
Text complexity increase in Russian texts as a function of morphological changes
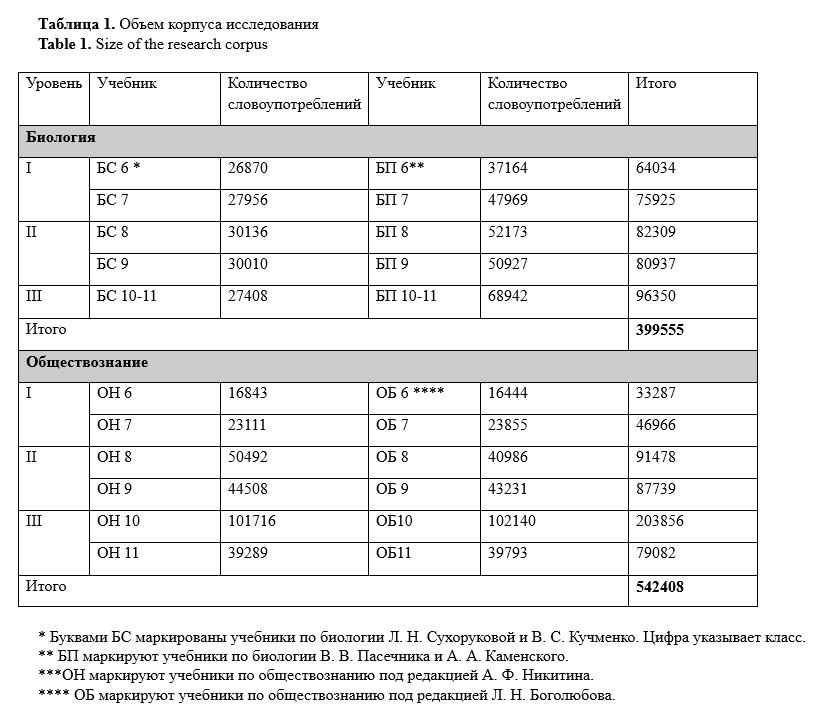
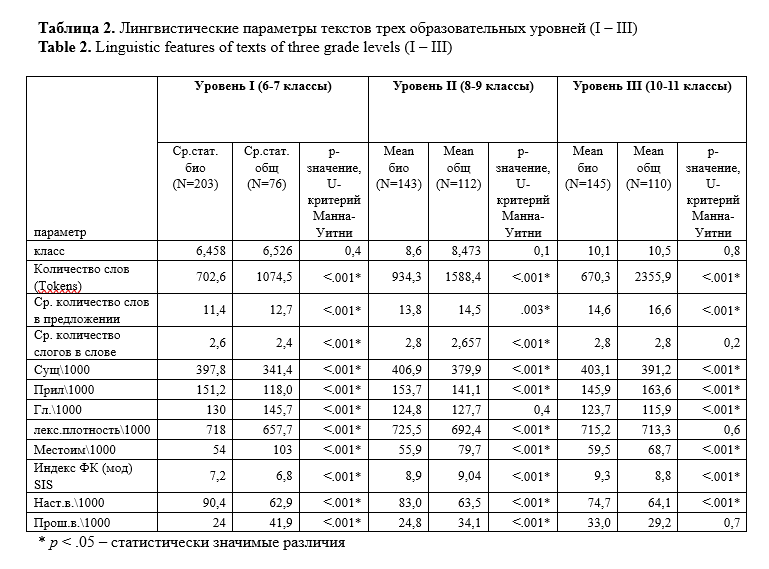
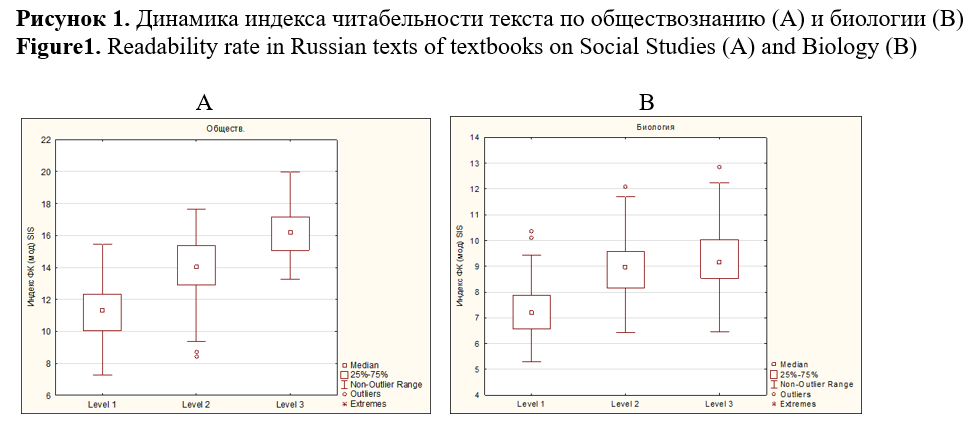
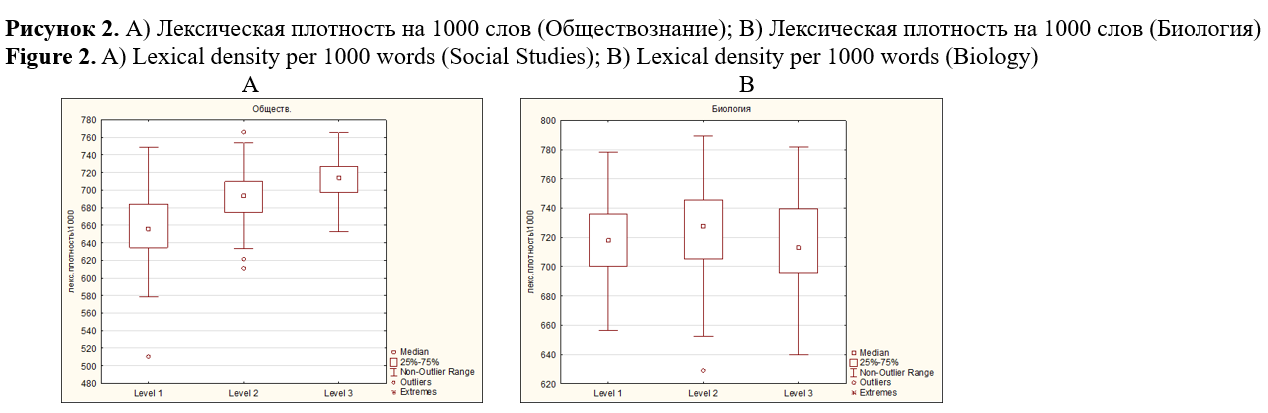
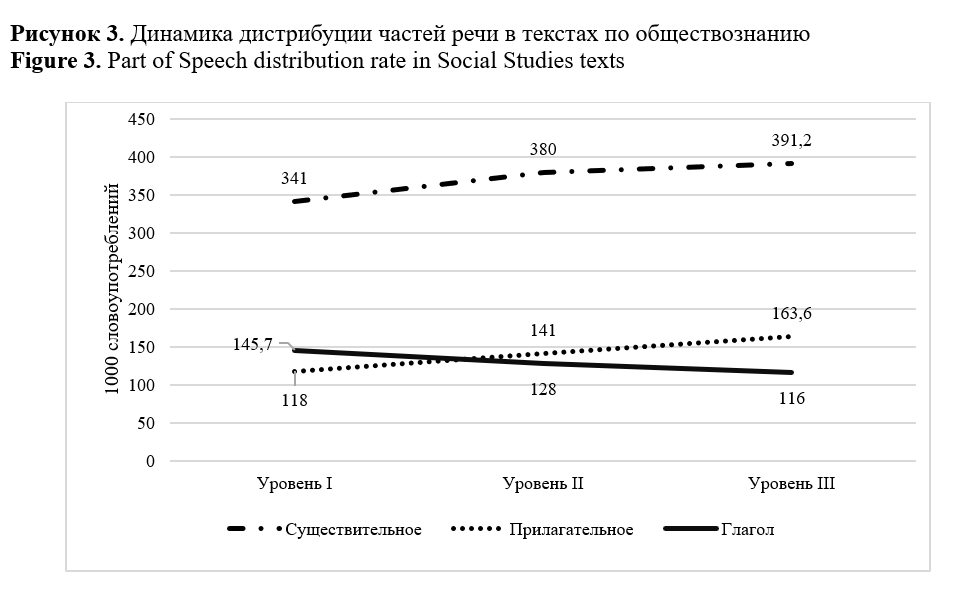
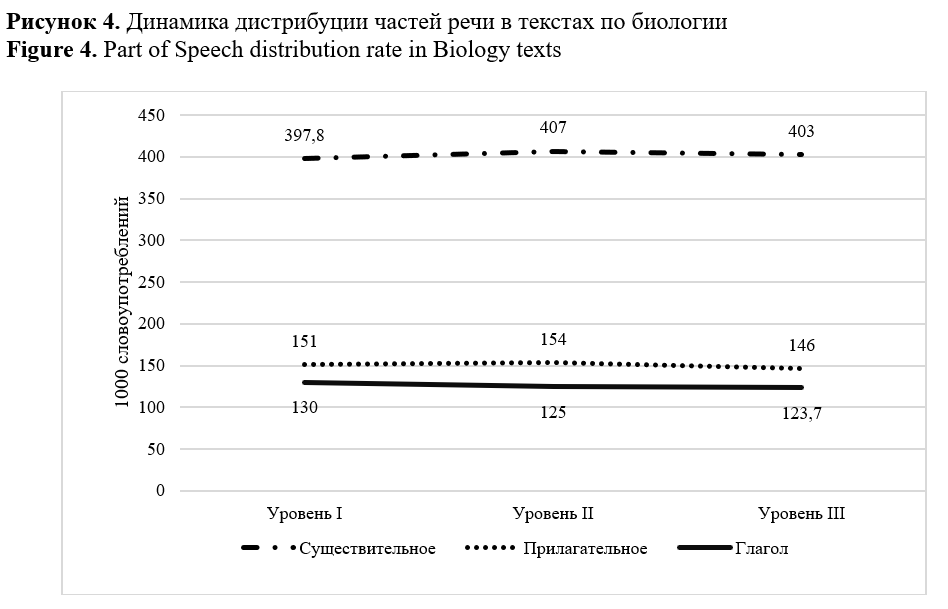
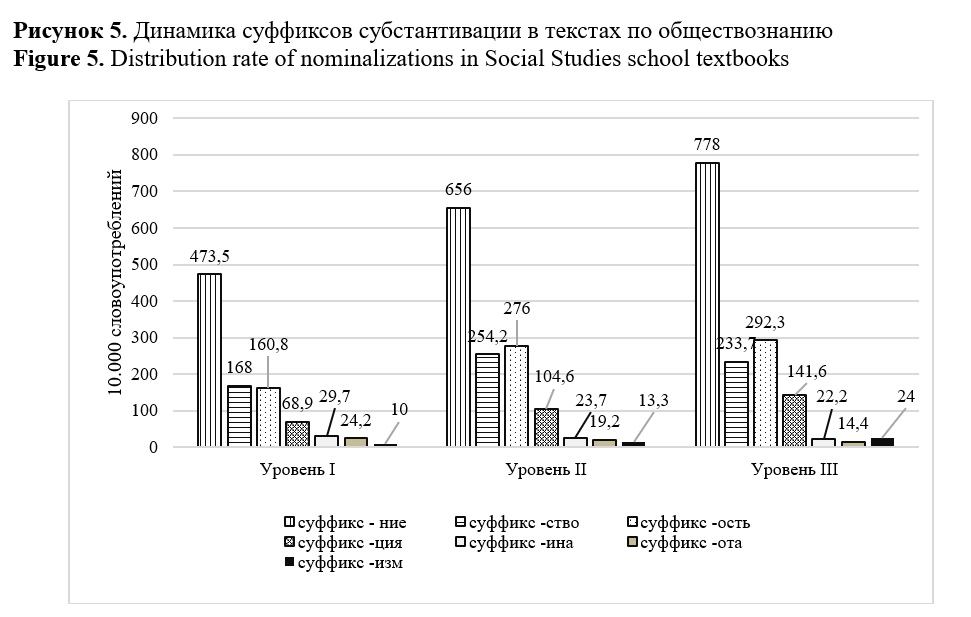
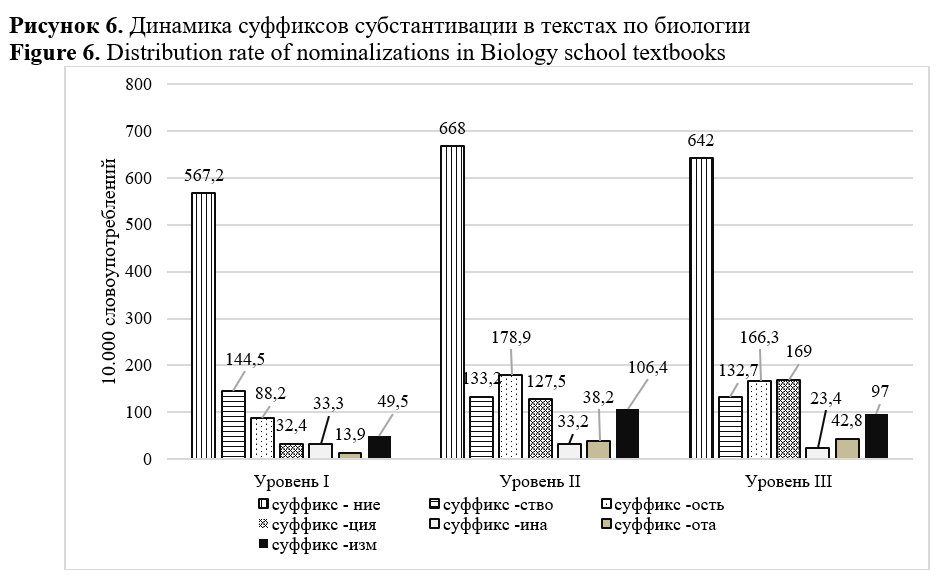
The study aims to identify (1) morphological complexity predictors and (2) domain inherent markers able to differentiate subject areas of academic text in Russian. The total size of the corpus, including textbooks on biology