
Выявление культурно обусловленных различий в значении слова с помощью трехъязычных векторных пространств: новый подход к аудиту LLM
Большие языковые модели (Large Language Models, LLM) всё чаще позиционируются как авторитетные посредники в передаче информации посредством текста, однако их способность сохранять культурно обусловленные лексические различия остаётся под вопросом. Эта проблема особенно остра в отношении ключевой лексики – высокочастотных, культурно значимых слов, формирующих концептуальный каркас языкового сознания конкретного сообщества. Если фундаментальные значения этих слов искажаются, возникающий семантический сдвиг может распространяться на последующие интерпретации, учебные материалы. Несмотря на реальность этой угрозы, надёжные методы оценки того, насколько LLM сохраняют культурно закреплённую лексическую семантику, остаются слабо разработанными.
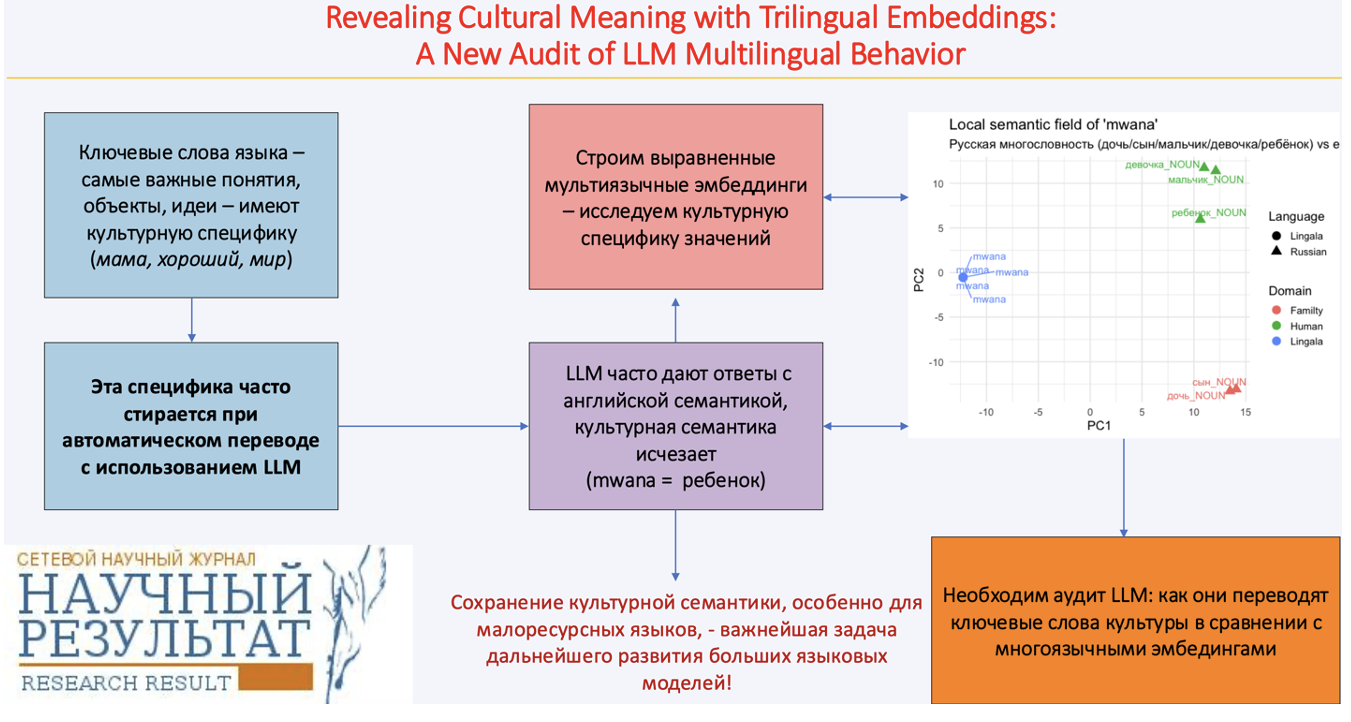
В данной статье предлагается новый диагностический подход к оценке LLM-текстов, основанный на трехъязычных выровненных векторных пространствах (эмбеддингах) для русского, французского языков и языка лингала. Путём приведения эмбеддингов в общее векторное пространство через прокрустово выравнивание мы получаем независимую семантическую систему отсчёта, сохраняющую внутреннюю структуру каждого языка. Французский язык выступает в роли высокоресурсного языка-пивота, что позволяет выполнять сопоставление, не вынуждая малоресурсный язык конкурировать с англоязычной или русскоязычной семантической геометрией.
