
Лингвистика алгоритмической логики виральной коммуникации
Aннотация
Статья посвящена лингвистическому анализу механизмов вирального распространения контента в условиях алгоритмически управляемой цифровой медиасреды. Актуальность исследования обусловлена трансформацией публичной коммуникации на цифровых платформах, где селекция и масштабирование сообщений все чаще осуществляются на основе формализуемых показателей вовлеченности, а не межличностных связей. Это требует пересмотра традиционных подходов к анализу публичной речи и разработки понятийного аппарата, учитывающего алгоритмическое опосредование дискурса. Проблема исследования заключается в выявлении устойчивых лингвистических характеристик алгоритмически усиливаемого контента и в описании структуры алгоритмического идиолекта – специфического речевого регистра, адаптированного к критериям платформенного отбора и ранжирования сообщений. Особое внимание уделяется соотношению формальных языковых средств, дискурсивной организации сообщений и метрик, используемых алгоритмами цифровых платформ. Исследование базируется на междисциплинарном подходе, сочетающем методы медиалингвистики, теории коммуникации и прикладного анализа данных. Эмпирическую базу составил корпус из 2000 постов социальных сетей (январь–июнь 2025 года), разделенных на виральную и контрольную подвыборки. В работе применялись количественные методы анализа, включая расчет средней длины предложений, частотности экспрессивных конструкций, автоматизированный анализ тональности текста и контент-анализ прагматических и мультимодальных элементов. Статистическая значимость различий проверялась с использованием t-критерия Стьюдента и χ²-критерия. Результаты показывают, что виральный контент характеризуется синтаксической редукцией, повышенной экспрессивностью, поляризацией тональности, ориентацией на бинарные оппозиции и высокой степенью мультимодальности, существенно повышающей вовлеченность. На основе совокупности выявленных признаков обосновано выделение алгоритмического идиолекта виральности как стандартизированного языкового регистра цифровой коммуникации, оптимизированного под алгоритмические механизмы платформ.
Ключевые слова: Виральная коммуникация, Виральность, Алгоритмический идиолект, Алгоритмически управляемая медиасреда, Цифровой дискурс
Введение
Современная цифровая медиасреда характеризуется не только ростом объемов производимого контента, но и глубокой трансформацией механизмов его циркуляции. Социальные медиаплатформы, функционирующие на основе алгоритмов рекомендаций, персонализации и ранжирования, существенно изменили саму логику публичной коммуникации. Видимость сообщения и масштаб его распространения все в меньшей степени зависят от структуры социальных связей, и все в большей от алгоритмической обработки пользовательской активности.
В рамках данного исследования мы проводим концептуальное разграничение между вовлеченностью (engagement) и виральностью (virality), которые в платформенной среде выступают как связанные, но различные звенья причинно-следственной цепи.
Вовлеченность понимается как совокупность количественно измеримых поведенческих реакций пользователей на единицу контента (лайк, репост, комментарий, время просмотра). Она является первичным сигналом для алгоритмов платформ, индикатором начального резонанса сообщения в аудитории.
Виральность трактуется как масштабный и часто нелинейный эффект алгоритмического усиления, запускаемый на основе высоких первичных показателей вовлеченности (Hemsley, 2011). Это не просто сумма репостов, а качественный переход контента в иной режим распространения, при котором платформенные алгоритмы (рекомендательные системы, механизмы попадания в «тренды») начинают активно продвигать сообщение за пределы исходной аудитории подписчиков, обеспечивая ему взрывной охват.
Таким образом, вовлеченность – это причина и триггер, а виральность – следствие и результат в логике алгоритмически управляемой медиасреды. Высокая вовлеченность – необходимое, но не всегда достаточное условие для виральности. Данное разграничение позволяет нам в эмпирической части работы рассматривать отобранные посты с аномально высоким индикатором вовлеченности пользователя (далее – ИВП) не просто как «популярные», а как контент, уже прошедший первичный алгоритмический отбор и ставший объектом масштабирования, то есть достигший состояния виральности
В результате виральность в платформенной среде приобретает алгоритмически масштабируемый характер. Действия пользователей (просмотры, клики, комментарии) сохраняют значение, но уже не как звенья сетевого обмена, а как сигналы, интерпретируемые алгоритмами ранжирования. Массовое распространение контента все чаще представляет собой не каскад репостов, а вспышку видимости, вызванную решением алгоритма о расширении охвата (Arjona-Martín et al., 2020; Narayanan et al., 2023). На этой основе формируется новая коммуникативная форма – виральная коммуникация, которая представляет собой не спонтанный сетевой эффект, а опосредованный алгоритмами процесс масштабирования контента, в котором платформа и сообщение образуют единый контур производства и распределения внимания.
Такое смещение имеет принципиальные последствия для лингвистического анализа цифровой коммуникации. В условиях алгоритмически опосредованной виральности отбор и усиление контента осуществляются не на уровне смысловой аргументации, а на уровне формализуемых характеристик контента, коррелирующих с показателями вовлеченности. Языковые, композиционные и мультимодальные характеристики сообщения оказываются встроенными в алгоритмическую логику платформ и начинают функционировать как адаптивные инструменты повышения видимости. В результате язык вирального контента приобретает свойства платформенно оптимизированного дискурсивного регистра.
Несмотря на значительный интерес к феномену сетевой диффузии информации, цифровой риторике и алгоритмической медиации (Leskovec et al., 2007; Jenkins, 2006; Gillespie, 2014; Bucher, 2018; van Dijck et al., 2018; Narayanan, 2023), лингвистические аспекты алгоритмически опосредованной виральной коммуникации разработаны пока недостаточно. Существующие работы фокусируются либо на психологических механизмах распространения контента (Berger, Milkman, 2012), либо на технических принципах функционирования рекомендательных систем (Kitchin, 2017; Narayanan et al., 2023). Отечественные исследования в области медиалингвистики и интернет-коммуникации затрагивают вопросы аттрактивности медиатекста и эмоциональных стратегий воздействия (Вартанова, 2019; Максименко, 2013; Леонтович, 2017; Антонова, 2020; Каминская, 2021; Старовойт, 2021; Крапивин, 2025), однако системный анализ языковых особенностей алгоритмически управляемой виральности практически не проводился.
Данная лакуна определяет актуальность нашего исследования, которое опирается на комплекс теоретических походов: концепцию платформенного детерминизма (Ахренова, 2024; ван Дейк, 2020), теорию аффективных алгоритмов (Bucher, 2018), акторно-сетевую модель (Latour, 2005), теорию диффузии инноваций (Rogers, 1962). Эти рамки позволяют рассматривать виральность как результат взаимодействия платформенного (алгоритмы), дискурсивного (языковые стратегии) и поведенческого (практики пользователей) уровней коммуникации. При этом именно язык выполняет интерфейсную функцию, связывая человеческое сообщение с вычислительной процедурой отбора и масштабирования.
Целью представленного анализа стало выявление и количественная оценка лингвистических характеристик, являющиеся частотными в контенте с высокими показателями вовлеченности. В рамках исследования виральность рассматривается не как постфактум-метрика популярности, а как результат адаптации языковых и дискурсивных стратегий к условиям платформенного отбора. Особое внимание уделяется анализу морфосинтаксических, лексико-семантических и дискурсивно-прагматических характеристик контента, коррелирующих с высокими показателями вовлеченности, а также формированию алгоритмического идиолекта – надиндивидуального речевого регистра, оптимизированного под алгоритмические механизмы видимости.
В основу исследования была положена рабочая гипотеза о том, что контент с более короткими синтаксическими конструкциями и использованием ряда риторических приемов, например, риторических вопросов, парцелляции, получает более высокий средний уровень вовлеченности аудитории; лексика с высокой эмоциональной валентностью, как положительной, так и отрицательной, и оценочностью способствует повышению виральности контента; поликодовые мультимодальные сообщения (текст + изображение/мем) имеют значимо более высокие показатели охвата и вовлеченности по сравнению с чисто текстовыми.
Таким образом, виральная коммуникация может рассматриваться как объект лингвистического анализа, требующий переосмысления теоретических оснований в свете алгоритмической трансформации цифровой публичности. Далее мы рассмотрим ключевые подходы, определяющие исследовательскую рамку настоящей работы.
Основная часть
Стратификация моделей цифровой коммуникации
Современные исследования цифровой коммуникации сходятся в признании того, что механизмы распространения информации в медиасреде претерпели принципиальную трансформацию. В классических работах начала 21 века этот сдвиг описывался как переход от подписной (вещательной) к сетевой модели коммуникации. В рамках подписной модели пользователь получал контент от ограниченного круга институциональных источников, а распространение сообщений носило линейный и централизованный характер. Исследования, посвященные теории диффузии инноваций и культуре участия, фиксировали разрушение этой модели и рост роли горизонтальных связей между пользователями (Rogers, 1962; Jenkins, 2006).
С развитием Web 2.0 на первый план вышла сетевая модель коммуникации, в которой пользователь становится не только реципиентом, но и активным ретранслятором контента. Механизмы репостинга и шеринга порождают эффект информационных каскадов, при котором сообщения распространяются по социальной сети за счет последовательных индивидуальных решений пользователей. Именно в рамках этой модели формируется классическое представление о виральности как социальном эффекте, основанном на межличностных связях и добровольном «усилении» контента внутри децентрализованной сети (Leskovec et al., 2007; Nahon et al., 2013).
Однако архитектура современных платформ не столько отменила, сколько надстроила новые режимы над старыми. В связи с этим термин «эволюция» требует уточнения: в современной цифровой среде мы наблюдаем не линейную смену, а стратификацию (многослойность) коммуникативных моделей. Подписная модель (follow-модель) продолжает существовать, формируя ядро лояльной аудитории. Сетевая модель (share-модель) опосредует распространение внутри доверительных кругов. Алгоритмическая же модель (rank-модель) выступает мета-уровнем, который селективно усиливает контент, уже прошедший первичный отбор в двух первых слоях (Gillespie, 2014; van Dijck et al., 2018). Следовательно, корректнее говорить не об эволюции как замещении, а об усложнении архитектуры цифровой публичности, где алгоритмическая логика становится доминирующим, но не единственным механизмом распределения внимания, надстраиваясь над подписной и сетевой.
Рисунок 1. Стратификация моделей цифровой коммуникации
Figure 1. Stratification of Digital Communication Models
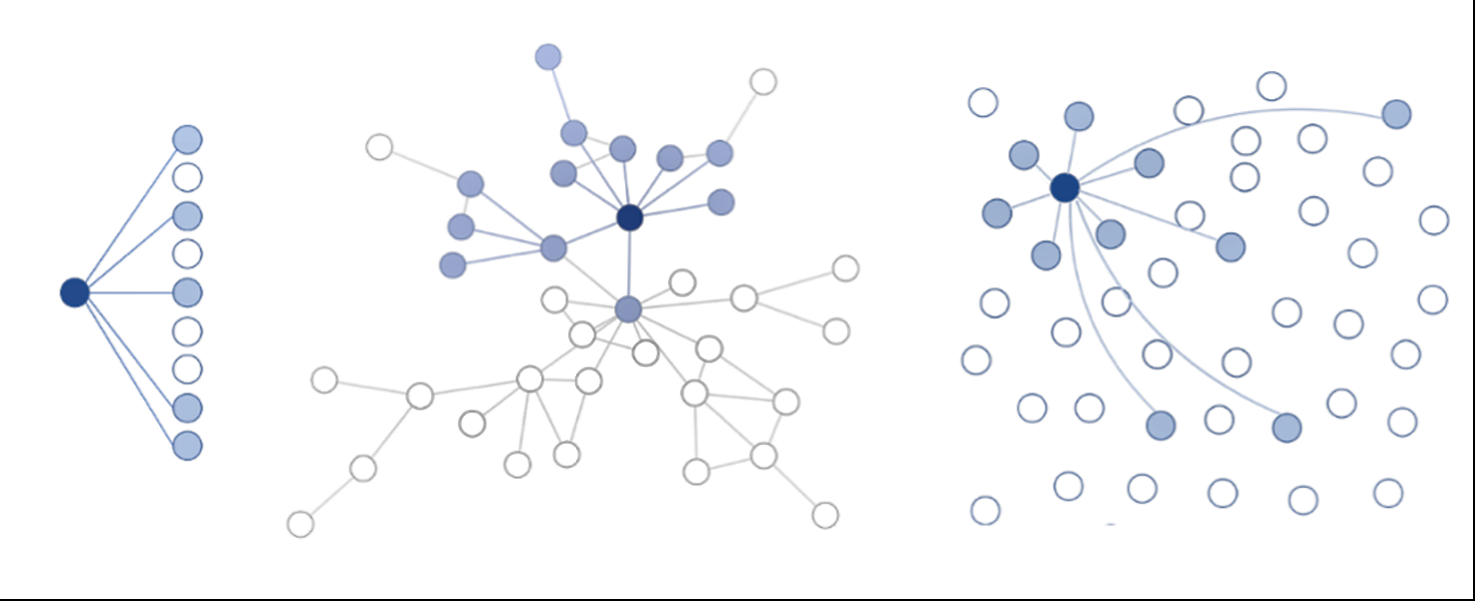
Таким образом, виральность в современных условиях перестает быть исключительно сетевым эффектом и все чаще выступает результатом алгоритмического усиления, при котором платформа активно участвует в принятии решений о масштабировании сообщения.