and social studies of three levels of complexity, corresponding to 6-7, 8-9, and 10-11 grades of the Russian school, amounted to 941963 tokens. The linguistic complexity of the texts was assessed using the Flesch-Kincaid readability formula modified for the Russian language, and the interdependence of the parameters was measured based on the correlation analysis conducted with STATISTICA. Calculation of linguistic parameters values, including distribution of nouns, adjectives, verbs, and readability index, were performed using RuLingva (rulex.kpfu.ru/), a text profiler for the Russian language, while the frequency metrics of deverbatives and deadjectives were identified by the contributors manually. To ensure comparability of the metrics, the distributional analysis of deverbatives and deadjectives was performed in the corpus normalized to 10000 tokens. Metrics “noun distribution”, “lexical density”, “deverbation”, “deadjectivation” demonstrated linear interdependence with readability and as such can be viewed as complexity predictors. Inverse correlation was revealed between text readability and verb distribution. Morphological analysis confirmed a high level of texts nominativity and a stable growth of substantives frequency. The latter explicates in an increase in the frequency of deverbation and deadjectivation suffixes in texts from the 6th to the 11th grade. Metrics of lexical density, adjective distribution and substantive suffixes demonstrate ability to discriminate academic texts domains. The research findings are applicable in text analytics, computational linguistics, genre studies, and can be useful for test developers and textbook writers. The authors view the research prospect in the study of compounds of Latin and Greek origin in academic texts. The identified parameters may be used as linguistic complexity predictors and domain discriminants.
