
What happened to Complexity? A review of definitions, measurement and challenges
Aннотация
The widely recognised multi-compositionality of linguistic complexity has led scholars to formulate several definitions of the construct according to the perspective taken on the matter in each field. The measurement of English complexity, in particular, seems to have long relied on a few indices, mainly lexical and morpho-syntactic, which in some cases appear to have been preferred over other measures for their ease of computation rather than methodological effectiveness. The picture of complexity emerging from the present review is that of a construct that often still lacks a thorough and shared definition and operationalisation. Notwithstanding these issues, it is argued that investigating linguistic complexity is still important and its study becomes more tractable when 1) it is carefully discerned from cognitive complexity (i.e., difficulty), thus when the linguistic forms characterising a text and their functions are studied separately from the implications these have on cognitive processing; 2) resorting to evidence-based inductive approaches, which reduce the impact of the set of a priori assumptions inherited from traditional categories of linguistic analysis about how language works; 3) adopting a register-functional approach, which adds an explanatory dimension to the study of linguistic complexity by taking into account how the communicative purposes, the type of audience and the production circumstances of a text influence its complexity.
К сожалению, текст статьи доступен только на Английском
1. Introduction
The construct of linguistic complexity has always been elusive and problematic from the point of view of its definition, operationalisation and measurement (Norris, Ortega, 2009; Pallotti, 2009; Bulté, Housen, 2012; Housen et al., 2019; Joseph, 2021; Biber et al., 2022). Many scholars have tried to contribute to the debate by widening or narrowing its scope and proposing an array of complexity indices for measurement (Norris, Ortega, 2000; Arends, 2001; McWhorter, 2001; Nichols, 2009; Trudgill, 2001, 2004; Miestamo, 2008; Bulté, Housen, 2012; Kortmann, Szmrecsanyi, 2015; Lintunen, Mäkilä, 2014; Pallotti, 2015; Biber et al., 2022). Nonetheless, a comprehensive theory which could account for the complexities of all levels of linguistic analysis, i.e., grammatical, lexical, phonological, pragmatic, was never put forward. Dealing with one level of linguistic complexity or the other requires different theoretical frameworks and measures, also mirroring the linguistic field within which the studies on complexity are being conducted: for instance, the approach to complexity in linguistic typology is different from the one adopted in second language acquisition (SLA henceforth) with the former mainly focusing on structural complexity, i.e. the complexity of a language system, and the latter on developmental complexity, i.e. the complexity of the process of language learning and acquisition.
Most of the problems concerned with the definition of linguistic complexity lie with the terms that have been used in the literature to describe it, which are recognised to be vague and circular (Bulté, Housen, 2012; Joseph, 2021; Biber et al., 2022). For example, from the SLA perspective Skehan (2003: 8) claims that complexity ‘refers to the complexity of the underlying interlanguage system developed’ and Ellis and Barkhuizen (2005: 139) define complexity as the ‘use of challenging and difficult language.’ These tautological statements do not allow to pose a common basis as to what ‘complex’ actually means in linguistics and how to establish whether certain linguistic features or structures are more complex than others, both within the language and across languages (cf. Equicomplexity Hypothesis, Dahl, 2004; Kusters, 2003; McWhorter, 2001; Miestamo, 2006).
An array of different definitions of linguistic complexity have been put forward in the literature (e.g., structural, cognitive, discourse-interactional), each one touching upon one or more dimensions of complexity (see Section 2). Among these, perhaps the most cited is Miestamo’s (2008) articulation of linguistic complexity into absolute and relative complexity, which introduced the important distinction between the complexity intrinsic to a language system (e.g., phonological, lexical and syntactic inventory and rules) and the impact of user’s variables (such as motivation, L1 background, etc.) on the complexity of their linguistic production. In fact, complexity can be articulated into at least three main sub-constructs: one is the complexity of the structure, i.e., the language system under analysis with its features and rules; another is cognitive complexity which involves the cognitive cost (i.e., difficulty) required by the processing of more or less complex language (Hulstijn, Graaf, 1994); the last is developmental complexity, which corresponds to the order in which language features and rules are acquired and mastered in both first and second language acquisition (Bulté, Housen, 2012; Pallotti, 2015). Discerning between structural, cognitive and developmental complexity, however, represents only a first step into defining the components of such a multi-faceted construct. Moreover, provided one manages to satisfactorily define its sub-constructs, it is rarely made explicit how the sub-constructs stand in relation with one another as well as where they overlap. A further issue with the systematisation of linguistic complexity is represented by the identification of analytical measures, as this stage heavily depends on the formulation of definitions concerning what counts as complex, how linguistic features are placed on the continuum less-to-more complex, and what are the measures that could reliably provide a quantitative indication of the degree of complexity of a feature or dimension under study.
2. Aims and methodology
The present review provides an overview on the definitions, operationalisation and measurement of English complexity as dealt with in the literature between the decades 1900-2020 with a focus on the challenges and issues presented by this construct. The final aim is to propose a number of adjustments to be implemented in the study of complexity that could solve some of the issues that have earned complexity the label of ‘intractable’ construct (Joseph, 2021).
The questions that will be answered are:
- Which definitions of linguistic complexity are there and what are their limitations?
- How has linguistic complexity been measured so far?
- What methodological changes could improve the reliability of complexity studies?
The theories reported in the paper and the related operationalisations through a number of indices and complexity measures will be critically discussed in order to highlight the ways in which such theories and measures can be biased or ineffective. This step is particularly relevant since many studies on complexity have simply borrowed measures and indices without testing whether these could yield reliable results.
For reasons of space, the paper focuses on English linguistic complexity and its relation to SLA, which has fostered a substantial body of scholarly production and discussion on the topic (see DuBay, 2004; Nelson et al., 2012; Pallotti, 2015; Joseph, 2021). The author, however, is aware of the contribution made by functional-typological studies (e.g. Kusters, 2003; Miestamo, 2006, 2008; Nichols, 2009; Sinnemäki, 2011; Di Garbo, Miestamo, 2019) to the debate on linguistic complexity and will occasionally resort to them.