Эволюция понятия виральности: от биологической метафоры к платформенной логике
Понятие виральности исторически формировалось на основе биологической метафоры заражения. В работах Р. Докинза и Д. Рашкоффа идеи и медиатексты рассматривались как культурные вирусы, самопроизвольно распространяющиеся в социальной среде (Dawkins, 1976; Rushkoff, 1994). Причем Рашкофф подчеркивал, что говорит о вирусах не метафорически, а буквально – медийные события, по его мнению, и есть вирусы. Такая трактовка предполагала относительную пассивность аудитории и автономность вирусного контента.
Критика данной модели была развернута в исследованиях Г. Дженкинса, С. Форда и Д. Грина, которые показали, что распространение контента невозможно без активного участия пользователей и их культурной переработки сообщений (Jenkins et al., 2013). Взамен вирусной метафоры ими была предложена концепция “spreadability” (распространяемости), подчеркивающую роль аудитории в сознательном перенаправлении сообщений. То есть идеи и контент распространяются, только если люди находят их значимыми, вписанными в их культурный контекст и техническую среду, и сознательно делятся ими.
В российской научной традиции аналогичные идеи развивались через понятия аттрактивности медиатекста, презентационности и эмоционального усиления (Максименко, 2013; Леонтович; 2017; Антонова, 2020; Каминская, 2021). Виральность описывали также как принцип презентационности и эмоционального усиления контента, то есть стремление подать информацию так, чтобы она сразу производила эффект и побуждала делиться (Вартанова, 2019; Старовойт, 2021; Крапивин, 2025).
Современные исследования фиксируют переход к гибридному пониманию виральности, возникающей на стыке пользовательской активности и алгоритмической селекции. Обзорные работы показывают, что в платформенной среде массовое распространение контента все чаще представляет собой не цепочку репостов, а алгоритмически инициированную вспышку видимости (Arjona-Martín et al., 2020; Narayanan et al., 2023). Алгоритмы могут усиливать контент, опираясь на ранние показатели вовлеченности, даже без многошагового «сарафанного радио». В результате традиционная метафора вируса утрачивает самостоятельность: виральность теперь во многом инфраструктурно обусловлена. Она определяется не только качествами самого сообщения или волей публики, но и параметрами платформы, в рамках которой это сообщение циркулирует.
Рисунок 2. Динамика вирального охвата
Figure 2. Dynamics of Viral Reach
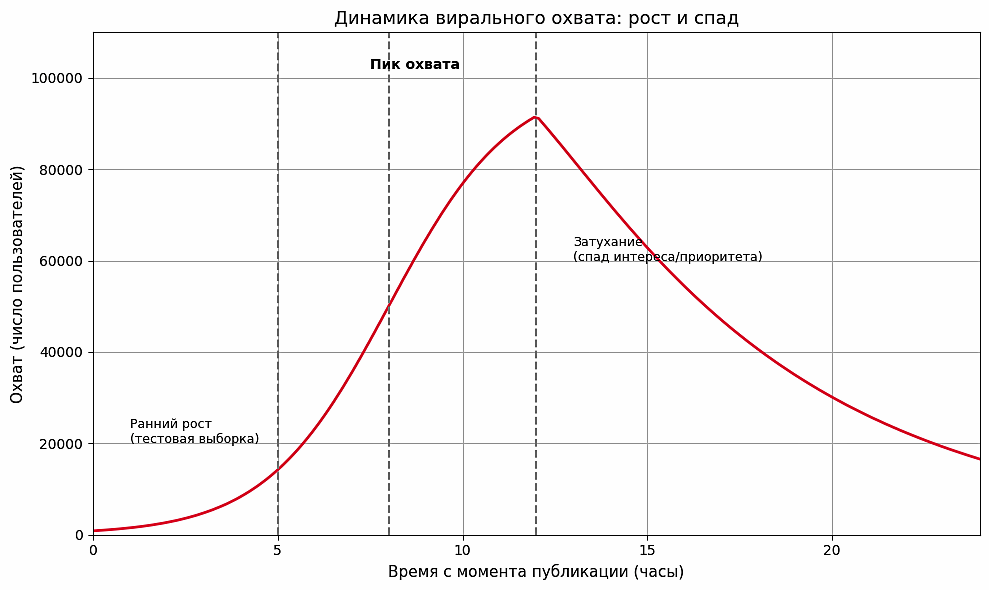
Алгоритмически управляемая медиасреда
Современная цифровая медиасреда функционирует по принципам алгоритмического управления, при котором автоматизированные платформы активно отбирают и ранжируют контент. Алгоритмы социальных сетей и агрегаторов выступают не нейтральными каналами, а полноправными акторами коммуникации, определяя, какой материал станет видимым для широкой аудитории (Gillespie, 2014; Bucher, 2018). Публичное высказывание в такой среде начинает зависеть не столько от его содержания, сколько от соответствия алгоритмическим приоритетам платформ. Иными словами, алгоритмическая логика цифровых платформ формирует новое «правило игры» для медийного дискурса: механизмы платформ задают условия распространения информации и модулируют внимание пользователей (Kitchin, 2017).
При этом алгоритмическое управление не носит полностью автономного характера. Критические исследования подчеркивают встроенность алгоритмов в институциональные, экономические и культурные контексты, а также их зависимость от человеческих решений на этапах проектирования, настройки и интерпретации данных. Тем самым автономность алгоритмических систем оказывается ограниченной, а их воздействие – опосредованным социальными и политическими факторами (Ananny, Crawford, 2018; Kitchin, 2017).
Алгоритмически управляемая медиасреда существенно влияет на язык и стиль производимого контента. Во-первых, алгоритмы все чаще определяют, что будет распространяться. Мы наблюдаем алгоритмический поворот в селекции новостного контента – вместо человеческих редакторов видимость сообщений обеспечивают вычислительные правила ранжирования (Gillespie, 2014). Во-вторых, авторы медиатекстов начинают сознательно подстраивать свои высказывания под критерии алгоритмической видимости, избегая тем самым «угрозы невидимости» в ранжированном потоке (Bucher, 2018). В результате наблюдается смещение риторики в сторону клипового, экспрессивного изложения, рассчитанного на мгновенное привлечение внимания: короткие броские заголовки, эмоционально насыщенные слоганы, кликбейт-формулы стали нормой вирусного контента (Антонова, 2020; Старовойт, 2021). Тексты упрощаются семантически и фрагментируются структурно, дополняются визуальными элементами и эмодзи – все это повышает их шансы быть подхваченными алгоритмом в условиях беглого онлайн-потребления. Эмпирические данные подтверждают эффективность подобных стратегий: эмоционально резонансные и когнитивно простые сообщения статистически чаще получают высокий виральный охват (Berger, 2013). Кроме того, алгоритмическая фильтрация контента приводит к фрагментации информационного пространства и формированию эффекта «эхо-камер» и пузырей фильтров (Pariser, 2011). Все это указывает на необходимость учитывать алгоритмический фактор как особый параметр анализа медиатекстов. Без него исследователь рискует упустить целое измерение современных медиапроцессов.
В рамках критической теоретической традиции алгоритмически управляемая медиасреда рассматривается как пространство алгоритмического посредничества, в котором автоматизированные системы не только ранжируют информацию, но и перераспределяют агентность между людьми и технологиями, формируя новые режимы власти, ответственности и контроля над публичной видимостью (Introna, 2016; Amoore, 2020; Roumbanis, 2025). В российской научной традиции близкие процессы осмысляются в рамках критической лингвистики и медиалингвистики, где анализируются властные и идеологические эффекты публичной риторики; однако алгоритмический фактор в этих исследованиях до последнего времени рассматривался преимущественно имплицитно (Чернявская, 2017; Клушина и др., 2024).
Значимый вклад в расширение теоретической рамки вносит и внеевропейская академическая перспектива. Так, Цюань Янь рассматривает алгоритмы как активных медиапосредников, формирующих информационную архитектуру на трех уровнях: метауровне (правила видимости и модерации), мезоуровне (отбор тем и фреймов) и микроуровне (форматирование и упрощение сообщений). Хотя данная концепция не ориентирована непосредственно на анализ языковых структур, она позволяет рассматривать алгоритмы как риторических агентов, задающих условия появления, продвижения и восприятия публичного высказывания еще до его публикации (Quan Yan, 2023а, Quan Yan, 2023 б).
Алгоритмический идиолект
Одним из следствий алгоритмизации медиасферы становится формирование алгоритмического идиолекта – устойчивого речевого регистра, адаптированного к механизмам платформенного отбора и основанного на статистически эффективных языковых стратегиях, которые повышают вероятность алгоритмического усиления. Его становление обусловлено, с одной стороны, бессознательной адаптацией пользователей к алгоритмическим правилам видимости, а с другой – непрерывным обучением алгоритмов на поведенческих, аффективных и лингвистических сигналах (Bucher, 2018; Gillespie, 2014; Dillet, 2020).
Введение термина «алгоритмический идиолект» может вызвать закономерный вопрос о его субъектности, учитывая классическую трактовку идиолекта как совокупности особенностей речи отдельного индивида. В данном случае мы намеренно используем этот термин, фиксируя парадокс современной коммуникации: алгоритмическое давление приводит к формированию стандартизированного, надындивидуального речевого регистра, который, однако, имитирует идиолектные черты – индивидуализированную манеру, эмоциональность, спонтанность. Субъектом, «продуцирующим» этот регистр, выступает не конкретный человек, а гибридный актор – пользователь, чья речевая практика бессознательно или сознательно оптимизируется под алгоритмические фильтры. Таким образом, алгоритмический идиолект – это не речь алгоритма, а речь, оптимизированная для алгоритма. Его «идиолектность» представляет собой симулякр индивидуальности, возникающий в результате массового копирования речевых паттернов, успешных с точки зрения алгоритмической селекции.
В отличие от классического идиолекта, отражающего уникальные особенности речи отдельного носителя языка, алгоритмический идиолект воспроизводит стандартизированный стиль, оптимизированный под критерии платформ. Он характеризуется синтаксической редукцией, эмоциональной насыщенностью, мультимодальностью и опорой на повторяемые триггерные конструкции – хештеги, мемы, слоганы, визуально-текстовые гибриды. Исследования показывают, что именно такие элементы обеспечивают наибольшую вовлеченность и, как следствие, распространение контента (Dillet, 2020; Ахренова, 2025).
Таким образом, интеграция отечественных и зарубежных подходов позволяет рассматривать виральную коммуникацию как алгоритмически опосредованный дискурсивный процесс, в котором язык выступает ключевым интерфейсом между человеческим восприятием и машинной логикой отбора. Виральность в этом контексте перестает быть случайным или исключительно социальным эффектом и становится результатом системной адаптации языковых стратегий к условиям платформенной медиасреды. Понимание алгоритмического идиолекта как адаптивного регистра, возникающего на пересечении человеческой речевой практики и алгоритмической селекции, открывает новые перспективы для лингвистического анализа цифровой коммуникации и служит индикатором трансформации публичной речи в условиях алгоритмически управляемой медиасреды.
Предлагаемый теоретический синтез создает основу для лингвистического анализа вирального контента, ориентированного не только на описание отдельных приемов, но и на выявление устойчивых закономерностей алгоритмического идиолекта.
Материалы и методы
В рамках данного исследования виральность трактуется как алгоритмически опосредованная форма масштабирования контента, при которой расширение охвата определяется взаимодействием пользовательской активности и платформенных механизмов ранжирования. Высокий уровень вовлечённости интерпретируется как результат алгоритмической селекции, а не как прямое следствие сетевой диффузии.
Для операционализации этого феномена используется следующая формула определения вирального потенциала (VP):
VP=E×C×T×A
где:
E (Emotional Appeal) – эмоциональная привлекательность или степень аффективного воздействия контента;
C (Cognitive Simplicity) – когнитивная доступность, т.е. легкость восприятия и понимания сообщения (измеряется через синтаксическую и семантическую простоту);
T (Timing) – актуальность контента временному контексту;
A (Algorithmic Affinity) – алгоритмическое соответствие, степень оптимизации под механизмы ранжирования платформ. Каждая компонента нормирована в диапазоне 0–1.
Данная модель служит теоретической рамкой для интерпретации эмпирических результатов на всех трёх уровнях анализа.
С целью проверки нашей гипотезы было сформирован корпус из 2000 текстовых постов в социальных сетях за период с января по июнь 2025 года. Эмпирическую базу составили публикации из двух наиболее популярных в русскоязычном сегменте платформ с доминированием алгоритмической ленты: ВКонтакте, Telegram (публичные каналы). Выбор платформ обусловлен их различной медийной архитектоникой: ВКонтакте сочетает социальный граф и алгоритмическую ленту рекомендаций («Умная лента»); Telegram-каналы представляют собой гибрид подписной модели с элементами алгоритмического продвижения через тематические рекомендации. Отбор производился исключительно из публичных источников – пабликов, публичных личных страниц с открытыми метриками и публичных каналов, что позволило верифицировать данные о вовлеченности. Из выборки исключались посты из закрытых групп и приватных аккаунтов. Для минимизации влияния платформенной специфики на итоговые выводы стратификация осуществлялась пропорционально доле вирального контента, обнаруженного на каждой платформе за исследуемый период. Такой дизайн, при сохранении доминирования общих лингвистических паттернов, позволяет в первом приближении говорить об универсальности выделяемого алгоритмического идиолекта, оставляя перспективу для кросс-платформенного сравнительного анализа.