Figures
Gatiyatullina, G. M., Gafiyatova, E. V., Danilov, A. V. (2024). Text complexity increase in Russian texts as a function of morphological changes, Research Result. Theoretical and Applied Linguistics, 10 (3), 70-90.












While nobody left any comments to this publication.
You can be first.
Valgina, N. S. (2003). Teoriya teksta [Theory of text], Logos, Moscow, Russia. (In Russian)
Jerebilo, Т. V. (2010). Slovar lingvisticheskih terminiv [A Dictionary of linguistic terms]. Issue 5, revised and added, Piligrim, Nazran, Russia. (In Russian)
Kozhina, M. N. (1972). O rechevoy sistemnosti nauchnogo stilya sravnitel’no s nekotorymi drugimi [On the speech systematicity of scientific style in comparison with some others] Perm State University Publishing House, Perm, Russia. (In Russian)
Mamontov, A. S., Mamontova, Ye. Ye. (2012). Lingvostatisticheskiy analiz ispol’zovaniya deverbativov v razlichnykh vidakh tekstov russkogo i angliyskogo yazykov [Linguistic and statistical analysis of the use of deverbatives in various types of texts in Russian and English], Vestnik RUDN, No. 2., 107–110. (In Russian)
Matskovskiy, M. S. (1976). Problemy chitabel’nosti pechatnogo materiala [Problems of readability of printed material], in Dridze, T. M. and Leontyev, A. A. (eds.) Meaningful perception of a speech message in the conditions of mass communication, Nauka, Moscow, 126–142. (In Russian)
Mikk, Ya. A. (1970). O faktorakh ponyatnosti uchebnogo teksta [On the factors of understandability of educational text], Abstract of Ph.D dissertation, University of Tartu, USSR. (In Russian)
Mitrofanova, O. D. (1973). Yazyk nauchno-tekhnicheskoy literatury [Language of scientific and technical literature], Moscow University Press, Moscow, Russia. (In Russian)
Oborneva, I. V. (2006). Avtomatizirovannaya otsenka slozhnosti uchebnykh tekstov na osnove statisticheskikh parametrov [Automated assessment of the complexity of educational texts based on statistical parameters], Abstract of PhD dissertation, Moscow, Russia. (In Russian)
Petrova, N. Ye. (2009). Substantivatsiya i deadverbializatsiya narechiy v sovremennom russkom yazyke [Substantivization and deadverbialization of adverbs in the modern Russian language], Vestnik Uralskogo gosudarstvennogo universiteta: Seriya gumanitarniye nauki, 1/2 (63), 35–42. (In Russian)
Sirotinina, O. B. (ed.) (2009). Razgovornaya rech’ v sisteme funktsional’nykh stiley sovremennogo russkogo literaturnogo yazyka. Grammatika: [Colloquial speech in the system of functional styles of the modern Russian literary language: Grammar], Moscow, USSR. (In Russian)
Shpakovskiy, Yu. F. (2007). Otsenka trudnosti vospriyatiya i optimizatsiya slozhnosti uchebnogo teksta (na materiale tekstov po khimii) [Assessing the difficulty of perception and optimizing the complexity of educational text (based on texts in chemistry)], Abstract of Ph.D dissertation, Minsk, Belarus. (In Russian)
Alderson, J. Ch. (2000). Assessing reading, Cambridge University Press, London, UK. (In English)
Banks, D. (2005). On the historical origins of nominalized process in scientific text, English for Specific Purposes 24/3, 347–367. DOI: 10.1016/j.esp.2004.08.002 (In English)
Banks, D. (2008). The Development of Scientific Writing: Linguistic Features and Historical Context, Equinox, London, UK. (In English)