It will be maintained that changing the approach to the definition of complexity, while also becoming aware of certain linguistic bias, substantially improves the quality of research and the reliability of results.
The paper is structured as follows: definitions of linguistic complexity are illustrated in Section 3 from the first global definitions of ‘code complexity’ to the articulation into sub-constructs of linguistic complexity; Section 4 outlines the measures of complexity and discusses the limitations; Section 5 deals with the complexity of written vs. spoken language; finally, in Section 6 methodological adjustments are proposed and conclusions are drawn.
3. Definitions of complexity
It is difficult to find a commonly accepted definition of linguistic complexity in the literature (Bulté, Housen 2012: 22, Pallotti, 2009), due to the polysemy of the term ‘complexity’ itself. As Pallotti (2015: 2) points out, even when looking at the dictionary definition of complexity, the term encompasses at least two main meanings: the first underlines the multi-compositionality of complex items as ‘composed of two or more parts’; the second highlights the difficulty implied in something complex as ‘hard to separate, analyze or solve’[1].
The first notions of ‘code complexity’ (Candlin, 1987, Skehan, 1996), thus complexity applied to language, were proposed by researchers who, as many teachers and lay people, noticed that some communicative tasks appeared to be more difficult than others in that they required more complex language, such as sophisticated vocabulary and syntactic structures, to be processed and produced. Linguistic complexity, in other words, has long been bound to the concepts of effort and difficulty. As a consequence, certain expressions, namely long structures and infrequent words, were deemed linguistically complex because generally perceived as difficult to process (cf. DuBay, 2004, Nelson et al., 2012). Between the 1800s and 1960s the literature focused on the implications length, frequency and predictability of linguistic expressions had on linguistic complexity: Sherman (1893) studied the sentence length of novels and noted that sentences were becoming shorter, thus simpler, over time; Zipf (1935) highlighted how frequent words in languages tend to be short, thus optimising form-meaning matching by requiring less processing effort (cf. Law of Abbreviation; Principle of Least Effort); Shannon (1948) related the unpredictability of the occurrence of certain words or expressions in a context to complexity; focusing on the written text, the literature on readability (Kitson, 1921; Lively, Pressey, 1923; Thorndike, 1934; Gray, Leary, 1935; Lewerenz, 1935; Patty, Painter, 1931; Flesch, 1948; Klare, 1963, 1974-5; Fry, 1968) claims that shorter sentences and words, as well as frequent vocabulary items, promote reading ease. Finally, with Chomsky (1957), syntax too begins to be given considerable importance in contributing its own complexity to the text, which is not only related to the length of sentences but also to the underlying rules of combination of its elements.
Over time complexity turns out to be a broader construct than the one originally outlined and begins to include different aspects of linguistic competence and sophistication. As mentioned in Section 1, two broad definitions of complexity become most often adopted and investigated in the literature around the years 2000s: absolute complexity and relative complexity (Miestamo, 2008).
Absolute complexity refers to the degree of sophistication of a language system. This approach studies the number of parts a linguistic system is composed of (e.g., sounds, vocabulary, morphological marks, etc.) together with the number and types of connections between the parts (e.g., word formation rules, syntactic rules, etc.). As outlined by Pallotti (2015), the expression ‘structural complexity’ is often preferred to ‘absolute complexity’, since the latter implies the existence of a theory-free description of language which is, in fact, very unlikely (Kusters, 2008: 8); what is complex according to an analytical framework or theory might not be according to another (Bulté, Housen, 2012: 26). The study of structural complexity is approached in two main ways (Dahl, 2004: 51): one is through Kolmogorov complexity (Li, Vitányi, 1997) according to which complexity directly corresponds to the length of the description of a linguistic feature or language system; the second is descriptive complexity which, in a similar way to Kolmogorov complexity, still defines structural complexity in quantitative terms, yet instead of considering the length of descriptions as an indicator of complexity, it counts the number of different elements in a linguistic production – or language system – and their interconnections (Pallotti, 2015: 4). For instance, German pronominal system requires a longer description than the English one. Similarly, the number of features expressed by German personal pronouns is higher compared to English pronouns. Indeed, German pronominal paradigm is characterised by a rich case system which marks accusative and dative by suffixation, whereas English pronouns have fewer cases marked by suffixation (see table 1 below); the dative case is marked in English either by the prepositional phrase to + Noun Phrase or by the accusative case in double accusative constructions (e.g., She gave him a book). Furthermore, differently from English, German encodes the distinction between formal and informal address on the second person, namely du vs. Sie, which produces pairs of second person pronoun forms in the plural, and in the accusative and dative cases (see table 1 below). Therefore, according to the quantitative parameters used to measure structural complexity (including Kolmogorov complexity), German personal pronouns are more complex than English personal pronouns.
Table 1. Personal pronouns in German and English
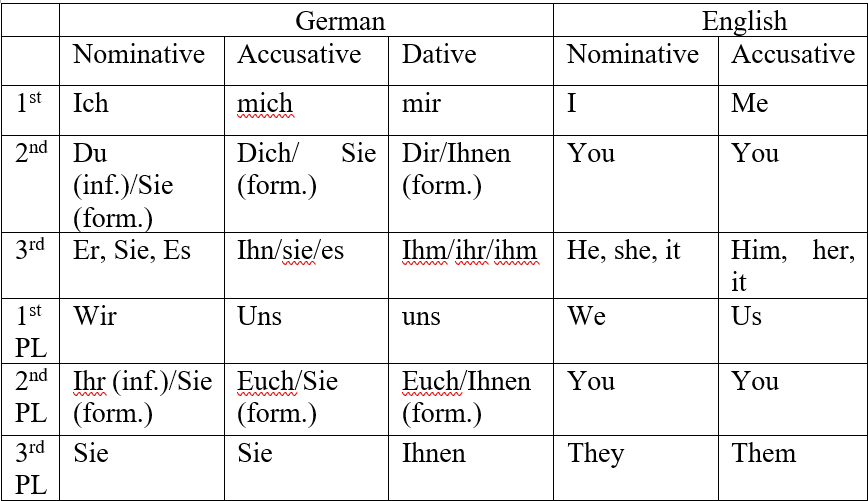
Although conceptually straightforward, descriptive complexity may be a not so reliable construct for two reasons: first, the linguistic systems and sub-systems in which a lack of order is observed will be deemed more complex (Sinnemäki, 2011), since they will require longer descriptions. For example, irregular verb morphology in English would generate a longer description than regular verb morphology. Nonetheless, length of description does not constitute proof of complexity (Pallotti, 2015) due to the second reason i.e., the descriptive approach is deeply theory-laden as the length of the description depends on the analytical categories adopted (Joseph, 2021). In other words, being the analytical categories mainly based on Latin, the attempt to make traditional linguistic categories fit other languages is bound to produce longer descriptions, especially the more the language under analysis drifts apart from the one on which the analytical categories are based. This becomes particularly evident when looking at functional-typological studies, in which the categories used to analyse European languages are often not suitable to be applied to languages spoken outside of Europe (cf. Miestamo, 2008). Therefore, longer descriptions might not necessarily correspond to an actually higher degree of complexity as, simply, to a lack of appropriate labels and, ultimately, to biased analyses.
