
Исследование межсловных пауз в текстах на русском языке по данным кейлоггера с использованием моделей гауссовой смеси
Aннотация
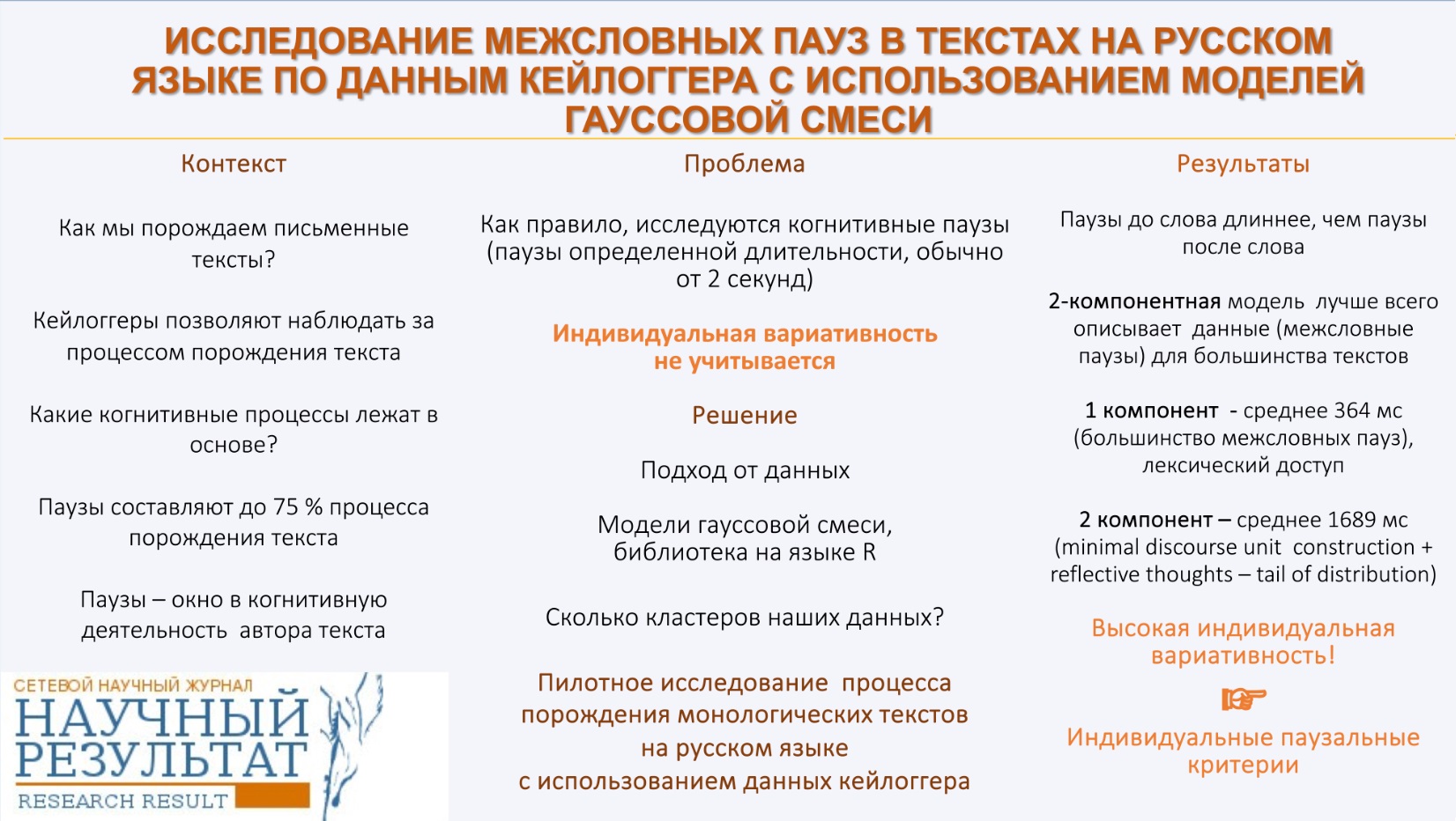
Регистрация нажатий клавиш с использованием специальных программ – кейлоггеров – это неинвазивная технология, которая стала золотым стандартом в моделировании процессов порождения текста. Особенно важными характеристиками в таком анализе являются длительности пауз, поскольку именно паузы рассматриваются как индикаторы базовых когнитивных процессов, лежащих в основе процесса порождения текста. Распространенным подходом является установление произвольных пороговых значений пауз, и разделение на их основе пауз на когнитивные, которые и используются для дальнейшего анализа, и некогнитивные, которые исключаются из дальнейшего анализа как незначимые. Однако такой подход имеет множество недостатков и не позволяет охватить сложность и индивидуальную вариативность когнитивных процессов, связанных с текстопорождением. В статье представлены результаты пилотного исследования, проведенного на основе данных кейлоггера в ходе порождения текстов на русском языке. В исследовании для кластеризации значений продолжительности пауз используются модели гауссовых смесей. Мы обнаружили, что паузы между словами не могут быть охарактеризованы одним распределением. Для описания межсловных пауз в текстах большинства наших участников лучше всего подходит двухкомпонентное распределение, отражающее, вероятно, лексический доступ и рефлексивные процессы. Мы обнаружили высокую индивидуальную вариативность пропорций для выявленных компонентов. В статье подчеркивается необходимость использования индивидуального подхода к установлению паузальных критериев, а также исследования пауз различной продолжительности в их совокупности и взаимосвязи на уровне отдельного текста.
Ключевые слова: Анализ нажатий клавиш, Кейлоггер, Пауза, Продолжительность пауз, Исследования письма, Процесс письма, Модели гауссовой смеси
К сожалению, текст статьи доступен только на Английском
Introduction
Keystroke logging software, which captures information regarding each key pressed and released along with timing data during text production via keyboard has gained prominence in writing research for the examination of the writing process and the cognitive mechanisms that underlie it. This trend has been evident since the introduction of academic keyloggers to research community (Leijten, Van Waes, 2006; Leijten, Van Waes, 2013). Keystroke logging has emerged as a gold standard methodology in writing research because, unlike other methods such as screen recording, thinking-aloud protocols, eye-tracking, it offers objective, detailed and easily obtainable data on typing processes during text production, which can be employed non-invasively in naturalistic settings.
