
Written vs generated text: “naturalness” as a textual and psycholinguistic category
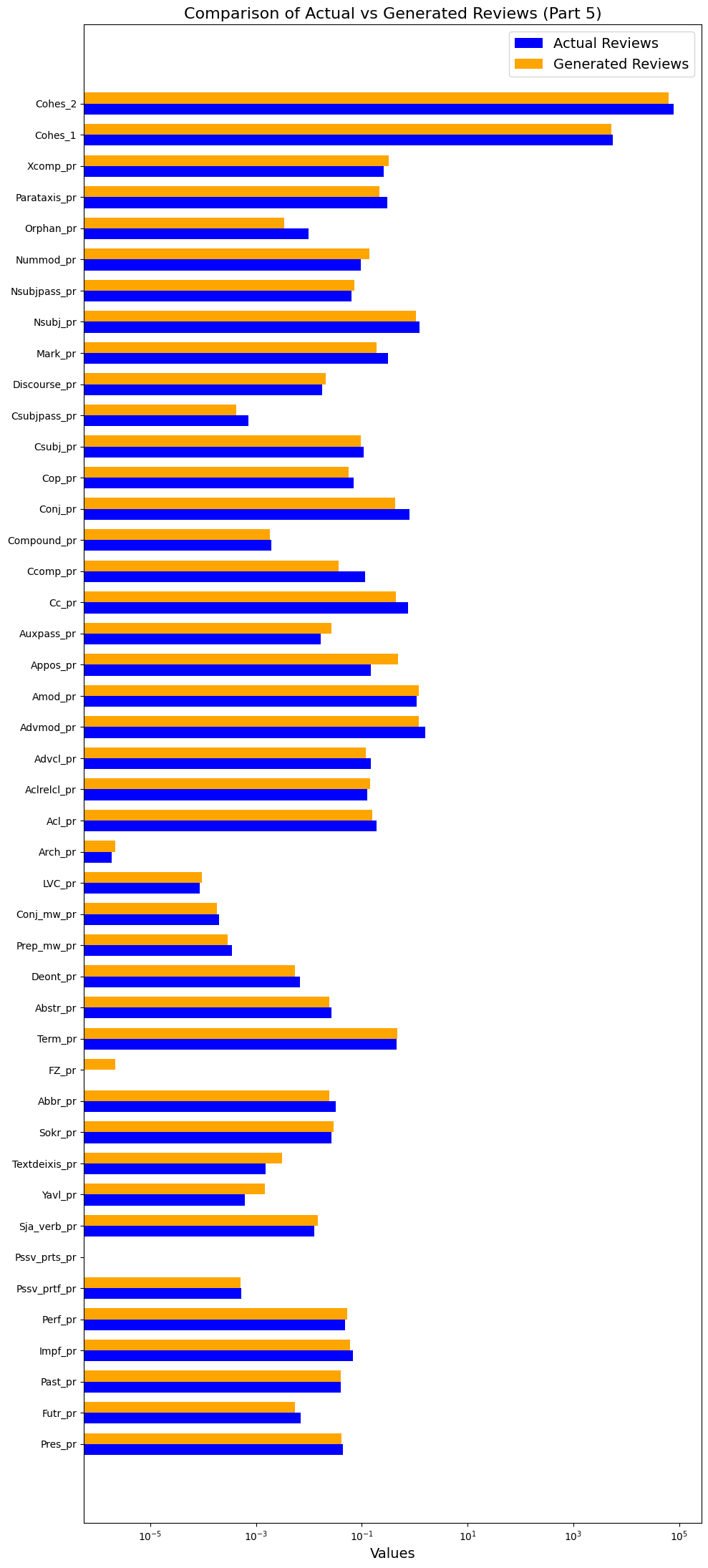
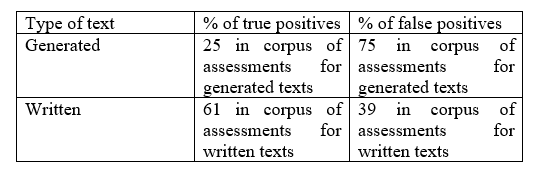
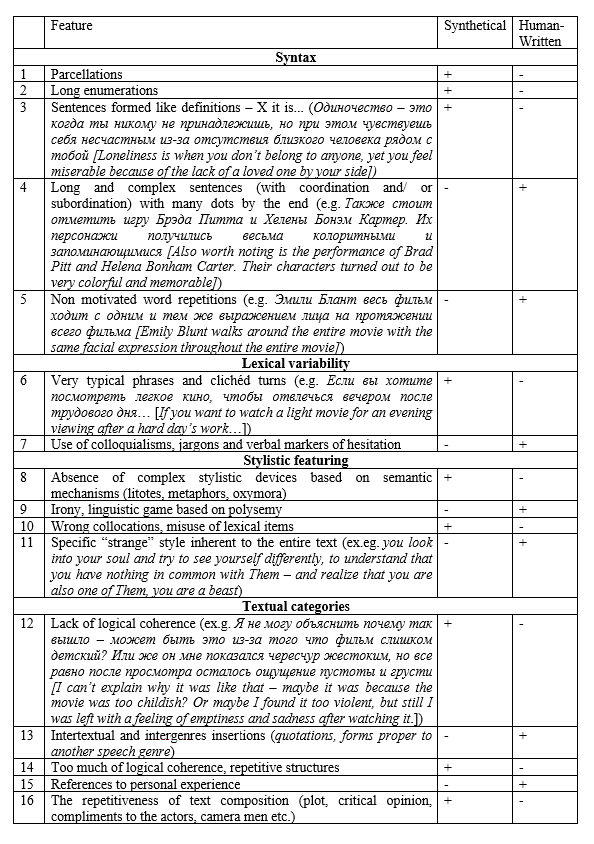
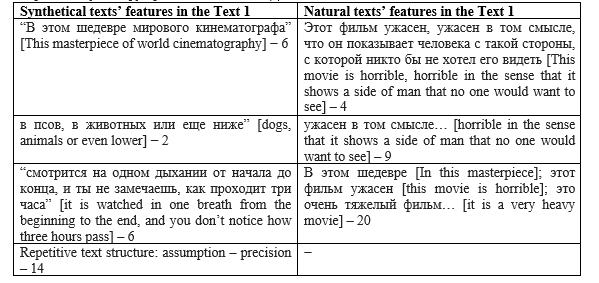
In the context of the development of text generation technologies, the opposition “naturalness − unnaturalness of text” has been transformed into a new dichotomy: “naturalness – artificiality”. The aim of this article is to investigate the phenomenon of naturalness in this context from two perspectives: analyzing the linguistic characteristics of a natural text against a generated (artificial) text and systematizing introspective perceptions of Russian native speaker informants as to what a “natural” text should be like and how it should differ from a generated text. The material for the study was a parallel corpus of film reviews in Russian, consisting of two subcorpora: reviews written by people and those generated by a large language model based on prompts, which are the beginnings of reviews, from the first subcorpus. The following methods were applied for the comparative analysis of the two subcorpora: computer-assisted text processing for calculating the values of 130 metrics of text linguistic complexity, psycholinguistic experiment, expert text analysis, contrastive analysis. As a result, it was determined that from the point of view of their own linguistic characteristics, “natural” texts differ from generated texts mainly by greater flexibility of syntactic structure, allowing both omission or reduction of structures and redundancy, as well as by slightly greater lexical variability. Naturalness as a psycholinguistic category is related to the informants’ autostereotypical ideas about the cognitive characteristics of people as a species. The analysis of texts erroneously attributed by informants (generated, labelled as natural and vice versa) showed that a number of characteristics of this autostereotype are overestimated by informants, while others, in general, correlate with the linguistic specificity of texts from the subcorpus of written reviews. In conclusion, we formulate definitions of naturalness as a textual and psycholinguistic category.