The second most common sub-construct of complexity is labelled relative complexity, since complexity is studied in relation to the language user and how individual variables affect the mastery of a second language (L2 henceforth). In particular, relative complexity investigates, on the one hand, the impact the structural complexity of the L2 exerts on teaching and learning (DeKeyser, 1998; Doughty, Williams, 1998; Spada, Tomita, 2010; Bulté, Housen, 2012) and, on the other hand, the linguistic complexity of the L2 output produced by learners. Furthermore, it makes inferences about the cognitive complexity (i.e. difficulty) experimented by the learner by looking at the order of acquisition of a number of linguistic features (e.g. 3SG present tense -s, passive constructions, relative clauses) based on the assumption that features that appear later in language development must be more difficult to master. While the impact of linguistic complexity on teaching and learning is believed to be related to the structural complexity of the target language, the complexity of the production of L2 learners is seen as the mirror of a learner’s stage of acquisition and level of proficiency as well as the result of the influence of learners’ individual variables such as linguistic and cultural background, motivation, attention capacity, identity, etc. (Bygate, 1996; Derwing, Rossiter, 2003; Collentine, 2004; Norris, Ortega, 2000). Relative complexity in English has been eagerly studied in SLA through the Complexity, Accuracy, Fluency (CAF) paradigm (cf. Hunt, 1965; Brown, 1973; Skehan, 1996; Pallotti, 2009; DeKeyser, 2005 for a detailed discussion). Within the CAF paradigm, complexity is a characteristic of the learner’s output and is related to the ability to produce linguistically demanding language in both variation and sophistication i.e., considering both quantitative (e.g., length, frequency of units) and qualitative (e.g., types of dependency) aspects (Ellis, Barkhuizen, 2005). This falls within the conception of ‘more is more complex’, whereby complexity ends up corresponding to a greater number of components in a unit and deeper levels of embeddings e.g., clauses occurring as part of other clauses, as happens in subordination (Bulté, Housen, 2012; Verspoor et al., 2017). In SLA complexity is most often investigated in terms of systemic complexity of an L2 learner’s system through measures of global elaborateness (Bulté, Housen, 2012: 26) which bring together the learner’s phonological, morphological, lexical, syntactic systems and so on. However, as pointed out by Bulté, Housen (2012: 22), studies on L2 complexity have often produced contradictory results, probably as a consequence of the ways in which complexity has been defined and operationalised in the first place. For example, the 3SG present -s in English has been characterised as simple (Krashen, 1994), formally simple yet functionally complex (Ellis, 1990) and formally and functionally complex (DeKeyser, 1998). A further limitation of L2 complexity studies can be found in the fact that the descriptions of a learner’s interlanguage complexity have short-term value given the intrinsic variability and lack of stability of the interlanguage system (Pallotti, 2015). What can be observed is the complexity of learners’ linguistic production at some stage of acquisition through the analysis of their production (e.g., texts and utterances), bearing in mind that any claim and generalization about the interlanguage system and its global complexity would represent a mere inference obtained from a few facts (Pallotti, 2015: 3).
3.1. Sub-constructs of complexity
Given the variability and proliferation of definitions of complexity, Bulté and Housen (2012: 23) propose a unified graphic representation of complexity constructs, which is reported in figure 1 below. Since their work adopts the L2 research perspective, both absolute and relative complexity are joined under the construct of L2 complexity, also given the intuition by many scholars about the interplay between absolute/structural complexity and relative complexity. Although the relationship between the two has not been clarified yet, scholars are prone to hypothesise, based on both experience and the results of cognitive studies (cf. Goldschneider, DeKeyser, 2001; DeKeyser, 2005), that the structural complexity of a linguistic feature may trigger what is referred to as difficulty (see figure 1 below) and more precisely defined as cognitive complexity i.e., the cost of using or learning and mastering that feature (see below).