One of the most significant types of information yielded by keystroke logging software pertains to the location, duration, and distribution of pauses that occur during the writing process. In the field of writing research pauses are defined as intervals during which no written output is generated (Garcés-Manzanera, 2024), as periods of inactivity, observable and measurable (Barkaoui, 2019). Pauses in writing have been “assumed to provide us with a window to the cognitive processes underlying language production” (Wengelin, 2006: 108).
In the field of writing research, written composition is often conceptualized as a series of temporal segments, referred to as “bursts” (a minimal units of text production whose linguistic characteristics remain to be fully elucidated) (Alves, Limpo, 2015; Limpo, Alves, 2017) divided by pauses. Various studies suggest that pauses can account for three-quarters of a text production time (Alamargot et al., 2007). This observation is not surprising, given that writing is an inherently complex activity; writers engage in planning, monitoring, revising, and continuously evaluating their work. These processes undoubtedly impose a considerable cognitive load, impacting both attentional and working memory capacities (Alamargot et al., 2007; Medimorec, Risko, 2017).
Pause data have been extensively employed to infer the cognitive processes that underpin writing since the inception of writing research. It is evident that not all pauses that occur during writing are regarded as indicators of cognitive activity; rather, only those pauses deemed indicative of higher-order thinking are taken into account. A general approach to distinguishing such pauses from “non-cognitive” involves the establishment of a specific threshold.
Classic cognitive models of writing emphasize the reflective processes that occur during cognitive pauses. Researchers in this field examine the locations and distribution of these pauses in relation to various factors, including the writing tasks, the characteristics of the writer, and the quality of the text, etc. The body of research investigating the different characteristics of bursts (Cislaru et al., 2024) is significantly influenced by the cognitive pause definition, as bursts are usually defined as units occurring between two cognitive pauses.