Figures

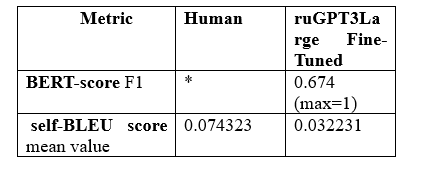
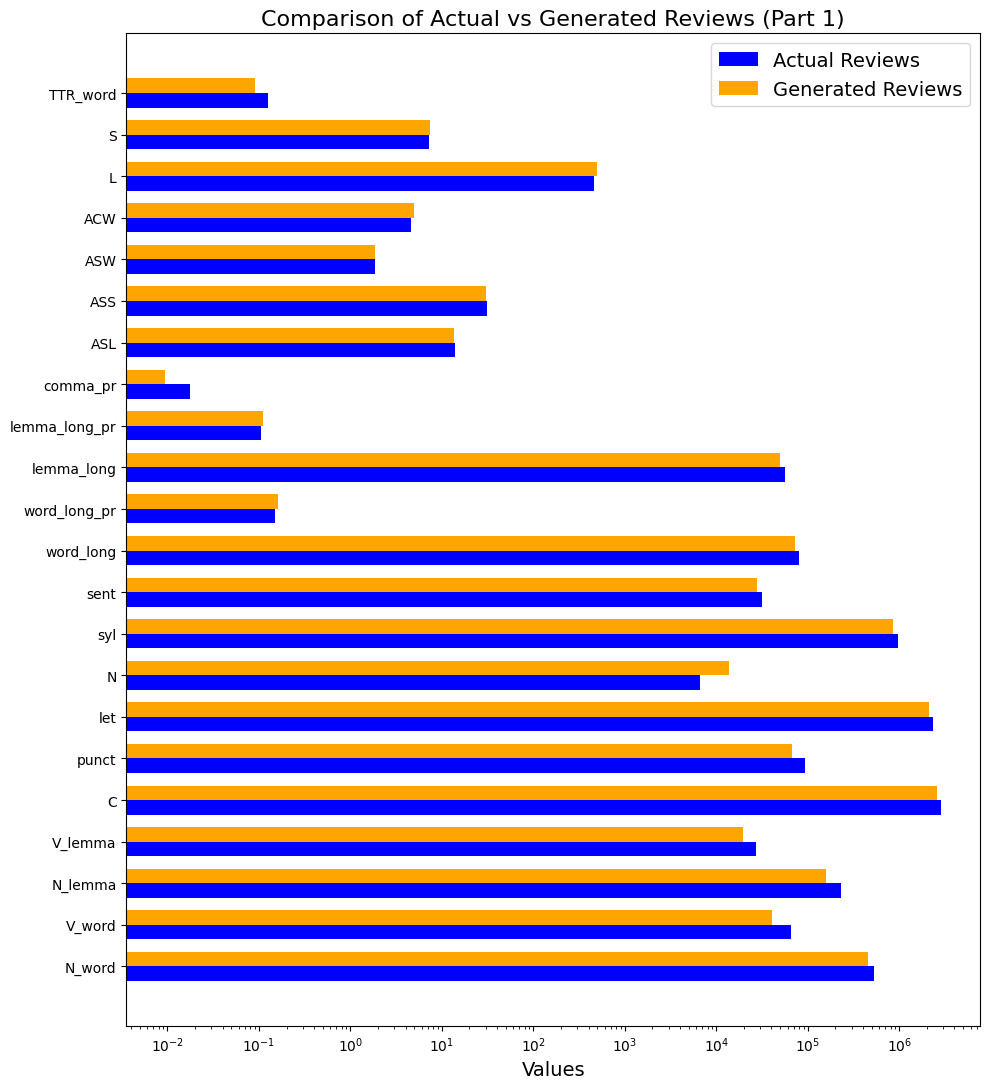
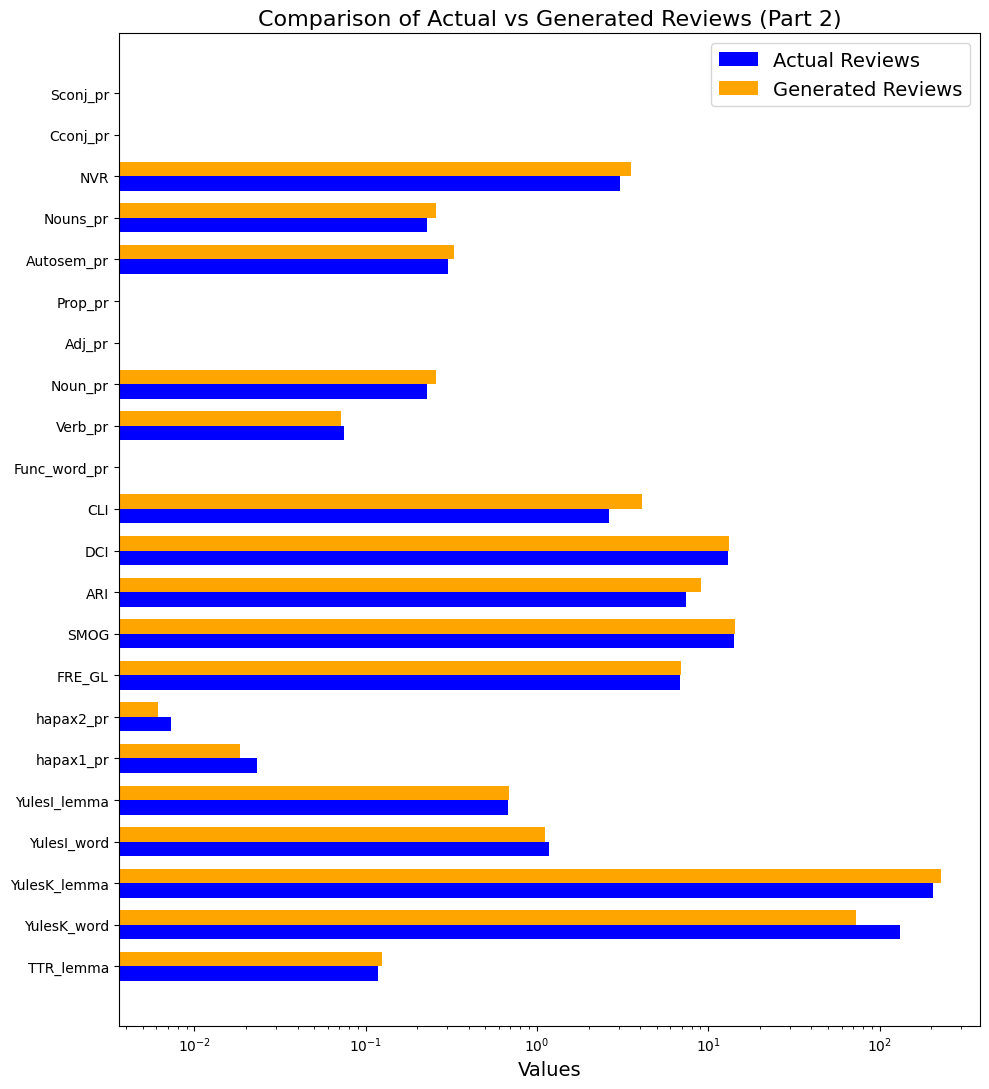
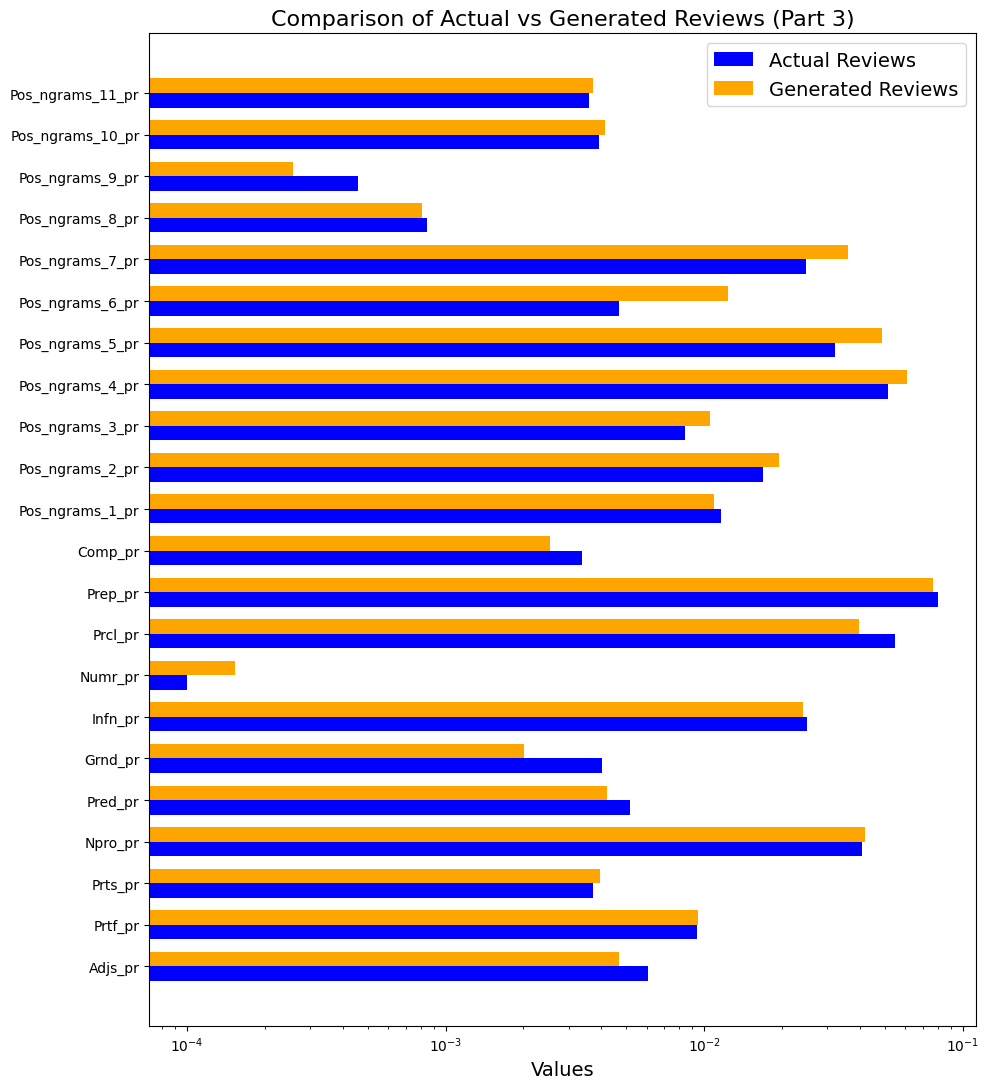



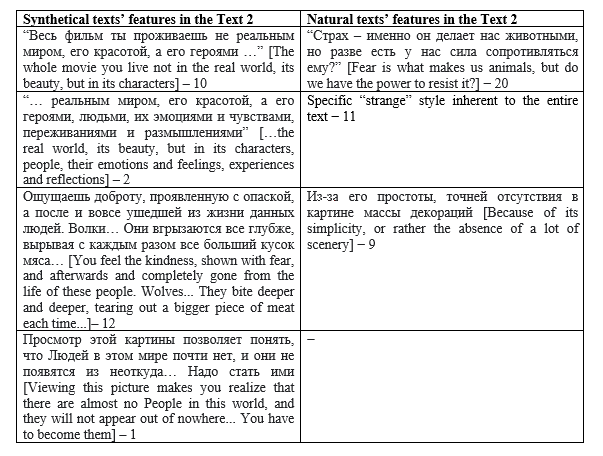
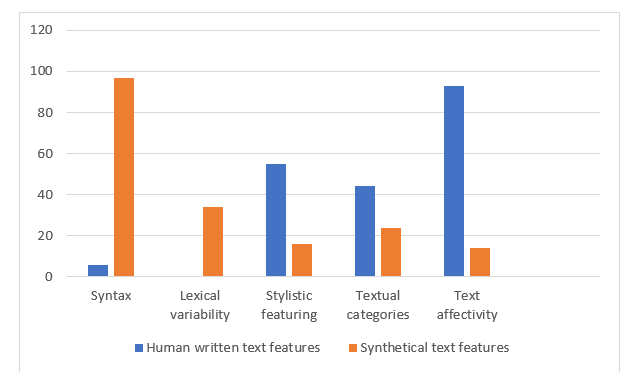
Kolmogorova, A. V. and Margolina, A. V. (2024) Written vs generated text: “naturalness” as a textual and psycholinguistic category, Research Result. Theoretical and Applied Linguistics, 10 (2), 71-99. DOI: 10.18413/2313-8912-2024-10-2-0-4
Research Result. Theoretical and Applied Linguistics is included in the scientific database of the RINTs (license agreement No. 765-12/2014 dated 08.12.2014).
