
Письмо в эпоху больших языковых моделей: библиометрический анализ предметного поля
Aннотация
Появление и бурное развитие больших языковых моделей и чат-ботов, наблюдающееся в последние два года, кардинально изменило практику письма. Цель этой редакционной статьи – провести библиометрический анализ междисциплинарной области исследований, связанных с различными аспектами письма в эпоху больших языковых моделей (LLM). Поиск был проведен в библиографической базе данных Scopus в декабре 2024 года с использованием следующего запроса: (“large language model*” OR “LLM” OR “*GPT”) AND "writing". Мы включили в анализ исследования, опубликованные с 2020 года, и ограничили наш поиск статьями, материалами конференций, книгами и главами книг. Поиск дал 1629 документов. Полученные записи были проанализированы с использованием R-пакета bibliometrix и программного обеспечения VOSviewer. С использованием данных инструментов нами были определены наиболее продуктивные и цитируемые исследователи, институты и страны, а также наиболее значимые работы. На основе различных методов анализа совместной встречаемости ключевых слов, реализованных в данных инструментах, нами была построена концептуальная структура предметного поля, а также определены исследовательские тренды. Мы пришли к выводу, что темы, связанные с авторством и плагиатом в академическом письме, проблемами обучения второму языку, включая автоматизированную оценку текстов на иностранном языке, вопросами креативного письма в эпоху LLM, являются наиболее популярными темами, находящимися в фокусе внимания исследователей.
Ключевые слова: Большие языковые модели, ChatGPT, письмо, Библиометрический анализ, Библиотека bibliometrix на языке R, VOSviewer, Scopus, Ключевое слово
К сожалению, текст статьи доступен только на Английском
1. Introduction
Large language models (LLMs) represent sophisticated artificial intelligence systems that are engineered to process and generate natural language. These models are constructed using deep neural network architectures and are trained on extensive corpora of text, allowing them to discern patterns in language usage and generate coherent responses. The advent of LLMs has had a substantial impact on the writing practices and the academic study of writing.
The objective of this editorial paper is to systematically analyze the literature related to the study of writing in the context of LLMs through the application of a bibliometric approach. This analysis seeks to identify the most prominent countries, sources and institutions as well as key topics and emerging trends within the examined research field.
We conducted a bibliometric analysis of scholarly articles that examined writing within the context of LLMs, utilizing the Scopus database. The research was conducted using the R package bibliometrix (Aria and Cuccurullo, 2017) in conjunction with the standalone application VOSviewer (Van Eck and Waltman, 2014). This bibliometric analysis encompasses a total of 1629 articles published over the past four years (2020-2024) and represents the first effort to provide statistical insights into the research status and trends regarding the use of LLMs in various aspects of writing.
2. Methods
The search string utilized in the title, abstract, and keyword sections of the article fields for data extraction from Scopus was as follows: (“large language model*” OR “LLM” OR “*GPT”) AND “writing”.
The data collection process for this study was conducted on December 21, 2024. Since 2020, there has been a notable increase in the number of published papers, with more than five papers published annually, in contrast to only two papers published in 2018. As a result, we selected for further analysis those papers published between 2020 and 2025. Furthermore, we focused on specific types of publications, which include: 1) articles; 2) conference papers; 3) book chapters; 4) books.
A total of 1,629 documents were retrieved from this search.
For the purpose of further analysis, all accessible bibliographic information for the 1,629 retrieved records was extracted from Scopus and exported in both CSV and BibTeX formats.
3. Results and Discussion
3.1. General structure of the collection
The field of writing within the context of LLMs has undergone considerable evolution over the past two years, as depicted in Figure 1. Specifically, 42 papers were published in 2022, followed by 468 in 2023, and over 1,000 papers published in 2024.