Despite decades of intensive research, little is still known about the exact nature of the cognitive processes underlying written production during “cognitive” pauses, and the results of existing studies are often difficult to compare, as researchers employ different pause duration thresholds to identify cognitive pauses. Currently, there is no objectively and universally accepted pause threshold (Medimorec, Risko, 2017; Galbraith, Baaijen, 2019). While various thresholds are used, the 2000 milliseconds (ms) threshold is widely employed adopted, with pauses above this duration considered indicators of higher-level cognitive processes such as planning new ideas and revising (Wengelin, 2006; Chukharev-Hudilainen, 2014; Chukharev-Hudilainen et al. 2019; Garcés-Manzanera, 2024). A pause lasting between 30 milliseconds and 2 seconds is believed to indicate transcription processes related to typographic skills and spelling, grammatical and lexical decisions (Limpo, Alves, 2017; Spelman-Miller, 2006; Valenzuela, Castillo, 2023). However, it is important to note that interpretation and linking keystroke logging variables to underlying cognitive processes is not straightforward and easy (Baaijen, Galbraith, 2018; Galbraith, Baaijen, 2019). Overall, the primary focus of writing research utilizing keystroke data has been on higher-level thinking processes rather than on more localized ones.
There are numerous challenges associated with establishing a universal pause threshold. First, this approach does not consider individual differences in typing skills and potentially in the cognitive processes that underlie writing and writing styles (Escorcia et al., 2017; Vandermeulen et al., 2024). Second, it overlooks shorter pauses that could be beneficial for a detailed analysis of the writing process (see Galbraith, Baaijen, 2018 for the dual-process model of writing).
To address the significant limitations of an approach that relies on assigning a predefined and universal pause duration threshold, Baaijen et al. (2012) proposed the use of a mixture models methodology (McLachlan, Peel, 2000) to identify the subcomponents of pause duration distributions. Mixture modeling is a form of cluster analysis that allows researchers to evaluate how many subcomponents — whether of the same type or different types — can be distinguished within an analyzed distribution. This method aims to achieve a better alignment between pause duration values and the underlying cognitive processes. The results obtained by Baaijen et al. (2012) revealed numerous advantages of application of mixture modeling for clustering pauses duration values, and the authors recommend it as a standard practice to analyze pause behavior during writing. However, since the publication of Baaijen et al. (2012) only few studies have employed this method to analyze pauses during writing (Guo et al., 2018; Roeser et al., 2019; Van Waes et al., 2021).
In recent research conducted by Hall et al. (Hall et al., 2024) mixture modeling was employed to cluster pauses at various locations within texts. Based on the results obtained, the authors assert that traditional threshold-based approaches to pause analysis “fail to capture the complexity of the cognitive processes involved in text production” (Hall et al., 2024). They conclude that pauses at different text locations cannot be adequately described by a single distribution and recommended that researchers “impose a common set of theoretically informed distributions” on pause duration data, rather than impose fixed pause thresholds. However, the aforementioned research was conducted on a small-scale corpus of English texts, highlighting the need for further studies on diverse text types and languages, as emphasized by the authors.
Another problem of analysing pauses in writing studies is related to the calculation of pause duration values. Typically, a pause between words is calculated as a sum of two distinct pauses: one occurring before and one after SPACE. However, these pauses are sometimes treated separately (e.g., Wengelin, 2006), yet the underlying processes occurring during each type of pause remain largely unknown. In the aforementioned work by Hall et al. (Hall et al., 2024) it is asserted that combining these two types of pauses is reasonable; however, no theoretical justification for this combination is provided. As Medimorec and Risko aptly argue, “a potential limitation of this approach is that it implies functional similarity between ‘‘after’’ and ‘‘before’’ pauses” (Medimorec, Risko, 2017: 56). Nevertheless, this issue has received comparatively attention in research. The authors (Medimorec, Risko, 2017) emphasize the importance of investigating the roles of these two types of pauses in text production separately to uncover potential functional differences between them. To the best of our knowledge, there has been no research conducted to reveal such differences to date. It is clear that without modeling the distribution of pauses before and after SPACE separately, in addition to considering the combined factor, these distinctions would remain unobservable.
