
Перцептивные характеристики слабых форм в китайском языке: омофония
Aннотация
Настоящее исследование нацелено на выявление особенностей восприятия некоторых слабых форм, сегментированных из китайской спонтанной речи и предъявленных на опознание вне широкого контекста. Эти формы возникли в результате естественных модификаций инициалей и финалей слога, а также стяжения слогов после выпадения элементов слога. В ходе ранее выполненного акустического анализа выявлено, что не только служебные, но и знаменательные китайские слова были реализованы в слабых формах. Согласно гипотезе данного исследования, некоторые из этих форм схожи с другими словами и сочетаниями слов в китайском языке, что является основанием для потенциальной омофонии. Для проверки гипотезы был проведён перцептивный эксперимент, материалом для которого послужили стимулы – потенциальные омофоны, сегментированные из спонтанной речи шести женщин, являющихся носителями языка. В эксперименте приняли участие две группы носителей китайского языка (20 мужчин и 20 женщин), перед которыми стояла задача прослушать и опознать стимулы. Полученные результаты полностью подтвердили выдвинутую гипотезу, поскольку в обеих группах лишь в 16% ответов пришлось на варианты с каноническими слогами, тогда как 84% ответов содержали варианты с омофонами. Была отмечена некоторая гендерная разница, однако для трёх четвертей данных она оказалась статистически не значимой – больше мужчин предпочли омофон каноническому слову/сочетанию слов. Как и ожидалось, надёжное опознание омофона зафиксировано в 64% случаев среди ответов, классифицированных как неопознание канонического слова/сочетания слов. Носители китайского языка осознают наличие омофонии, которая в ряде случаев развивается далее и приводит к изменению иероглифов и, следовательно, к образованию полных омонимов, которые нельзя не учитывать при обучении китайскому языку как иностранному.
Ключевые слова: Китайская спонтанная речь, Задание на распознание, Стимул, Омофон, Каноническое слово, Канонический слог, Слабые формы, Надёжное/ненадёжное восприятие
К сожалению, текст статьи доступен только на Английском
1. Introduction
Syllabic morpheme is a minimal pronunciation and meaningful unit in the Chinese language. According to Kasevich (2006: 524-525), it is the basic unit of the language unlike morpheme and word that occupy the periphery. Its graphic expression is hieroglyph or character that in its modern manifestation has lost its original iconic nature to a certain extent (although it is present in general) as it includes symbols that guide pronunciation (Shen, 2018: 133). Syllable is also a minimal (monosyllabic) word, and monosyllabic words are archetypal lexical units in Chinese.
Syllabic morpheme pronunciation can certainly vary, however, the patterns of this variation and variability extent are still far from being thoroughly investigated, although there are a few very successful studies in this field (see e.g. Tseng, 2005; Cheng and Xu, 2009).
Very few researchers have focused on the way naturally modified syllables (including contracted ones) are perceived. Thus, Tseng (2005: 159) reported that about 32% of 123,320 syllables studied were contracted – the result of work of professional human annotators whose task was to mark contractions and provide acoustic transcription. No perceptual studies of syllable phonemics natural modifications with non-linguist listeners have been performed.
At the same time, Chinese linguists admit (see, e.g., Fu and Li, 2018) that studying the ways language units are perceived is a vital experimental goal, however, mostly non-Chinese colleagues have succeeded in this realm so far. At present, more and more researchers make perceptual features the primary focus of their attention, and auditory experiment has become a crucial part of new technologies of linguistic research in China. There is a marked shift from studying canonical forms or full forms as a result of careful pronunciation to non-canonical or weak forms (including reduced or contracted forms) as a result of natural modifications in the speech flow where we can observe a combination of careful and careless pronunciation types whose proportion depends on many factors. In Russian, the theory of those types was developed by Liya Bondarko and her colleagues (Bondarko et al., 1974) based on Lev Shcherba’s earlier ideas first reported in 1915 and later published in the book of his Selected works (Shcherba, 1957).
Based on different languages, it was shown that in non-prominant positions in the utterance where coarticulatory pressures are very high, canonical phonemic patterns of words are subject to various consonant and vowel context-dependent quality changes and omissions giving way to weak forms, and by this, to co-existence of different phonetic and phonemic patterns of one and the same word in our mental lexicon (see e.g. (Jones, 1969; Zinder, 1981; Laver, 1994; Port, 2007; Babushkina, 2012; Androsova, 2015; Lobacheva and Androsova, 2016; Karavaeva, 2018; Priva and Strand, 2023)). Robert Port (2007) called it a very concrete, detailed auditory code (see also Borisova (2018) who mentioned native speakers using lexical coding that will definitely challenge Chinese as L2 learners’ perception by the slips of the tongue and wrong word use). However, the real challenge is not in wrong word use or the slips of the tongue but in connected speech processes that are part of the code. Mücke et al. (2017) analyzed multiple works studying connected speech processes as a result of regulation mechanisms during speech production and perception in a variety of languages including Arabic, English, French, German, Russian and some others.
For native speakers, weak forms are identifiable in a wider context in most instances. But when the context is minimal, weak forms (a word or its part) will be perceived in a different way (see Karavaeva (2018) experimenting with the perception of VCV tokens segmented from British speech flow).
As far as Chines, there is a whole war between those who consider that the Chinese syllable does not change its phonemics and boundaries (or if it does, the changes are minor enough for the canonical syllable to be be perceptually identified) and those who provide overwhelming evidence of the changes. Thus, Cao Jianfen (1992), based on the analysis of 200 Chinese neutral-tone syllables in the 2nd position in bisyllabic words, found that despite weakening of their intensity, shortening of their duration and neutralization of sound quality (consonant voicing, vowel neutralization to schwa etc), the original quality of a normal syllable is still perceptually identifiable due to relational invariance. However, high context sensitivity of the Chinese language from both perceptual and grammatical viewpoints determining the openness, flexibility and adaptability in speech (Wenzel, 2009: 124) casts doubt on the idea of identifying the syllable original quality, that has been naturally weakened, without a wider context, particularly if they resemble other Chinese syllables triggering homophony.