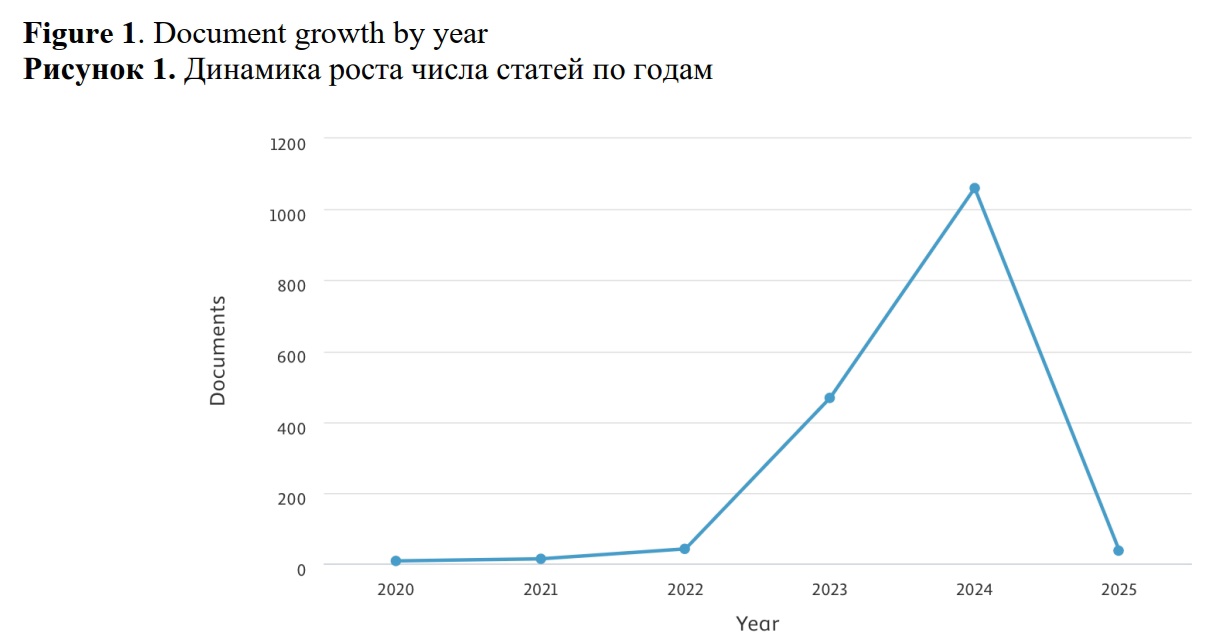
More than half of the papers consist of articles (57,2 %), while over a third of the collection comprises conference papers (39,2%). The remaining contributions include book chapters and books.
The majority of the papers in our collection are published in journals and conference proceedings that align with the domains of computer science and social science (see Figure 2), thereby highlighting the interdisciplinary nature of the field.

3.2. Most relevant sources
The most pertinent sources specifically those with the highest volume of publications pertaining to writing in the context of LLMs, are illustrated in Figure 3. This figure additionally depicts trends in publication dynamics, revealing a distinct overall increase in the number of papers associated with each publication source.

It should be noted that the Conference on Human factors in Computing systems has the highest impact factor within the collection (H index = 10). The ACM Proceedings and Proceedings of the Annual Meetings of the Association for Computational Linguistics rank second (H index =6).
3.3. Leading countries and organizations
In the analyzed domain, several countries and universities emerge as leaders both in the volume of published papers and the number of citations. Notably, the United States, China, and the United Kingdom are identified as prominent contributors (see Figures 4-5). It is important to highlight that while the United States leads in both productivity and citation metrics, China ranks fourth in citation count but second in the number of papers. United Kingdom and India have less paper published than China, but they garnered a higher number of citations. National Science Foundation is the foremost funding agency, having supported 60 papers, while other U.S. agencies, including Department of Defense and Department of Health and Human Services collectively funded an additional 30 papers. Furthermore, two Chinese funding bodies, namely the National Natural Science Foundation of China and the Ministry of Science and Technology of the People’s Republic of China, collectively supported more than 100 papers.