Figure 1. Constructs of complexity: a taxonomy (Bulté, Housen, 2012: 23)
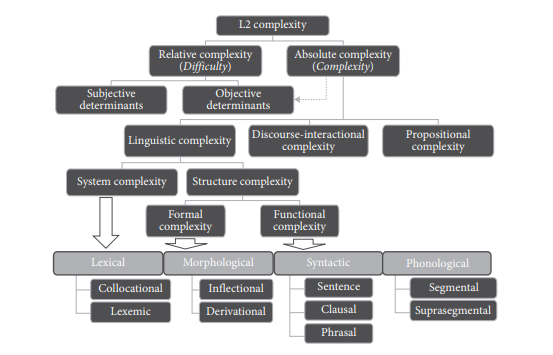
As can be observed in Figure 1 above, both absolute and relative complexity can be analysed on different levels, which vary according to the scope and dimension of language analysis. Structural complexity can be investigated locally by focusing on single aspects of the phonology, lexis, morphology or syntax, which can be analysed both formally (e.g. length, number of morphemes, lexical variation) and functionally (e.g. type of clause, semantic processes). On the phonological level, the aspects investigated in terms of complexity can be the size of the phoneme inventory, tonal distinctions, the maximum complexity of consonant clusters, the incidence of marked phonemes (Nichols, 2009; Shosted, 2006). Morphological complexity can be investigated through a mapping of the inflectional and derivational morphology, the degree of allomorphy, the number and types of morphophonemic processes (Kusters, 2003; Dammel, Kürschner, 2008; Pallotti, 2015). Syntactically, complexity can be investigated by looking at the level of clausal embedding permitted by the language, dependencies, the number of syntactic rules, the degree of movement allowed to the items in a sentence (Ortega, 2003; Givón, 2009; Karlsson, 2009). From a semantic and lexical point of view, complexity can be found in the degree of transparency (with one-to-one mapping of meaning onto form being considered less complex), homonymy and polysemy, the size of the vocabulary, the inclusive/exclusive distinction marked on pronouns, lexical variation, collocations, etc. (Fenk-Oczlon, Fenk, 2008; Kuiken, Vedder, 2008; Nichols, 2009; Bulté, Housen, 2012).
Structural complexity can be further combined with higher-level complexities which are relevant to the analysis of discourse, such as pragmatic complexity,propositional complexity, interactional complexity (Ellis, Barkhuizen, 2005). Pragmatic complexity, also labelled ‘hidden complexity’ (Bisang, 2009), concerns the quantification of pragmatic inferencing and its relationship with markedness and ambiguity (cf. Kilani-Schoch et al., 2011). Propositional complexity refers to the number of ideas encoded by the speakers in order to convey a given message (Zaki, Ellis, 1999; Ellis, Barkhuizen, 2005). Thus, the more idea units are encoded in narrating a story, the higher its propositional complexity. However, the authors do not explicitly state what exactly corresponds to an ‘idea unit’ and how it is measured. Even the definitions of proposition found in the literature (Kintsch, Keenan 1973, Kintsch 1974, Turner, Greene, 1977) tend to vary according to whether certain elements are considered as constituting new propositions or as part of other propositions (e.g. the information contributed by verb tense and aspect, verb arguments, nouns, adjectives, etc.). It derives that the measurement of propositional complexity may oscillate greatly depending on the definition of ‘idea unit’ chosen. Discourse-interactional complexity (Young, He, 1998) measures how interactive a speaker gets in group exchanges. Interactional competence is defined as the knowledge and ability developed as a result of ‘interactional processes during interactive tasks such as negotiation of meaning, feedback, and production of modified output’ (Kim, 2009: 255). This type of complexity requires the mastery of processes such as corrective feedback, confirmation checks, recasts, metalinguistic comments as well as interaction management. It is a discursive practice in which participants are expected to recognise and to comply with expectations of participation in discourse by contributing with cultural, identity, linguistic and interactional resources (Morales, Lee, 2015: 34).
Taken all together, the different sub-constructs of linguistic complexity constitute parts of absolute complexity, which in the taxonomy by Bulté, Housen (2012) is conceived as an overarching construct comprising structural complexity. Absolute complexity, in turn, is seen as a determinant of relative complexity, which combines with user-related variables (i.e. subjective determinants) and ultimately results in the degree of difficulty experimented by a learner, thus making relative complexity overlap with cognitive complexity (Burleson, Caplan, 1998; Bell, 2004). In this view, complexity also needs to be defined in terms of what is cognitively costly or difficult to language users. However, many scholars have warned about the relativity of the concept of difficulty and the issues of including it in the definition of linguistic complexity. For example, based on psycholinguistic studies Kusters (2003) argues that a first hint of the relativity of difficulty is to be found in the different effects it has on speakers as opposed to hearers. In particular, Kusters (2003) reports that redundant agreement is found to be difficult to learn for L2 users, yet represents no burden for L1 speakers and facilitates the task of both L1 and L2 hearers (cf. Miestamo, 2008: 5). A second hint to the relativity of difficulty can be found in the development of proficiency: the more the learner’s competence evolves, the more the L2 becomes second nature to them, the less the perceived cognitive complexity. A third point supporting the relativity of difficulty lies in the fact that the degree of difficulty experimented will depend on how accustomed learners are to certain structures and vocabulary (Van der Slik et al., 2019; Joseph, 2021). For example, speakers of languages that do not possess noun declension will find more difficult to learn a second language that does. Thus, the real question to be discussed when including difficulty in the construct of complexity is: ‘complex to whom?’. The question would probably yield no user-type-neutral definition of complexity (Miestamo, 2008: 5) and represents a pivotal point which throws into question what the differences in structural complexity really mean and whether they are mere artifacts of the structural analysis linguists apply (Joseph, 2021).