Chinese is a language where homophony is very extensive contrary to, e.g., English having little homophony (Huff, 2017). The reason, according to Huff, is in the number of unique syllables which in Chinese is about 7 times less than in English (around 1,200 vs around 9000, respectively). Huff identified three types of homophony: (1) identical phonemics + identical etymological tone, (2) identical phonemics but different etymological tone, and (3) identical phonemics + unspecified tone (for a number of reasons, one of them being the case of neutral/zero tone). These types can be united under the term “inherent homophony” or phonological homophony. In addition to inherent homophony, there is homophony that results from natural modifications in the continuous speech flow giving way to syllable reduction of various degrees. We will refer to such homophony as phonetic homophony. It is crucial to understand that homophony is a perceptual phenomenon that a research can prove during perceptual studies. It means that if during acoustic study we find certain naturally modified syllables that look like other syllables, we can interpret them as potential homophones, and only when perceptual evidence is obtained, we can classify them as phonetic homophones – the ones that resulted from syllable reduction.
Instances of Chinese syllable reduction are abundant. According to a number of researches (Tseng, 2005; Cheng and Xu, 2009; Burchfield, Bradlow, 2014), the amount of reduced syllables in Chinese is greater than in English, and the reason for this is that, unlike in English, most syllables in Chinese are open (73–75%), and open syllables are more subject to reduction than closed syllables. It means that the openness of the Chinese syllable increases its chances for reduction.
In one of our previous studies based on spontaneous female speech (Li, Androsova, 2022), we obtained some statistics on modifications of Chinese syllables (syllable = minimal word in Chinese) that contextually functioned as monosyllabic or united in disyllabic and trisyllabic words or formed word combinations that functioned as single phonetic complexes (all of them further referred to as items or tokens). First, we found that 481 unique items or 882 tokens including repetitions were involved in modification process resulting in weak forms. 105 items out of 481 had more than 1 weak form. Some of the weak forms were a result of a single modification (e.g., 1 instance of monophthonging or 1 instance of voicing, etc.) while others were a result of a series of modifications (e.g., omission + vowel quality reduction, etc.). Second, we obtained the proportion of word grammatical classes for the items in weak forms. It should be noted that, unlike in Indo-European languages, a word in Chinese does not have a permanent word-class label, instead, a particular context determines belonging to a particular word class. Among the 481 unique items having weak forms, only 148 were functional words while the majority of 333 words were notional words. However, if to consider repetitions, the proportion of functional and notional words was almost equal (470 and 412 tokens, respectively). The third finding was that contextually, among 148 unique functional words the majority (73) were adverbs (unlike in most Indo-European languages, adverbs in Chinese are considered functional words). Contextually, among 333 unique notional words the majority were nouns (149) and verbs (107) while adjectives, numerals and count words were the least frequent to be represented by weak forms – ten times less often (15, 13 and 12, respectively). Third, out of 882 instances of weak form use, 548 tokens preserved the canonical lexical tone while the remaining 334 tokens exhibited the change of canonical tone unrelated to tone sandhi but being a part of connected spontaneous speech processes. Mostly, it was the change to the neutral tone (in 302 tokens) but sometimes (in 32 tokens) Tone 1 was involved. Forth, as far as the number of syllables in the items, only 5 of them were monosyllabic words, the majority of 323 were disyllabic words, 121 items were trisyllabic words, and 32 were word combinations of 2 words (22 items), 3 words (8 items) and 4 words (2 items). The priority of disyllabic and trisyllabic words and word combinations over other patterns reflects the preference of disyllables and trisyllables for Chinese vocabulary (Arcodia, 2007; Xiao et al., 2009: 19, 40). We also found (Li, Androsova, 2022) that acoustically weak forms of some of the items resembled other Chinese words and word combinations.
All this brought us to hypothesize the following:
(i) single Chinese syllables and syllable sequences that undergo natural modifications in non-prominent position in the utterance in the natural speech flow might resemble other single syllables and syllable sequences giving way to potential homophony;
(ii) these potential homophones segmented from the speech flow would hardly be identified as canonical syllables or syllable sequences; without a wider context, listeners might perceive many of them as other syllables / syllable sequences.
To test the hypothesis, we carried out a perceptual study whose results will be presented in the following paragraphs.
2. Materials and Methods
To perform this research, we used a combination of 3 methods from different scientific fields – linguistics, acoustics and psychology. A set of 44 tokens, or stimuli, (1 monosyllabic word, 31 disyllabic sequences and 12 sequences of three and four syllables) was constructed as testing material. The tokens were segmented from spontaneous monologues of 6 female Mandarin Chinese speakers aged 20-30 who volunteered to participate in the experiment for free. None of the subjects reported of any speech or hearing disorders, nor did any of them have any acoustic or phonetic knowledge. The recordings were made by the authors of this paper in the period of 2018–2019, in a quiet room at the frequency rate of 44000 Hz, 16-bit sampling rate, mono. At the first stage of the experiment, an acoustic study was carried out using PRAAT, version 6.0.05[1]. The segmentation was performed using audivisual control on the dynamic spectrogram. During the acoustic study, the above-mentioned tokens were segmented. The reason for including the 44 tokens into the set was their naturally induced modification due to non-prominence in the speech flow (see more on prominence due to highlighting and chunking in (Cangemi, Baumann, 2020)) that resulted in potential homophony with other Chinese syllables / syllable sequences. The modifications were classified into three types taking into account the specifics of syllable status and syllable structure in Chinese:
Type 1 – initials (syllable-initial consonants) substitutions due to e.g. voicing and some other processes;
Type 2 – finals (vowel or vowel + n/ŋ part of the syllable) with vowel quality change as well as nasal locus change;
Type 3 – initials and finals omissions including the instances that lead to severe syllable reduction (=contraction and further coalescence).