The current study is the first to analyze the distribution of between-word pauses in the log files of typed texts in Russian, utilizing mixture modeling to uncover the subcomponents of pause time distribution.
Our main research questions are as follows:
1. How many clusters of pause duration values can be identified among pauses between words?
2. Is the structure of pause duration values differ for pauses occurring after words compared to those before words?
3. If more than one cluster can be identified, do the pause duration thresholds apply to all writers?
Methodology
Participants
All respondents were native Russian speakers. A total of 53 students participated in our experiment and provided written informed consent for their data and texts to be processed for research purposes. For this study, we selected only those participants who wrote texts of all three types resulting in a final sample of 50 participants.
Out of the 50 participants, 48 (94 %) were female, all participants were aged 18 to 20 years old.
The data utilized in this study were collected during a general academic course titled “The Russian Language and Language Culture” for Russian students enrolled in the bachelor’s degree program in pedagogical education in Voronezh State Pedagogical University.
Design
The participants received an electronic version of the questionnaire, which included three writing tasks, demographic questions, and links to psychological tests. They were encouraged to ask any questions about the experiment details and the tasks assigned to them via Telegram chat with the instructor.
For the first writing assignment, the students were required to compose a detailed description of the view from the window of their home. The second assignment involved writing about their impressions of any event they had attended. For the third text, the students were asked to discuss a topic of personal interest.
Several writing tasks were selected, as it is known that the type of writing task influences the pausing behavior. For instance, research conducted by Medimorec and Risko demonstrated that argumentative essays are more cognitively demanding — being more constrained and requiring greater planning — compared to narratives (Medimorec and Risko, 2017).
No more than one text should be written in a single day; however, the order in which the writing assignments are completed is restricted. Each text must be at least 150 words long. Additionally, it is important to consider that several days should elapse between completion of one text and the writing of the next text.
Before writing each text, the students were required to complete an emotional state assessment consisting of 20 questions (https://psytests.org/emo/panas.html). Additionally, during the course of their participation in the study, the students completed the Big Five Questionnaire – a test designed to identify personality traits – consisting of 44 questions (https://psytests.org/big5/bfi.html).
Tests were collected as part of a larger project aimed at assessing the effect of participants' characteristics on their pause behavior during text production.
The study participants provided the finished materials to the moderator via e-mail or Telegram. Each respondent was assigned an individual code. As a result, the anonymous study materials were transferred to the project manager.
All the students used their personal computers for the task. The participants were allowed to use the Internet during the task but were prohibited from copying and pasting texts or their fragments. Students were not restricted in terms of time on the task, but we asked them to write one text per writing session, without interruption.
Before starting to write the texts, the participants had installed the academic keylogger GenoGraphiX-Log 2.0 (abbreviated GGXLog) on their personal computers (Usoof et al., 2020). GGXLog records writing sessions in different writing contexts and stores the data from the writing session as a log file. Furthermore, GGXLog captures and stores informant data, third-party application usage during the writing session, and the final product text.
This software was chosen as the only academic keylogger currently available for download in Russia.
The example of the fragment of the log file provided by GGXLog is presented in Figure 1.

Data Analysis and Preprocessing
For this exploratory study, we used only one text type – describing the view from the window – as we assumed this writing task would yield the most homogeneous texts. The dataset used for this study is available on GitHub[1].
We analyzed the log files (50) containing individual participants’ keystroke data. In the preliminary stage, we removed outliers from our pause duration values which totaled 111948 entries. We employed the quantile method, eliminating values lower than the 0.1 percentile (2 ms) and higher than 99.9 percentile (50370.28 ms). This process resulted in a final count of 111538 pause duration values.
