
Параметризация числовой вариативности для русских именных групп с помощью экспериментальных исследований и языкового моделирования
Aннотация
В данном исследовании рассматривается проблема вариативности числа при согласовании с сочиненными конструкциями. Мишень, согласующаяся с двумя сочиненными существительными единственного числа, может копировать признак единственного или множественного числа. Статья посвящена изучению синтаксиса русских именных групп с сочиненными модификаторами, которые демонстрируют вариативность числа контроллера согласования. Если два сочиненных прилагательных единственного числа имеют расщепленную интерпретацию, для вершины-существительного допустимо и единственное, и множественное число. В отличие от предшествующих работ, которые использовали интроспекцию и корпусный метод, мы осуществляем параметризацию вариативности числа с опорой на результаты экспериментальных исследований. В качестве методики для экспериментов были выбраны оценка приемлемости по шкале Ликерта от 1 до 7 и чтение с саморегуляцией скорости. Также мы сравниваем данные человеческого восприятия с вероятностными метриками, предсказанными нейронной языковой моделью для генерации текста ruGPT-3. Для изучения морфологических и синтаксических факторов, которые влияют на выбор стратегии согласования, было проведено два исследования. Первое исследование рассматривает роль числовой морфологии существительного, второе исследование анализирует влияние атрибутивного согласования премодификатора. Опосредованные данные о приемлемости и непосредственные данные чтения показывают, что изучаемые морфологические и синтаксические факторы оказывают значимое влияние на выбор числа существительного в русских именных группах с сочиненными модификаторами. Рассматриваемая языковая модель ruGPT-3, обученная на большом количестве неразмеченных русских текстов, предсказывает корректные вероятностные метрики для строго приемлемых и строго неприемлемых предложений, однако не способна определить верную стратегию согласования для контекстов вариативности.
Ключевые слова: Сочинение, Вариативность согласования, Русский язык, Экспериментальный синтаксис, Языковое моделирование, Приемлемость, Перплексия
К сожалению, текст статьи доступен только на Английском
Introduction
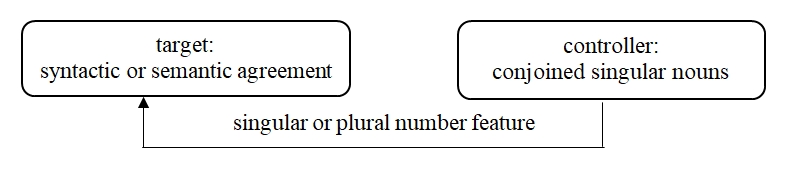
Agreement with coordinated structures frequently permits number form alternation. The syntax of coordinated structures has been widely examined in different languages (Wilder, 1997; Hartmann, 2000; Barros and Vicente, 2011; Grosz, 2015; Shen, 2018, among others). The target (e.g., verb or adjective), agreeing with two conjoined singular nouns, copies either singular or plural number feature corresponding to a syntactic and semantic agreement, respectively (Figure 1).
Figure 1. Number agreement variation
Рисунок 1. Вариативность числового согласования
The number choice in coordinated constructions is parametrized by morphological, syntactic, and semantic factors (Corbett, 1979). English conjoined expressions provide confirmation for this thesis. With conjoined inanimate nouns, the attributive must be singular (1) while the predicate can be of either number (2). Agreement with conjoined animate nouns shows a shift toward syntactic agreement. The singular is still required in the attributive position, while the plural is required in the predicate (3).
(1) this/ *these frost and freezing fog
(2) Frost and freezing fog has/ haveaffected most of the country today.
(3) This/ *these man and woman were/ *was living in the moat. (Corbett, 1979: 6)
The agreement controller may also demonstrate number variation which is observed in Russian noun phrases with coordinated modifiers. If two conjoined singular adjectives have split interpretations, both singular and plural nouns are acceptable (4).