It is necessary to make a few comments on the procedure of identifying the instances of consonant (Type 1) and vowel (Type 2) quality change. Acoustically, this change is reflected in (i) noise configuration and noise location change for consonants and (ii) formant frequency change for vowels. Some of these changes are slight variations while others are big enough to cause a phonemic change in languages like English (Cruttenden, 2001) and a syllable constituent (consonant or vowel) change for Chinese being aware of the fact that there are no phonemes in Chinese in the sense they are viewed in Indo-European languages.
At this point of Chines phonetic studies, almost no parameter-value-based generalized results have been reported so far in the linguistic literature on acoustic cues of consonant changes and vowel formant changes in non-prominent parts of an utterance compared to its prominent parts. To the best of our knowledge, the only study in the field of consonants is the one of Rao and Shaw (2021) focusing on the acoustic cues of velar-labial merger of [x]-[f] in Zhongjiang Chinese (Southwestern Mandarin). As far as Chinese vowels, even the data on the vowel formant values are rare: Meng et al. (2006) provided the averages for 5 formants (F1-F5) and standard deviations from those (a statistical study based of 212 female and 126 male subjects trained for broadcasting), Wang et al. (2020) targeted at building the vowel quality acoustic space in terms of F1 (vowel raising-lowering) and F2 (vowel advancement-retraction), Gu et al. (2003) measured F1 and F2 for 5 vowels in a carrier sentence each in 2 positions – focused and neutral. All the three studies involved only clearly pronounced monophthongs but obtained no averaged data for F1 and F2 in the flow of speech. The only work addressing the issue of modification acoustics is the one of (Tseng, 2005) where he pointed to F1-F2 raising/lowering, the absence of standard cues in cases of vowel and consonant deletion and the energy redistribution on dynamic spectrograms for some cases of consonant modifications.
Therefore, our decisions on identifying a consonant and vowel constituent change dwelt upon comparing (i) a naturally modified consonant spectrum with canonical spectral energy distribution of a consonant in terms of frequency, duration and intensity, (ii) F1-F2 averages measured in prosodically prominent utterance parts for clearly pronounced vowels with F1-F2 averages measured in prosodically non-prominent parts with fast speech rate and no sentence stress where the vowels were naturally modified.
Types 1-2 change the so-called phonemics of the canonical syllables while Type 3, often accompanied by Types 1-2, can change the number syllables in the sequences (Li, Androsova, 2019). We will interpret the syllables undergoing any of the modification types as weak forms.
The tokens were 14 functional words (e.g. 但是 /tanȿi/ 'but', 虽然 /sueiʐan/ 'although' etc) and 30 notional words including word combinations of notional words with functional words (e.g.喜欢 /ɕixuan/ 'like', 阴暗 /jin'an/ 'dark', 考完 /kɑuwan/ 'after exam', 如果你有 /ʐukuonijou/ 'if you have' etc). The notional words represented different word classes (nouns, verbs, adjectives etc).
The stimuli were randomized and given to 2 groups of volunteer listeners who were native Chinese speakers (20 males, 20 females, aged 20–23, 3d-year students of Musical Department of Shanxi Datong University, all of them having either 2nd or 3d level certificate of Putonghua – Mandarin Chinese Standard). We informed the listeners that the stimuli had been segmented from Chinese speech.
Each listener received a questionnaire with 44 questions (according to the number of tokens). To each question, 3 options were offered as answers: target token (canonical syllable / syllable sequence) and 2 potential homophones: first homophone represented actual realization of the syllable / syllable sequence, second was a variant acoustically close to the first potential homophone. We limited the number of listenings to 3 for each token. During the experiment, there were 3 failures to perform the task, and in 2 instances the listeners ignored the options and offered their own variant. Therefore, the real total number of reactions was taken as 100%.
As a result, 1758 listeners’ reactions were obtained. The data was further processed and the reactions were distributed into 2 groups: 1) more than 50% identification of canonical syllable sequence (target token) including reliable canonical syllable / syllable sequence identification by 70% of listeners or more; 2) 50 or more percent of homophones identification including reliable homophones identification by 70% of listeners of more. 50% value was considered as absolute impossibility to discriminate between canonical syllable / syllable sequence and homophone syllable / syllable sequence. Reactions belonging to the second group were interpreted as non-identification of the canonical syllable / syllable sequence.
Table 1[2] shows the distribution of the reactions. Group 1 comprised less than 16% of all reactions, the remainder formed group 2 – 84%.