In the present analysis, we focused solely on pauses between words, specifically instances where a word ended and new word began after a SPACE. This approach meant that we excluded all pauses associated with punctuation marks, revision indicators (such as DELETE and BACKSPACE), and navigation markers. Consequently, we analyzed only those cases where no actions other than pause occurred between consecutive words, eliminating instances of revision, mouse movements, insertion, edits, or punctuation marks. Pauses occurring between sentences, sub-sentence pauses (as defined by Hall et al., 2024 in Table 1, which describes them as “the time between the end of a word that is followed by a comma, and the start of the next word that is preceded by the same comma”) and revision pauses (termed “non-linear events”) are typically regarded as distinct types of pauses in writing research and will be analyzed individually.
In the current analysis, we analyzed three types of pauses between two concessive words: 1) pauses after words, i.e., after the last letter of preceding word before SPACE (t2 in Figure 2); 2) pauses before words, i.e., after SPACE mark (t3 in Figure 2); 3) combined indicator (pause time before SPACE + pause time after SPACE) (i.e., for between-word pause for word2 and word3 is calculated as t2+t3) (Figure 2).

Although the SPACE key serves as a marker for pauses between words, the random insertion of SPACE within words is a common issue in the analysis of text production through keystroke logging. Various thresholds for the minimum duration of between-word pauses have been proposed to filter out the random occurrence of SPACE within words. For instance, Van Waes et al. (2021) employed a threshold of 30 ms in their study of typing skills. In contrast, Hall et al. (2024) used a threshold of 50 ms across all text locations to eliminate accidental SPACE transitions within words from their analysis. A manual inspection of our dataset revealed that pauses shorter than the 30 ms threshold were indicative of accidental SPACE within words rather than between words. Consequently, these instances were excluded from further analysis. The resulting dataset comprises 22,300 pauses occurring after words and before word.
Given that pause data are highly positively skewed, with most of pauses being relatively short and a minority being significantly longer, we performed natural log transformations, which is a standard practice in pause analysis (Baaijen et al., 2012).
As the primary analytical approach, we employed mixture modeling which is a form of cluster analysis that enables researchers to assess how many subcomponents can be identified within an analyzed distribution.
Relying on the results of the studies (Baaijen et al., 2012; Hall et al., 2024) in which between-word pauses were analyzed through clustering via mixture modeling, we constrained the maximum number of components (parameter G) to test to three. Specifically, we constructed models with G=1,2,3, and subsequently selected the best model using the Bayesian Information Criterion (BIC).
Following (Hall et al., 2024), we constructed Gaussian mixture models (GMMs) using the expectation-maximization (EM) algorithm (McLachlan, Peel, 2000) to assess whether the pause times between words, after words, and before words exhibit an underlying structure that is better represented by multiple distributions rather than a single Gaussian distribution. For more details on this algorithm which is also widely used for speech data analysis we refer the reader to the work by Little et al. (Little et al., 2012). To this end, we formally evaluated the relative goodness of fit of single Gaussian distributions compared to two- and three-component models for each participant separately. Consequently, we employed the EM algorithm to fit multiple GMMs to each participant’s log-transformed data, including before-word, after-word and between-word pause duration values, for all pauses longer than 30 ms.
The analysis was conducted using in the R package Mclust version 5.4.7 (Fraley et al., 2020).
Results
Before-word and After-word pauses
Figures 3-4 show that, although log transformations reduced skewness, they did not eliminate it for most writers.


Table 1S[2] presents Bayesian Information Criterion (BIC) values for various Gaussian Mixture Models (GMM) with G values of 1, 2, and 3, with the best values highlighted in bold. It is important to note that we also evaluated 4-component models; however, their performance was inferior to that of the two- and three-component models (though better than the one-component model) and therefore, their results are not included.
The differences between the best and second-best models are presented in Table 1S. The best models, along with the second-best models that exhibits differences greater than 3.7 compared to the best models, are highlighted and underscored. This threshold was proposed by Kass and Raftery (Kass, Raftery, 1995: 777) who suggested that a difference of this magnitude could be considered significant, while a difference greater than 20 indicates a strong distinction between models.