(4) v imenitel’n-om i vinitel’n-om padezh-e/ padezh-akh
in nominative-loc.sg and accusative-loc.sg case-loc.sg case-loc.pl
‘in nominative and accusative cases’ (Kodzasov, 1987: 210)
Previous studies revealed factors parametrizing variation relying on introspection (Kodzasov, 1987) and corpus data (Pekelis, 2013)[1]. However, these methods have several drawbacks (Talmy, 2018). Introspection enables receiving data only about the author’s idiolect, making this method subjective and inaccurate. Corpus studies provide only data on the frequency of acceptable sentences but do not present information about the perception of unacceptable examples.
This paper uses an experimental method and language modeling to parametrize the number variation. There are two goals of the study. Firstly, we aim to parametrize number variation in Russian noun phrases with coordinated modifiers based on the results of syntactic experiments. Experimental method allows us to reveal particular factors which influence the number choice in coordinated constructions. Secondly, we aim to compare the human perception of alternative number forms with the neural models’ probabilities. The modern neural models extract language knowledge from large amounts of unlabeled data and can be evaluated by comparison with human acceptability judgments. The methods and materials of the study will be considered in the next section.
Materials and methods
In order to parametrize the number variation, we conducted syntactic experiments which combined two tasks: the acceptability judgments on a Likert scale from 1 to 7 (Likert, 1932) and self-paced reading (Aaronson and Scarborough, 1976). In contrast to introspection and corpus studies, experimental methods enable us to gather controlled data from many speakers and identify subtle differences in acceptability. The usage of these two methods enables the retrieval of not only offline data on the acceptability of a particular structure but also online data on possible delays and difficulties in the perception. We have chosen the 7-point Likert scale for formal judgment collection since this method demonstrates the greatest statistical power compared to magnitude estimation and two alternative forced choices based on a random sample (Sprouse et al., 2013).
The acceptability scores collected from the experiment must be normalized in order to solve the problem of scale bias. The respondents might use the scale in different ways: avoid the highest (7) and the lowest (1) scores, and use only the top or bottom of the scale. The calculation of normalized scores or z-scores is represented in (5), where Zij is the normalized score j of respondent i, Xijis the score j of respondent i on the 1-7 scale,  i is the mean score of the respondent i and σi is the standard deviation of the respondent i (Schütze and Sprouse, 2014). Normalization was not applied to reading time, but values less than 100 ms and more than 10000 ms were excluded (Gold, 2021).
i is the mean score of the respondent i and σi is the standard deviation of the respondent i (Schütze and Sprouse, 2014). Normalization was not applied to reading time, but values less than 100 ms and more than 10000 ms were excluded (Gold, 2021).

Besides experimental syntax, acceptability judgments have been broadly applied in natural language processing (Sprouse et al., 2018; Warstadt et al., 2019; Brunato et al., 2020 among others). They are used to test language models’ robustness and probe their acquisition of grammatical phenomena. Modern neural language models can generate text almost indistinguishable from human texts (Dou et al., 2022). They are trained on large language datasets without explicit grammar information but somehow generate grammatical texts. In this study, we calculated sentence probabilities by ruGPT-3[2], a neural model for text generation in Russian.
We used perplexity to measure how well a model predicts a sentence (Lau et al., 2020). Perplexity is an evaluation metric for language models and correlates well with human judgments (Lau et al., 2017). Perplexity can be interpreted as the inverse probability of a sentence, normalized by the number of words (6), where PP is perplexity measure, W is a sentence, w1, w2, …, wn are the words of a sentence and n is the number of words in that sentence. Since we are taking the inverse probability, a lower perplexity indicates a higher acceptability. The sentences may have different lengths, so the metric must be independent of its size. It could be obtained by normalizing the probability of the sentence by the total number of words.
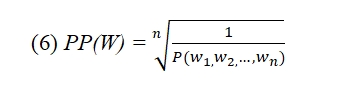
Two platforms were used to conduct the experiments: IbexFarm (Drummond, 2013)[3] and Pen Controller for IBEX (Zehr and Schwarz, 2018)[4]. The library Transformers (Wolf et al., 2020) on Python programming language was used to launch ruGPT-3 model. The R programming language was used for the statistical analysis of the results (R Development Core Team, 2009)[5]. Linear mixed effects models were implemented to identify subtle differences in acceptability (Gries, 2021). To determine the significance level of fixed factors, the lmerTest library was used (Kuznetsova et al., 2017)[6]. After selecting a suitable model, a pairwise comparison of conditions was carried out with the emmeans package (Lenth et al., 2019)[7].