Журнал включен в перечень рецензируемых научных изданий, рекомендуемых ВАК












While nobody left any comments to this publication.
You can be first.
Alzahrani, E. and Jololian, L. (2021). How Different Text-Preprocessing Techniques Using The BERT Model Affect The Gender Profiling of Authors, arXiv preprint arXiv: 2109.13890. https://doi.org/10.48550/arXiv.2109.13890 (In English)
Bally, Ch. (1913). Le language et la vie, Edition Atar, Paris, France. (In French)
Bender, E. M., Gebru, T., McMillan-Major, A. and Shmitchell, Sh. (2021). On the dangers of stochastic parrots: Can language models be too big?, Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–623. (In English)
Blinova, O. and Tarasov, N. (2022). A hybrid model of complexity estimation: Evidence from Russian legal texts, Frontiers in Artificial Intelligence, 5. https://doi.org/10.3389/frai.2022.1008530 (In English)
Celikyilmaz, A., Clark, E. and Gao, J. (2021). Evaluation of text generation: A survey, arXiv preprint arXiv: 2006.14799. https://doi.org/10.48550/arXiv.2006.14799 (In English)
Dashela, T. and Mustika, Y. (2021). An Analysis of Cohesion and Coherence in Written Text of Line Today about Wedding Kahiyang Ayu and Bobby Nasution, SALEE: Study of Applied Linguistics and English Education, 2 (2), 192−203. https://doi.org/10.35961/salee.v2i02.282 (In English)
Fauconnier, G. (1981). Pragmatic functions and mental spaces, Cognition, 10 (1-3), 85−88. (In English)
Holtzman, A., Buys, J., Du, L., Forbes, M. and Choi, Y. (2019). The Curious Case of Neural Text Degeneration, arXiv preprint arXiv: 1904.09751. https://doi.org/10.48550/arXiv.1904.09751 (In English)
Lavie, A. &Agarwal, A. (2007). METEOR: An automatic metric for MT evaluation with high levels of correlation with human judgments, Proceedings of the Second Workshop on Statistical Machine Translation, 228–231. (In English).
Li, C., Zhang, M. and He, Y. (2022). The Stability-Efficiency Dilemma: Investigating Sequence Length Warmup for Training GPT Models, arXiv preprint arXiv: 2108.06084v4. https://doi.org/10.48550/arXiv.2108.06084 (In English)
Lin, Ch-Y. (2004). Rouge: A package for automatic evaluation of summaries, Text summarization branches out, 74–81. (In English)
Liu, X., Ji, K., Fu, Y., Lam Tam, W., Du, Zh., Yang, Zh. and Tang, J. (2022). P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-Tuning Universally Across Scales and Tasks, arXiv preprint arXiv: 2110.07602.https://doi.org/10.48550/arXiv.2110.07602 (In English)
Margolina, A.V. (2022). Controlling impression: making ruGPT3 generate sentiment-driven movie reviews, Journal of Applied Linguistics and Lexicography, Vol. 4., 1, 15-25. (In English)
Margolina, A., Kolmogorova, A. (2023). Exploring evaluation techniques in controlled text generation: a comparative study of semantics and sentiment in ruGPTLarge-generated and human-written movie reviews, Computational Linguistics and Intellectual Technologies: Papers from the Annual International Conference, 1082-1090. (In English).