Для отбора единиц корпуса использовался интегральный показатель вирального потенциала (ИВП), рассчитываемый для каждого поста отдельно по формуле:
ИВП = (L / L_avg) × 0.3 + (R / R_avg) × 0.4 + (C / C_avg) × 0.3
где:
L, R, C – абсолютные значения лайков, репостов и комментариев у конкретного поста;
L_avg, R_avg, C_avg – средние значения соответствующих реакций для данной тематической группы и платформы за анализируемый период (январь–июнь 2025 г.). Весовые коэффициенты (0.3, 0.4, 0.3) отражают приоритет распространения (репост) как ключевого маркера виральности над одобрением (лайк) и дискуссией (комментарий).
Принципиальным для дизайна исследования является вопрос о репрезентации виральности через показатели вовлечённости. Как отмечалось выше, виральность – это эффект алгоритмического масштабирования, запускаемый на основе высокой вовлечённости. В условиях закрытости «чёрного ящика» (black box) платформенных алгоритмов прямые данные о факте и моменте алгоритмического усиления недоступны для внешнего наблюдателя. В связи с этим в настоящем исследовании применяется метод обоснованной аппроксимации: контент с аномально высоким ИВП (более 3.0) рассматривается как уже прошедший стадию алгоритмического усиления. Логика данного допущения базируется на том, что столь кратный (трехкратный и выше) отрыв от среднестатистических показателей вовлеченности в своей тематической нише не может быть объяснен исключительно «органическим» сетевым распространением среди подписчиков и с необходимостью предполагает вмешательство рекомендательных систем, выведших контент на массовую аудиторию. Таким образом, экстремально высокая вовлеченность выступает в нашем исследовании операциональным индикатором состоявшейся виральности.
Корпус разделен на две равные подвыборки по 1000 текстов каждая.
Группа 1 (виральная): 1000 постов, чей ИВП превышал 3.0, то есть демонстрировавших как минимум трехкратное превышение нормативных для своей ниши показателей вовлеченности. Данный порог был установлен эмпирически на основе анализа распределения ИВП во всем предварительном датасете и позволил отсечь локально популярный контент, выделив посты с аномально высокой скоростью и масштабом распространения.
Группа 2 (контрольная): 1000 постов, отобранных для обеспечения репрезентативного фонового сравнения. Значение ИВП каждого поста находилось в диапазоне от 0.8 до 1.2, то есть демонстрировало вовлеченность, близкую к среднестатистической для их тематического кластера и платформы. Такой подход позволил исключить как аномально популярные, так и полностью незамеченные публикации, сформировав выборку типичного, «рядового» контента. Для минимизации тематического смещения отбор проводился стратифицированно: из каждого из пяти тематических кластеров было случайным образом выбрано по 200 постов, удовлетворяющих указанному диапазону ИВП. Таким образом, контрольная группа репрезентирует стандартные лингвистические практики в исследуемых сегментах цифрового дискурса при отсутствии значимого алгоритмического усиления.
Общий объем корпуса составил около 2 млн символов, по 1000 текстов в каждой группе, сбалансированных по тематике и условиям распространения.
Необходимо оговорить методологическое ограничение, обусловленное спецификой объекта. Идеальная экспериментальная схема предполагала бы сравнение двух групп постов с одинаково высокой вовлечённостью, одна из которых получила алгоритмическое усиление (вошла в рекомендации), а другая – нет. Однако в реальных условиях функционирования платформ такое разделение для внешнего исследователя невозможно: факт алгоритмического усиления не является публично маркированным параметром, а составляет часть внутренней логики платформы. Высокая вовлечённость и алгоритмическое усиление в современной медиасреде связаны циркулярной причинностью: алгоритмы усиливают то, что вовлекает, а усиление, в свою очередь, генерирует ещё большую вовлечённость. В связи с этим принятый в работе дизайн – сравнение постов с аномально высоким ИВП и постов со средним ИВП направлен на выявление лингвистических маркеров, коррелирующих с попаданием контента в «петлю усиления». Мы исследуем не столько результат однократного алгоритмического решения, сколько лингвистические свойства контента, который с наибольшей вероятностью становится объектом такого решения. Выделение «чистой» группы алгоритмически усиленных постов представляет перспективную задачу для дальнейших исследований, реализуемую лишь при коллаборации с платформами и доступе к их внутренней аналитике.
Исследование носит комплексный характер и включает многоуровневый лингвистический анализ контента. Мы предлагаем трехступенчатую процедуру анализа: 1. Морфосинтаксический уровень (количественный анализ) – изучение формальных синтаксических характеристик сообщений. 2. Лексико-семантический уровень – анализ словарного состава, тональности и содержательных маркеров. 3. Дискурсивно- прагматический уровень – анализ способов подачи сообщения, его прагматических компонентов (мультимодальность, призывы, хэштеги и др.).
На первом уровне (морфосинтаксис) мы измеряли ряд ключевых формальных показателей, предполагая, что вирусный контент склонен к упрощенным, динамичным формам: - Средняя длина предложения (в словах) – рассчитывалась по каждому тексту и усреднялась по группе. - Длина заголовка или первой фразы – ряд исследований указывает, что короткие, броские заголовки лучше привлекают внимание. - Частота риторических вопросов – доля сообщений, в которых автор использует вопросительные предложения без ожидания ответа (например, "Знаете ли вы, что...?" в начале поста). - Частота парцелляции – случаев расчленения фразы на несколько коротких интонационно-смысловых фрагментов (прием, создающий эффект устной речи и эмоциональности). – Частота инверсии – нестандартного порядка слов, используемого для акцента (например, вынесение дополнения или сказуемого в начало).
Для автоматизированного сбора этих метрик мы использовали инструменты Python: библиотеку pymorphy2 для морфологического анализа (определение границ предложений, подсчет слов), а также авторские скрипты для поиска риторических вопросов (регулярные выражения по символу "?"), парцеллированных конструкций (выявление аномально коротких предложений, следующих после точки или вопросительного знака), инверсий (по ключевым порядкам слов в русском предложении). Данные автоматически полученные метрики дополнялись ручной разметкой выборок для валидации спорных случаев. Статистическое сравнение групп проведено с помощью критериев: t-тест Стьюдента для средних (длина предложений и заголовков) и χ² (хи-квадрат) для долей категориальных признаков (наличие риторического вопроса, парцелляции, инверсии). Уровень значимости устанавливали p < 0,05. Также вычислялись оценки размера эффекта: разница средних выражалась через коэффициент Коэна d, для φ коэффициент использован φ для таблиц сопряженности 2x2.
На втором уровне (лексико-семантический) мы исследовали особенности словаря и семантики вирусных сообщений.
Проведен частотный анализ лексики обеих групп с выявлением слов, статистически значимо чаще встречающихся в вирусной группе. Для этого построены списки частотности слов (с предобработкой: тексты очищены от стоп-слов, лемматизированы с помощью морфологического анализатора MyStem). Для построения частотных списков и анализа коллокаций применялся инструмент AntConc. Сравнение частотности конкретных слов выполнялось с помощью χ²-теста или точного критерия Фишера (для редких слов) с расчетом отношения шансов (Odds Ratio) – насколько вероятность встретить данное слово выше в вирусной группе, чем в контрольной.
Для анализа тональности использовалась предобученная нейросетевая модель ruBert-tiny2 (DeepPavlov), классифицирующая тексты на три категории: положительный, отрицательный и нейтральный тона. Валидация и калибровка модели были проведены на ручно размеченной выборке из 500 случайных постов нашего корпуса, не вошедших в основную выборку. Три независимых эксперта-лингвиста присваивали каждому посту доминирующую тональность по заданному гайдлайну. Совпадение оценок экспертов (мера Флейсса каппа) составило κ = 0.78, что свидетельствует о существенном уровне согласия. Точность (accuracy) модели на этой валидационной выборке, измеренная относительно экспертного консенсуса, составила 87%. Расхождения в основном касались сложных случаев иронии и сарказма, которые затем были учтены при интерпретации количественных результатов. Для повышения надежности, автоматически полученные оценки эмоциональной интенсивности дополнительно проверялись по наличию в тексте лексических маркеров из заранее составленного словаря экспрессивной лексики (например, «потрясающе», «ужас», «разочарование»).
Исследованы бинарные оппозиции в лексике. Мы задали несколько шаблонных пар антонимических понятий, которые по нашей гипотезе могут использоваться как прием (например, «до – после», «просто – сложно», «старое – новое», «правильно – неправильно», «дорого – бесплатно»). С помощью поиска по шаблонам (регулярные выражения и n-граммный анализ) выявлялись случаи явного противопоставления в постах (например, фраза "раньше было сложно, теперь – просто"). Подсчитана доля текстов с таким приемом и наиболее частотные противопоставления.
Наконец, выполнено выявление ключевых тематических триггеров – тем или областей знания, которые особенно характерны для вирусного контента. Для этого все тексты были подвергнуты тематическому классифицированию (методом topic modeling LDA – латентное размещение Дирихле, число тем ~10). Однако для интерпретации результатов мы также вручную сгруппировали самые распространенные хештеги и ключевые слова по темам (например, тема "технологии/ИИ", "здоровье/биохакинг", "космос" и т.д.) и рассчитали среднюю вовлеченность постов на эти темы. Цель – обнаружить, есть ли специфические «горячие» темы, резко повышающие шансы на вирусность.
На третьем уровне (дискурсивно-прагматический) рассмотрены особенности подачи вирусных сообщений и дополнительные кодовые системы.
Проанализирована поликодовость контента, то есть использование помимо текста других медиаресурсов: изображений, видео, мемов, инфографики. По каждому посту отмечено, содержит ли он вложенное изображение/картинку, видео или только текст. Далее сопоставлено распределение типов контента в обеих группах (процент чисто текстовых постов vs. постов с мультимедиа). Также рассчитаны средние показатели вовлеченности для разных форматов (например, текст+мем, текст+видео и т.д.), чтобы выявить наиболее эффективный формат.
Проведена классификация и оценка мемов как особого жанра контента. В тех постах вирусной группы, где присутствовал мем (изображение с подписью, или шаблонное массовое изображение), мемы отнесены к функциональным типам: юмористические, объясняющие, провокационные, мобилизующие и др., по нашей авторской типологии. Для каждого типа посчитана доля среди всех мемов и средняя вовлеченность, чтобы понять, какой тип мемов более «вирусный».
Исследовано использование хэштегов – одного из ключевых инструментов цифровой риторики. Мы подсчитали среднее число хэштегов на пост в каждой группе, долю постов без хэштегов, а также отдельно выделили хэштеги оценочного характера (эмоциональные, призывные, маркирующие оценку, например #шок #гениально #mustread). Построено облако наиболее популярных хэштегов в вирусной группе. Далее хэштеги классифицированы по прагматической функции: тематические (обозначающие тему: #наука, #технологии), оценочные (#удивительно, #шок), призывные (#узнайПервым, #делись), идентификационные (#нашПроект, #мыКоманда). Эта классификация введена для понимания, как авторы используют хэштеги – просто для темы или как средство вовлечения.
Наконец, проведен корреляционный анализ между обнаруженными параметрами (наличие мема, число хэштегов, наличие оценочных хэштегов, тип контента и т.п.) и показателями вовлеченности (в пределах всей выборки). Это позволяет количественно оценить вклад каждого фактора.
Все собранные количественные данные обобщены в виде таблиц и графиков. Обработка данных и визуализация выполнены средствами Python (библиотеки pandas, matplotlib). В тексте ниже представлены наиболее значимые результаты с иллюстрациями (таблицы и графики) и их статистическая значимость.
Результаты и обсуждение
1) Морфосинтаксический анализ вирального контента
Для проверки ранее выдвинутой гипотезы были количественно измерены показатели формальной сложности текста и частотности экспрессивных синтаксических средств: средняя длина предложения (в словах), длина заголовка или первой фразы, а также частотность трех экспрессивных синтаксических приемов – риторических вопросов, инверсии и парцелляции.
В нижеприведенной таблице 1 демонстрируется сравнение ключевых метрик между группами. Как видно, вирусные посты значительно лаконичнее по синтаксису, чем обычные: их средняя длина предложений почти на 40% меньше, а заголовки/начальные фразы почти вдвое короче, по сравнению с контрольной группой. Эти различия статистически значимы (t-тест Стьюдента для независимых выборок показал, например, t(1998)=18.34, p<0.001, Cohen’s d=1.82 для длины предложений).
Помимо редукции синтаксической длины, виральный контент демонстрирует значительно более высокую насыщенность экспрессивными синтаксическими приемами. Так, риторические вопросы обнаружены в 34.2% виральных постов против 11.8% в контрольной группе; парцелляция — в 28.7% против 7.3%; инверсия — в 19.5% против 8.9%. По всем трем параметрам различия статистически значимы (χ², p < 0.01). При этом размеры эффекта варьируют от среднего до крупного: для риторических вопросов и парцелляции φ составляет около 0.21–0.23, тогда как для инверсии — около 0.11. Иными словами, виральный контент гораздо чаще «разговаривает» с читателем через вопросы, нарочито дробит фразы на короткие ударные сегменты и играет порядком слов, тогда как менее популярные посты написаны более нейтрально и развернуто.