Biber, D. and Gray, B. (2016). Grammatical complexity in academic English: Linguistic change in writing, Cambridge University Press, Cambridge, UK. (In English)
Biber, D., Gray, B. (2013). Nominalising the verb phrase in academic scientific writing, in Bas Aaarts et al. (Eds.), The Verb Phrase in English, Cambridge University Press, Cambridge, UK. (In English)
Biber, D., Johansson, S., Leech, G., Conrad, S. and Finegan, E. (2021). Grammar of spoken and written English, John Benjamins, Amsterdam, Netherlands. https://doi.org/10.1075/z232(In English)
Biber, D., Johansson, S., Leech, G., Conrad, S. and Finegan, E. (1999). The Longman grammar of spoken and written English, Longman, London, England. (In English)
Biber, D. (1989). A typology of English texts, Linguistics, 27, 3–43. (In English)
Crossley, S. A. et al. (2007). Toward a new readability: A mixed model approach in McNamara, D. S. Trafton, G. (eds.) Proceedings of the 29th annual conference of the Cognitive Science Society; Austin, TX: Cognitive Science Society, 197–202. (In English)
DuBay, W. H. (2007). The Classic Readability Studies. Costa Mesa. 240 р. URL: https://files.eric.ed.gov/fulltext/ED506404.pdf (Accessed 21 July 2024) (In English)
Eggins, S. (2004). An introduction to systemic functional linguistics, London, UK. (In English)
Fang, Z., Schleppegrell, M. J. and Cox, B. E. (2006). Understanding the Language Demands of Schooling: Nouns in Academic Registers, Journal of Literacy Research, 38 (3), 247–273. https://doi.org/10.1207/s15548430jlr3803_1(In English)
Flesch, R. (1948). A new readability yardstick, Journal of Applied Psychology, 32, 221–233. (In English)
Gatiyatullina, G., Solnyshkina, M., Solovyev, V., Danilov, A., Martynova, E. and Yarmakeev, I. (2020). Computing Russian Morphological distribution patterns using RusAC Online Server, 13th International Conference on Developments in eSystems Engineering (DeSE), Liverpool, UK, 393–398. DOI: 10.1109/DeSE51703.2020.9450753 (In English)
Halliday, M. A. K. and Martin, J. R. (eds.) (2003). Writing Science: Literacy and Discursive Power, Falmer Press, London, UK. (In English)
Just, M. A., Carpenter, P. A. (1987). The psychology of reading and language comprehension, Allyn and Bacon, Boston, London. (In English)
Kincaid, J. P., Fishburne, R. P., Rogers, R. L. and Chissom, B. S. (1975). Derivation of new readability formulas (Automated Readability Index, Fog Count, and Fesch Reading Ease Formula) for Navy enlisted personnel, Research Branch Report, 8–75. (In English)
Koda, K. (2005). Insights into second language reading: A cross-linguistic approach, Cambridge University Press, Cambridge, UK. (In English)
Martin, J. R. (1991). Nominalization in science and humanities: Distilling knowledge and scaffolding, Functional and systemic linguistics: Approaches and Uses, De Gruyter Mouton, Berlin, New York, 307–338. https://doi.org/10.1515/9783110883527.307(In English)
McLaughlin, G. H. (1969). SMOG Grading – A new readability formula, Journal of Reading, 12(8), 639–646. (In English)
Solnyshkina, M., Ivanov, V., Solovyev, V. (2018). Readability formula for Russian texts: A modified version in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 132-145. DOI: 10.1007/978-3-030-04497-8_11 (In English)
Solnyshkina, M. I., Kiselnikov, A. S. (2015). Text complexity: Study phases in Russian linguistics, Vestnik Tomskogo Gosudarstvennogo Universiteta, Filologiya, 38 (6), 86-99. DOI: 10.17223/19986645/38/7 (In English)