In an attempt to adopt a more objective, user-independent perspective which would measure the cognitive cost of processing certain linguistic structures independently of the individual learner’s variables, difficulty has been reformulated and investigated in terms of cognitive complexity (cf. Bieri, 1955 for a psychological approach, Wang et al., 2012 for a mathematics-based cognitive linguistic approach). Among user-independent factors contributing to cognitive complexity attention has been paid to perceptual salience, frequency of occurrence, imageability and perceptibility (Goldschneider, DeKeyser, 2001; DeKeyser, 2005). Perceptual salience can be defined as an intrinsic property of certain linguistic entities which makes them more easily noticed (Kerswill, Williams 2002); for example, syllabic grammatical suffixes are more perceptually salient than non-syllabic ones e.g., the past tense syllabic /Id/ was found to be more easily attended to than the non-syllabic /t/ or /d/ (as in learned or kissed) (Goldschneider, DeKeyser, 2001; Klein et al., 2004). Syntactically, items occurring at the beginning or at the end of sentences are observed to be prioritised compared to items occurring in other positions. Indeed, marked word orders such as dislocations use sentence peripheries as loci for highlighting dislocated items and draw attention to them (Biber et al., 1999, 2021). Frequency of occurrence, therefore frequency of exposure, allows to draw attention to common expressions and to memorise them (Caruana, 2006; Van Lommel et al., 2006; Ghia, 2007). Imageability describes the ease with which a linguistic expression and its meaning can be associated with a mental image (Ellis, 1999; Griffin, Ferreira, 2006). The imageability factor is particularly evident in the difference between content and function words, with content words being more easily visualised, thus, prioritised in processing. Perceptibility refers to how easily the linguistic expression can be perceived (Goldschneider, DeKeyser, 2001; Gagarina, 2002): factors influencing perceptibility are, for example, the length of the expression, with longer items being more easily perceptible than short ones, and clarity of articulation, with voiced syllables being more perceptible than unvoiced ones (Ellis, 1999; DeKeyser, 2005). These quantitative and qualitative factors affect cognition in a proportionally inversed fashion: the less frequent, perceptible, imageable and salient a linguistic element is in its context, the more cognitively complex. It follows that more cognitively complex linguistic expressions are less easily, thus less likely, noticed and internalised in a context of L2 learning (Bley-Vroman, 2002; Bybee, 2008). Psycholinguistic studies have also demonstrated a relation between cognitive complexity and syntactic complexity showing how relative clauses and passives are harder to process than other structures such as coordinate and active structures (Diessel, 2004; Byrnes, Sinicrope, 2008). Cognitive complexity has always been an integral part of SLA studies because it is believed to be intertwined with developmental timing. In other words, what is acquired later in the process of developing an L1 or L2 was considered more cognitively complex (Diessel, 2004; Byrnes, Sinicrope, 2008). However, as intuitive as might seem to deem the occurrence or non-occurrence of certain features at a certain developmental stage as related to cognitive complexity, this would only represent ‘perceived’ cognitive complexity i.e., difficulty. Objective cognitive complexity is hardly demonstrable (Pallotti, 2009) unless brain-activity imaging techniques such as fMRI and PET scans are employed.
4. Measures of complexity
There is no shortage of measures of complexity, as highlighted, among others, by Bulté and Housen (2012) who provide a full inventory of the most and least used complexity indices (reported in Table 2 below). The inventory is divided into two main categories: indices of grammatical complexity, which comprise syntactic and morphological measures, and indices of lexical complexity, which deal with diversity and sophistication. The measures of syntactic complexity generally aim to quantify the range of syntactic structures, length of unit, degree of structural complexity of certain structures and amount and type of coordination, subordination and embedding. These measures tap into different layers of the syntactic structures by focusing on the phrase, clause or sentence/utterance (Norris, Ortega, 2009). The measures of morphological complexity deal with the number of morphemes and their inflectional or derivational function (Bulté, Housen, 2012). Lastly, the measures of lexical complexity aim to quantify how dense a text is, how variable its vocabulary is and whether less frequent words are used.
Table 2. Measures of complexity (Bulté, Housen, 2012: 30)
- GRAMMATICAL COMPLEXITY
- Syntactic
- Overall
- Mean length of T-unit
- Mean length of c-unit
- Mean length of turn
- Mean length of AS-unit
- Mean length of utterance
- S-nodes/T-unit
- S-nodes/AS-unit
- Sentential – coordination
- Coordinated clauses/clauses
- Sentential – subordination
- Clauses/AS-unit
- Clauses/c-unit
- Clauses/T-unit
- Dependent clauses/clauses
- Number of subordinate clauses
- Subordinate clauses/clauses
- Subordinate clauses/dependent clauses
- Subordinate clauses/T-unit
- Relative clauses/T-unit
- Verb phrases/T-unit
- Subsentential (Clausal + Phrasal)
- Mean length of clause
- S-nodes/clause
- Syntactic arguments/clause
- Dependents/(noun, verb) phrase
- Other (+/- syntactic sophistication)
- Frequency of passive forms
- Frequency of infinitival phrases
- Frequency of co-joined clauses
- Frequency of wh-clauses
- Frequency of imperatives
- Frequency of auxiliaries
- Frequency of comparatives
- Frequency of conditionals
- Morphological
- Inflectional
- Frequency of tensed forms
- Frequency of modals
- Number of different verb forms
- Variety of past tense forms
- Derivational
- Measure of affixation
- LEXICAL COMPLEXITY
- Diversity
- Number of word types
- Type-Token Ratio
- Mean segmental Type-Token Ratio
- Guiraud Index
- Lexical richness
- Diversity
- Density
- Lexical words/function words
- Lexical words/total words
- Sophistication
- Less frequent words/total words
Three indices are mostly used to measure syntactic complexity: length of clause, number of phrases per clause and number of clauses per unit (see Table 2 above) (Van Valin, La Polla, 1997; Lu, 2010). Different degrees of complexity are assumed in the calculation of a variety of syntactic complexity measures such as the Syntactic Complexity Formula by Botel et al. (1973) and the Elaboration Index by Loban (1976), which assign syntactic structures different weights according to putative different degrees of difficulty. Subordinate structures are generally given great weight in the measurement of complexity because they are believed to be cognitively harder to process compared to other strategies of linking (Bygate, 1999; Biber et al., 2022). However, as already stated in Section 3, different degrees of difficulty in processing some syntactic structures do not necessarily and automatically correspond to syntactic complexity, since it is not demonstrated that there is a correspondence between the two (Pallotti, 2009; Bulté, Housen, 2012). A different approach to investigating syntactic complexity focuses on the number of word order patterns allowed in a language or present in a text. This approach is more typical of typological studies and brings about the issue of establishing what counts as pattern, also considering that even basic word orders are not particularly easy to identify (Dryer, 2007). Adopting Kolmogorov complexity in this context would mean deeming more complex the texts exhibiting a higher variability of syntactic patterns, whereas adopting a quantitative perspective, the occurrence of regular word order patterns would be counted (Pallotti, 2015). Therefore, a linguistic production using a variety of regular word orders (e.g., basic, clefts, dislocations) would be said to be more complex than one using less variation and adhering to the same word order throughout the text.