Таблица 1. Сравнительный анализ метрик
Table 1. Comparative Analysis of Metrics
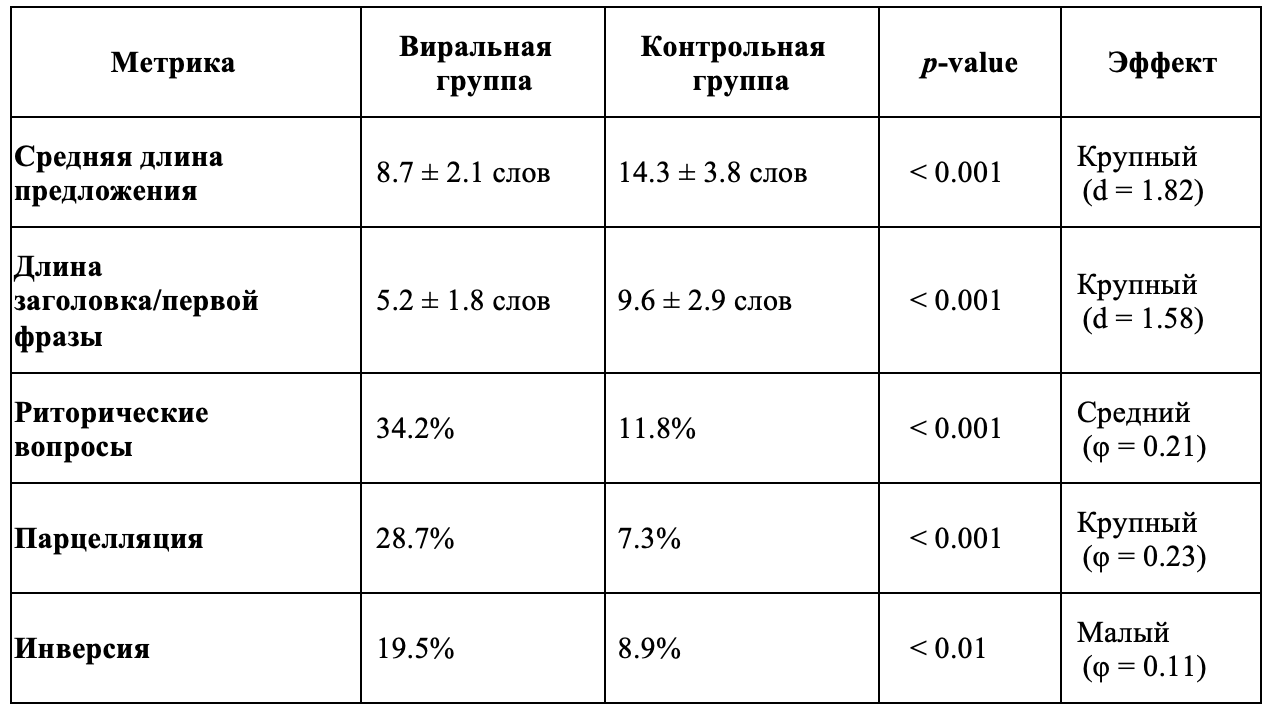
Выявленные различия позволяют интерпретировать виральный контент как особый тип текстовой организации, в котором синтаксическая экономия сочетается с повышенной экспрессивностью. Эти тенденции наглядно иллюстрируются схемой 3, где сопоставляется средняя длина предложения в виральной и контрольной группах: визуально фиксируется устойчивый разрыв между группами, подтверждающий количественные данные таблицы 1. Однако различия между группами проявляются не только на уровне формальных характеристик, но и в их связи с пользовательской реакцией.
Рисунок 3. Средняя длина предложения в виральной и контрольной группах
Figure 3. Average Sentence Length in Viral and Control Groups
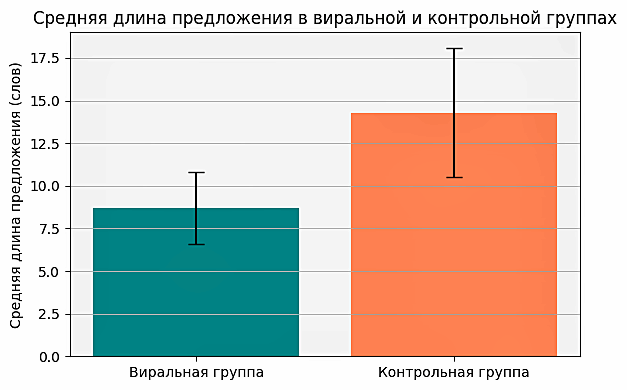
Корреляционный анализ показал, что средняя длина предложения находится в сильной отрицательной связи с вовлеченностью аудитории (коэффициент Пирсона r = – 0.68, p < 0.001), то есть более короткие фразы ассоциируются с большим числом реакций. Это согласуется с общими трендами SMM, где более сжатые тексты обычно показывают более высокий уровень взаимодействия аудитории. Напротив, наличие риторического вопроса положительно коррелирует с вовлеченностью (r = +0.42), как и парцелляция (r = +0.51) и, в меньшей степени, инверсия (r = +0.28), при статистической значимости p < 0.01 для всех трех.
Таблица 2. Корреляция метрик с вовлеченностью
Table 2. Correlation Between Metrics and Engagement
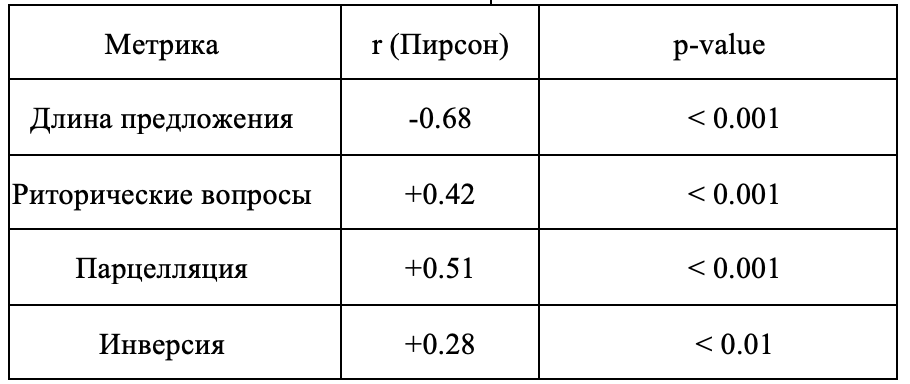
Иначе говоря, посты, содержащие эти приемы, в среднем получают больше откликов, чем тексты без них. Данная зависимость схематически представлена на схеме 4, где показано снижение средней вовлеченности по мере увеличения длины предложения.
Рисунок 4. Зависимость вовлеченности от длины предложения
Figure 4. Relationship Between Engagement and Sentence Length
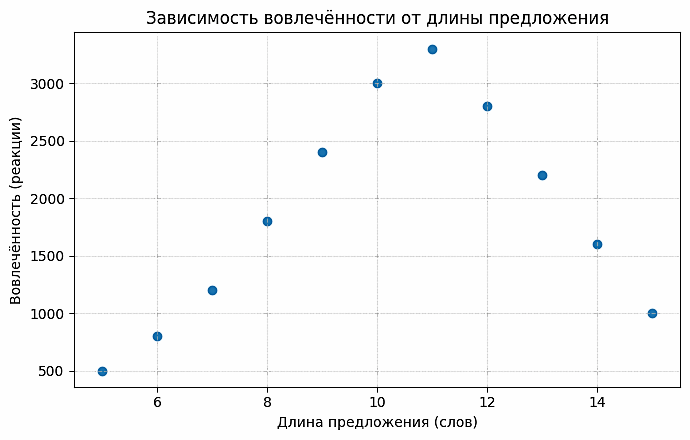
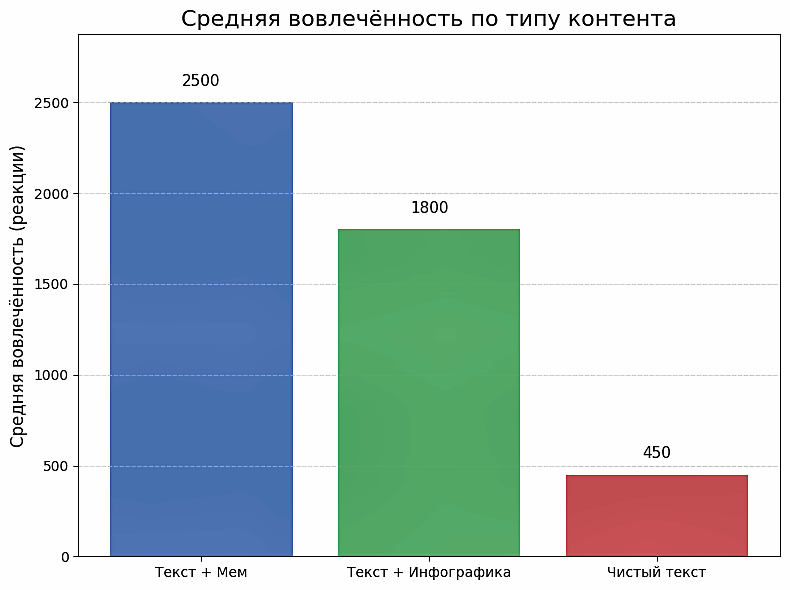
Наряду с синтаксическими маркерами, существенную роль в вариативности вовлеченности играет и формат подачи, в том числе наличие визуального компонента. Это отражено на схеме 5, где видно, что сочетание текста с ярким визуальным элементом значительно повышает вовлеченность аудитории и удобство восприятия контента. Так, посты формата «текст + мем» собирали ~2500 реакций в среднем, текст с инфографикой – около 1800. Напротив, чисто текстовые публикации набирали лишь ~450 реакций. Результаты подтверждают поликодовою природу современного медиатекста. Вирусному распространению контента способствует сопровождение лаконичного текста наглядными мемами или инфографиками, тогда как одиночный текст без визуала редко достигает высоких показателей. (На схеме усредненные данные по выборке: для каждого типа контента рассчитано суммарное среднее число реакций.)
Рисунок 5. Средняя вовлеченность (количество реакций) в зависимости от типа контента
Figure 5. Average Engagement (Number of Reactions) by Content Type
Полученные количественные закономерности находят подтверждение в качественном анализе типичных текстовых примеров из нашего корпуса. Рассмотрение конкретных публикаций позволяет проследить, каким образом выявленные статистические различия реализуются на уровне реальных речевых стратегий и синтаксической организации высказывания.
Характерным для виральных текстов является сочетание риторического вопроса и парцелляции, выступающее в качестве механизма первичного вовлечения адресата. Так, посты трендового научно-популярного сегмента нередко начинаются с вопроса, который инициирует диалог с читателем, а затем разворачиваются в виде серии кратких, интонационно завершенных фрагментов: «Мы – это то, что мы помним. Но как мы это делаем? И можно ли улучшить память?»; «Почему мы так быстро устаем? Не из-за работы. И не из-за возраста. Причина гораздо ближе, чем кажется»; «А вы уверены, что прокрастинация – это лень? Скорее всего, нет. Это защита. И вот почему». В данных примерах вопросная форма выполняет функцию когнитивного «крючка» (тж. «хука»), а последующая парцелляция задает ритм и поэтапно дозирует информацию, имитируя устную речь. Такая организация текста снижает когнитивную нагрузку и одновременно поддерживает внимание адресата, стимулируя дальнейшее чтение.
Другим устойчивым приемом виральных публикаций является инверсия в сочетании с акцентной парцелляцией. В новостных технологических постах ключевой результат часто выносится в начало высказывания: «Сенсационный прорыв совершили ученые из США…», после чего следует краткое уточнение и призыв: «В области медицины. Узнайте первыми». Инвертированный порядок слов («прорыв совершили ученые» вместо нейтрального «ученые совершили прорыв») усиливает экспрессивность и драматизацию сообщения, а короткая парцеллированная вставка уточняет контекст, не перегружая читателя деталями. Финальный императивный элемент выполняет прагматическую функцию побуждения к действию, усиливая вовлеченность.
Для сопоставления показателен контрольный пример, иллюстрирующий нейтральный синтаксис. Типичный пост со страницы IT-компании сообщает информацию развернуто и информативно, как правило, в форме длинного сложного предложения: «ВКонтакте представила “Итоги года 2025”: в специальном мини-приложении можно узнать, как прошел год в соцсети и получить предсказание на 2026 год…». или «ИИ – мощный инструмент, но не волшебная палочка. Раньше, чтобы узнать структуру белка, нужно было потратить год работы и кучу денег, а сейчас AI делает это за минуты». Здесь отсутствуют риторические вопросы, парцелляция, инверсия, нет визуального ряда; сообщение ориентировано на полноту и точность, но лишено экспрессивных средств, обеспечивающих мгновенное вовлечение. Подобная синтаксическая организация типична для менее виральных публикаций и коррелирует с более низкими показателями пользовательской реакции.
На основании совокупности количественных и качественных данных можно выделить несколько устойчивых синтаксических паттернов виральности, повторяющихся в различных тематических сегментах. Во-первых, это паттерн «вопрос – ответ – решение», при котором текст начинается с риторического вопроса, за которым следует краткий ответ и прагматически ориентированное предложение решения (например: «Нет времени на учебу? Есть решение. Всего 10 минут в день.»). Во-вторых, паттерн «инверсия + акцент», где ключевое слово или результат выносится в начальную позицию и затем уточняется короткими сегментами («Прорыв совершили ученые. В области медицины. Узнайте первыми.»). В-третьих, паттерн «декомпозиция сообщения», реализующийся в серии кратких парцеллированных высказываний, последовательно раскрывающих тезис («Технология изменит все. Скорость выше. Цена ниже. Это гениально.»). Во всех случаях наблюдается выраженная ритмизация текста и минимизация синтаксической развернутости.