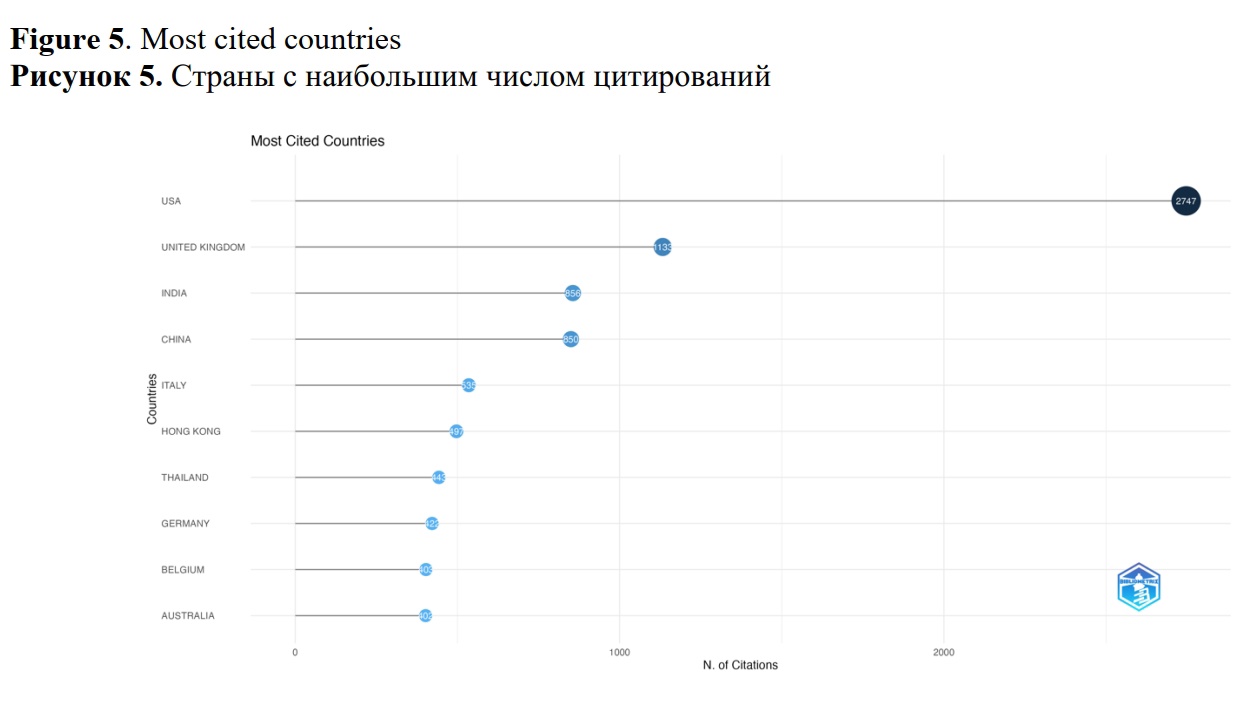
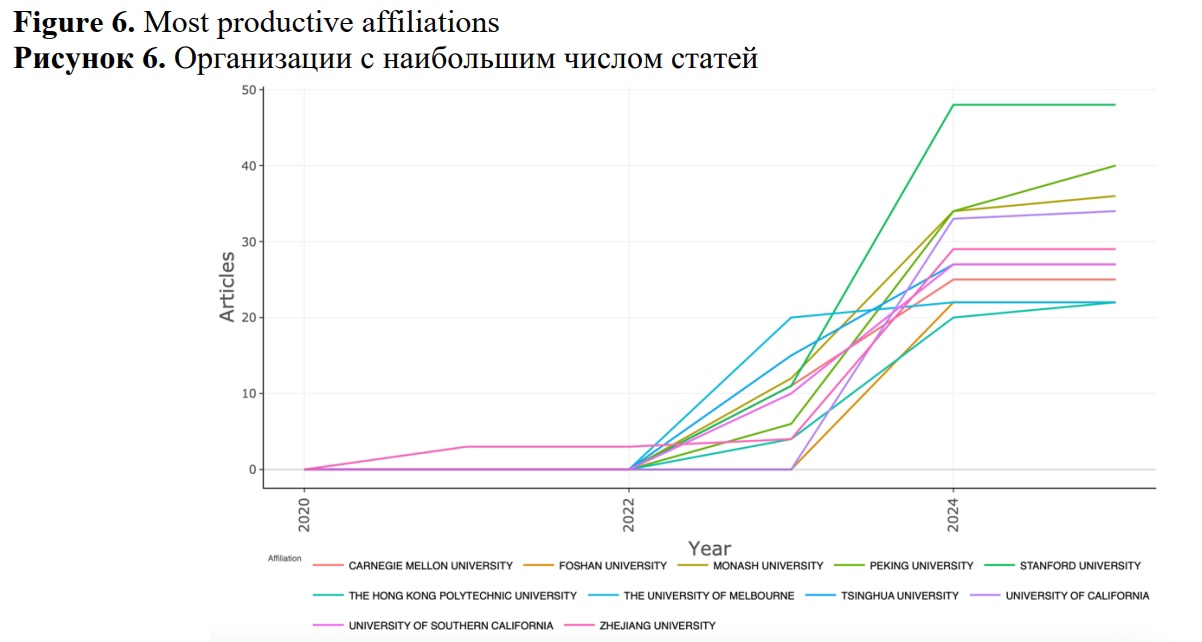
Figure 6 illustrates the most productive organizations in terms of research output. Notably, there is a general trend indicating increase in the number of publications across all organizations beginning in 2023. Among these, the leader – Stanford University – exhibits most pronounced upward trajectory publication volume.