Table 1[3]. Potential homophones perception by Chinese listeners
Таблица 1. Восприятие потенциальных омофонов носителями китайского языка
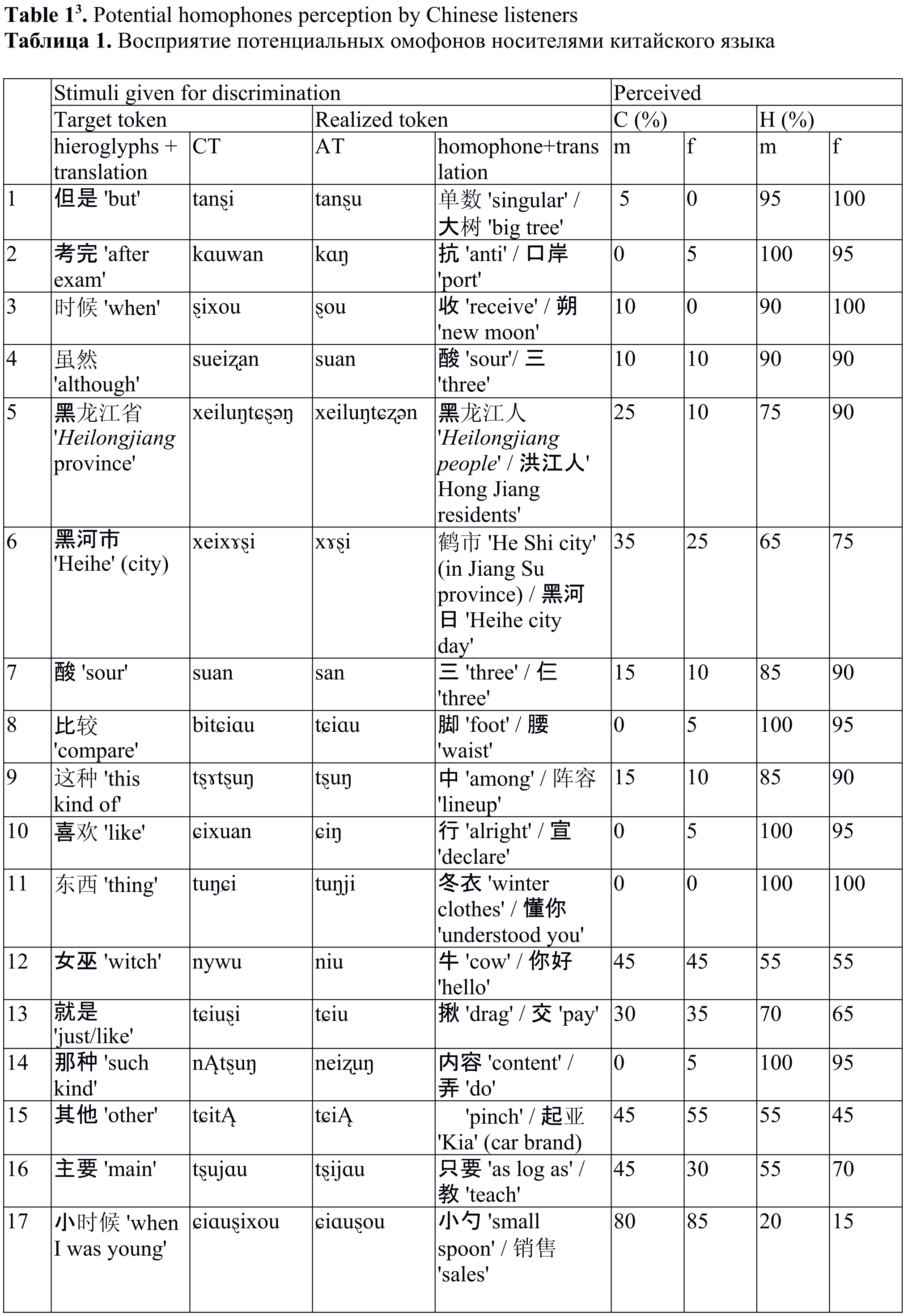
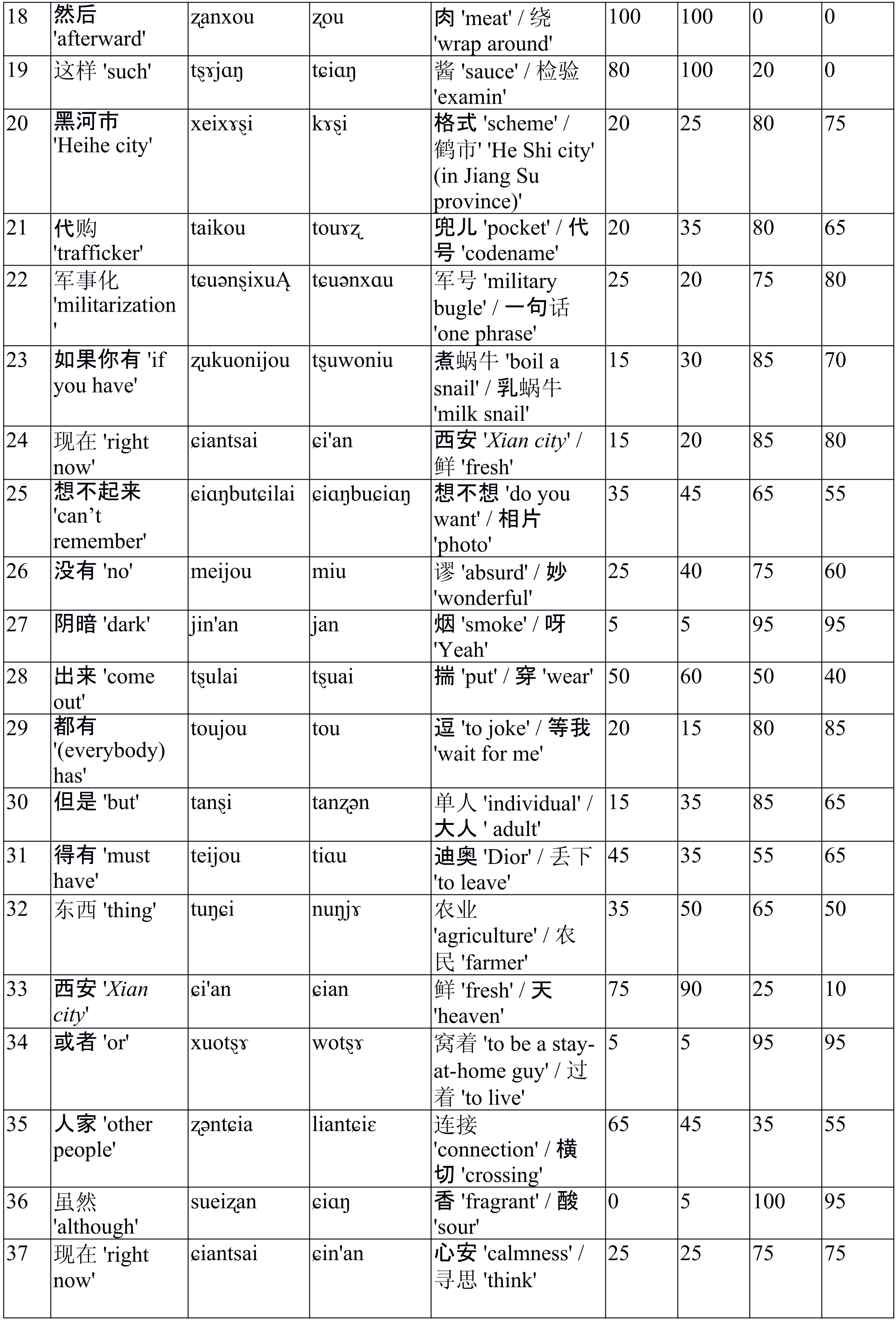

Note to Table 1: C – canonical word/word group, H – homophones, CT – Canonical transcription (IPA), AT – acoustic transcription. Pinyin transfer in to IPA symbols is performed in accordance with the table of matches[4].
