
Cultural code in academic discourse: corpus and parametric approaches
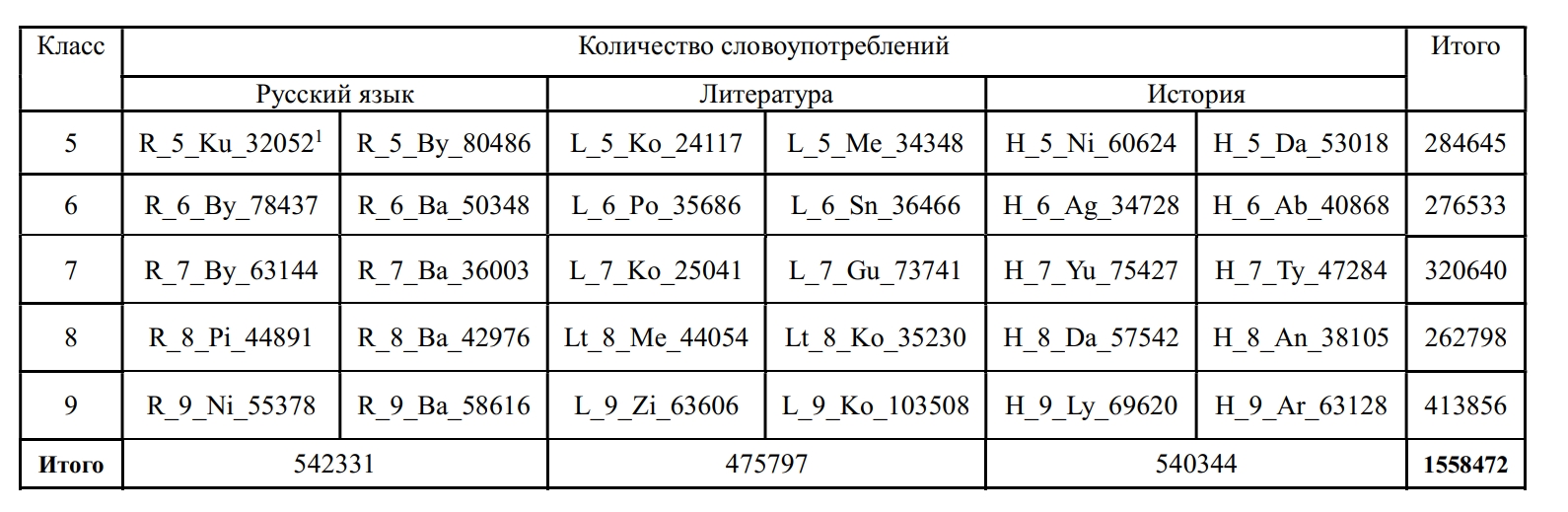
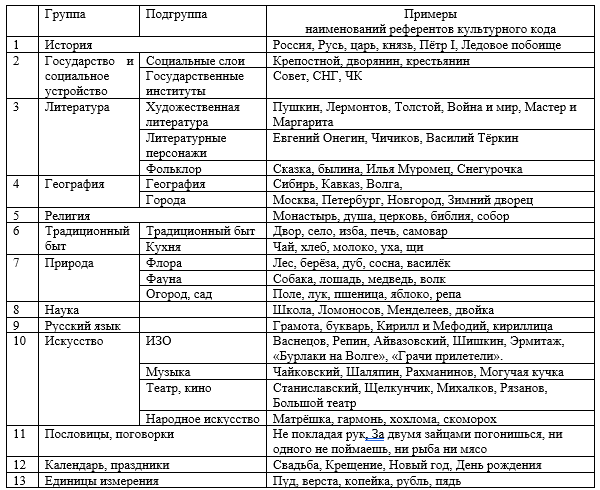
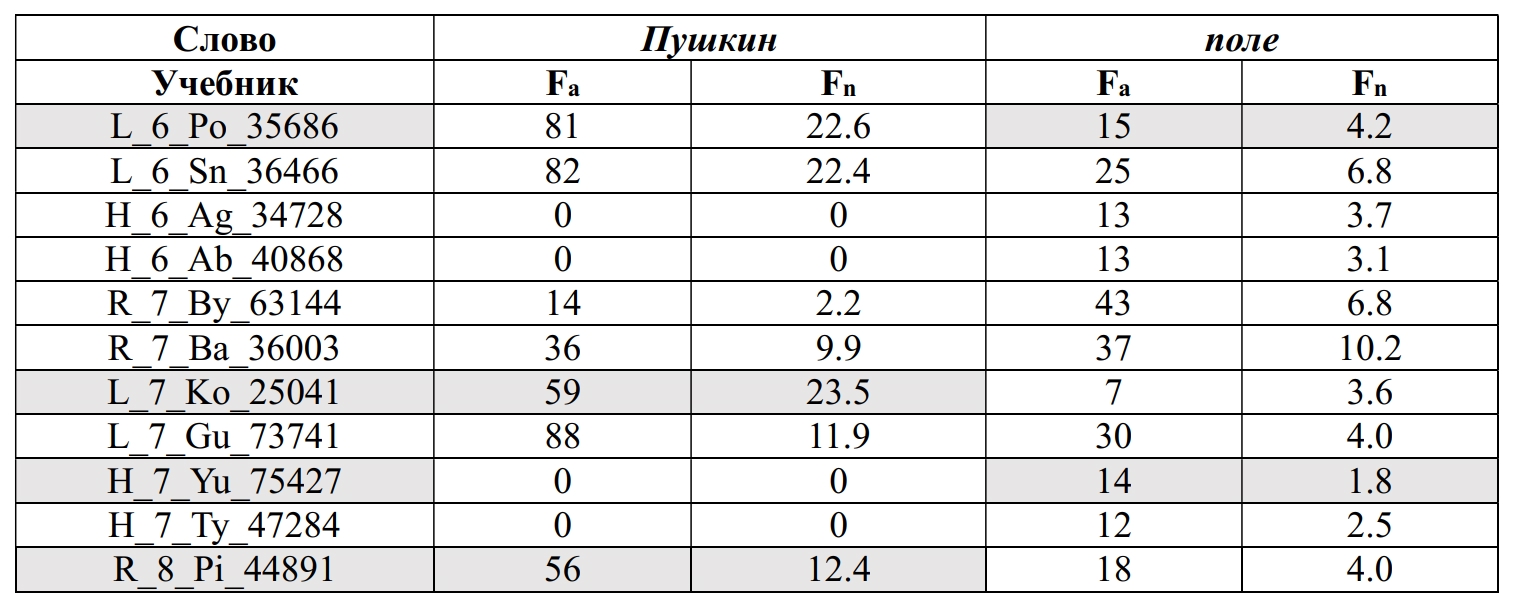
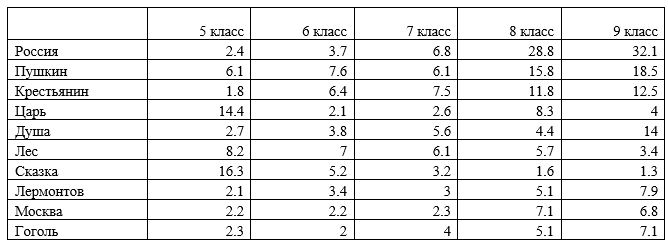
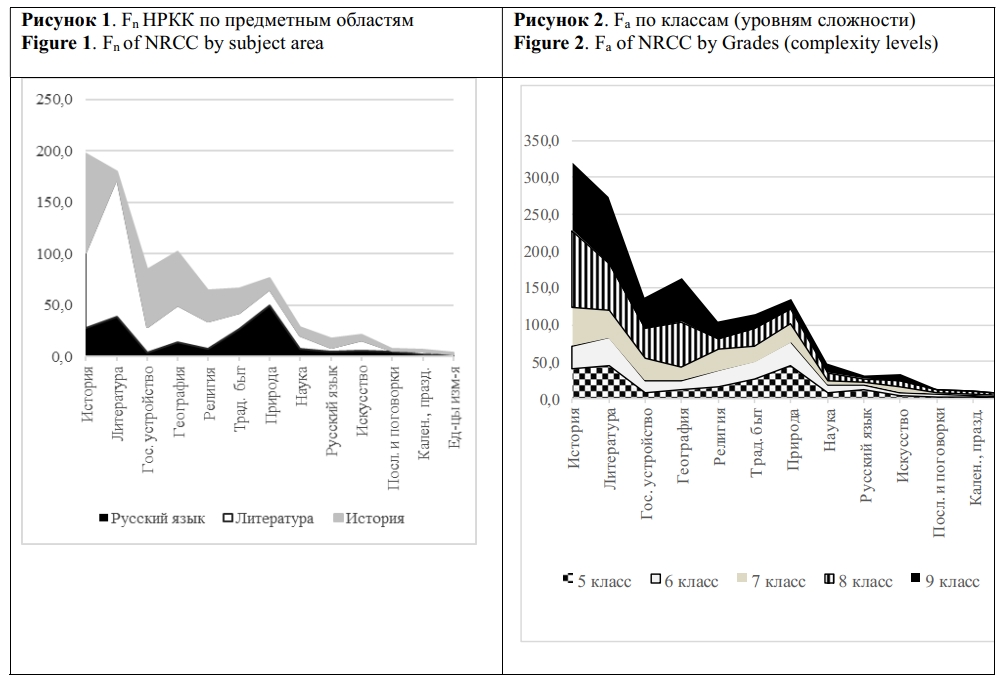
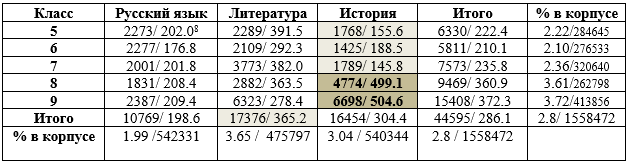
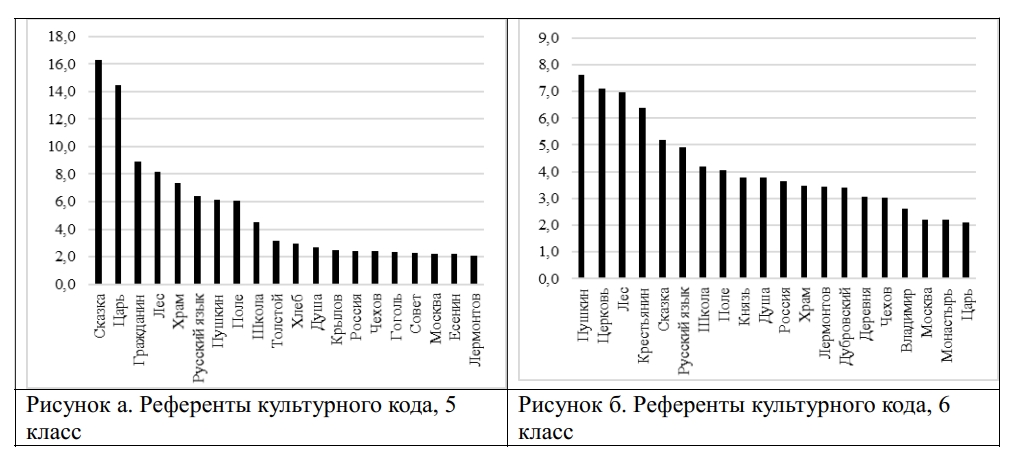
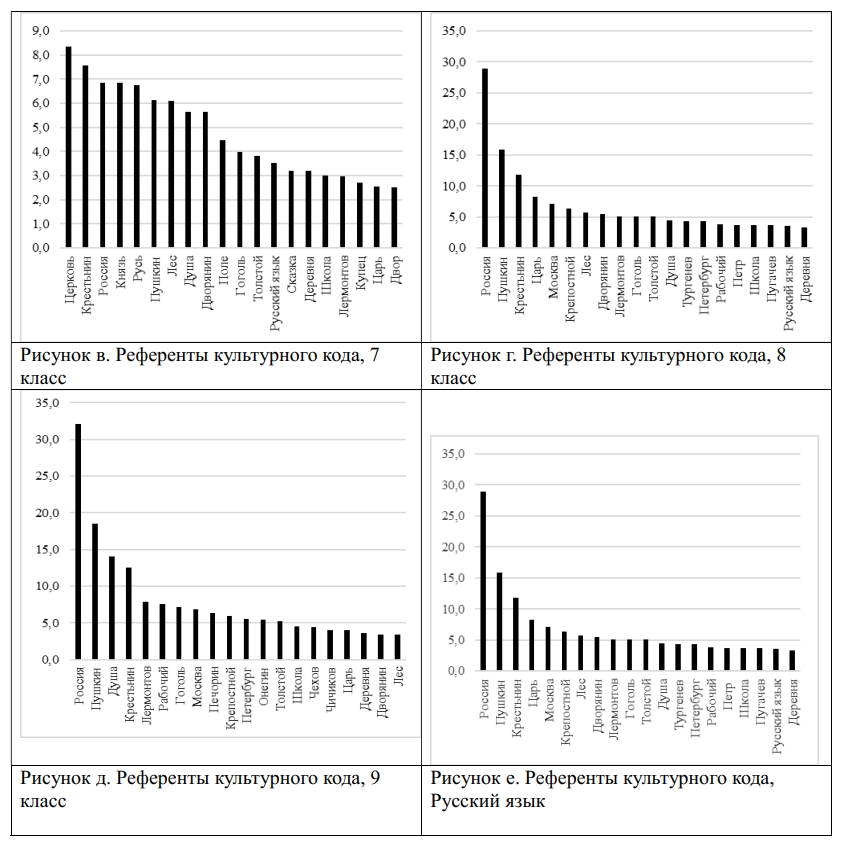
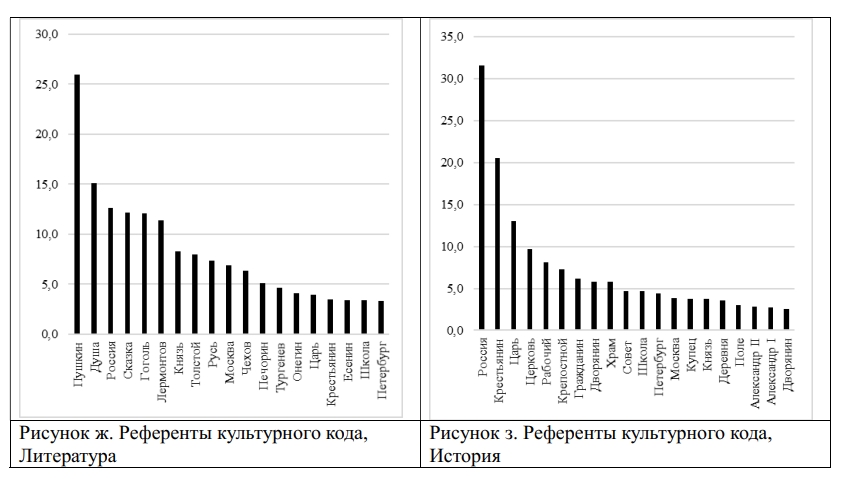
The study presents a corpus and parametric analysis of 785 nominations of Russian cultural code referents in academic discourse. The dataset