3.4. Highly cited publications
The most frequently cited document within the collection as indicated by Global Citations Metrics which means the total citations that an article, included in the collection, has received from documents indexed in the bibliographic database (Scopus in our case) is “Chatting and cheating: Ensuring academic integrity in the era of ChatGPT” with more than 600 citations (Cotton et al., 2023). This paper explores the opportunities and challenges associated with the utilization of ChatGPT in higher education, while also addressing the potential risks and benefits of these tools. Furthermore, study examines the complexities involved in detecting and preventing academic dishonesty.
The paper that examines the potential applications and limitations of LLMs in healthcare is the second most cited document in our collection, with a total of 471 citations (Cascella et al., 2023). Other highly cited papers on a global scale address various topics, including the utilization of AI chatbots in scientific writing (Salvagno et al., 2023), the progressive workflow processes associated with the ChatGPT tool (Haleem et al., 2022), university students’ perceptions of generative AI (GenAI) technologies, such as ChatGPT, within the context ofhigher education (Chan et al., 2023). Additionally, the paper with considerations regarding the academic integrity related to students’ use of AI tools employing Large Language Models (LLMs), such as ChatGPT in formal assessments are highly cited (Perkins, 2023). A systematic review for an up-to-date examination of artificial intelligence (AI) in higher education (Crompton and Burke, 2023) is also among highly cited papers of the collection as well as the paper which presents the results of topic modeling of the tweets about ChatGPT during its initial post-launch (Taecharungroj, 2023). Among highly cited papers there are publications which compare scientific abstracts generated by ChatGPT with actual abstracts (Gao et al., 2023), discusse Codex, a deep learning model trained on Python code that generates solution code in response to natural language input (Finnie-Ansley et al., 2022).
The most frequently cited document of the collection defined by local citation metrics, which refer to the number of citations received by a reference article internally to the collection itself, examines the potential benefits and risks associated with ChatGPT and other NLP technologies in the context of academic writing and research publications (Dergaa et al., 2023). Additionally, highly cited documents within collection investigate behaviors and reflections of second language (L2) writing learners in their exposure to ChatGPT in writing classrooms (Yan, 2023), present a text editor that enables users to collaborate with a generative language model to co-create a story (Yuan et al., 2022). Lastly, they raise critical questions regarding the intellectual property implications and the potential for GPT-3 to facilitate instances of plagiarism (Dehouche, 2021).
Among the most locally cited references are GPT-4 Technical Report[1], a paper that suggests the integration of ChatGPT into classrooms focused on argumentative writing (Su, 2023) and a discussion of thematic analysis in psychology (Braun and Clarke, 2006). Highly cited references include a paper by H. Else who discusses abstracts written by ChatGPT (Else, 2023), a publication by J. Barrot who reflects on the potential impacts of ChatGPT, as well as similar AI tools, on education in general and second language (L2) writing in particular (Barrot, 2023).