To, V., Fan, S., Thomas, D. P. (2013). Lexical density and readability: A case study of English textbooks. The International Journal of Language, Society and Culture, 37(7), 61–71. (In English)
Vahrusheva, A., Solovyev, V., Solnyshkina, M., Gafiaytova, E., Akhtyamova, S. (2023). Revisiting Assessment of Text Complexity: Lexical and Syntactic Parameters Fluctuations, in Karpov, A., Samudravijaya, K., Deepak, K. T., Hegde, R. M., Agrawal, S. S., Prasanna, S. R. M. (eds) Speech and Computer. SPECOM 2023. Lecture Notes in Computer Science, Vol 14338, Springer, Cham, Switzerland. https://doi.org/10.1007/978-3-031-48309-7_35(In English)
Corpus Materials
Vinogradova, N. F., Gorodetskaya, N. I., Ivanova, L. F. et al. (2012) Obshchestvoznaniye. 6 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 6th grade: textbook for general educational institutions], in Bogolyubov, L. N., Ivanova, L. F. (eds.), Prosvescheniye, Moscow, Russia. (In Russian)
Vinogradova, N. F., Gorodetskaya, N. I., Ivanova, L. F. et al. (2013) Obshchestvoznaniye. 7 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 7th grade: textbook for general educational institutions], in Bogolyubov, L. N., Ivanova, L. F. (eds.), Prosvescheniye, Moscow, Russia. (In Russian)
Bogolyubov, L. N., Gorodetskaya, N. I. (2010) Obshchestvoznaniye. 8 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 8th grade: textbook for general educational institutions], Prosvescheniye, Moscow, Russia. (In Russian)
Bogolyubov, L. N. (2014) Obshchestvoznaniye. 9 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 9th grade: textbook for general educational Institutions], Prosvescheniye, Moscow, Russia. (In Russian)
Bogolyubov, L. N. (2014) Obshchestvoznaniye. 10 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 10th grade: textbook for general educational institutions: general level], in L. N. Bogolyubov, Yu. A. Averyanov, A. V. Belyavsky (eds.), Prosvescheniye, Moscow, Russia. (In Russian)
Bogolyubov, L. N. (2014) Obshchestvoznaniye. 10 klass: uchebnik dlya obshcheobrazovatelnykh organizatsiy: profilnyy uroven [Social science. 10th grade: textbook for general education organizations: advanced level], in Bogolyubov, L. N., Lazebnikova, A. Yu., Smirnov, N. M. (eds.), 8th ed., Prosvescheniye, Moscow, Russia. (In Russian)
Bogolyubov, L. N. (2010) Obshchestvoznaniye. 11 klass: uchebnik dlya obshcheobrazovatelnykh organizatsiy: profilnyy uroven [Social science. 11th grade: textbook for students of general education institutions: profile level], in Bogolyubov, L. N., Lazebnikova, A. Yu., Kholodkovsky, K. G. (eds.), 3rd ed., Prosvescheniye, Moscow, Russia. (In Russian)
Nikitin, A. F. (2011) Obshchestvoznaniye. 6 klass: ucheb, dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 6th grade: textbook for educational institutions], 4th ed., Drofa, Moscow, Russia. (In Russian)
Nikitin, A. F. (2014) Obshchestvoznaniye. 7 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 7th grade: textbook], 6th ed., Drofa, Moscow, Russia. (In Russian)
Nikitin, A. F. (2014) Obshchestvoznaniye. 8 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 8th grade. Textbook], Drofa, Moscow, Russia. (In Russian)
Nikitin, A. F. (2014) Obshchestvoznaniye. 9 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 9th grade. Textbook], Drofa, Moscow, Russia. (In Russian)