As for the before-word data, the two-component model demonstrated the best fit for 21 of the respondents (42%), the three-distribution model was most suitable for 11 of them (22%), the remaining 17 writers (34%) were indeterminate between two and three-distribution models. Only for 1 respondent (2 %) the one-distribution model were the best fit.
In the analysis of the afterword pauses, we found that 28 out of 50 texts (56%) were better described by a two-component model. For 9 texts (17.65%) the three-distribution model was the best fit, and the remaining 9 texts (17.65%) being indeterminate between two and three distributions. Only for 2 respondents (4%) the one-distribution model was the best fit. One writer was intermediate between the one- and three-distribution models, and another writer was intermediate between the one- and two-distribution models.
These results demonstrates that the cognitive processes occurring at word boundaries — both before word and after word — are heterogeneous and cannot be encapsulated by a single threshold.
Next, we constructed a two-component distribution model for pauses occurring before and after words for all writers to compare the properties of these distributions among them. Specifically, we calculated the proportion of pauses within each of the two distributions, as well as the mean values for each distribution (see Table 2S[3]).
Let us compare the data obtained for the first and second components. The mean duration of pauses for the first component specifically for before-word pauses is log 5.31 (202.35 ms), median value is log 5.40 (221.41 ms). The mean duration for after-word pauses in the first component is log 4.8 (121.51 ms), and median value is log 4.78 (119.1 ms).
We used the paired samples Wilcoxon test, also known as Wilcoxon signed-rank test, which is a non-parametric alternative to the paired t-test used. This method is employed to compare paired data due to the violation of normality in our dataset.
This test confirmed that the differences in pause duration before and after word were statistically significant (V = 1193, p-value < 0.00001) (Figure 5).

The second component is characterized by pauses with a median duration of 6.97 log ms (1064 ms) before word, 6.46 log ms (639.06) after word (IQR = 0.85). The differences in pause duration before and after the word in the second component are statistically significant (V = 1026, p-value = 0.00018) (Figure 6).
Let us note that the mean mixing proportion of the first component for before-word pauses is 0.692, while for after-word pauses it is 0.827. This indicates that the share of longer pauses (the second component) is greater in the pause position before words.
Note that the mixing proportions of components vary significantly among the individuals. While some exhibit a strong preference for the first component, accounting for more than 90% of the pauses, others show that the second component also constitutes a significant part of the pause data.

Between-word pauses
The histogram illustrating the distribution of between-word pause duration values is presented in Figure 7.

Again, we observe that even after applying a log transformation pause time data exhibit a multicomponent distribution for the majority of the writers. The pause data from only a few respondents (NN 6 and 36) tend to display a unimodal distribution, while most of the data clearly indicate a multimodal distribution. However, specific characteristics of these distributions vary significantly among the writers. While most of the data demonstrate a two-modal distribution, pause durations for some writers are better described by a three-modal distribution (NN 34, 35, 45, 49).
We constructed GMMs with varying numbers of components (G = 1, 2, 3). Three-distributional models provided the best fit for the data from 5 participants (10%), while 11 (22%) were indeterminate between two- and three-component model, one writer (2%) was indeterminate between one- and two-component models. One-distribution model was a best fit for two participants (4%). For the majority of the writers (31, 62%), two-distributional models demonstrated the best fit (see Table 3S[4]).
So, for the sake of comparison, we built a two-component model for all the respondents.
The mean duration of between-word pauses for each mixture component along with the mean proportion of pauses falling within each mixture component for each participant is presented in Table 4S[5].
The mean duration of pauses between words for the first component is 5.897 log ms, which corresponds to 364 ms (median value is 5.865 log ms, i.e., 352.48 ms) (see Figure 8).

The mean mixing proportion of the first component is 0.7 (sd=0.15).
The mean duration of between-word pauses for the second component is 7.4 log ms, which corresponds to 1685.8 ms (median value is 7.3 log ms, i.e., 1415 ms) (see Figure 9).
The mean mixing proportion of between-word pauses for the second component is 0.3 (sd=0.15).