3.5. Topical structure of the collection
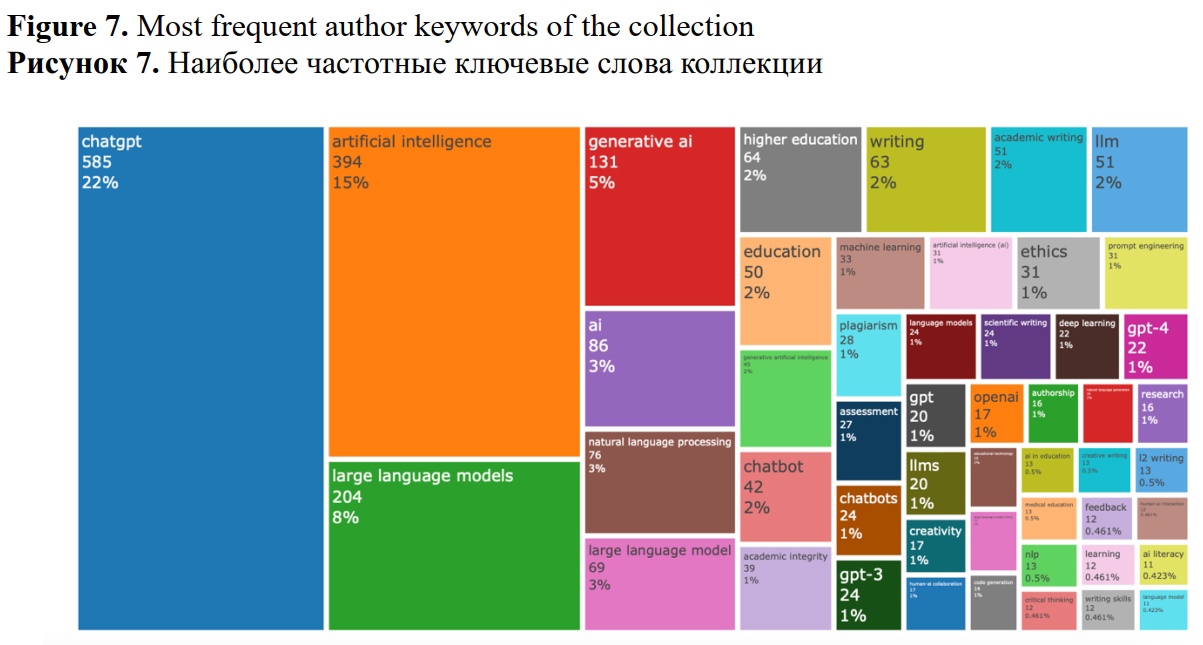
Figure 7 illustrates the most frequently occurring author keywords within the collection, which delineate its overarching knowledge structure and serve as a proxy for its thematic map.
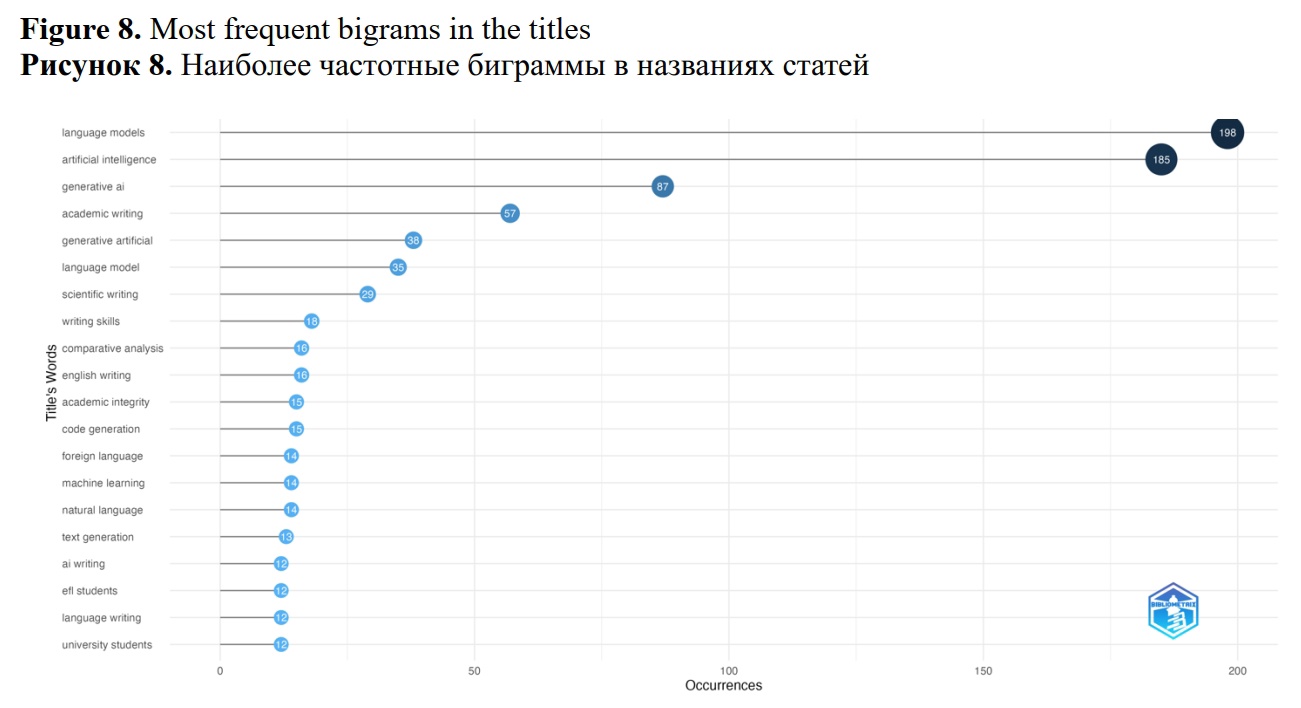
Titles represent a critical component of the academic papers; therefore, we compiled a list of the most frequently occurring bigrams in the titles within our collection (see Figure 8). The data indicates that issues related to academic writing in the context of LLMs are among the most prevalent concerns identified in the collection, alongside challenges associated with writing in a second language.