Мы рассматриваем несколько культурно значимых лексем – термины родства и лексику с оценочной семантикой, чтобы показать, как сформированное нами выравненное векторное пространство может выявлять потенциальные зоны "семантического разногласия" между выдачей LLM и корпусно обоснованной семантикой. Хотя наши примеры не претендуют на установление систематической семантической предвзятости LLM ("английского семантического акцента"), они демонстрируют, как предложенная методология способна выявлять тонкие расхождения в представлении значений культурно значимых слов в разных языках и служить ориентиром для дальнейших исследований.
Мы утверждаем, что диагностика, основанная на эмбеддингах, является перспективным инструментом аудита многоязычного поведения LLM, особенно в контексте малоресурсных языков, чьи семантические категории рискуют быть поглощёнными семантикой английского языка. Настоящая работа очерчивает научную траекторию и призывает NLP-сообщество к более масштабным усилиям по защите языковой и культурной специфики в эпоху генеративного искусственного интеллекта.
Литвинова Т. А., Дехнич О. В. Выявление культурно обусловленных различий в значении слова с помощью трехъязычных векторных пространств: новый подход к аудиту LLM // Научный результат. Вопросы теоретической и прикладной лингвистики. 2025. Т. 11. № 4. C. 4–23.












Пока никто не оставил комментариев к этой публикации.
Вы можете быть первым.
Artetxe M., Labaka G. and Agirre E. A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), 2018. Pp. 789–798. https://doi.org/10.18653/v1/P18-1073(In English).
Bird S. (2020). Decolonising speech and language technology // Proceedings of the 28th International Conference on Computational Linguistics (Online). Barcelona, International Committee on Computational Linguistics. 3504–3519. https://doi.org/10.18653/v1/2020.coling-main.313(In English).
Blasi D. E., Anastasopoulos A. and Neubig G. Systematic inequalities in language technology performance across the world’s languages // Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, 2022. Volume 1: Long Papers, May 22-27. 5486–5505. DOI: 10.18653/v1/2022.acl-long.376 (In English).
Goddard C. and Wierzbicka A. Words and meanings: Lexical semantics across domains, languages, and cultures. Oxford University Press, 2013. https://doi.org/10.1093/acprof:oso/9780199668434.001.0001(In English).
Guo Y., Conia S., Zhou Z., Li M., Potdar S. and Xiao H. Do Large Language Models Have an English Accent? Evaluating and Improving the Naturalness of Multilingual LLMs // Annual Meeting of the Association for Computational Linguistics, 2024.https://doi.org/10.48550/arXiv.2410.15956(In English).
Joshi P., Santy S., Budhiraja A., Bali K. and Choudhury M. The state and fate of linguistic diversity in the NLP world // Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online. 2020. 6282–6293, https://doi.org/10.18653/v1/2020.acl-main.560(In English).
Li C., Chen M., Wang J., Sitaram S. and Xie X. CultureLLM: incorporating cultural differences into large language models // Proceedings of the 38th International Conference on Neural Information Processing Systems (NIPS '24), 2024. Vol. 37. Curran Associates Inc., Red Hook, NY, USA, Article 2693. 84799–84838. https://doi.org/10.52202/079017-2693(In English).