Обобщая результаты, можно констатировать, что синтаксическая редукция выступает ключевым маркером виральности: виральный контент в среднем на 39% короче контрольного (8.7 против 14.3 слова в предложении), а экспрессивные конструкции используются статистически значимо чаще (риторические вопросы — в 2.9 раза, парцелляция — в 3.9 раза, инверсия — в 2.2 раза). Сильная отрицательная корреляция длины предложения с вовлеченностью (r = –0.68) подтверждает гипотезу об алгоритмическом предпочтении лаконичных и динамичных форматов.
Тем самым выявленные синтаксические паттерны можно рассматривать как ядро алгоритмического идиолекта. На морфосинтаксическом уровне алгоритмическая адаптация проявляется как систематическое упрощение и ритмизация текста, при которых синтаксическая сложность уступает место скорости восприятия, акцентности и прагматической эффективности коммуникации.
2) Лексико-семантический анализ вирального контента
На данном уровне анализ был направлен на выявление тех смысловых и оценочных элементов, которые статистически ассоциируются с высоким коэффициентом вовлеченности аудитории. Для проверки гипотезы исследования был проведен частотный анализ лексики виральной и контрольной групп, анализ тональности сообщений и выявление типичных семантических паттернов.
В первую очередь был выполнен частотный анализ лексем, статистически значимо различающихся между виральной и контрольной группами. Сравнение проводилось с использованием критерия χ² (хи-квадрат) и расчета отношения шансов (Odds Ratio), что позволило выявить слова-маркеры, повышающие вероятность алгоритмического масштабирования контента.
Таблица 3. Частотность ключевых лексем в виральной и контрольной группах
Table 3. Frequency of Key Lexemes in Viral and Control Groups
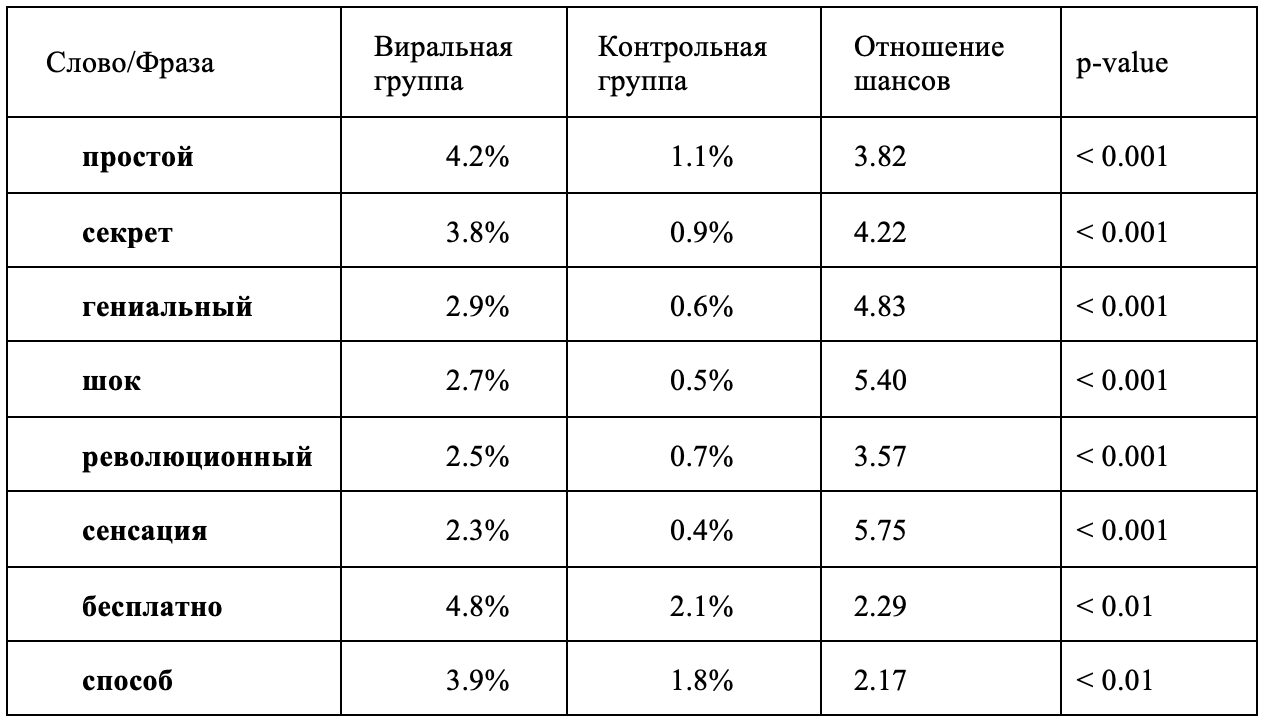
Как видно из таблицы, виральный контент характеризуется существенно более высокой частотностью лексем, объединяемых общей семантикой упрощения, эксклюзивности и эмоционального воздействия. Особенно выражены различия по словам шок, сенсация, гениальный, секрет, где отношение шансов превышает 4–5, что указывает на сильную связь этих лексем с виральным распространением. Семантически данные слова формируют у адресата ощущение особой ценности и исключительности информации («секрет», «сенсация»), а также обещание когнитивной экономии («простой способ», «бесплатно»). Подобные лексические маркеры не столько передают информацию, сколько выполняют прагматическую функцию привлечения внимания и мотивации к дальнейшему взаимодействию с контентом. Так, например распространены заголовки в духе: «Шок!То, что случилось с этим человеком, изменит ваше представление о жизни навсегда!», где напрямую используется слово «шок» и обещается сенсация. В технологической сфере можно встретить заголовки вроде «Эти 9 секретных промптов превращают GPT в гения-маркетолога!Просто скопируй!».
Дополнительно был проведен анализ общей тональности сообщений с целью выявления различий в эмоциональной насыщенности между группами. Для каждого поста определялась доминирующая тональность (позитивная, негативная, нейтральная) и интегральный показатель эмоциональной интенсивности.
Рисунок 6. Распределение тональности в контенте (доли позитивных, негативных и нейтральных сообщений) для виральной и контрольной групп
Figure 6. Sentiment Distribution in Content (Proportions of Positive, Negative, and Neutral Messages) in Viral and Control Groups
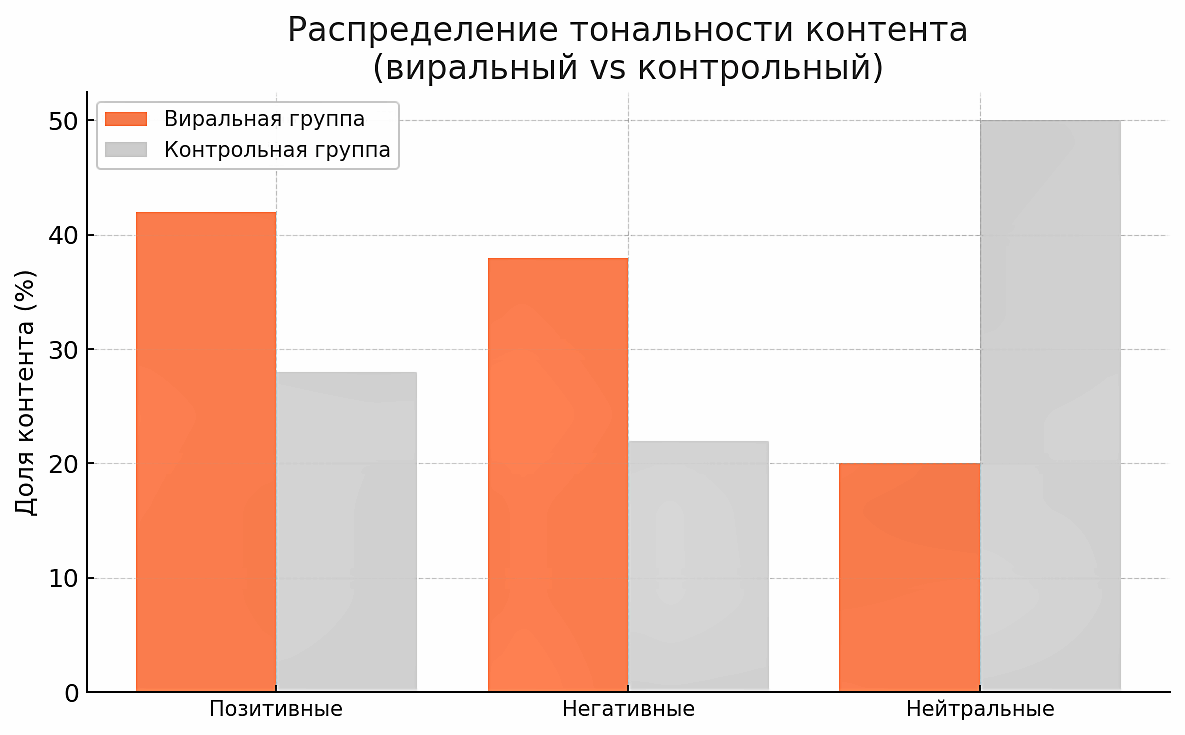
Полученные данные показывают, что виральный контент принципиально отличается от контрольного по уровню эмоциональной экспрессии. Вирусные публикации значительно реже имеют нейтральную тональность (20% против 50%) и, напротив, характеризуются доминированием эмоционально окрашенных сообщений. Позитивные эмоции вообще несколько преобладают над негативными в вирусном контенте (42% против 38%). Однако вирусный эффект дают и отрицательные эмоции, если они сопряжены с элементом сюрприза или возмущения. Более того, ряд данных свидетельствует, что негативные триггеры (страх, гнев, тревога) могут генерировать даже больше кликов, чем позитивные новости (Libert, 2024). Средний показатель эмоциональной интенсивности в виральной группе почти вдвое выше, чем в контрольной (0.72 против 0.41), что подтверждает гипотезу о том, что алгоритмически успешный контент должен вызывать сильный аффективный отклик. Нейтральное, описательное изложение, напротив, значительно реже становится объектом алгоритмического усиления.
Отдельное внимание было уделено анализу бинарных оппозиций – конструкций, основанных на противопоставлении двух состояний, оценок или сценариев. Для их выявления применялся шаблонный N-граммный анализ.
Таблица 4. Основные бинарные оппозиции в виральном контенте
Table 4. Key Binary Oppositions in Viral Content

Как видно, вирусный контент нередко преподносит информацию через резкие противопоставления: “было трудно – стало легко”, “до – после”, “старое – новое”, “правильно – неправильно”, “дорого – бесплатно” и т.д. Подобная поляризация сообщений выполняет сразу несколько задач. Во-первых, она упрощает сложную идею до понятной дуальной схемы, которую легче воспринять и запомнить. Во-вторых, драматизм контраста привлекает внимание – читателю интересно увидеть “прорыв” или “разоблачение”, когда что-то плохое сменяется на хорошее, дорогое противопоставляется бесплатному, сложное упрощается и т.п. Фактически, бинарные оппозиции превращают посыл в мини-историю с конфликтом и разрешением, что повышает вовлеченность. Например, фраза «95% делают это неправильно» мгновенно цепляет: аудитория узнает, что почти все ошибаются, и ее мотивируют узнать, как же правильно. Таким образом, противопоставления усиливают эффект новизны и значимости предлагаемых сведений, побуждая пользователя заинтересоваться контентом.