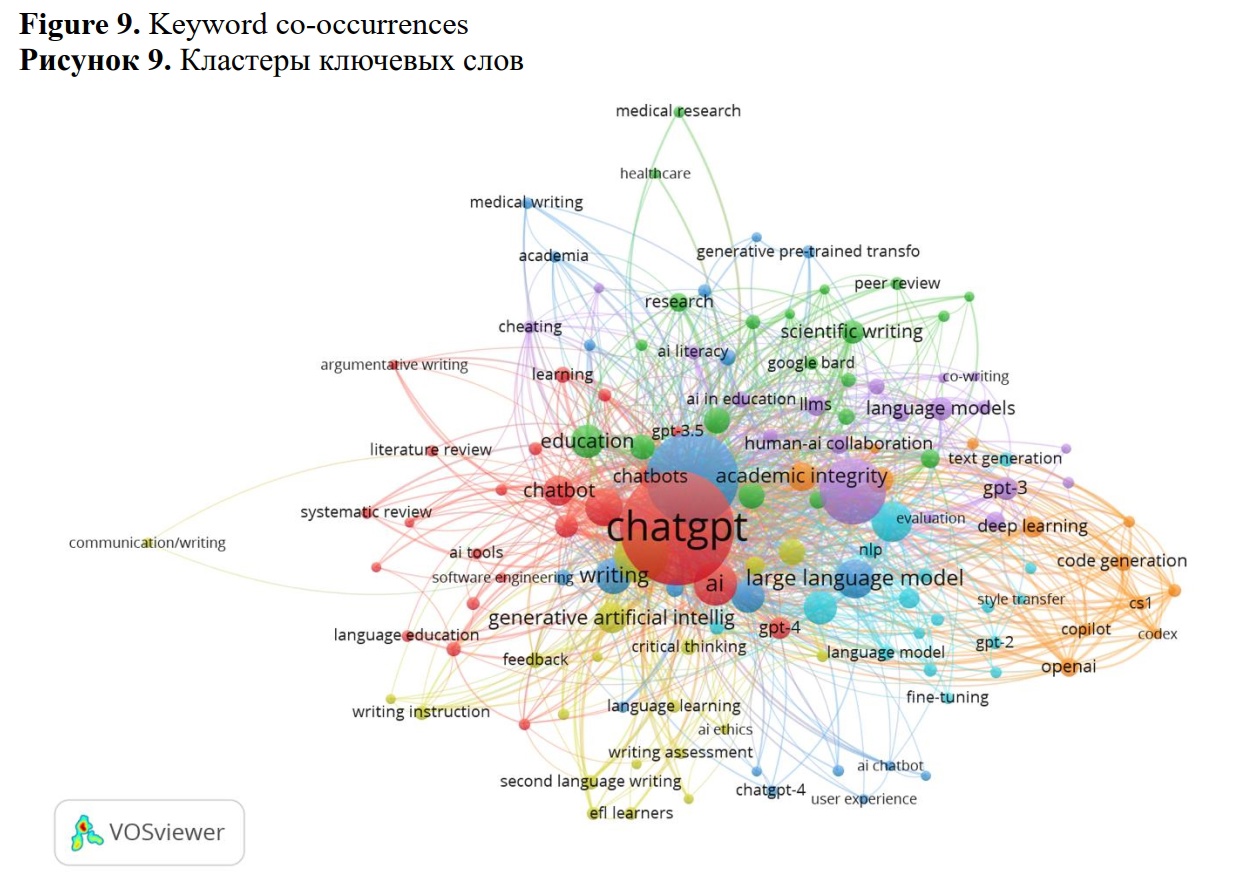
The visualization generated by VOSviewer, which is based on the co-occurrences of author keywords (see Figure 9), illustrates multiple clusters of topics present within our collection.