Discussion
In this study, we conducted a cluster analysis of pause duration occurring after words, before words and between words in Russian typed texts, clearly outlining our methodology for calculating the pause duration in these contexts. We utilized mixture modeling to analyze the pause time and discovered that for the majority of participants, two-cluster solution demonstrated the best fit.
We also identified differences in the duration of the pauses before word compared to those after words. These results indicate that pauses occurring before and after words reflect distinct cognitive processes, with pauses before words typically being longer. This phenomenon may be related to the increased cognitive load experienced by the writers. As emphasized in the Introduction, the challenge of elucidating the differences in the underlying cognitive processes involved in word retrieval during text production is less explored in writing research. Nevertheless, our findings replicate those reported in (Mohsen and Qassem, 2020). Their small-scale study, which included data from eight respondents, demonstrated that pauses during the writing of two text genres – descriptive and argumentative essays – varied based on pause location: pauses before words were significantly longer than those after words for genres. Clearly, this issue warrants further investigation.
Our results concerning the multicomponent model, which demonstrated a better fit for between-word pauses than the one-component model, align with those reported in literature (Baaijen et al., 2012; Hall et al., 2024).
As our results indicate, for the majority of the participants, short pauses (up to roughly 500 ms) account for most of the pauses between words. This finding aligns with the results obtained by Baaijen et al. (2012) reported that mean duration of pauses in the first component is 330 ms, constituting 65% of the pauses in their dataset. Our results are similar to those presented in the papers by E. Chukharev-Hudilainen, (Chukharev-Hudilainen, 2011; Chukharev-Hudilainen, 2014), who, to the best of our knowledge, is the only researcher to have analyzed keystroke data from Russian texts (specifically chat messages) in the context of the writing process. Using ex-Gaussian distribution equation, he demonstrated that two types of pause distributions could be identified. The first distribution has an average pause duration of 386.9 ± 102.9 ms and varies across the subjects, which is close to our results.
It is important to note that in our data two-component distribution was the best fit for modeling between-pause durations for the most (though not all) writers. In this regard, our results are similar to those obtained by Chukharev-Hudilainen. The second type of pauses he identified falls within the range up to 937.9 ± 357.4 ms, which are believed to be associated with the production of predicate expressions (Chukharev-Hudilainen 2014). Therefore, pauses above 1,2 sec threshold are considered indicative of higher-level planning.
In English-language data, three-component models were the best fit for the majority of the writers. A middle distribution, accounting for 26% of the pauses, with mean duration of 735 ms, was revealed by (Baaijen et al., 2012) who suggested that it represents phrase boundary processes. Baaijen et al., 2012 also revealed the right-hand distribution which comprised 9% of the pauses with a mean duration of 2697 ms, indicating a higher-level message planning or reflection. They further proposed that the “long tail” of such pauses should not be treated as a normal distribution but rather as a miscellaneous set of reflective thoughts, with cutoff of around 1.686 ms. The equivalent threshold reported by (Hall et al., 2024) is 1426 ms. These thresholds are comparable to those obtained on our data for the second distribution.
We argue that the assumption of a common set of underlying cognitive processes during writing should not be taken for granted; instead, different models may be necessary to accurately describe the writing processes of various individuals. It is also should be stressed that the relatively high standard deviations for the mixing proportions indicate substantial variation among individuals regarding the relative contributions of different component processes. This suggests the need to consider an individual factor in the analysis of writing behavior.
Our study demonstrated that, counting pauses above an arbitrarily established threshold — particularly the commonly used 2000 ms threshold — fails to encompass the range of processes involved in text production.
In our research, we found that mixture modeling has proven to be an effective method for describing writers’ pausing behavior. It allowed us to identify the relatively strong evidence for a multi-component structure in the linear between-word pause distribution in Russian monological texts for the majority of the writers.
However, the question that remains unresolved in previous studies — regarding the justification for characterizing the distribution of between-word pauses as a variable property of writers also arises in our data. While most writers exhibit two distributions, others display three.