Two case studies are described in this paper. The first study reveals the role of morphological factors while the second study deals with the effect of syntactic context. For each study, 64 sentences were created: 32 stimuli and 32 fillers. One half of the fillers were grammatical (7), another half were ungrammatical and included agreement mistakes (8).
(7)slab-yj vostochn-yj veter nagnal gust-oj tuman.
weak-m.sg east-m.sg wind.m.sg bring.pst.m thick-sg.acc fog.sg.acc
‘A weak east wind brought a thick fog.’
(8)parizhsk-aja nacional’n-yj oper-a otkryl-a nov-yj
Paris.adj-f.sg national-m.sg opera-f.sg open.pst-f new-sg.acc
sezon.
season.sg.acc
‘The Paris National Opera has opened a new season.’
Using grammatical and ungrammatical fillers has a certain goal (Belova et al., 2021). The fillers are used to mark the boundaries of the scale and verify the scores of the stimuli since the fillers do not include context variations. We expect low perplexity values and high acceptability scores for grammatical fillers and high perplexity values and low acceptability scores for ungrammatical fillers. If our expectation is met, the perplexity values and acceptability scores for stimuli will be correctly localized on the scale.
The next two sections describe experimental studies and language model evaluation in detail.
The effect of noun morphology on the number variation
The first study examines the effect of noun morphology on the number variation. The role of number morphology in Russian noun phrases with coordinated modifiers has not been studied before. The correlation between the morphology and the agreement was described for Bulgarian (Harizanov and Gribanova, 2015). The regular number morphology of the noun enables only semantic strategy (9) while the irregular number morphology enables only syntactic agreement (10).
(9) bălgarsk-i-ja i rusk-i narod-i/ * narod
bulgarian-sg.m-def and russian-sg.m nation-pl/ nation.sg
‘the Bulgarian and Russian nations’
(10) naj-nisk-o-to i naj-visok-o dete/ * deca
most-short-sg.n-def and most-tall-sg.n child/children
‘the shortest and tallest child’
The current study tested this assumption in Russian and included two factors: the noun number (singular / plural) and the morphological noun type. The nouns of four morphological types were examined: suppletion and stem alternations (11), suffix alternations (12), syncretic forms, namely singularia tantum (13a) and pluralia tantum (13b), regular nouns (14).
(11) vysok-ij i nizk-ij chelovek/ ljudi perebezhal-i
tall-sg and short-sg man people run.pst-pl
cherez dorog-u.
across road-sg.acc
‘A tall and a short man ran across the road.’
(12) bur-yj i bel-yj medvezhonok/ medvezhata adaptirovalis’
brown-sg and white-sg bear.sg bear.pl adapt.pst.pl
v zoopark-e.
in zoo-sg.loc
‘The brown and the white bears adapted in the zoo.’
(13) a. tvorcheska-ja i nauchna-ja molodjoz spel-i
creative-sg and scientific-sg youth sing.pst-pl
na prazdnik-e.
at festival-sg.loc
‘Creative and scientific youth sang at the festival.’
b. bolsh-ie i malen’k-ije ochki zavalilis’ pod krovat’.
big-pl and small-pl glasses fall.pst.pl under bed.sg.acc
‘Big and small glasses fell under the bed.’
(14) pozhil-oj i molod-oj prepodavatel’/ prepodavatel-i voshl-i
elderly-sg and young-sg teacher.sg teacher-pl go.pst-pl
v auditori-ju.
in classroom-sg.acc
‘An elderly and a young teachers entered the classroom.’