amounting 1.5 mln. tokens comprises a collection of 30 textbooks used in the 5th - 9th grades of general secondary schools in Russia to teach Russian, Literature and History. The nominations of cultural code referents were sourced from validated linguistic, cultural and sociological studies, and were classified into thirteen thematic groups, including: History, State and Social Structures, Literature, Geography, Religion, Traditional Life, Nature, Science, Russian Language, Art, Proverbs and Sayings, Calendar and Holidays, Units of Measurement. The research revealed systematicity and thematic homogeneity of the cultural code nominations employed in the textbooks: the most representative in each of the grade collections are the following thematic groups: "History", "Art", "Literature" and "Geography (space)". The share of nominations of Russian cultural code referents in textbooks varies from 1.8% to 5.04% (in tokens): the smallest number of instances is registered in the textbooks of Russian, the highest – in Literature textbooks. The frequency of Russian cultural code referents nomination increases across grades predominantly due to the growth in groups "History", "Literature", and "State structures". The revealed empirical data and ranges of the NRCC frequency can be used to improve algorithms for automated assessment of the language of educational texts and modeling linguistic worldview in texts of various genres.
Figures

Dontsov, M. A., Solnyshkina, M. I., Shelestova, O. V. (2025). Cultural code in academic discourse: corpus and parametric approaches, Research Result. Theoretical and Applied Linguistics, 11 (3), 63–84.












While nobody left any comments to this publication.
You can be first.