Mikhaylovskiy, N. (2023). Long story generation challenge, Proceedings of the 16th International Natural Language Generation Conference: Generation Challenges, 10–16. (In English)
Mnih, V., Kavukcuoglu, K., Silver, D. et al. (2015). Human-level control through deep reinforcement learning, Nature, 518 (7540), 529–533. http://dx.doi.org/10.1038/nature14236 (In English)
Newmark, P. (1987). Manual de traducción. Madrid: Ediciones Cátedra. (In Spanish)
Novikova, J., Lemon, O. and Reiser, V. (2016). Crowd-sourcing NLG data: Pictures elicit better data, Proceedings of 9th International Natural Language Generation Conference, 265–273. DOI: 10.18653/v1/W16-6644 (In English)
Obeidat, A. M., Ayyad, G. R., Sepora, T. and Mahadi, T. (2020). The tension between naturalness and accuracy in translating lexical collocations in literary text, Journal of Social Sciences and Humanities, 17 (8), 123–134. (In English)
Orešnik, J. (2002). Naturalness in English: some (morpho)syntactic examples, Linguistica, 42. DOI: 10.4312/linguistica.42.1.143-160 (In English)
Rachmawati, S., Sukyadi, D. and Samsudin, D. (2021). Lexical cohesion in the commercial advertisements of five Korean magazines, Journal of Korean Applied Linguistics, 1 (1), 29−44. (In English)
Rogers, M. (1998). Naturalness and Translation, SYNAPS: Journal of Professional Communication, 2 (99), 9–3. (In English)
Schramm, A. (1998). Tense and Aspect in Discourse, Studies in Second Language Acquisition, 20 (3), 433–434. https://doi.org/10.1017/s0272263198283069 (In English)
Schuff, H. & Vanderlyn, L. & Adel, H. & Vu, Th. (2023). How to do human evaluation: A brief introduction to user studies in NLP, Natural Language Engineering, 29, 1-24. DOI: 10.1017/S1351324922000535 (In English)
Serce, G. (2014). Relationship between naturalness and translations methods: Towards an objective characterization, Synergies Chili, 10, 139−153. (In English)
Siipi, H. (2008). Dimensions of Naturalness, Ethics and the Environment, 13 (1), 71−103. https://doi.org/10.2979/ETE.2008.13.1.71 (In English)
Sinclair, J. (1983). Naturalness in language, in Aarts, J. and Meys, W. (eds.), Corpus Linguistiсs, 203−210. (In English)
Talmy, L. (2000). Toward a cognitive semantics, vol. 2: Typology and process in concept structuring. Cambridge, Mass.: MIT Press (In English)
Thibault, P. J. (2011). First order languaging dynamics and second order language: The distributed language view, Educational Psychology, Vol.V, 32, 210–245. (In English)
Venuti, L. (1995). The translator’s invisibility, Routledge, London and New York. (In English)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter,D., Xia,F., Chi E., Le Qu., Zhou D. (2023). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, arXiv:2201.11903. https://doi.org/10.48550/arXiv.2201.11903 (In English)
Wilson, D. (1998). Discourse, coherence and relevance: A reply to Rachel Giora, Journal of Pragmatics, 29 (1), 57−74. (In English)
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q. and Artzi, Y. (2020). BERTscore: Evaluating text generation with BERT, arXiv preprint arXiv: 1904.09675. https://doi.org/10.48550/arXiv.1904.09675 (In English)
Zhou, J. and Bha, S. (2021). Paraphrase generation: A survey of the state of the art, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 5075–5086. (In English)
Zhu, Y., Lu, S., Zheng, L., Guo, J., Zhang, W., Wang, J. and Yu, Y. (2018). Texygen: A Benchmarking Platform for Text Generation Models, arXiv preprint arXiv: 1802.01886.https://doi.org/10.48550/arXiv.1802.01886 (InEnglish)
The article was prepared based on the materials of the project “Text as Big Data: Methods and Models of Working with Big Text Data”, which is carried out within the framework of the Fundamental Research Program of the National Research University Higher School of Economics (HSE University) in 2024.