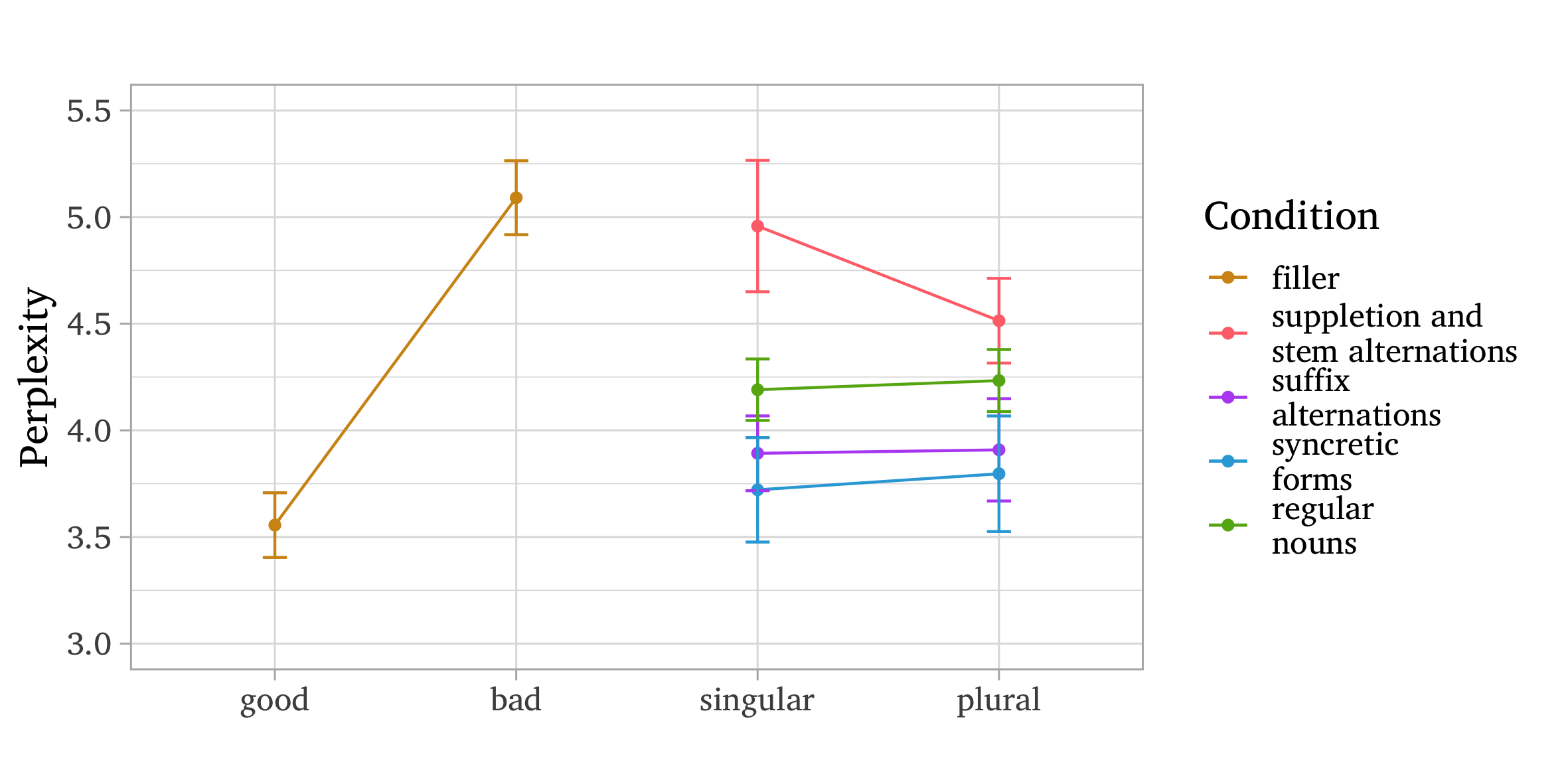
Figure 2 demonstrates the perplexity measures of the ruGPT-3 language model. As mentioned before, the lower the perplexity (y-axis), the more probable or acceptable the sentence is. The grammatical fillers receive low perplexity values, while the perplexity measures for the ungrammatical fillers are high. It corresponds to our expectations and allows us to compare stimuli perplexity value with some benchmark. Thus, the stimuli with the singular suppletive nouns receive almost as high a perplexity value as ungrammatical fillers. The singular number is significantly less probable than the plural number for the sentences with suppletion and stem alternations (p<.05). The other noun types do not demonstrate a significant difference in number probability (p>.05). According to ruGPT-3, the suppletive nouns are the least probable, the regular nouns are more probable than the nouns with suffix alternations, and the syncretic nouns are the most probable.