На следующем этапе были выделены тематические кластеры, внутри которых наблюдается повышенный уровень вовлеченности. Для этого была сопоставлена средняя вовлеченность постов с доминирующей тематикой. Анализ тематических кластеров показал, что у вирусного контента часто наблюдаются определенные “триггерные” темы, вокруг которых сосредоточено повышенное внимание аудитории. В нашем случае можно выделить топ-5 наиболее виральных тематик (по средней вовлеченности поста, в реакции):
Таблица 5. Тематические триггеры вирального контента
Table 5. Thematic Triggers of Viral Content
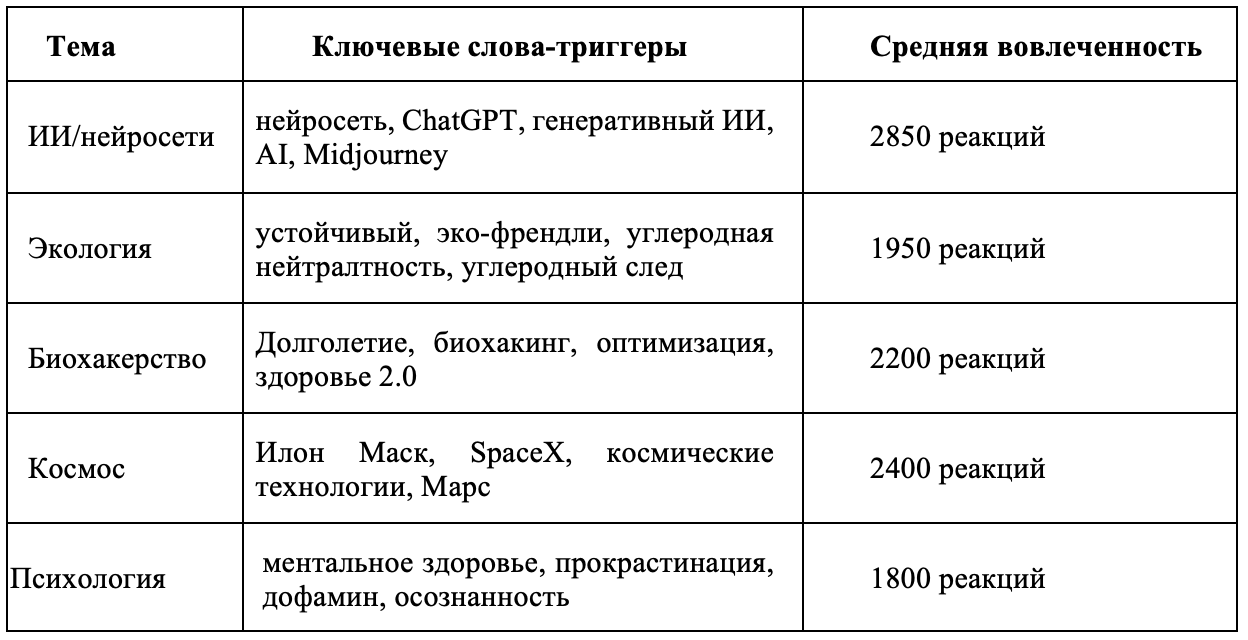
Рисунок 7. Средняя вовлеченность контента в зависимости от тематики/триггера
Figure 7.Average Content Engagement by Topic/Trigger
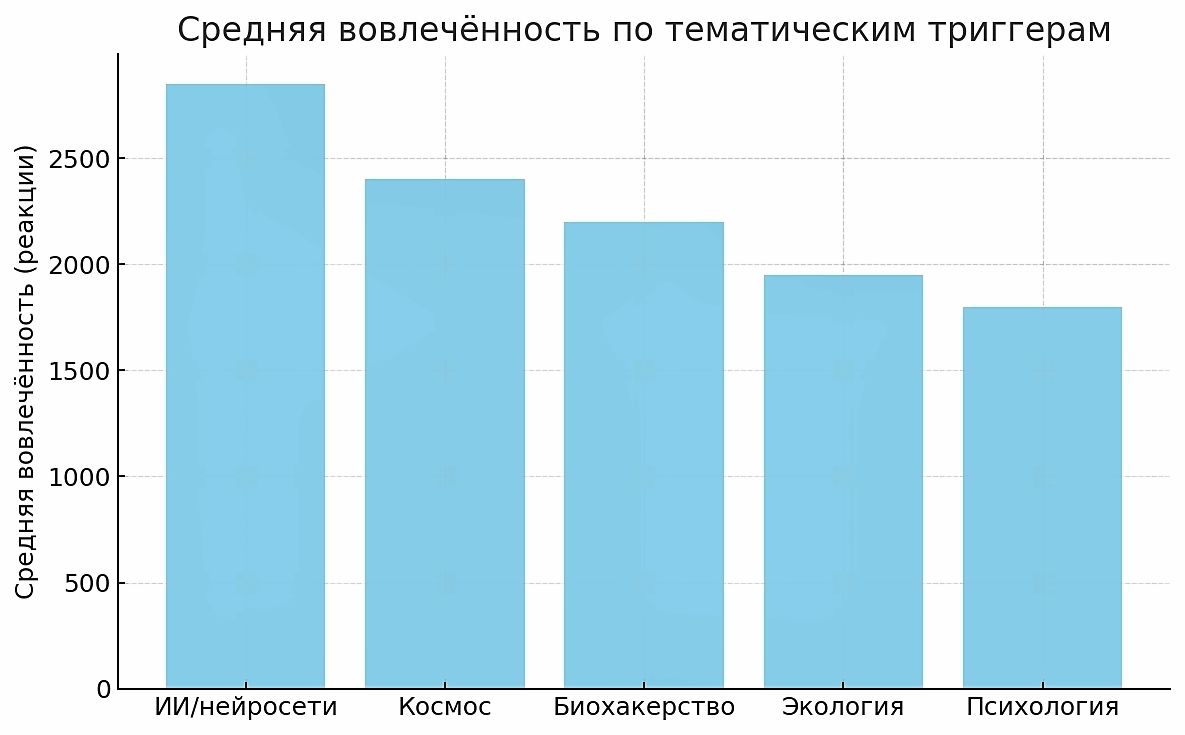
Примечательно, что все эти триггер-темы так или иначе апеллируют к сильным эмоциям и актуальным интересам общества. Популярные тренды (бурный прогресс ИИ, космические достижения) вызывают восторг и чувство причастности к будущему, тогда как социально значимые темы (экология, психическое здоровье) затрагивают чувство ответственности или личной обеспокоенности. Кроме того, многие из перечисленных триггеров сопровождались характерными «виральными» словами. Например, материалы по ИИ часто содержали в заголовках слова вроде «прорыв», «революционный ИИ», «потрясающий пример», посты про космос – «марсианская колония», «исторический запуск» и т.д., что усиленно стимулирует интерес аудитории. В целом же выбор темы сам по себе влияет на шансы контента стать вирусным: способность затронуть модный тренд или животрепещущую проблему – важнейший фактор виральности. Как отмечают специалисты, вирусный контент обычно либо касается того, что уже «на слуху» у масс, либо преподносит неожиданный новый факт по знакомой теме, либо дает практически полезные советы по популярному запросу (там же). Наш анализ триггерных тематик подтверждает это: наибольший отклик получают либо трендовые технологические темы, либо универсально значимые вопросы (здоровье, психология, экология), особенно если поданы с эмоцией и новизной.
3) Дискурсивно-прагматический анализ вирального контента
На дискурсивно-прагматическом уровне анализ был направлен на выявление способов организации сообщения как целостного коммуникативного акта в условиях алгоритмически управляемой медиасреды. В рамках исследования предполагалось, что виральный контент отличается не только формальными языковыми и лексико-семантическими характеристиками, но и специфической прагматической архитектурой, включающей мультимодальность, стратегическое использование визуальных элементов, мемов и хэштегов, а также ориентацию на алгоритмическую видимость.
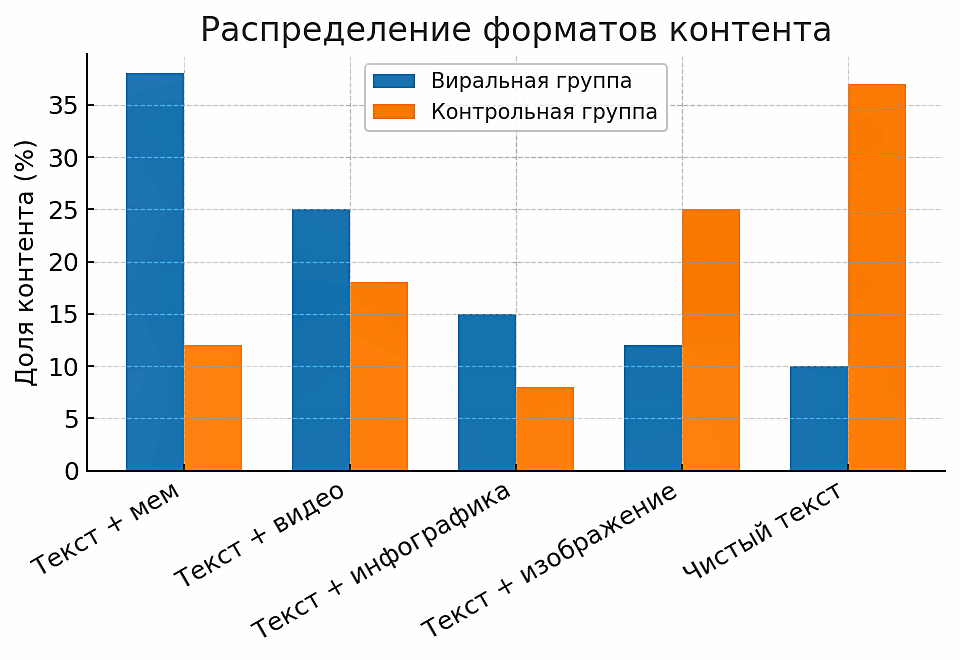
Сравнительный анализ форматов публикаций показал резкое расхождение между виральной и контрольной группами по степени поликодовости. В виральной выборке лишь около 10% сообщений представляли собой чисто текстовые посты, тогда как остальные ~90% включали визуальные компоненты: мемы, видео, инфографику или статические изображения. Для сопоставления, в контрольной группе доля чисто текстовых публикаций достигала 37%, а мультимодальные форматы использовались существенно реже.
Рисунок 8. Распределение форматов контента
Figure 8. Distribution of Content Formats
Анализ метрик вовлеченности подтверждает эффективность поликодовых форматов: чисто текстовые публикации собирали в среднем лишь около 450 реакций, тогда как любой добавленный визуальный элемент заметно повышал отклик аудитории. Так, посты с изображениями получали ~1200 реакций, с инфографикой – около 1950, с видео– порядка 2200. Максимальный эффект наблюдается у постов, сопровождаемых мемами: в среднем ~2850 реакций, что более чем в 6 раз превосходит показатели текста без дополнений. Мем можно определить как «краткий фрагмент медийного текста, сочетающий информационное содержание с яркой упаковкой и благодаря этому многократно копируемый в культуре заинтересованной аудитории. Мемы анализируют как мультимодальные дискурсивные объекты, сочетающие текст и изображение, построенные «горьким юмором» и лаконичностью, направленные на мобилизацию и распространение политических нарративов в ультраправых сообществах (Hakoköngäs et al., 2020). Популярность мемов как социального феномена подтверждается тем, что около 30% миллениалов и представителей поколения Z обмениваются мемами ежедневно. Следовательно, интеграция мема в пост существенно повышает шансы на вирусное распространение, делая сообщение более «заразительным» за счет эмоциональной вовлеченности. В целом прослеживается прямая зависимость: чем более мультимодален контент, тем выше у него показатели вовлеченности. Это наглядно иллюстрирует следующая схема:
Рисунок 9. Средняя вовлеченность по типу контента
Figure 9. Average Engagement by Content Type
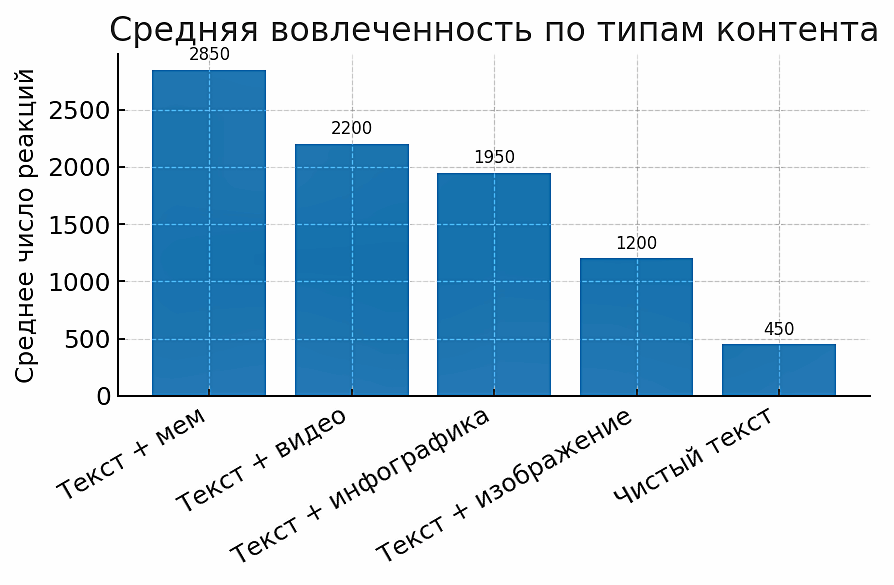
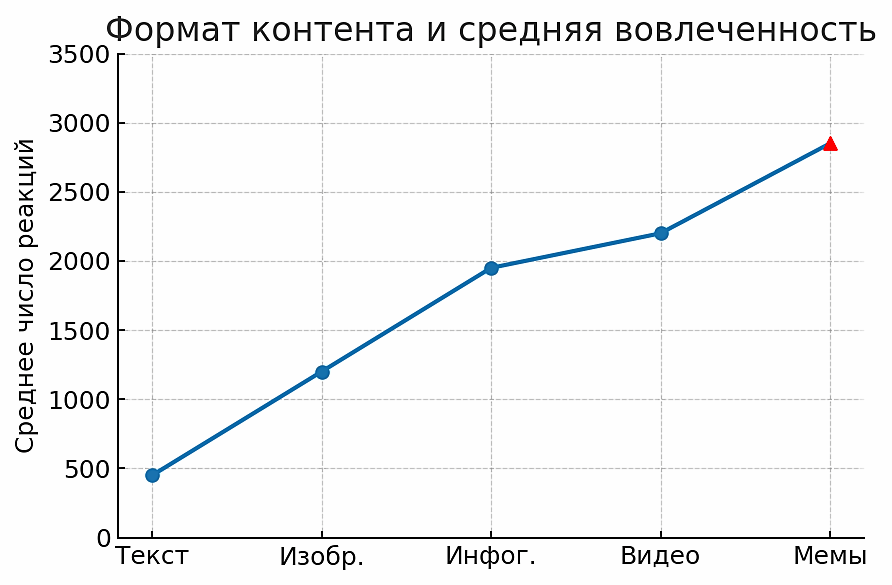
Корреляционный анализ подтвердил значимость рассмотренных дискурсивно-прагматических факторов. Наличие мема в посте оказалось сильнейшим предиктором виральности (коэффициент корреляции r = 0.68, p < 0.001). Также высокую положительную связь с количеством реакций показало использование оценочных хэштегов – r = 0.57 (p < 0.001). Вклад таких параметров, как общее количество хэштегов (r = 0.42, p < 0.01) и формат «текст + видео» (r = 0.39, p < 0.01), статистически значимо меньший, но тоже существенный. Таким образом, данные свидетельствуют: юмористический мем-контент и экспрессивные хэштеги сильнее всего «разгоняют» вовлеченность, тогда как просто добавление видео или множества тегов дает умеренный эффект. График выше визуализирует общий тренд: переход от текста к изображениям, инфографике, видео и мемам сопровождается неуклонным ростом средней реакции аудитории. Этот положительный градиент подтверждает, что мультимедийное обогащение контента является ключевым фактором его вирусного успеха. Более того, определенные типы визуального контента сами по себе привлекательны для пользователей – например, ~90% читателей считают полезными наглядные инфографики, а мемы прочно вошли в повседневную коммуникацию в соцсетях. Все это создает благодатную почву для повышенного распространения подобных сообщений.