The proportion of canonical reactions vs homophone 1 + homophone 2 displayed certain gender differences (3 reactions or more, 7-15% in fact). In particular, the differences were, first, in the cases where homophones prevailed – the degree of prevalence was different for tokens 5, 16, 21, 23, 26, 30, 39. For token 33 with the prevalence of canonical reactions, the degree of prevalence was also gender-specific. Third, for token 28, males demonstrated impossibility to differentiate between the canonical token and the homophone while females preferred the canonical token, however, for token 32 it turned out vice versa; males interpreted token 35 as the canonical one and females – as the homophone. In addition, males gave more canonical reactions to tokens 5, 16, 35, 39 while females gave more canonical reactions to tokens 13, 19, 21, 23, 30, 32, 33 (the difference of 3 reactions or more).
Table 2[5] shows details on each of the 2 homophones perception in absolute values.
Table 2. Details of homophones perception (absolute values)
Таблица 2. Детализация по восприятию омофонов (в абсолютных единицах)
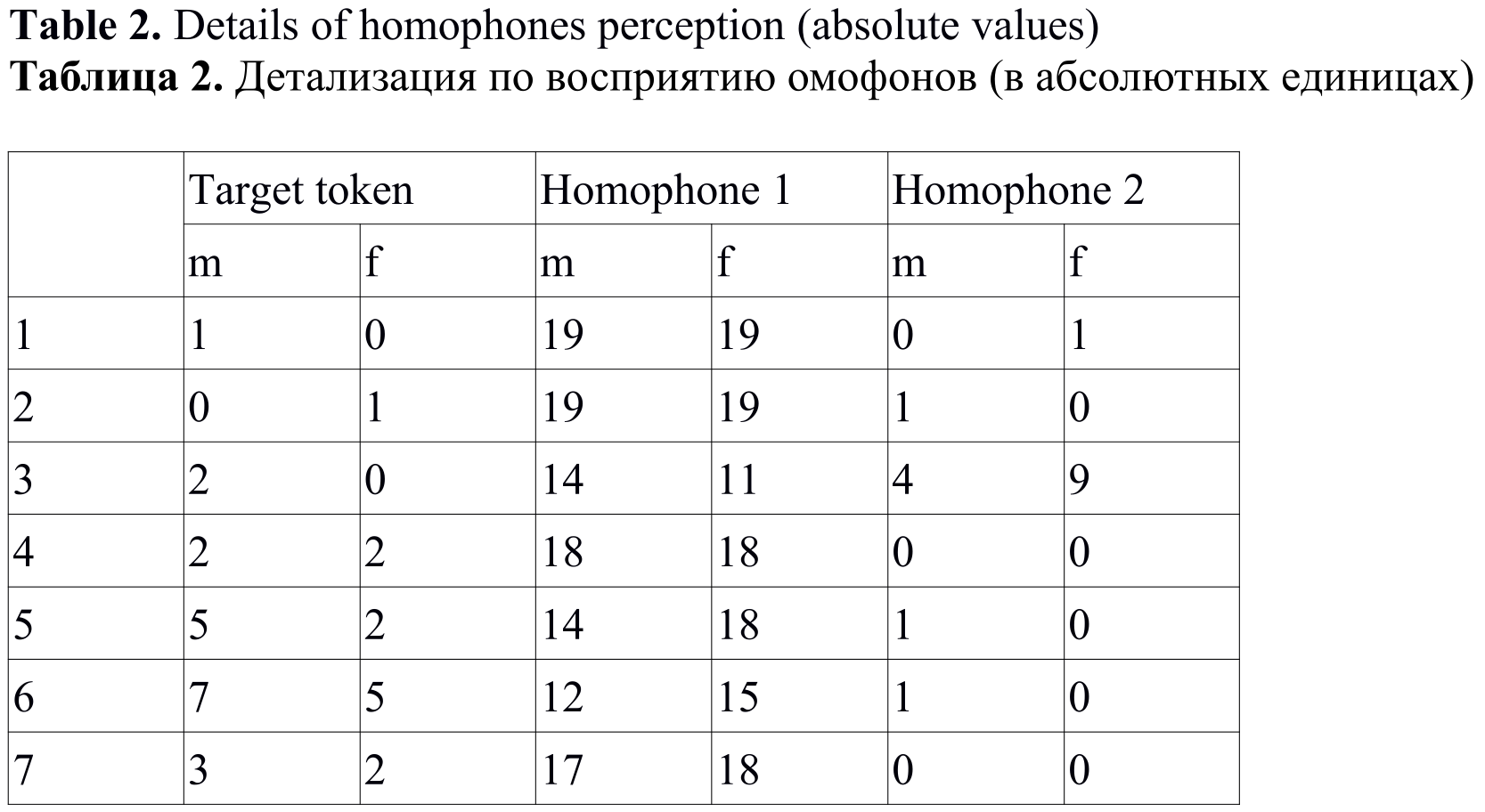
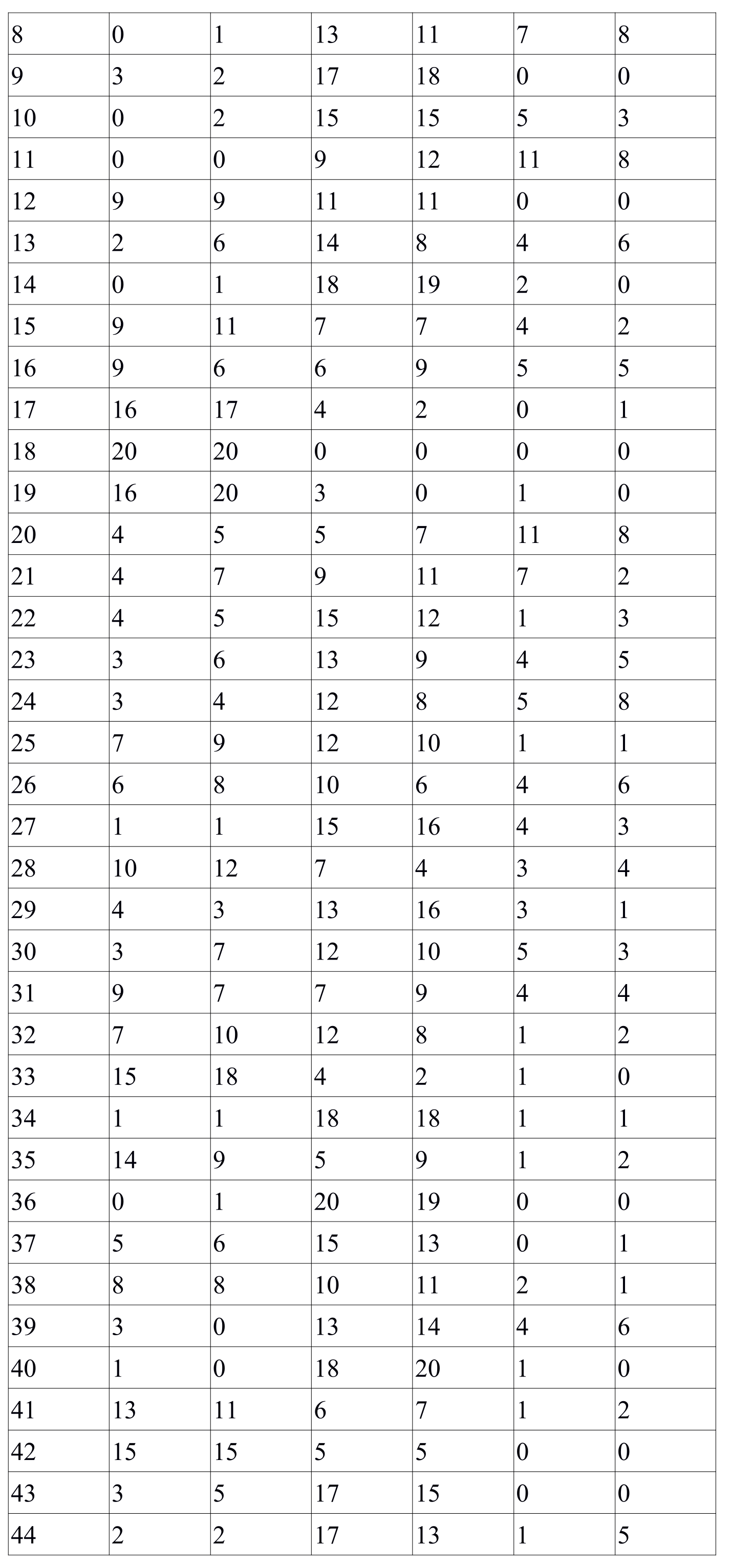
It was discovered during the data analysis that there were instances when males preferred 1st homophone, while females tended to choose 1st and 2nd homophone in equal proportion (tokens 3, 13, 24 and 28 in Table 2). The contrary result was obtained for tokens 16 and 21 where females preferred 1st homophone, while males chose homophone 1 and homophone 2 in equal proportion. Only 1 case was found when males gave preference to homophone 2 (token 20), while female preferences for homophone 1 and homophone 2 were distributed equally. For tokens 23 and 41, both males and females preferred 1st homophone to 2nd homophone, but the preference was higher with males compared to females.
The significance of these gender differences was tested using chi-square test and Fisher’s test. About 10% of the data turned out to demonstrate very significant gender differences and about 15% – significant differences. Thus, about ¼ of the data show significant gender difference, while ¾ of the data show insignificant difference or no difference whatsoever.