Figure 2. Mean perplexity values for fillers and stimuli
Рисунок 2. Средние значения перплексии для филлеров и стимульных предложений
The experimental study processes the results of 68 respondents. The mean age of the participants was 37 years (sd=10). There were 32 women and 36 men among the respondents, including 5 people whose profession is related to language (linguist, philologist), and 63 people who are not related to language by profession. A resource Yandex.Toloka[8] was used to involve the respondents. Initially, 71 people participated in the experiments, but the responses of 3 participants were excluded. One respondent used only extreme scores: 1 and 7. Since such responses cannot sufficiently reflect possible contrasts in acceptability, this data has been deleted. In addition, the winsorization by the sum of square deviations was applied to search for outliers. This method was described by J. Sprouse[9]. If the scores for fillers differed from the expected ones (2 for ungrammatical and 6 for grammatical) by more than 2 standard deviations, then the data of such respondents were deleted. After applying this procedure, the results of 2 participants were excluded.
Figure 3 shows the acceptability measures of human judgments. In contrast to perplexity, the higher the normalized score (y-axis), the most acceptable the sentence is. Consequently, the grammatical fillers receive high scores, and ungrammatical fillers are scored low. The acceptability judgments also reveal a significant difference between the singular and plural number of the suppletive nouns (p<.0001). However, the correlation is different: the singular nouns turn out to be more acceptable, while the plural nouns are almost as unacceptable as ungrammatical fillers. There is also a significant difference in the number of regular nouns (p<.01). The plural forms are more acceptable than the singular forms, but the singular forms are still more acceptable than ungrammatical fillers. There is no statistically significant difference in number for the nouns with suffix alternations (p>.05) and for the syncretic forms (p>.05). The syncretic forms, both in singular and plural, receive higher scores than other noun types. The other noun types are equally acceptable in singular number but differ in plural: the most acceptable are regular nouns, followed by forms with suffix alternations, and then by nouns with stem alternations.
Figure 3. Mean normalized acceptability scores for fillers and stimuli
Рисунок 3. Средние нормализованные оценки для филлеров и стимульных предложений

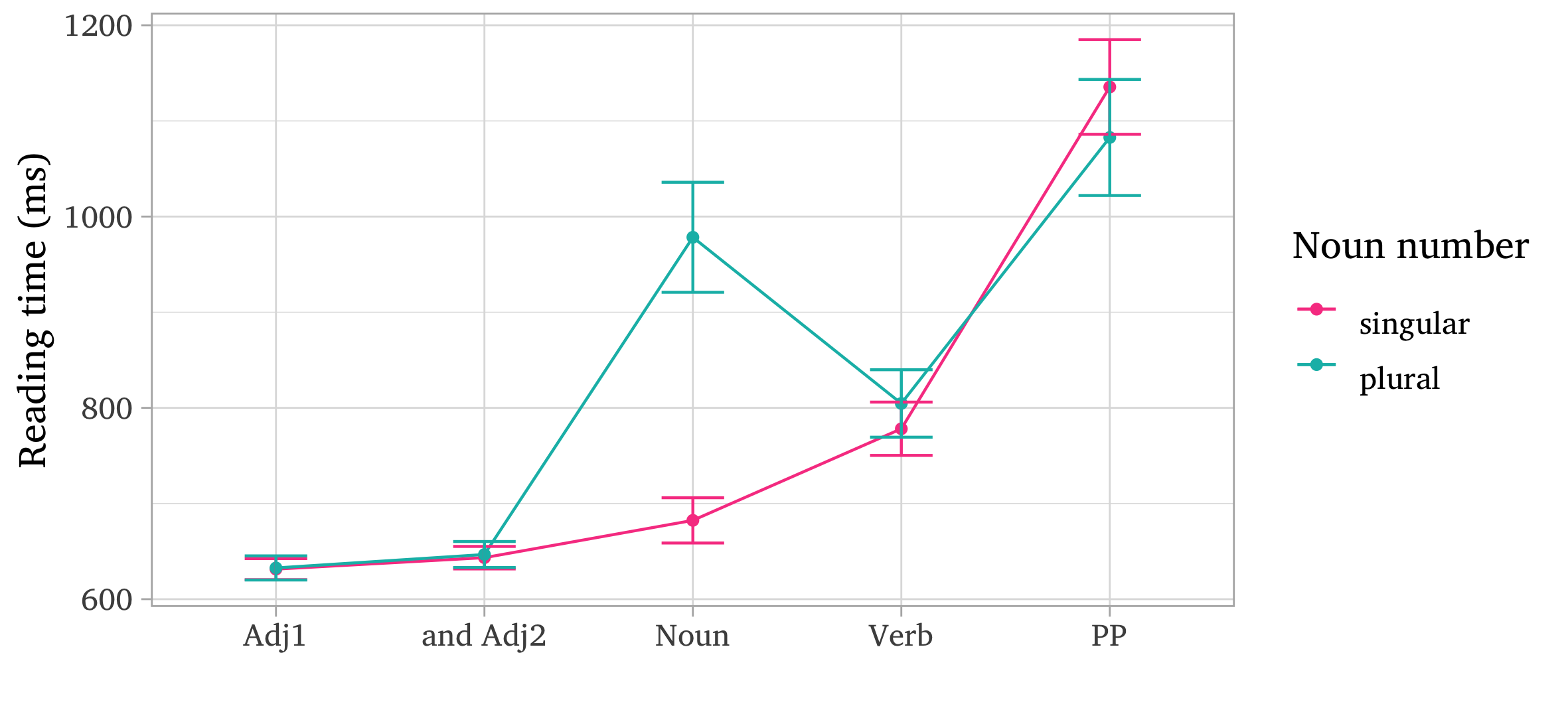
Figure 4 presents the results of the self-paced reading task for sentences with suppletion and stem alternations. The statistical analysis reveals a significant difference in reading time on the noun only for this morphological type (p<.01). Thus, the perception difficulties of plural suppletive forms are confirmed not only by low acceptability scores but also by reading delays.