Morphological complexity has not been investigated in many studies on English (Pallotti, 2015). The morphological measures employed in the study of complexity include frequency of tensed forms, number of different verb forms, variety of past tense forms (Bulté, Housen, 2012). All of these, however, deal with verbal morphology. Pallotti (2015) proposes measures of inflectional morphology that explore the relationship between the forms of lexemes and the semantic or syntactic features they express, such as gender, number, case, person. Starting from a quantification of the basic word classes (e.g., noun, verb, adjective, adverb, etc.), their ‘exponents’, i.e., the forms in which the lexemes are turned so as to express grammatical information, are investigated. This implies the identification of stems (i.e., the base forms of the lexemes) and then the inflection. Obviously, the process is more straightforward with concatenative morphological processes such as suffixation (e.g., book-s), whereas it becomes harder to identify in non-concatenative processes with internal stem change, such as the past tense forms of irregular verbs (e.g., flew as a past form of fly). Periphrastic morphemes are treated as a single operation (e.g., be V-ing or have V-en) and different strategies for expressing the same grammatical function are counted as separate operations, as happens with the past tense marked with suffixation (e.g., arriv-ed), suppletion (e.g., went) or stem change (e.g., took). Being this measure type-based, it is sensitive to text length, therefore it will become more accurate the more data are available. Another measure of morphological complexity is proposed by Haspelmath and Sims (2010) and deals with the relationship between form and function by classifying as more complex the exponents encoding more features than others. In other words, if nouns are inflected for number and case in one language and only for number in another language, the former will be considered more complex.
Lexical complexity aims to measure the number of components of the lexical system leaving out the analysis of semantic complexity (e.g., specificity, transparency, concreteness, polysemy). While the semantic aspects of complexity are undeniably important, they also tend to be difficult to measure objectively (Pallotti, 2015). Thus, lexical complexity is usually calculated by measuring variation based on the assumption that a linguistic production where lexemes are diversified will be deemed more complex than a production with a higher number of repetitions. The most frequently used measures of lexical complexity are the type-token ratio, which quantifies lexical variation, lexical density, i.e., the amount of information encoded in a text quantified by focusing only on the lexical words in a text, and core vocabulary, i.e., the list of the most frequent 7000-7500 words in the entire language system (Halliday, 1985; Stubbs, 1996; Biber et al., 1999; Rundell, 2007).
The measurement of discourse-interactional complexity, which is not included in Bulté and Housen’s (2012) taxonomy, is carried out by quantifying the extent of a speaker’s contribution to the interaction (Young, He, 1998; Ellis, Barkhuizen, 2005; Kim, 2009; Morales, Lee, 2015). The more regularly a speaker contributes to a communicative exchange the higher their interactional complexity. Two scales are generally used to measure it: the index of elaborate and complex interaction counts the total number of turns performed by each speaker and calculates a ratio between the total number of words produced by each speaker divided by the total number of turns taken by each speaker. The density of interaction measures how many exchanges there are in an interaction. The more actors have connections with others, the denser the interaction is. As these measures require a qualitative analysis of the interaction, they are difficult to apply to large datasets.
As far as the reliability of measures of complexity is concerned, the studies in English L2 acquisition using length measures show mixed results (Bulté, Housen, 2012). Scholars such as Larsen-Freeman and Strom (1977) and Wolfe-Quintero et al. (1998) maintain that syntactic measures of complexity are reliable when picturing only a coarse-grained development of L2 proficiency. Other researchers, such as Dewaele (2000) and Unsworth (2008) point out that linear results follow circular argumentation depending on how the linguistic unit and proficiency levels are defined. Although measures of subordination are considered more reliable indices of complexity, Norris and Ortega (2009) notice that subordination appears only at later stages of L2 development (i.e., intermediate), while at advanced stages complexity is mainly achieved through the sophistication of phrases (see also Biber et al., 2022). Therefore, Norris and Ortega (2009) underline the importance of including measures of coordination and phrasal complexity, such as the Coordination Index and the Mean Length of Clause. Concerning the latter, however, Bulté and Housen (2012) refrain from considering it as a pure measure of phrasal complexity given that clause length also increases through the addition of adjuncts (e.g., time, manner, place), thus still at the clausal level and not only through the expansion of the phrase via pre- and post-modification.
The picture resulting from comparing measures of linguistic complexity and the follow-up discussion about their effectiveness and reliability is one characterised by variability and several limitations. Besides observing a preference for only a number of measures that are easy to compute (e.g. syntactic vs semantic measures) (Bulté, Housen, 2012: 34), indices of linguistic complexity vary according to the definitions provided for the parts that are counted. In order to be able to measure any dimension of complexity and to obtain comparable results, scholars would have to agree on how several linguistic units are defined i.e., what is intended by ‘word’, ‘clause’, ‘phrase’, etc. For example, it is necessary to decide whether the unit ‘word’ comprises compounds or multi-word expressions: does sports car count as one or two words? (Booij, 2012; Pallotti, 2015). As far as the clause is concerned, provided that the verb phrase is essential to have a clause (Van Valin, La Polla, 1997), does its definition include non-finite forms of verbs as well? And does the subject of the verb need to be explicitly expressed? It should also be defined what a complex predication is and whether predicates such as keep trying, make stop, begins to rain constitute a single clause or multiple clauses (Bulté, Housen, 2012). A further issue is represented by coordinated phrases, such as the boy and the girl, as it needs to be established whether they should be treated as a single constituent, thus representing only one slot in the argument structure, or as two constituents (Pallotti, 2015). Furthermore, it should be decided whether clauses can be combined into overarching units. For example, Hunt (1965) introduced the T-Unit[2] and Foster et al. (2000) introduced the AS-Unit[3], which comprise a main clause with all its dependent clauses leaving coordinated clauses out to be interpreted as new units. The explicitation of what is intended when referring to the different units of measurement is the first step to be taken when segmenting a text with the aim of counting its parts, as happens with type-token ratios, clauses per text, length of clauses and so on. Any variation in these definitions could result in different numerical values and ultimately affect the validity and comparability of results.