Nikitin, A. F. (2014) Obshchestvoznaniye. 10 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. 10th grade: textbook for general education organizations: general level], 10th ed., Drofa, Moscow, Russia. (In Russian)
Nikitin, A. F. (2013) Obshchestvoznaniye. 11 klass: ucheb. dlya obshcheobrazovatelnykh uchrezhdeniy [Social science. Grade 11: textbook for general education organizations: general level], 6th ed., Drofa, Moscow, Russia. (In Russian)
Sukhorukova, L. N., Kuchmenko, V. S., Kolesnikova, I. Ya. (2014) Biologiya. Zhivoy organizm. 5-6 klassy: ucheb. dlya obshcheobrazovat. organizatsiy [Biology. Living organism. Grades 5-6: textbook for general educational institutions], 3rd ed., Prosvescheniye, Moscow, Russia. (In Russian)
Sukhorukova, L. N., Kuchmenko, V. S., Kolesnikova, I. Ya. (2014) Biologiya. Raznoobraziye zhivykh organizmov. 7 klass: ucheb. dlya obshcheobrazovat. organizatsiy [Biology. Diversity of living organisms. 7th grade: educational. for general education organizations], Prosvescheniye, Moscow, Russia. (In Russian)
Sukhorukova, L. N., Kuchmenko, V. S., Tsekhmistrenko, T. A. (2009) Biologiya. Chelovek. Kultura zdorovya: ucheb. dlya 8 kl. obshcheobrazovat. uchrezhdeniy [Biology. Human. Culture of health. 8th grade: textbook for general educational institutions], Prosvescheniye, Moscow, Russia. (In Russian)
Sukhorukova, L. N., Kuchmenko, V. S. (2010) Biologiya. Zhivyye sistemy i ekosistemy. 9 klass: ucheb. dlya obshcheobrazovat. uchrezhdeniy [Biology. Living systems and ecosystems. 9th grade: textbook for general educational institutions], Prosvescheniye, Moscow, Russia. (In Russian)
Sukhorukova, L. N., Kuchmenko, V. S., Ivanova, T. V. (2011) Biologiya. 10-11 klassy: ucheb. dlya obshcheobrazovat. uchrezhdeniy [Biology. Grades 10-11: textbook for general educational institutions], Prosvescheniye, Moscow, Russia. (In Russian)
Pasechnik, V. V. (ed.) (2011) Biologiya. Bakterii, griby, rasteniya. 6 kl.: ucheb. dlya obshcheobrazovat. uchrezhdeniy [Biology. Bacteria, fungi, plants. 6th grade: textbook for general educational institutions], 14th ed., Drofa, Moscow, Russia. (In Russian)
Pasechnik, V. V., Sumatokhin, S. V., Kalinova, S. G. (2014) Biologiya. 7 klass: ucheb. dlya obshcheobrazovat. organizatsiy [Biology. 7th grade: textbook for general educational institutions], 3rd ed., Prosvescheniye, Moscow, Russia. (In Russian)
Pasechnik, V. V., Kamensky, A. A., Shvetsov, G. G. (2010) Biologiya. 8 klass: ucheb. dlya obshcheobrazovat. organizatsiy [Biology. 8th grade: textbook for general educational institutions], Prosvescheniye, Moscow, Russia. (In Russian)
Kamensky, A. A., Kriskunov, E. A., Pasechnik, V. V. (2002) Biologiya. Vvedeniye v obshchuyu biologiyu i ekologiyu: Ucheb. dlya 9 kl. obshcheobrazovat. ucheb. zavedeniy [Biology. Introduction to general biology and ecology: 9th grade: textbook for general educational institutions], 3rd ed., Drofa, Moscow, Russia. (In Russian)
Kamensky, A. A., Kriskunov, E. A., Pasechnik, V. V. (2005) Obshchaya biologiya. 10-11 klass: ucheb. dlya obshcheobrazovat. uchrezhdeniy [General biology. 10-11 grade: textbook for general educational institutions], Drofa, Moscow, Russia. (InRussian)
The research was supported by the RSF grant 24-28-01355 “Genre-discourse characteristics of the text as a function of lexical range”.