The largest – red – cluster (23 terms) addresses issues related to the challenges of AI tools including chatbots in higher education context, specifically for language education, including the problems of automated evaluation of writing in a second language, automated essay scoring. The second largest cluster, depicted in green (21 terms) concerns with the challenges posed by the problems of the use of LLMs in academia. The problems of ethics of the use of LLMs in academic context are examined, particularly issues related to authorship and plagiarism, especially in the realm of medical research. The third cluster represented in blue and containing 20 terms discusses the general challenges associated with the application of LLMs for medical education and medical writing. Cluster 4 illustrated in yellow and comprising 20 terms, addresses issues related to creativity, second language writing, automated feedback during writing assessments, writing pedagogy and writing proficiency. Cluster 5 represented in purple and consisting of 19 items, focuses on the challenges of creative writing, including poetry, co-writing with LLMs, and human-AI collaboration more broadly. Cluster 6 depicted in light blue and containing 17 terms is associated with challenges in text classification and style transfer using transformer models, including the issues related to fine-tuning and data augmentation. Finally, Cluster 7, represented in orange and comprising 12 terms, discusses the challenges of utilizing LLMs for code generation and programming education, as well as broader issues related to digital literacy.
The analysis of the dynamics of topics conducted using VOSviewer and bibliometrix indicates that research interest is currently concentrated on issues related to ethics of the use of LLMs in writing, automated essay scoring in the context of EFL, problems of text classification including AI-generated texts.
Conclusions
This editorial employs a combination of the bibliometrix R package and VOSviewer to provide a brief overview of the rapidly evolving research domain concerning the study of writing as both a process and a product in the context of LLMs. Our review indicates a notable upward trend in the number of publications within this field over the past two years (2023 and 2024). It is reasonable to anticipate that this trend will persist at least in the foreseeable future. The predominant topics associated with the application of LLMs in writing pertain to the opportunities and challenges that arise in relation to their use for second language writing, its automated evaluation and feedback, as well as issues surrounding the use of LLMs in academic writing, including ethical considerations, authorship and plagiarism. A significant number of papers are devoted to the discussion of LLMs within the context of medical education and medical writing. Additionally, the challenges of creative writing and LLMs as co-writers are extensively examined. As this field continues to develop, the focus of research attention is shifting from the issues related to code generation to concerns surrounding artificial intelligence ethics, second language writing, and its automated evaluation.
[1] OpenAI (2023), GPT-4 Technical Report, accessed 20.12.2024
Благодарности
Т. А. Литвинова благодарит за финансовую поддержку Министерство просвещения Российской Федерации (работа выполнена при финансовой поддержке Министерства просвещения Российской Федерации в рамках выполнения государственного задания в сфере науки, номер темы QRPK-2024-0011). О. В. Дехнич и Дж. Микрос не получали финансовой поддержки за выполнение исследований, написание и публикацию статьи.