Рисунок 10. Связь формата контента и средней вовлеченности
Figure 10. Relationship Between Content Format and Average Engagement
Виральные посты часто опираются на мемы как на особый формат, совмещающий изображение и текст в юмористической или метафорической форме. Был проведен контент-анализ мемов с точки зрения их прагматических функций, и выявлено несколько основных категорий:
Таблица 6. Основные категории мемов
Table 6. Main Categories of Memes
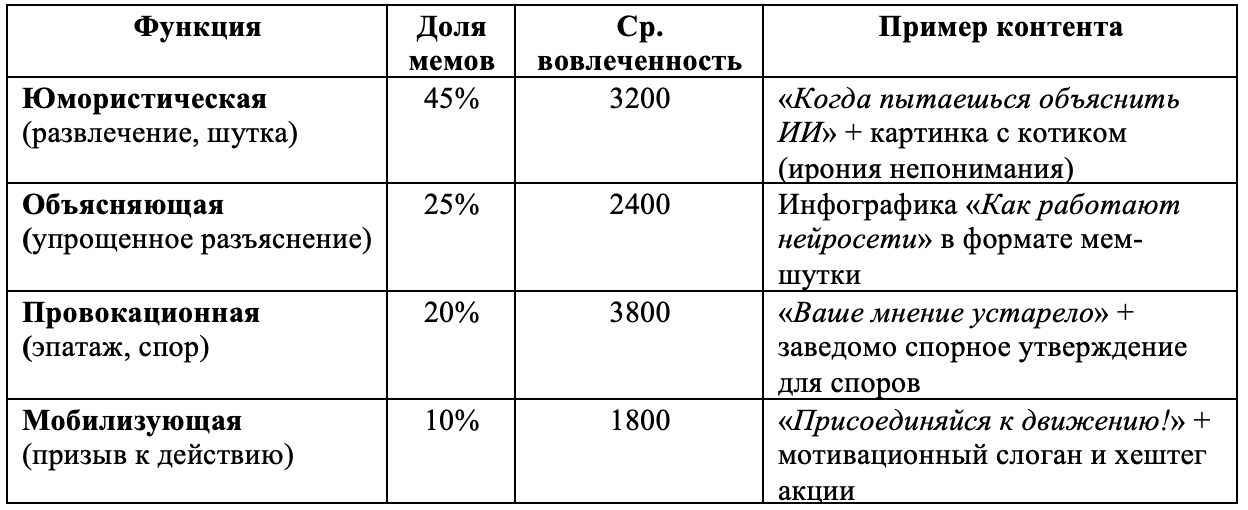
Юмористические мемы доминируют количественно и обеспечивают высокий, но не максимальный уровень вовлеченности. Наибольший эффект демонстрируют провокационные мемы, стимулирующие дискуссию и поляризацию аудитории. Мобилизующие мемы, напротив, оказываются наименее эффективными, что позволяет предположить: открытая агитация уступает виральности юмору и конфликту.
Хэштеги (слова или фразы, помеченные символом #) зародились как механизм навигации в соцсетях, как способ группировать сообщения по темам для удобного поиска. Еще недавно хэштег был прежде всего инструментом объединения постов на одну тему, но сегодня его функция существенно расширилась (Латушко, 2022: 58). Хэштеги в социальных медиа выполняют важную прагматическую функцию маркировки контента и влияния на его алгоритмическую видимость. Наш анализ показал, что создатели вирального контента используют хэштеги значительно активнее, чем обычные пользователи:
Таблица 7. Сравнительные показатели использования хэштегов
Table 7. Comparative Indicators of Hashtag Usage
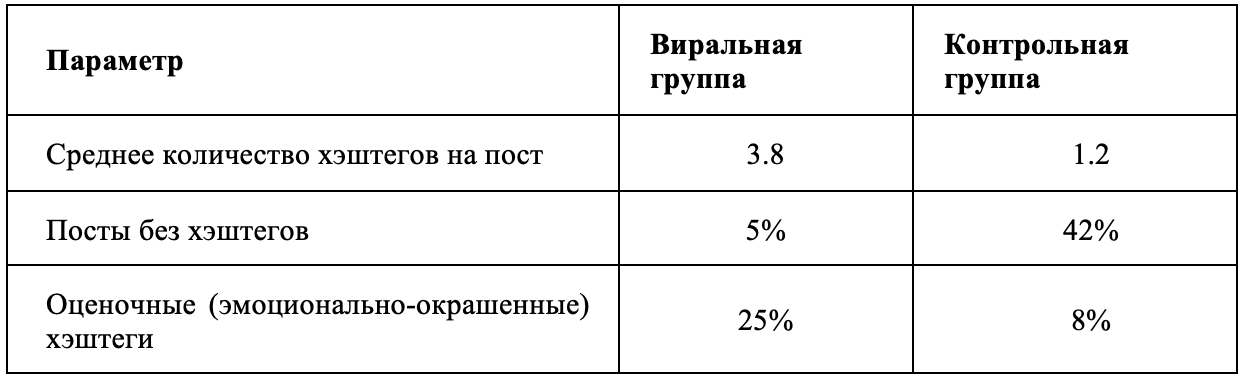
В виральных постах в среднем используется 3–4 хэштега, тогда как в контрольной выборке лишь 1–2. Почти каждый вирусный пост снабжен хотя бы одним хэштегом (только 5% обошлись без них), в то время как среди невиральных постов более 40% вообще не содержали тегов. Также заметно, что авторы вирусного контента чаще добавляют оценочные хэштеги – эмоциональные маркеры типа #шок, #гениально – четверть популярных постов содержала подобные теги, тогда как в обычной группе лишь 8%. Эти различия отражают продуманную стратегию: хэштеги делают пост доступным для более широкой аудитории, так как привязывают его к популярным темам и обсуждениям. Кроме того, хэштеги способствуют вовлечению – исследования показывают, что публикации с хэштегами получают ~12% больше откликов пользователей. Оптимальным считается использование нескольких релевантных тегов; рекомендации на 2025 год говорят о 3–5 хэштегах как «золотой середине» (избыток тегов может восприниматься как спам). Именно такое число мы и видим в среднем у вирусных постов. Таким образом, авторы вирусного контента сознательно насыщают сообщения тегами для максимального охвата, тогда как менее успешные авторы нередко игнорируют этот инструмент.
Частотный анализ тегов выявил преобладание тематических хэштегов, отражающих ключевые темы контента. Как видно из облака тегов, в топ-10 вошли прежде всего слова, связанные с технологиями и наукой: #ИИ, #нейросети, #технологии, #наука, #будущее, #инновации и др. Это показывает, что вирусный контент активно помечается по теме (например, посты про искусственный интеллект получают теги #ИИ и #нейросети почти по умолчанию). Такие теги выполняют сразу две функции: во-первых, повышают алгоритмическую видимость поста в соответствующих интересах аудитории, во-вторых, формируют для читателя фрейм восприятия, заранее указывая, о чем будет сообщение (наука, инновации, и т.д.). Менее часто в топ-10 встречаются эмоционально окрашенные теги типа #шок или #гениально. Они используются точечно для создания эффекта сенсационности, но не принадлежат к одной тематике, поэтому по отдельности не превосходят по частоте тематические метки. Тем не менее, роль таких оценочных хэштегов проявляется в другом измерении – в уровне вовлеченности, который они генерируют.
Рисунок 11. Облако топ-10 хэштегов в виральном контенте
Figure 11. Word Cloud of the Top 10 Hashtags in Viral Content

Функциональная классификация хэштегов в виральном контенте показала, что помимо тематики, теги выполняют ряд прагматических ролей:
Таблица 8. Классификация хэштегов по прагматическим функциям
Table 8. Classification of Hashtags by Pragmatic Functions
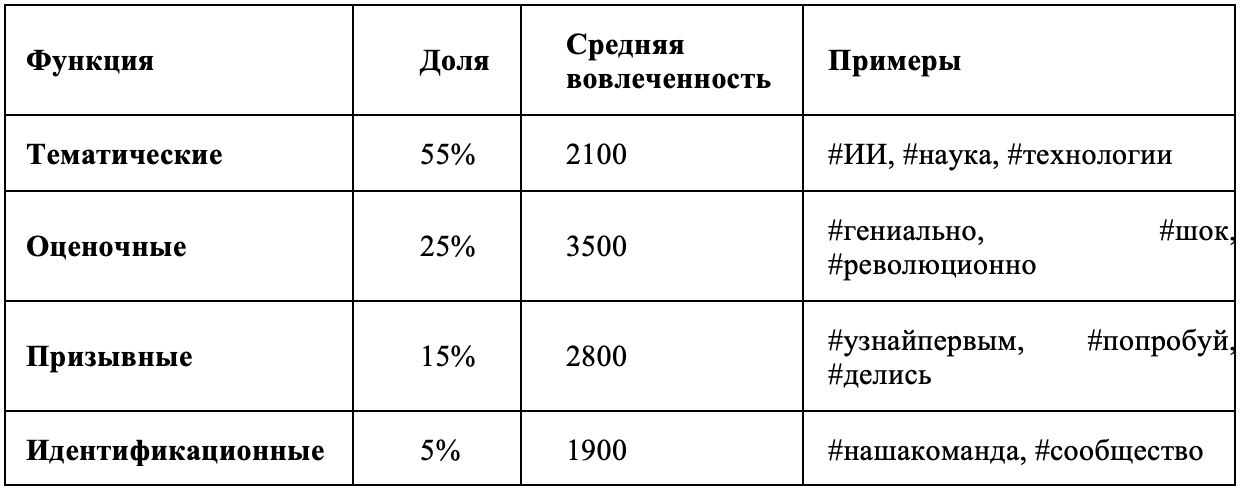
Можно сделать вывод, что успешный виральный пост стремится комбинировать несколько видов хэштегов: как минимум один-два по теме и при необходимости – один оценочный для усиления эмоционального отклика.
Помимо количественных параметров, исследование выявило типичные дискурсивные паттерны, присущие вирусной коммуникации. Эти паттерны показывают, как авторы контента комбинируют различные средства языка и визуального ряда, ориентируясь на восприятие аудитории и алгоритмов платформ:
Мультимодальная аргументация. Виральный дискурс отличается преобладанием визуально-текстового повествования, где основная смысловая нагрузка возлагается на изображение или клип, а текст играет вспомогательную роль. Такой прием можно назвать аргументацией через мем или инфографику: вместо длинного объяснения автор подбирает меткое изображение (мем, график, диаграмму) и сопровождает его минимальным комментарием. В результате сложная идея коммуницируется быстро и эффективно, пользуясь когнитивными преимуществами визуализации. Подобная мультимодальность не только удерживает внимание скроллящей аудитории, но и облегчает доступность информации – недаром 90% пользователей считают, что инфографика помогает им лучше усвоить материал. Таким образом, сочетание картинки и краткого текста создает убедительный месседж, легко распространяемый и понимаемый в социальных сетях.
Хэштег-фрейминг. Еще одной характерной чертой вирусного дискурса является активное использование хэштегов для рамки смыслов и привлечения трафика. Создатели виральных сообщений нередко включают в пост несколько тематических хэштегов, сразу определяя контекст (например, #нейросети, #инновации для технологических новостей). Помимо темы, добавляются оценочные теги, которые задают эмоциональный тон (скажем, #шок, #сенсация или #вау могут предварительно настроить читателя на удивление). В результате еще до чтения основного текста аудитория получает от хэштегов имплицитный сигнал, как воспринимать контент – как что-то удивительное, забавное, важное или относящееся к конкретной сфере. Одновременно хэштеги выполняют и сугубо прагматическую роль – благодаря им пост попадает в соответствующие фиды и поисковые выборки, что существенно увеличивает шансы на вирусное распространение контента за пределы изначальной аудитории.
Алгоритмическая оптимизация контента. Полученные результаты свидетельствуют, что авторы вирусного контента сознательно подстраивают форму подачи под алгоритмические требования платформ. Выявлен своеобразный алгоритмический дизайн сообщений: комбинируются те элементы (мемы, видео, теги, упоминания), которые, как известно, повышают показатели охвата и вовлеченности. Например, если платформа продвигает видеопосты, то делается упор на короткий клип; если в тренде определенный мем-шаблон, используют именно его; если алгоритмы учитывают активность обсуждений, автор может сформулировать провокационный вопрос для комментариев. Такие метадискурсивные стратегии вырабатываются на основе опыта и инсайтов о работе алгоритмов. В результате контент получается «оптимизирован под продвижение». Можно сказать, формируется особый регистр речи – гибрид человеческого творчества и расчета под машину. Как отмечается в современных медиаисследованиях, знание о том, какой формат и какие ключевые слова предпочитают алгоритмы, заставляет создателей контента изначально конструировать сообщение в наиболее выгодном виде. Иными словами, виральный дискурс – это адаптивный дискурс: стиль, тон, структура поста планируются с оглядкой не только на людей, но и на алгоритмического «читателя».
Полученные результаты свидетельствуют о формировании специфического дискурсивного регистра, ориентированного на алгоритмическое продвижение через оптимизацию поликодовых параметров контента.