Litvinova, T. A., Mikros, G. K. and Dekhnich, O. V. Writing in the era of large language models: a bibliometric analysis of research field. Research Result // Theoretical and Applied Linguistics, 2024. Vol. 10 (4). Pp. 5–16. https://doi.org/10.18413/2313-8912-2024-10-4-0-1(In English)
Liu H., Cao Y., Wu X., Qiu C., Gu J. et al. Towards realistic evaluation of cultural value alignment in large language models: Diversity enhancement for survey response simulation // Information Processing and Management, 2025. Vol. 62. Iss. 4. https://doi.org/10.1016/j.ipm.2025.104099(In English).
Malt B. C and Majid A. How thought is mapped into words. Wiley Interdiscip Rev Cogn Sci. Nov., (2013). Vol. 4 (6). Pp. 583–597. https://doi.org/10.1002/wcs.1251 (In English).
Masoud R., Liu Z., Ferianc M., Treleaven P. C. and Rodrigues M. Cultural Alignment in Large Language Models: An Explanatory Analysis Based on Hofstede’s Cultural Dimensions // Proceedings of the 31st International Conference on Computational Linguistics. Abu Dhabi, UAE, Association for Computational Linguistics, 2025. 8474–8503. https://aclanthology.org/2025.coling-main.567/(In English).
Mikolov T., Chen K., Corrado G. and Dean J. Efficient estimation of word representations in vector space // 1st International Conference on Learning Representations (ICLR 2013), Scottsdale, Arizona, USA, May 2-4, 2013. Workshop Track Proceedings, 2013. https://doi.org/10.48550/arXiv.1301.3781(In English).
Mirko F. and Lavazza A. English in LLMs: The Role of AI in Avoiding Cultural Homogenization // Hacker P. (ed.) Oxford Intersections: AI in Society (Oxford, online edn, Oxford Academic, 20 Mar. 2025). https://doi.org/10.1093/9780198945215.003.0140. (In English).
Pistilli G., Leidinger A., Jernite Y., Kasirzadeh A., Luccioni A. S. and Mitchell M. CIVICS: Building a Dataset for Examining Culturally-Informed Values in Large Language Models // Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 2024. Vol. 7 (1). 1132–1144. https://doi.org/10.1609/aies.v7i1.31710(In English).
Qin L., Chen Q., Zhou Y., Chen Z., Li Y. et al. A survey of multilingual large language models // Patterns. 2025. Vol. 6 (1). 101118. https://doi.org/10.1016/j.patter.2024.101118(In English).
Ruder S., Vulić I. and Søgaard A. A survey of cross-lingual word embedding models // Journal of Artificial Intelligence Research. 2019. Vol. 65. Pp. 569–631. https://doi.org/10.1613/jair.1.11640(In English).
Wendler C., Veselovsky V., Monea G., and West R. Do Llamas Work in English? On the Latent Language of Multilingual Transformers // Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 2024. Volume 1: Long Papers. Bangkok, Thailand. Association for Computational Linguistics. 15366–15394. https://doi.org/10.18653/v1/2024.acl-long.820(In English).
Wierzbicka A. M. Semantics: Primes and Universals. UK: Oxford University Press, 1996. (In English).
Xing C., Wang D., Liu C. and Lin Y. Normalized word embedding and orthogonal transform for bilingual word translation // Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Denver, Colorado. Association for Computational Linguistics, 2015. Pp. 1006–1011. https://doi.org/10.3115/v1/N15-1104(In English).
Т.А. Литвинова благодарит за финансовую поддержку Министерство просвещения Российской Федерации (работа выполнена при финансовой поддержке Министерства просвещения Российской Федерации в рамках выполнения государственного задания в сфере науки, номер темы QRPK-2025-0013). О.В. Дехнич не получала финансовой поддержки за выполнение исследований, написание и публикацию статьи.