Список литературы
Aria, M. and Cuccurullo, C. (2017). bibliometrix: An R-tool for comprehensive science mapping analysis, Journal of Informetrics, 11 (4), 959–975. https://doi.org/10.1016/j.joi.2017.08.007 (In English)
Barrot, J. S. (2023). Using ChatGPT for second language writing: Pitfalls and potentials, Assessing Writing, 57, 100745. https://doi.org/10.1016/j.asw.2023.100745(In English)
Braun, V. and Clarke, V. (2006). Using thematic analysis in psychology, Qualitative Research in Psychology, 3 (2), 77–101. https://doi.org/10.1191/1478088706qp063oa (In English)
Cascella, M., Montomoli, J., Bellini, V. and Bignami, E. (2023). Evaluating the Feasibility of ChatGPT in Healthcare: An Analysis of Multiple Clinical and Research Scenarios, Journal of Medical Systems, 47, 33. https://doi.org/10.1007/s10916-023-01925-4(In English)
Chan, C. K. Y. and Hu, W. (2023). Students’ voices on generative AI: perceptions, benefits, and challenges in higher education, International Journal of Education Technology in Higher Education, 20, 43. https://doi.org/10.1186/s41239-023-00411-8 (In English)
Cotton, D. R. E., Cotton, P. A. and Shipway, J. R. (2023). Chatting and cheating: Ensuring academic integrity in the era of ChatGPT, Innovations in Education and Teaching International, 61 (2), 228–239. https://doi.org/10.1080/14703297.2023.2190148(In English)
Crompton, H. and Burke, D. (2023). Artificial intelligence in higher education: the state of the field, International Journal of Education Technology in Higher Education, 20, 22. https://doi.org/10.1186/s41239-023-00392-8(In English)
Dehouche, N. (2021). Plagiarism in the age of massive Generative Pre-trained Transformers (GPT-3), Ethics in Science and Environmental Politics, 21, 17–23. https://doi.org/10.3354/esep00195 (In English)
Dergaa, I., Chamari, K., Zmijewski, P. and Ben Saad, H. (2023). From human writing to artificial intelligence generated text: examining the prospects and potential threats of ChatGPT in academic writing, Biology of sport, 40 (2), 615–622. https://doi.org/10.5114/biolsport.2023.125623 (In English)
Else, H. (2023). Abstracts written by ChatGPT fool scientists, Nature, 613 (7944), 423. https://doi.org/10.1038/d41586-023-00056-7 (In English)
Finnie-Ansley, J., Denny, P., Becker, B. A., Luxton-Reilly, A. and Prather, J. (2022). The Robots Are Coming: Exploring the Implications of OpenAI Codex on Introductory Programming, in Proceedings of the 24th Australasian Computing Education Conference (ACE’22), Association for Computing Machinery, New York, NY, USA, 10–19. https://doi.org/10.1145/3511861.3511863 (In English)
Gao, C. A., Howard, F. M., Markov, N. S., Dyer, E. C., Ramesh, S., Luo, Y. and Pearson, A. T. (2023). Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers, npj Digital Medicine, 6, 75 https://doi.org/10.1038/s41746-023-00819-6 (In English)
Haleem, A., Javaid, M. and Singh, R.P. (2022). An era of ChatGPT as a significant futuristic support tool: A study on features, abilities, and challenges, BenchCouncil Transactions on Benchmarks, Standards and Evaluations, 2 (4). https://doi.org/10.1016/j.tbench.2023.100089(In English)
Perkins, M. (2023). Academic integrity considerations of AI Large Language Models in the post-pandemic era: ChatGPT and beyond, Journal of University Teaching and Learning Practice, 20 (2). https://doi.org/10.53761/1.20.02.07(In English)
Salvagno, M., Taccone, F. S. and Gerli, A. G. (2023). Can artificial intelligence help for scientific writing?, Critical Care, 27, 75. https://doi.org/10.1186/s13054-023-04380-2 (In English)
Su, Y., Lin, Y. and Lai, C. (2023). Collaborating with ChatGPT in argumentative writing classrooms, Assessing Writing, 57. https://doi.org/10.1016/j.asw.2023.100752(In English)
Taecharungroj, V. (2023). What Can ChatGPT Do? Analyzing Early Reactions to the Innovative AI Chatbot on Twitter, Big Data and Cognitive Computing, 7 (1), 35. https://doi.org/10.3390/bdcc7010035 (In English)
Van Eck, N. J. and Waltman, L. (2014). Visualizing bibliometric networks, in Ding, Y., Rousseau, R. and Wolfram, D. (eds.) Measuring scholarly impact: Methods and practice, Springer, 285–320. http://dx.doi.org/10.1007/978-3-319-10377-8_13 (In English)
Yan, D. (2023). Impact of ChatGPT on learners in a L2 writing practicum: An exploratory investigation, Education and Information Technologies, 28, 13943–13967. https://doi.org/10.1007/s10639-023-11742-4 (In English)
Yuan, A., Coenen, A., Reif, E., and Ippolito D. (2022). Wordcraft: Story Writing With Large Language Models, Proceedings of the 27th International Conference on Intelligent User Interfaces (IUI’22), Association for Computing Machinery, New York, NY, USA, 841–852. https://doi.org/10.1145/3490099.3511105 (In English)