5. The complexity of written versus spoken language
Most empirical studies about complexity have focused on written texts (Ortega, 2012). As a consequence, it is likely that the measuring tools fitting written language might not perform as well when applied to spoken language. Since spoken language exhibits specificities in the syntax, vocabulary and communicative strategies which differ from written language, it is worth asking whether linguistic complexity in spoken language should be expected to be operationalised and measured in the same way as written language. As Biber et al. (1999, 2021) highlight, spoken language is typically syntactically more fragmented (cf. also Greenbaum, Nelson, 1995), with a freer organisation of discourse, uses more general rather than specific or technical vocabulary, hedging devices, vocatives and interjections, discourse markers, false starts, politeness and conversational formulae. If one adopts the definition of complexity as ‘lexical and syntactic sophistication’, it follows that spoken language is not very complex, being it mainly characterised by coordination, short units and low degree of embedding (Biber et al., 1999, 2021). However, if pragmatic and interactional complexity were taken into account and measured thoroughly, spoken language would likely result to be more complex than when only considering lexical and syntactic complexity indices. Spoken language, indeed, especially conversation, heavily relies on inferences and implicatures i.e., cognitive processes that draw on the situational context and shared knowledge (cf. Kilani-Schoch et al., 2011) and represent a sort of ‘invisible’ complexity. As Halliday (1985) claims, neither spoken nor written language is more complex than the other per se; the two varieties display different degrees of complexity on different levels (see also Biber et al., 2022). Therefore, the question revolves around the central issue of identifying the best sub-constructs of complexity to be investigated according to the aims of the study as well as the type of data under investigation.
A first problematisation of the measures of complexity taking into account the differences between written and spoken language is found in Lintunen and Mäkilä (2014). The study focuses on the syntactic complexity of written and spoken production by 18 L1 Finnish learners of L2 English. The authors observe that when changing the unit of segmentation of the data (they use the U-unit[4] instead of the traditional T-unit and AS-unit), spoken language appears to be more similar to written language in terms of syntactic complexity. Therefore, it is called for further studies with the aim of uncovering whether the differences in complexity between written and spoken language are due to either the nature of the modes or the units and measures used in the analysis.
Aiming to find measures of complexity that could perform efficiently on spontaneous spoken language, Lahmann et al. (2019) study highly proficient L2 English speakers and L1 German attriters. By focusing on grammatical and lexical complexity, the authors analyse a corpus of oral history testimonies to confirm the multidimensionality of the two sub-constructs of complexity. The study also puts forward the possibility to reduce the number of traditional measures of complexity (following Bulté, Housen, 2012) after noticing considerable overlap. Grammatical complexity is shown to be captured by measures of length and subordination. Lexical complexity is recognised to be a multidimensional construct that needs to be articulated in at least two sub-constructs, namely lexical diversity and lexical sophistication. The latter, in turn, should be analysed in terms of abstractness and hypernymy as well as polysemy. The authors conclude that the measures of lexical complexity could be reduced to three essential ones: frequent, infrequent and abstract lexical items.
Stemming from empirical evidence, a problematisation of the definition of complexity in relation to modes of expression can be found in Biber et al. (2022) who observe, after having compared a number of corpus-based studies on the differences between spoken and written language, that the two registers are characterised by two different types of complexity. The complexity of the spoken register lies in the regular use of long and structurally elaborated dependent clauses (see 1 below), whereas the complexity of the written registers can be witnessed in the embedding of the noun phrase. In other words, complexity in writing (in particular, specialist and academic) is to be found in linguistic units containing phrases embedded in other phrases as well as a low occurrence of verbs. This results in ‘compressed’ structures in which the relationship between phrases (i.e., premodifiers and head) is not always clear; see, for example the phrases system perspective and new systemic mechanisms in (2) below reported from Biber et al. (2022, Ch. 5, Section 3, para 3).
(1) Sentence from conversation:
But I don’t think [we would want [to have it [sound like [it’s coming from us]]]].
(2) Sentence from a university sociology textbook:
From the system perspective, these stages are marked by the appearance of new systemic mechanisms and corresponding levels of complexity.
Spoken registers are found to express complexity through adverbial and complement clauses, thus as clause modifiers, whereas academic written registers tend to express complexity through noun modification (Biber et al., 2022). The point on which particular attention is drawn is the fact that grammatical complexity cannot be considered as a unified concept, as there are different ways in which structure can be made complex and these ways essentially represent different types of grammatical complexity, namely clausal vs. phrasal (Biber et al., 2022). Clausal vs. phrasal complexification is a distinction that also mirrors two developmental stages of linguistic competence: studies of child language acquisition, such as Givón (2009), Hunt (1965) and Diessel and Tomasello (2001), have shown that clausal complexity is developed earlier than phrasal complexity. More specifically, the latter continues to be acquired into adulthood (i.e., university education) and is not necessarily fully acquired or mastered, also given its use being limited to specialist academic writing (Biber et al., 2022).
6. Discussion and conclusion
This article has proposed an overview of the definitions of linguistic complexity, its measurement and the issues related to its investigation between the decades 1900-2020. The multi-faceted nature of the construct of complexity brings out issues when comprehensive and unambiguous definitions need to be provided. Even the most agreed-upon definitions in the literature correspond to a number of constructs and sub-constructs characterised by different focuses and research aims which call for different analytical frameworks and measures. Nonetheless, it is acknowledged that several of these complexity constructs may be, in reality, intertwined, although it seems complicated to identify the boundaries between them and understand the nature of the interplay of the sub-constructs with each other. Despite the issues and limitations related to its investigation, the many theories and attempts at measuring complexity show that there is a common intuition that complexity is there in the language and deserves some attention.
In order to reduce the limitations due to the polysemy and the multiplicity of the constructs of complexity, Pallotti (2015) proposes to adopt a ‘simple view of complexity’ to be seen as a purely descriptive category. Its scope is limited to structural complexity; therefore, it is concerned with the formal and functional characteristics of the language. However, as the other sub-constructs of complexity can be deemed equally interesting and rich in providing perspectives on the different dimensions of language and linguistic competence, including the interactional one, it is perhaps more useful to stress the importance of definitions; rather than reducing the multi-faceted nature of complexity to structural complexity for ease of investigation, scholars should be invited to put more effort into clearly identifying which sub-construct of complexity they are investigating, how it is operationalised and which measures are considered more effective.