Andreeva, M. I., Solnyshkina, M. I. and Mufazalova, N. I. (2024). Nominations of Referents of the Russian Cultural Code as a Predictor of Text Complexity in Russian as a Foreign Language, Vzaimodeystvie nauki i obshchestva: yazyk, innovatsii, kultura: sbornik nauchnykh trudov Mezhdunarodnogo foruma [Interaction of Science and Society: language, innovation, culture: proceedings of the International Forum], Almaty, Kazakhstan, October 14–16, 2024, in Begalieva, S. B. (ed.), Compiled by Isalieva, S. T., KazNU named after al-Farabi, Almaty, Kazakhstan, 119-124. (In Russian)
Batyrshin, R. I. (2025). Cultural Code of War as a Culturological Phenomenon, Obshchestvo: filosofiya, istoriya, kultura, 3, 187–193. https://doi.org/10.24158/fik.2025.3.26. (In Russian)
Velilaeva, L. R. and Abdulzhemileva, F. I. (2021). Cultural Code in Fiction, Mir nauki, kultury, obrazovaniya, 6 (91), 527–529. (In Russian)
Galimullina, A. F. and Galimullin, F. G. (2022). National and Cultural Codes in the Works of Modern Tatar Poets, Byulleten Kalmytskogo nauchnogo tsentra RAN, 1, 174–190. DOI: 10.22162/2587-6503-2022-1-21-174-190 (In Russian)
Gudkov, D. B. and Kovshova, M. L. (2007). Telesnyy kod russkoy kultury: materialy k slovaryu [Bodily Code of Russian Culture: Materials for a Dictionary], Gnozis, Moscow, Russia. (In Russian)
Duktova, L. G. (2023). Representation of Cultural Meanings Through National Cultural Codes in Fiction, Litera, 12, 361–371. (In Russian)
NAFI Analytical Center (n.d.). Pushkin, sila voli i bogatyri: chto sostavlyaet kulturnyy kod rossiyan [Pushkin, Willpower and Bogatyrs: What Constitutes the Cultural Code of Russians] [Online], available at: https://nafi.ru/analytics/pushkin-sila-voli-i-bogatyri-chto-sostavlyaet-kulturnyy-kod-rossiyan/ (accessed 22.06.2025). (In Russian)
Karasik, V. I. (2013). Yazykovaya matritsa kultury [Linguistic Matrix of Culture], Gnozis, Moscow, Russia. (In Russian)
Kovshova, M. L. (2016). Lingvokulturologicheskiy metod vo frazeologii: kody kultury [Linguocultural Method in Phraseology: Codes of Culture], 3rd ed., LENAND, Moscow, Russia. (In Russian)
Krasnykh, V. V. (2002). Etnopsikholingvistika i lingvokulturologiya [Ethnopsycholinguistics and Linguoculturology], Gnozis, Moscow, Russia. (In Russian)
Laposhina, A. N., Veselovskaya, T. S., Lebedeva, M. Yu., Kupreshchenko, O. F. (2019). Lexical composition of texts in Russian language textbooks for primary school: a corpus study, Kompiuternaia lingvistika i intellektualnye tekhnologii: po materialam mezhdunarodnoi konferentsii «Dialog 2019» [Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2019”], 18 (25), 351–363. (In Russian)
Lapteva, L. E. (2024). Kulturnyy kod Rossii v istoriko-pravovykh issledovaniyakh [Cultural Code of Russia in Historical and Legal Research], Vestnik Universiteta imeni O.E. Kutafina (MGYuA) [Kutafin University Law Review (MSAL)], 1 (12), 145–153. https://doi.org/10.17803/2311-5998.2024.124.12.145-153 (In Russian)
Lyubavin, M. N. (2002). Archetypal Matrix of Russian Culture, Abstract of Ph.D. dissertation, Culturology, Nizhny Novgorod, Russia. (In Russian)
Maksimchuk, N. A. (2024). Proper Name in Regulatory-Scientific Text, Neofilologiya, 10 (4), 838–850. https://doi.org/10.20310/2587-6953-2024-10-4-838-850. (In Russian)
Maslova, V. A. (2001). Lingvokulturologiya [Linguoculturology], Akademiya, Moscow, Russia. (In Russian)
Nebera, M. V. and Sherina, E. A. (2024). Reflection of Russian Cultural Values in Foreign Textbooks on the Russian Language, Kazanskaya nauka, 5, 245–247. (In Russian)
