Estes, Z., Brysbaert, M. and Warriner, A. B. (2014). Emotion and language: Valence and arousal affect word recognition, Journal of Experimental Psychology: General, 143 (3), 1065. DOI: 10.1037/a0035669(In English)
Latanov, A. V., Anisimov, V. N. and Chernorizov, A. M. (2016). Eye movement parameters while reading show cognitive processes of structural analysis of written speech, Psychology in Russia: State of the Art, 9 (2), 129-137. DOI: 10.11621/pir.2016.0210 (In English)
Leinenger, M. and Rayner, K. (2017). What we know about skilled, beginning, and older readers from monitoring their eye movements, in León, J. A. and Escudero, I. (eds.), Reading Comprehension in Educational Settings, John Benjamins, Amsterdam, Netherlands, 1–27. DOI: 10.1075/swll.16.01lei(In English)
Martin, R. C., Tan, Y., Newsome, M. R. and Vu, H. (2017). Language and Lexical Processing, Reference Module in Neuroscience and Biobehavioral Psychology, Elsevier, Amsterdam, Netherlands, 631–643. DOI: 10.1016/B978-0-12-809324-5.03078-9 (In English)
McNamara, D. S. (ed.) (2007). Reading Comprehension Strategies: Theories, Interventions, and Technologies, Psychology Press, New York, NY, USA. (In English)
Norris, D. (1984). The Effects of Frequency, Repetition and Stimulus Quality in Visual Word Recognition, Quarterly Journal of Experimental Psychology, 36, 507–518. (In English)
Norris, D. (2013). Models of visual word recognition, Trends in Cognitive Sciences, 17 (10), 517–524. https://doi.org/10.1016/j.tics.2013.08.003(In English)
Norris, D. and Kalm, K. (2021). Chunking and data compression in verbal short-term memory, Cognition, 208, Article 104534. https://doi.org/10.1016/j.cognition.2020.104534(In English)
Rabeson, M. and Blinnikova, I. (2020). Cross-cultural research of strategies and efficiency in visual semantic search, European Proceedings of Social and Behavioural Sciences, 94, 636–645. DOI: 10.15405/epsbs.2020.11.02.78 (In English)
Rastle, K. (2016). Visual Word Recognition, in Hickok, G. and Small, S. L. (eds.), Neurobiology of Language, Academic Press, Amsterdam, Netherlands, 255–264. (In English)
Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research, Psychological bulletin, 124 (3), 372. https://doi.org/10.1037/0033-2909.124.3.372(In English)
Rayner, K. (2009). Eye movements and attention in reading, scene perception, and visual search, The quarterly journal of experimental psychology, 62 (8), 1457–1506. DOI: 10.1080/17470210902816461(In English)
Schad, D. J. and Engbert, R. (2012). The zoom lens of attention: Simulating shuffled versus normal text reading using the SWIFT model, Visual Cognition, 20 (4–5), 391–421. https://doi.org/10.1080/13506285.2012.670143(In English)
Schotter, E. R. and Payne, B. R. (2019). Eye Movements and Comprehension Are Important to Reading, Trends in Cognitive Sciences, 23 (10), 811–812. https://doi.org/10.1016/j.tics.2019.06.005(In English)
Slavova, V. (2022). Language, concept formation and child language acquisition – an information modeling approach, Academic Publishing House of the Bulgarian Academy of Sciences, Sofia, Bulgaria. (In English)
Snell, J. and Grainger, J. (2019). Readers Are Parallel Processors, Trends in Cognitive Sciences, 23 (7), 537–546. https://doi.org/10.1016/j.tics.2019.04.006(In English)
Snow, C. (2002). Reading for Understanding: Toward an R&D Program in Reading Comprehension, RAND Corporation, Santa Monica, CA. (In English)
Solovyev, V., Solnyshkina, M., McNamara, D. (2022). Computational linguistics and discourse complexology: Paradigms and research methods, Russian Journal of Linguistics, 26 (2), 275–316. https://doi.org/10.22363/2687-0088-30161 (In English)
Staub, A., White, S. J., Drieghe, D., Hollway, E. C. and Rayner, K. (2010). Distributional effects of word frequency on eye fixation durations, Journal of Experimental Psychology: Human Perception and Performance, 36 (5), 1280–1293. https://doi.org/10.1037/a0016896(In English)
Toyama, Y., Hiebert, E. H. and Pearson, P. D. (2017). An Analysis of the Text Complexity of Leveled Passages in Four Popular Classroom Reading Assessments, Educational Assessment, 22, 139–170. https://doi.org/10.1080/10627197.2017.1344091(In English)
Velichkovsky, B. M., Challis, B. H. and Pomplun, M. (1995). Arbeitsgedächtnis und Arbeit mit dem Gedächtnis: Visuell-räumliche und weitere Komponenten der Verarbeitung [Working memory and work with memory: Visuospatial and further components of processing], Zeitschrift für Experimentelle Psychologie, 42 (4), 672–701. (In German)
Velichkovsky, B. M., Joos, M., Helmert, J. R. and Pannasch, S. (2005). Two visual systems and their eye movements: Evidence from static and dynamic scene perception, Proceedings of the XXVII conference of the cognitive science society, 2283–2288. (In English)
Yap, M. J. and Balota, D. A. (2015). Visual word recognition, in Pollatsek, A. and Treiman, R. (eds.), The Oxford handbook of reading, Oxford University Press, Oxford, UK, 26–43. (In English)
Zelinsky, G. J. (2008). A theory of eye movements during target acquisition, Psychological Review, 115, 787–835. DOI: 10.1037/a0013118 (In English)