Drawing on past theorisations and operationalisations of linguistic complexity, a number of adjustments can be proposed to make its study more tractable. First of all, the study of linguistic complexity would benefit from an evidence-based bottom-up approach. The bottom-up approach, which relies on the emergence of patterns from language data, constitutes an advantage when it comes to limiting the impact of a priori conceptions of what linguistic complexity is and where it should be found in the text. As shown by Biber et al. (2022), the distribution of certain grammatical features in the written and spoken registers analysed allowed the emergence of at least two types of grammatical complexity which differ substantially. The same data-driven approach could be applied to other sub-constructs of linguistic complexity, such as lexical complexity, pragmatic complexity, etc., in order to obtain new and reliable insights that account for register-related variation in linguistic complexity.
Second, by adopting a register-functional approach (Biber et al. 2022), the study of linguistic complexity may also be enriched by an explanatory dimension: the linguistic complexity of registers varies because different registers rely on different structures, vocabularies and pragmatic strategies in order to fulfil their communicative purposes. Communicative purposes, type of audience and the production and reception circumstances (e.g. mode, time for pre-planning) of a text are taken into account as factors influencing the linguistic complexity of texts, hence as reasons underlying the variation in linguistic complexity across texts and registers.
Third, in accordance with Pallotti (2009; 2015), this author believes that efforts should be put into keeping cognitive complexity (i.e., cognitive costs and difficulty in processing language) separate from the linguistic complexity characterising texts. As often pointed out in the literature (Pallotti, 2009; Bulté and Housen, 2012; Joseph, 2021; Biber et al., 2022), it would be misleading to believe that linguistically complex texts are always difficult and that difficulty can only be experienced with linguistically complex texts. As tempting and natural as it may be to infer the difficulty of linguistic features based on how sophisticated a text may look like, our personal experience with language and observing L2-learners developing competence, many scholars have already pointed out how difficulty largely depends on individual variables and is far from being an objective property of linguistic features. Therefore, cognitive complexity should rely on very different methodologies, measures and tools compared to linguistic complexity. Its study should employ tools that measure cognitive processes, such as brain-activity imaging (e.g., fMRI, PET scans). The data about language reception and production costs should then be triangulated with data about the linguistic complexity of the texts used as input and the subjects’ individual variables (e.g. age, motivation, language level, education level, L1 and L2 similarity, etc.).
Carefully discerning between linguistic and cognitive complexity also represents a step towards eliminating one main issue with the study of complexity i.e., defining a less-to-more complex continuum of linguistic structures. If cognitive complexity (i.e. difficulty) is not taken as a factor intrinsic to the linguistic complexity of language features, the question can shift from ‘which language features are more complex?’ to ‘how is this text complex?’. In answering the latter question, instead of relying on measures such as length of sentences or number of subordinate clauses, once could observe the degree of in-text variation. From this perspective, the measurement of linguistic complexity would become the measurement of how variable the vocabulary, structures, pragmatic strategies in a text are, borrowing an approach that is more typical of typological studies (Dryer, 2007; see also Pallotti, 2015). Hence, the more variation in these parameters, the more linguistic complexity; the more repetition, the less complex. Linguistic complexity, thus, would not be conceived as a property of single language features or constructions as, rather, of texts and as linguistic richness rather than sophistication. A view of complexity that relies on variation is compatible with both evidence-based and register-functional approaches, since it allows different registers to display different types of linguistic complexity characterised by the occurrence of a variety of linguistic features, which are not necessarily the same across registers (cf. Biber et al. 2022). This would also avoid the perpetuation of absolute statements, such as ‘finite dependent clauses are more complex than coordinate clauses’ (see, for example Huddleston, 1984; Purpura, 2004; Carter, McCarthy, 2006; Givón, 2009) that may result in interpretative biases such as ‘texts that do not feature subordinate clauses are less linguistically complex’.
Studying linguistic complexity in terms of in-text variation may also prove useful to developmental complexity. Measuring variation in L2 learners’ outputs would be in line with the natural variability of learning trajectories. Whether displaying native or non-native patterns, the learner is believed to be effectively learning when producing new structures and vocabulary, thus adding linguistic variation to the output.
Finally, as already claimed in the literature, the reliability of the results of complexity studies can be improved by reducing scope (Sinnemäki, 2011). As measuring linguistic complexity globally (e.g. the entire language system or learner’s interlanguage) has proven hardly feasible, the study of linguistic complexity would benefit from choosing one target sub-constructs at a time (e.g., grammatical, pragmatic, discourse-interactional) (cf. Miestamo, 2006, 2008 and Nichols, 2009) and addressing texts and registers rather than entire language systems. Narrowing down scope allows to avoid overgeneralisations that cannot acknowledge the variation required by different registers and level of language analysis and enables the development of more suitable methodologies for the study object at hand which possibly include a qualitative dimension.
[1]https://www.merriam-webster.com/dictionary/complex (accessed: 06.02.2025)
[2] The Minimal Terminable Unit (T-Unit) is defined by Hunt (1965: 20, 49) as “an entity that consists of one main clause and (optional) subordinate clauses (i.e. dependent clauses) and non-clausal units or sentence fragments attached to it”.
[3] The Analysis of Speech Unit (AS-Unit) introduced by Foster et al. (2000: 365) as “a single speaker’s utterance consisting of an independent clause, or sub-clausal unit, together with any subordinate clause(s) associated with it”.
[4] The Modified Utterance (U-Unit) is defined as “one independent clause or several coordinated independent clauses, with all dependent clauses or fragmental structures attached to it, separated from the surrounding speech by a pause of 1.5 seconds or more, or, especially in occurrences of coordination, a clear change in intonation and a pause of 0.5 seconds or more (depending on the average length of boundary pauses in the sample), containing one semantic unity” (Lintunen, Mäkilä, 2014: 385).












Список литературы
Список использованной литературы появится позже.