Заключение
На основе проведенного исследования нами была разработана базовая типология виральных паттернов, представленная в Таблице 9.
Таблица 9. Классификация механизмов виральности
Table 9. Classification of Virality Mechanisms

Проведенный многоуровневый лингвистический анализ подтвердил исходную гипотезу о том, что в условиях алгоритмически управляемой медиасреды виральность контента является результатом системной адаптации языковых и дискурсивных стратегий к критериям платформенного отбора. На всех трех исследовательских уровнях – морфосинтаксическом, лексико-семантическом и дискурсивно-прагматическом – зафиксированы статистически значимые различия между виральным и контрольным контентом. Ниже обобщены ключевые выводы:
На морфосинтаксическом уровне установлена тенденция к синтаксической редукции. Средняя длина предложения в вирусных текстах существенно меньше (≈8.7 слов против 14.3 в контроле) за счет разбиения мысли на короткие фразы. Активно используются риторические вопросы (в 3 раза чаще, чем в контроле), парцелляция (в ~4 раза чаще) и инверсия (в ~2 раза чаще), формируя у текста ритмичность и экспрессивность. Выявлены устойчивые синтаксические паттерны (“вопрос–ответ–решение”, “инверсия+акцент”, “серия парцеллятов”), составляющие ядро алгоритмически оптимизированного стиля на структурном уровне.
На лексико-семантическом уровне подтверждена гипертрофия эмоциональности. Виральные тексты демонстрируют доминирование экспрессивной лексики (“шок”, “сенсация”, “гениально” и пр.), служащей для привлечения внимания. Около 45% вирусных постов построены на бинарных оппозициях (против ~20% в контроле), упрощая и драматизируя смысл. Топ-темы вирусного контента отражают текущую повестку: многочисленные упоминания технологий (ИИ, нейросети) и других трендовых концептов выступают семантическими триггерами, повышающими заметность и актуальность сообщений.
На дискурсивно-прагматическом уровне выявлена доминанта поликодовости. Почти 90% вирусных постов используют гибридные форматы (изображения, мемы, видео и т.д.), тогда как чисто текстовые сообщения крайне редко достигают высокой вовлеченности. Наибольший эффект дают мемы и наглядные инфографики, значительно повышающие отклик аудитории. Практически обязательным элементом вирусного поста стал хэштег: в среднем ~3–4 тега на пост (против ~1 в контроле), выполняющие одновременно навигационную и прагматико-оценочную функцию. Хэштеги задают контекст и эмоцию высказывания, а также увеличивают шансы на попадание контента в тренды и рекомендательные ленты.
В совокупности результаты исследования указывают на формирование своеобразного алгоритмического идиолекта в цифровом дискурсе – стандартизированного языка и стиля, выработанного под воздействием алгоритмических фильтров платформ. Этот идиолект характеризуется краткостью, эмоциональностью, клишированностью и мультимодальностью, то есть всеми теми чертами, которые повышают показатели вовлеченности и видимости. По сути, эффективность сообщения определяется не столько его содержательной новизной или глубиной, сколько соответствием формальным параметрам, считаемым «привлекательными» для алгоритма (и как следствие – для массовой аудитории). Данное явление отмечено не только в развлекательном или коммерческом сегменте, но и в политической коммуникации – там также наблюдается унификация и упрощение языка под влиянием алгоритмической логики. Это свидетельствует о универсальном характере алгоритмического детерминизма в сфере публичной речи: дискурсы различной природы вынужденно приобретают общие черты, продиктованные метриками онлайн-платформ.
Разработанная методика анализа позволяет: прогнозировать виральный потенциал контента на основе лингвистических маркеров; оптимизировать коммуникационные стратегии для цифровой среды; разрабатывать образовательные программы по цифровой грамотности.
Таким образом, формирование алгоритмического идиолекта свидетельствует не просто об изменении стиля, а о более глубокой трансформации механизмов языковой эволюции в цифровой среде. Эволюционный отбор языковых форм все в большей степени осуществляется не в рамках естественной коммуникации между людьми, а под воздействием искусственной среды платформенных алгоритмов, отбирающих контент по формальным, квантифицируемым параметрам. Это порождает феномен «двойной адресации», где языковая стратегия становится инструментом интерфейса с машинной логикой. Подобная оптимизация ведет к стандартизации и ритуализации цифрового дискурса, что, в перспективе, может влиять на когнитивные паттерны восприятия информации, способствуя фрагментации и эмоциональной поляризации. Следовательно, алгоритмический идиолект следует рассматривать как ключевой маркер новой парадигмы публичной коммуникации, в которой эффективность речи детерминируется ее совместимостью с инфраструктурой внимания.
Перспективным представляется кросс-платформенное сравнительное исследование, которое позволит выявить локальные варианты алгоритмического идиолекта. Методологически оно может быть построено на сопоставлении корпусов контента единой тематики с платформ, различающихся архитектурой (например, VK, Telegram, TikTok), с применением единого набора лингвистических метрик. Для изучения долгосрочных эффектов целесообразно комбинировать лонгитюдный корпусный анализ (отслеживание динамики паттернов) с экспериментальными методами (A/B-тестирование воздействия разных стилей на восприятие) и качественными интервью с продуцентами контента. Наконец, сравнительный анализ различных дискурсивных сфер (политического, научного, коммерческого) с использованием разработанной в данной работе трехступенчатой модели позволит оценить универсальность давления алгоритмической логики на публичную речь.
В заключение можно констатировать, что алгоритмически опосредованная коммуникация порождает новую риторическую парадигму, где эффективность высказывания определяется не столько его содержательной ценностью, сколько соответствием формальным параметрам платформенных алгоритмов. Это требует пересмотра традиционных лингвистических моделей в контексте цифровой трансформации публичной сферы и медиакоммуникации.
1 https://martech.org/what-makes-content-go-viral-backed-by-research/#:~:text=,common%20emotion%20in%20viral%20content
https://news.pressfeed.ru/virusnyj-marketing-chto-eto-takoe-kak-im-zanimatsya-primery-uspeshnyh-kampanij/#:~:text=Основной%20параметр%20вирусного%20маркетинга%20–,истории%2C%20а%20также%20забавный%20контент
https://russiancouncil.ru/analytics-and-comments/analytics/politicheskie-memy-i-novyy-mirovoy-poryadok/?sphrase_id=104258383#:~:text=Мем%20,1












Список литературы
Ахренова Н. А. Эволюция политической медиариторики: от монолога к цифровой фрагментации // Медиалингвистика. 2025. Т. 12. № S. С. 168–172.
Ахренова Н. А. Интернет-лингвистика: доминантный подход. М.: Русайнс, 2024. 178 с.
Ахренова Н. А. Лингвопрагматические особенности коммуникации власти и общества в цифровой среде: от государственных порталов к искусственному интеллекту / Ахренова Н. А., Голубцова Е. В., Зененко Н. В. [и др.] // Информационная война: формы ведения и методы лингвистического анализа. М. : Флинта, 2025. 344 с.
Антонова А. А. Эмоционально-презентационные стратегии медийного текста в цифровой среде // Вестник Московского университета. Серия 10: Журналистика. 2020. № 1. С. 34–49.
Вартанова Е. Л. Принцип презентационности и эмоционального усиления контента в новых медиа // МедиаАльманах. 2019. № 4. С. 15–22.
Каминская Т. Л. Экспрессивные приемы и аттрактивность медиатекста: клиповое изложение в онлайн-коммуникации // Вестник Воронежского государственного университета. Серия: Филология. Журналистика. 2021. № 2. С. 88–95.
Крапивин М. Ю. Вирусный медиатекст: от аттрактивности к алгоритмической оптимизации // Медиалингвистика. 2025. № 1 (31). С. 52–66.
Леонтович А. В. Влияние интернет-коммуникации на современные речевые практики // Язык и культура. 2017. № 39. С. 120–128.
Максименко О. В. Аттрактивность медиатекста: лингвостилистические приемы завоевания внимания // Вопросы журналистики. 2013. № 6. С. 45–53.
Медиалингвистика в современной научной парадигме : коллективная монография / под ред. Н. И. Клушиной, Т. В. Ицкович, Л. В. Селезневой. М.: Флинта, 2024. 308 с.
Старовойт М. В. Клиповая подача информации как фактор виральности контента // Труды СПбГУ. Серия 9: Филология. 2021. Т. 27. № 4. С. 112–125.
Чернявская В. Е. Дискурс власти и власть дискурса: проблемы речевого воздействия: учеб. пособие. 3-е изд. М.: Флинта, 2017. 128 с. Электрон. версия. URL: https://dokumen.pub/540300-9785893499872.html (дата обращения: 25.12.2025)
Amoore L. Cloud Ethics: Algorithms and the Attributes of Ourselves and Others. Durham : Duke University Press, 2020. 256 p.
Ananny M., Crawford K. Seeing without knowing: Limitations of the transparency ideal in algorithmic accountability // New Media & Society. 2018. Vol. 20. No. 3. Pp. 973–989.
Arjona-Martín J. B., Gutiérrez-García E., López-de-Ayala M. C. Algoritmos en redes sociales y estrategias de visibilidad mediática // Media and Communication. 2020. Vol. 8. No. 4. Pp. 31–44.
Berger J. A. Contagious: Why Things Catch On. New York : Simon & Schuster, 2013. 256 p.
Berger J. A., Milkman K. L. What Makes Online Content Viral? // Journal of Marketing Research. 2012. Vol. 49. No. 2. Pp. 192–205.
Bucher T. If… Then: Algorithmic Power and Politics. New York : Oxford University Press, 2018. 256 p.
Dawkins R. The Selfish Gene. Oxford : Oxford University Press, 1976. 224 p.
Dillet B. Speaking to algorithms? Rhetorical political analysis as technological analysis // Politics. 2020. Vol. 42. No. 2. Pp. 231–246.
Gillespie T. The Relevance of Algorithms // Media Technologies: Essays on Communication, Materiality, and Society / ed. by T. Gillespie, P. J. Boczkowski, K. A. Foot. Cambridge, MA : MIT Press, 2014. Pp. 167–193.
Hakoköngäs E., Halmesvaara O., Sakki I. Persuasion Through Bitter Humor: Multimodal Discourse Analysis of Rhetoric in Internet Memes of Two Far-Right Groups in Finland // Social Media + Society, 6(2). URL: https://doi.org/10.1177/2056305120921575 (дата обращения: 25.12.2025).
Hemsley J. Virality: Developing a Rigorous and Useful Definition of an Information Diffusion Process: working paper. Syracuse University, 2011. URL: https://ssrn.com/abstract=3129424 (дата обращения: 25.12.2025).
Jenkins H. Convergence Culture: Where Old and New Media Collide. New York : New York University Press, 2006. 336 p.
Jenkins H., Ford S., Green J. Spreadable Media: Creating Value and Meaning in a Networked Culture. New York : New York University Press, 2013. URL: https://www.researchgate.net/publication/298428278_Henry_Jenkins_Sam_Ford_Joshua_Green_Spreadable media Creating Value and meanin in A Networked Culture New York New York University Press 2013 (дата обращения: 25.12.2025).
Introna L. D. Algorithms, Governance, and Governmentality: On Governing Academic Writing // Science, Technology & Human Values. 2016. Vol. 41. No. 1. Pp. 17–49.
Kitchin R. Thinking Critically about and Researching Algorithms // Information, Communication & Society. 2017. Vol. 20. No. 1. Pp. 14–29.
Latour B. Reassembling the Social: An Introduction to Actor-Network-Theory. Oxford : Oxford University Press, 2005. URL: https://academic.oup.com/book/52349 (дата обращения: 25.12.2025).
Leskovec J., Adamic L. A., Huberman B. A. The Dynamics of Viral Marketing // ACM Transactions on the Web. 2007. Vol. 1. No. 1. Article 5. URL: https://www.researchgate.net/publication/308062589_The_Dynamics_of_Viral_Marketing (дата обращения: 25.12.2025).
Nahon K., Hemsley J. Going Viral: Everybody’s Guide to the Viral Phenomenon. Cambridge : Polity Press, 2013. 182 p.
Narayanan A. Understanding Social Media Recommendation Algorithms. Knight First Amendment Institute, 2023. URL: https://knightcolumbia.org/content/understanding-social-media-recommendation-algorithms (дата обращения: 25.12.2025).
Pariser E. The Filter Bubble: What the Internet Is Hiding from You. New York : Penguin Press, 2011. 302 p.
Quan Yan. 算法修辞:媒介实践新形态与数字人文新取向 [Algorithmic rhetoric: a new form of media practice and a new orientation of digital humanities] // Jianghuai Forum. 2023. No. 2. Pp. 52–61.
Quan Yan. 隐形超权力:算法传播研究 [Invisible superpower: research on algorithmic communication]. Beijing : Social Sciences Academic Press, 2023. 312 p.
Roumbanis L. On Algorithmic Mediations // European Journal of Social Theory. 2025. URL: https://journals.sagepub.com/doi/10.1177/13684310251319677 (дата обращения: 25.12.2025).
Rogers E. M. Diffusion of Innovations. New York : Free Press, 1962. 367 p.
Rushkoff D. Media Virus! Hidden Agendas in Popular Culture. New York : Ballantine Books, 1994. 320 p.
Van Dijk T. A. The Network Society: Social Aspects of New Media. 4th ed. London : Sage, 2020. 368 p.
van Dijck J., Poell T., de Waal M. The Platform Society: Public Values in a Connective World. New York : Oxford University Press, 2018. 226 p.