Figure 4. Mean reading time for the suppletive nouns and the forms with stem alternations
Рисунок 4. Средние значения времени чтения для супплетивных существительных и форм с чередованием в корне
To summarize the results, we need to compare the predictions of the language model and the human judgments. Both perplexity values and normalized scores assign high acceptability to grammatical fillers and low acceptability to ungrammatical fillers. According to human judgments, nouns with stem alternations prefer singular number, resulting in higher acceptability scores and less reading time. The nouns with suffix alternations demonstrate free variation. So, stem rather than suffix alternation influences the number choice. The sentences with singularia tantum and pluralia tantum demonstrate the syncretism effect: they receive the highest scores and show no reading delay on the noun since there is no number choice needed. The ruGPT-3 language model also predicts the highest probability for syncretic nouns. Moreover, it assigns an equal probability for singular and plural forms of the nouns with suffix alternations and syncretic nouns. These results correspond with human acceptability judgments. However, ruGPT-3 fails to predict the preference for singular forms in sentences with suppletion and stem alternations.
In this section, we discussed the effect of noun morphology on the number variation in Russian noun phrases with coordinated modifiers. The impact of the syntactic context will be analyzed in the next section.
The impact of syntactic context on the number variation
According to S. Kodzasov (1987), the subject position and the plural predicate agreement cause the preference for the plural forms (15). This effect of syntactic context was also observed in the first experimental study described in the previous section. The regular plural forms were significantly more acceptable than singular nouns.
(15) atlantichesk-ij i tikh-ij okean-y slavjats’a
Atlantic-sg and Pacific-sg ocean-pl are_famous.pl
svo-imi uragan-ami
their-pl.instr hurricane-pl.instr
‘The Atlantic and Pacific oceans are famous for their hurricanes.’
The second study considered in this section deals with the effect of the syntactic context on the number variation. Specifically, we examine the attributive agreement of the premodifier. The study tested three factors: the premodifier number (singular/plural), the noun number (singular/plural), and the case of the noun phrase (direct/oblique). The stimuli were preceded by a context (16) to provide a split interpretation when each adjective characterizes its object. An example of a stimulus is presented in (17-18).