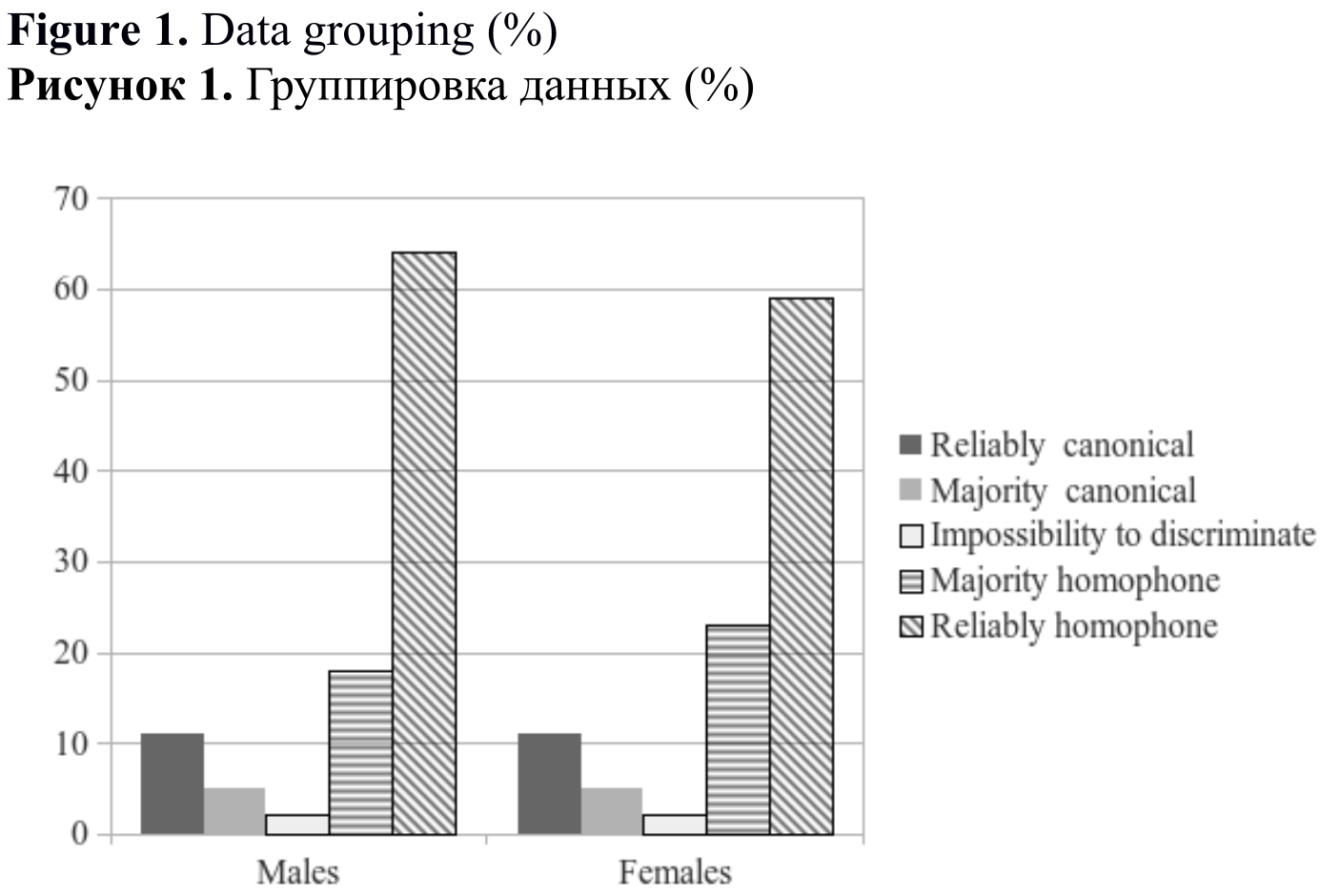
Here we are presenting the descriptive statistics on Group 1 (identification of canonical syllable by the majority – more than 50%) and Group 2 (non-identification of canonical syllables – 50% or less). 16% of male responses appeared in Group 1 (7 tokens out of 44). Reliable identification, i.e. by the vast majority (70% and more), accounted for 11% out of 16%. Non-identification of canonical syllables accounted for 84% of male responses – 37 out of 44 tokens were not identified as normal canonical syllables / syllable sequences therefore they were distributed into Group 2. Within this group, three subgroups were formed: reliable identification (≥70%) – 64%, identification by the majority (>50% but <70%) – 18% and absolute impossibility to discriminate between canonical syllable / syllable sequence and homophone syllable / syllable sequence (=50%) – 2%.
As far as the female listeners, the number of responses distributed into Group 1, Group 2 and to the subgroup of reliable responses within Group 1 was the same as for the males. However, the distribution within Group 2 was different. The number of reliable responses was lower: 59% (vs 64% with male listeners) account for reliable identification, other majority responses accounted for 23% (vs 18% with male listeners). There was no difference as far as absolute impossibility to discriminate between canonical tokens and homophone tokens. Table 3[6] and Figure 1[7] show the distribution into the 5 subgroups. Although the details are a little different, the distribution pattern is clearly similar.
Table 3. Data grouping (%)
Таблица 3. Группировка данных (%)

Figure 1. Data grouping (%)
Рисунок 1. Группировка данных (%)
4. Discussion
This study showed the results contrary to Cao Jianfen (1992) as the original quality of a normal syllable in our experiment was not perceptually identified for 84% of the tokens which is the vast majority. There might be several reasons for such an outcome. Firstly, the corpus for our study included only potential homophones that emerged as a result of naturally induced modifications. No homophony was reported by Cao Jianfen. Secondly, all stimuli in the experiment of 1992 were bisyllabic sequences, but among our tokens there were also 3 and 4 syllable sequences and one monosyllablic token. Thirdly, due to the fact that our tokens occurred in spontaneous monologues and tokens for the 1992 experiment were syllables from neutral type bisyllabic words (2nd position), relational invariance that Cao Jianfen insisted upon did not work in our case.
There is nothing surprising in the obtained results of our perceptual study. All the 44 tokens are plausible candidates for homophony as they were naturally reduced to differing extents (whether it is a consonant / vowel change or syllable merger as a result of omissions and further vowel and/or consonant change) in favor of articulatory convenience triggered by context sensitivity characteristic for the Chinese syllable and speech rapidness. Below, we can see the classes of modifications exemplified by the tokens from Table 1.