It is essential to model pause distribution at different text locations (within-word, between-word, between-sentences) simultaneously, since these elements are clearly interrelated. This can be accomplished using multilevel mixture modeling (Muthén, Asparouhov, 2009). However, to the best of our knowledge, no research employed this method for a comprehensive analysis of a writer’s pausing behavior during text production has been performed.
It is important to acknowledge that our study has certain limitations. It was conducted using data from highly homogeneous population, while it is known that individual characteristics, such as demographics, affect writing styles. For instance, Zhang et al. (Zhang et al., 2019) found that female authors produced their texts more fluently, engaged in more extensive macro- and local editing, and exhibited a reduced need to pause at the locations associated with planning (e.g., between bursts of text and at sentence boundaries) compared to their male counterparts. Additionally, our analysis focuses on only one text genre, which, as suggested by previous research, does not impose a high cognitive load (unlike argumentative essays, for example). Clearly, broadening the range of analyzed genres and incorporating greater diversity in the writers’ characteristics would enhance the validity of our findings.
In this study, we did not consider the effect of the operating system of the participant's computer (MAC/Windows) on their writing behavior. As one of our reviewers reasonably suggested, this factor could have an impact on the results. In our future study, we will analyze this effect.
Conclusions
The use of keystroke data has become a gold standard in writing research, with pause duration at different text locations being one of the most important features analyzed based on keystroke data, since the analysis of pauses during writing is crucial for modeling the writing processes. To conduct analyses, many researchers rely on predefined pause thresholds. However, this approach has several drawbacks: it fails to account for individual differences in typing skills, writing competencies, styles, and it overlooks pauses below a predetermined threshold, which arguably hinders a comprehensive understanding of the writing process.
Our study is the first to analyze log files containing keystroke data that reflects the process of producing free monologue texts in Russian. We examined pauses before and after words separately and in combination using mixture modeling methodology. Our findings indicate that the majority of the participants’ data fit better with multicomponent (primarily two-component) distributions. The first distribution may be related to lexical assessment and depends on the motor (typing) skills of the writers, while the second distribution could signify underlying reflective thoughts related to text planning. To gain a deeper understanding of the nature of writing process, an individual-based pause threshold should be determined, and linguistic nature of the resulting burst should be examined. This field could greatly benefit from adopting methods for identifying and describing minimal discourse units in oral speech (Kibrik et al., 2020).
Our study clearly demonstrates the necessity to examine all types of pauses during writing and considering the relationships between pause durations at different locations within the text. The issue of individual variations not only regarding the thresholds for different types of pauses but also concerning the structure of distributions should be investigated across various writing tasks.
Our future research directions are manifold. First, we aim to expand our dataset in terms of both text types and the diversity of the writers’ characteristics. We will pay special attention to the effects of cognitive load associated with writing tasks on writers' pausing behavior.
Second, we will conduct multilevel mixture modeling of pauses at different locations within text to gain a more comprehensive understanding of pausing behavior during text production.
Third, we will calculate pairwise semantic distance between words and align these results with pause duration to gain a better understanding of the relationship between a semantic flow and text production.
Fourth, we aim to assess the relationship between the revealed characteristics of the writers’ pausing behavior and the quality of their texts, which represents a promising avenue of writing research (Beauvais et al., 2011).
[1]https://github.com/Litvinova1984/keystroke_Russian_texts (accessed on 15.10.2024).
[2]https://github.com/Litvinova1984/keystroke_Russian_texts (accessed on 15.10.2024).
[3]https://github.com/Litvinova1984/keystroke_Russian_texts (accessed on 15.10.2024).
[4]https://github.com/Litvinova1984/keystroke_Russian_texts/tree/main (accessed on 15.10.2024).
[5]https://github.com/Litvinova1984/keystroke_Russian_texts/tree/main (accessed on 15.10.2024).
Благодарности
Авторы благодарят за финансовую поддержку Министерство просвещения Российской Федерации (работа выполнена при финансовой поддержке Министерства просвещения Российской Федерации в рамках выполнения государственного задания в сфере науки, номер темы QRPK-2024-0011).












Список литературы
Список использованной литературы появится позже.