(16) prodavec predlozhil dva kostjum-a na vybor.
assistant.sg offer.pst two suit-pl for choice
‘The assistant offered two suits for choice.’
(17) Vanja primeril et-ot/ et-i sin-ij i
Vanja try_on.pst this-acc.sg/ this-acc.pl blue-acc.sg and
korichnev-yj kostjum/ kostjum-y v magazine-e odezhd-y.
brawn-acc.sg suit.acc.sg/ suit-acc.pl in store-loc.sg clothes-gen.sg
‘Vanya tried on these blue and brown suits in a store.’
(18) Vanja zaljubovalsja et-im/ et-imi sin-im i
Vanja admire.pst this-instr.sg/ this-instr.pl blue-instr.sg and
korichnev-ym kostjum-om/ kostjum-ami v magazine-e odezhd-y.
brawn-instr.sg suit-instr.sg/ suit-instr.pl in store-loc.sg clothes-gen.sg
‘Vanya admired these blue and brown suits in a store.’
It was noted in Russian that many structures are permissible only in the context of the direct case (Gerasimova, 2018). For instance, masculine nouns denoting female referents allow either masculine or feminine attributive agreement in the direct case (19a). In the oblique case, only masculine attributive agreement is possible (19b). Therefore, the direct case was expected to allow a number mismatch of the premodifier and the noun, while the oblique case was expected to disallow a number mismatch.
(19) a. nov-yj/ nov-aja vrach ann-a petrovn-a
new-sg.nom.m new-sg.nom.f doctor.nom.m Anna-nom.f Petrovna-nom.f
‘the new doctor Anna Petrovna’ (direct case)
b. nov-omu/ *nov-oj vrach-u ann-e petrovn-e
new-sg.dat.m new-sg.dat.f doctor.dat.m Anna-dat.f Petrovna-dat.f
‘to the new doctor Anna Petrovna’ (oblique case)
Figure 5 shows the mean perplexity values generated by the ruGPT-3 language model. As in the first study, the perplexity measures for the grammatical fillers are low, and the ungrammatical fillers receive high perplexity values. According to the language model, there is no significant difference in probability for the direct and the oblique case (p>.05). A statistically significant difference in probability occurs between singular and plural premodifiers for the singular noun (p<.01) but not between other conditions (p>.05). Thus, the sentences with plural premodifier and singular noun are the least probable, the sentences with singular or plural premodifier and a plural noun are more probable, and the sentences with singular premodifier and singular number are the most probable.
Figure 5. Mean perplexity values for fillers and stimuli
Рисунок 5. Средние значения перплексии для филлеров и стимульных предложений

In the experimental study, the results of 73 people were analyzed. The mean age of the respondents was 36 years (sd=13). There were 25 women and 48 men among the participants; 20 people whose profession is related to language (linguist, philologist), and 53 people who are not related to language by profession. Social networks VKontakte[10] and d3[11] were used to invite the respondents. Initially, 74 people took part in the experiment, but the data of one respondent was excluded. We used the winsorization method to search for outliers described in the previous section.
Figure 6 demonstrates the results of human acceptability judgments. As for the perplexity measures, the case does not influence the acceptability significantly (p>.05). Beyond that, the statistical analysis reveals a significant difference between all four agreement strategies (p<.01). The construction with the plural premodifier and the plural noun receives the highest scores and turns out to be the most acceptable. The combination of the singular premodifier and the plural noun is less acceptable. The acceptability of the singular premodifier and the singular noun is lower. The sentences with the plural premodifier and the singular noun are the least acceptable, which was also predicted by perplexity values.
Figure 6. Mean normalized acceptability scores for fillers and stimuli
Рисунок 6. Средние нормализованные оценки для филлеров и стимульных предложений

The mean reading time is illustrated in Figure 7. The results for self-paced reading reveal a significant reading delay (p<.05) on the plural noun (6th word) after the singular premodifier (3rd word). Although this experimental condition receives high acceptability scores, the reading delay can be attributed to the perception difficulties of the sentences with the singular premodifier and the plural noun.