1. Consonant substitutes (Table 1, tokens 2, 5, 11, 39):
– terminal [n] → [ŋ] or [ŋ] → [n], e.g.:
a) [n] → [ŋ] 考完 'after exam' /kɑuwan/ → [kɑŋ] (forelingual nasal → velar nasal);
b) [ŋ] → [n] 黑龙江省 'Heilongjiang province' /xeiluŋtɕȿəŋ/ → [xeiluŋtɕʐən] (velar nasal → forelingual nasal);
– sonantization of initials:
[ɕ] → [j] e.g. 东西 'thing' /tuŋɕi/ → [tuŋji] (fricative → glide);
– occlusion weakening and voicing:
[tȿ] → [ʐ] e.g. 这个 'this' /tȿɤkɤ/ → [ʐɤĄ] (voiceless affricate → voiced fricative in initial of the 1st syllable).
2. Vowel substitutes (Table 1, tokens 1, 7, 14, 16, 40, 44):
– monophthong-to-monophthong or diphthong-to-diphthong (front to back as well as back to front vowel finals):
[i] → [u] e.g. 但是 'but' /tanȿi/ → [tanȿu] (2nd syllable, front to back);
[u] → [i] e.g. 主要 'main' /tȿujɑu/ → [tȿijɑu] (1st syllable, back to front);
– monophonging of diphthong:
[ua] → [a] e.g. 酸 'sour' /suan/ → [san];
– diphthonging of monophthons:
[Ą] → [ei] e.g. 那种 'such kind' /nĄtȿuŋ/ → [neiʐuŋ] (1st syllable);
[i] → [ou] e.g. 所以 'and so' /suoji/ → [suojou] (2nd syllable);
[ɑu] → [u] e.g. 就要 'is going to' /tɕiujɑu/ → [tɕɑuju] (2nd syllable).
3. Whole syllable omission (Table 1, tokens 43, 29) e.g 学校 'school' /ɕyɛɕiɑu/ → [ɕiɑu] (1st syllable drop), 都有 '(everybody) has' /toujou/ → [tou] (2nd syllable drop).
4. Syllable parts (consonants, vowels) omissions with further liaison: 考完 'after exam' /kɑuwan/ → [kɑŋ], 时候 'when' /ȿixou/ → [ȿou], 虽然 'although' /sueiʐan/ → [suan] (Table 1, tokens 2–4).
There are instances when contracted syllables may be conventionalized or lexicalized by a fixed character in the written form (Tseng, 2005: 154). At present time, such processes start in social networks – 15 neologisms of this kind (Li, 2020) were found in Chinese online Encyclodedia Baidu (http://www.baidu.com/).
This naturally induced variability created homophony identified in the tokens. The same processes are abundant in spontaneous speech flow, and when they do not trigger homophony, the normal canonical syllable might be identified due to the relational invariance advocated by Cao Jianfen (1992). In any case, no matter leading to homophony or not, naturally-induced modifications have to be identified and classified, the occurrences of a particular modification class have to be calculated, and the distribution of different classes of modifications must be revealed. The study of syllable phonemics changes initiated by (Tseng, 2005) is getting more support (Cheng and Xu, 2009; Burchfield and Bradlow, 2014) including specialists in creating models for continuous Chinese speech recognition who use context-dependent data (Hao Wu, Xihong Wu, 2007), but these issues are still far from being thoroughly studied.
Literature analysis has shown that Chinese weak forms study is still in its infancy. To the best of our knowledge, no previous research has focused on the perceptual perspective to test the hypothesis that naturally induced modifications of Chinese syllables can result in homophony or even homonymy that listeners cannot resolve in narrower context.
This multidisciplinary study was performed using a combination of acoustic, perceptual and traditional linguistic methods. The obtained results of 84% of non-identification of canonical syllables bring an important insight into the common patterns of human linguistic behavior whose integral part are weak forms. Neglecting careful articulation in those parts of utterances that lack prosodic prominence due to the lack of informativeness is a common strategy for the speaker as far as it gives an opportunity to make important parts of the utterances more prominent, more carefully articulated. It enables the listener to base on these prominent, carefully articulated parts to rebuild the utterance despite phonetic losses in non-prominent parts.
Native speakers and listeners develop this ability during their lifetime interaction in the language environment. Therefore, it is a certain implication for Chinese as L2 teaching methods as well. There is a vital need to identify and collect common weak forms and include them in practical courses of developing listening and speaking skills to provide adequate interaction between speaker and listener characteristic for native speakers.
[1] Boersma, P. and Weenink, D. (2015). Praat: Doing phonetics by computer [Computer program], (version 6.0.05), available at: http://www.fon.hum.uva.nl/praat/ (Accessed 16 November 2015) (In English)
[2] This is the unpublished material of Li Yifang’s Ph.D. dissertation prepared under the scientific supervision of Svetlana V. Andosova (Li, 2022).
[3] Tables 1–3 and Figure 1 are designed by authors.
[4] Baidu venku (百度) [Chinese online encyclopedia], available at: http://www.baidu.com/ (Accessed 20 December 2019) (In Chinese)
[5] This is the unpublished material of Li Yifang’s Ph.D. dissertation prepared under the scientific supervision of Svetlana V. Andosova (Li, 2022).
[6] This is the unpublished material of Li Yifang’s Ph.D. dissertation prepared under the scientific supervision of Svetlana V. Andosova (Li, 2022).
[7] This is the unpublished material of Li Yifang’s Ph.D. dissertation prepared under the scientific supervision of Svetlana V. Andosova (Li, 2022).
Благодарности
Авторы выражают благодарность Амурскому государственному университету и Лаборатории экспериментально-фонетических исследований за техническую поддержку данного исследования.












Список литературы
Список использованной литературы появится позже.