Figure 7. Mean reading time for each word
Рисунок 7. Средние значения времени чтения по словам

We can now compare the results for the ruGPT-3 language model and the human judgments. As in the first study, the probability of the fillers meets our expectations: the grammatical fillers turn out to be highly acceptable, while the acceptability of the ungrammatical fillers is very low. According to the human acceptability scores, the premodifier number feature implies the same noun number feature. The highest scores were given to the sentences with the plural premodifier and the plural noun, as well as to the constructions with the singular premodifier and the singular noun. The number mismatch turns out to be acceptable for the plural noun. However, relatively high acceptability scores are accompanied by significant reading delays. The number mismatch is unacceptable for the singular noun, which causes low acceptability scores. Similarly, the language model predicts the lowest probability for the constructions with the plural premodifier and the singular noun. Besides that, ruGPT-3 assigns high probability to constructions with the same number of premodifiers and nouns. These results correspond with human acceptability judgments. However, the language model fails to predict the preference of the plural premodifier and the plural noun in contrast to the singular premodifier and the plural noun.
Conclusions
This paper considered the number variation in Russian noun phrases with coordinated modifiers. The coordinated singular adjectives with the split interpretation allow either singular or plural number feature for the head noun. The current study examined morphological and syntactic factors influencing the number choice in this construction. We have conducted two self-paced acceptability experiments to parametrize number variation and identified subtle differences in the acceptability of possible agreement strategies. Beyond that, we compared the results for human judgments with the perplexity values predicted by the neural ruGPT-3 language model. Since the language model was trained on a large amount of text, we expected that its measures will correspond with human judgments and it would predict the correct choice of agreement strategy.
The results of the study are as follows. According to human judgments, stem alternation significantly affects the choice of the number form and causes the preference for the singular number form. The attributive agreement also turns out to be significant since the number of the premodifier implies the same number feature of the noun. Even though the language model did not reveal these contrasts, the perplexity values predicted by ruGPT-3 partially correspond with human judgments. The syncretic forms singularia tantum and pluralia tantum receive the highest normalized scores and the lowest perplexity for their high acceptability and probability. The constructions with the plural premodifier and the singular noun receive the highest perplexity values and the lowest normalized scores, arguing their low acceptability and probability.
To summarize, the offline acceptability scores and the online reading time demonstrate that the observed morphological and syntactic factors are significant and should be considered while parametrizing number variation in Russian noun phrases with coordinated modifiers. The ruGPT-3 language model, trained on a vast collection of Russian texts, predicts the correct probabilities for highly acceptable and unacceptable sentences (both fillers and stimuli); however, it fails to assign correct probability values to the cases of variation.
[1] Pekelis, O. E. (2013). Sochinenie [Coordination], Materials for the project of Russian corpus grammar, Manuscript copyright.
[3] Drummond, A. (2013). Ibex Farm. http://spellout.net/ibexfarm/
[4] Zehr, J. and Schwarz, F. (2018). PennController for Internet Based Experiments (IBEX).https://farm.pcibex.net/
[5] R Development Core Team. (2009). A language and environment for statistical computing, R Foundation for Statistical Computing.
[6] Kuznetsova, A., Brockhoff, P. B. and Christensen, R. H. (2017). lmerTest package: tests in linear mixed effects models, Journal of statistical software, 82, 1–26.
[7] Lenth, R., Singmann, H., Love, J., Buerkner, P. and Herve, M. (2019). Emmeans: Estimated marginal means, aka least-squares means, R package version 1.4.5. https://cran.r-project.org/web/packages/emmeans/index.html
[9]https://www.jonsprouse.com/courses/experimental-syntax/scripts/7.4.identify.and.remove.outliers.R
Abbreviations
acc – accusative, adj – adjective, dat – dative, def – definite, instr – instrumental, f – feminine, gen – genitive, loc – locative, m – masculine, n – neutral, pst – past tense, pl – plural, sg – singular.
Благодарности
Исследование выполнено при финансовой поддержке Некоммерческого Фонда развития науки и образования «Интеллект».












Список литературы
Список использованной литературы появится позже.