Nikolaychuk, I. A., Yakova, T. S., Yanglyaeva, M. M. (2024). Media-Geographic Research of Mental Landscapes of the North Caucasus Region of the Russian Federation in the Context of the Escalation of the Palestinian-Israeli Conflict, Diskurs-Pi, 21 (4), 152–176. DOI:10.17506/18179568_2024_21_4_152. (In Russian)
Nikolaychuk, I. A., Yakova, T. S., Yanglyaeva, M. M. (2023). Cultural Codes in Modern Public Space: Metameanings and Their Consumption in Russia and Abroad, Vestnik MGPU. Seriya: Filosofskiye nauki, 1 (45), 48–67. (In Russian)
Oxenchuk, A. Ye. (2013). Specifics of Academic Educational Text: Main Approaches to the Concept of “Educational Text”, Materialy XVIII konferentsii prepodavateley, nauchnykh sotrudnikov i aspirantov [Science for Education, Industry, Economics: Proceedings of the 18th Conference of Teachers, Researchers and Postgraduates], Vitebsk, Belarus, 13–14 March 2013, Vol. 2, Vitebskiy gosudarstvennyy universitet im. P. M. Masherova [Vitebsk State University named after P. M. Masherov], Vitebsk, Belarus, 277–279. (In Russian)
Pimenova, M. V. (2007). Cultural Codes and the Problem of Concept Classification, Yazyk. Tekst. Diskurs, 5, 79–86. (In Russian)
Privalova, I. V. (2004). Towards Defining the Concept of “Linguistic Markers of National-Cultural Consciousness”, Yazyk, soznaniye, kommunikatsiya, Vol. 26, MAKS Press, Moscow, Russia, 91–97. (In Russian)
Savitsky, V. M. and Gashimov, E. A. (2005). Lingvokulturnyy kod (sostav i funktsionirovaniye) [Linguocultural Code (Structure and Functioning)], Moskovskiy gorodskoy pedagogicheskiy universitet, Moscow, Russia. (In Russian)
Simbirtseva, N. A. (2016). “Culture Code” as a Culturological Category, Znaniye. Ponimaniye. Umeniye, 1, 157–167. (In Russian)
Starostin, A. M. (2017). Intangible Heritage of Russia in the Context of the Cultural Code of Civilization Concept, Zhurnal instituta naslediya, 1 (8), 1. (In Russian)
Stetsenko, V. V. (2024). Value Transformation of Russian Society in Modern Conditions: Dynamics, Challenges, Development Prospects, Gosudarstvennoye i munitsipalnoye upravleniye. Uchenyye zapiski, 4, 208–214. https://doi.org/10.22394/2079-1690-2024-1-4-208-214(In Russian)
Teliya, V. N. (1996). Russkaya frazeologiya: Semanticheskiy, pragmaticheskiy i lingvokulturologicheskiy aspekty [Russian Phraseology: Semantic, Pragmatic and Linguocultural Aspects], Nauka, Moscow, Russia. (In Russian)
Teliya, V. N. (1999). Pervoocherednyye zadachi i metodologicheskiye problemy issledovaniya frazeologicheskogo sostava yazyka v kontekste kultury [Primary Tasks and Methodological Problems of Studying the Phraseological Composition of Language in the Context of Culture], Teliya, V. N. (ed.), Frazeologiya v kontekste kultury [Phraseology in the Context of Culture], Yazyki russkoy kultury, Moscow, Russia, 336. (In Russian)
Terskikh, M. V., Zaytseva, O. A. (2024). Lexical Means of Reflecting the Russian Mentality in Textbooks of Russian as a Foreign Language, Vestnik slavyanskikh kultur, 71, 208–224. https://doi.org/10.37816/2073-9567-2024-71-208-224(In Russian)
Tishin, V. V. (2019). Once Again on the Content of the Term “Horde” and the Categories “Golden Horde”, “White Horde”, “Blue Horde”, Zolotoordynskoye obozreniye, 7 (2), 295–317. DOI: 10.22378/2313-6197.2019-7-2.295-317 (In Russian)
Tolstaya, S. M. (2007). K ponyatiyu kulturnykh kodov [On the Concept of Cultural Codes], Sbornik statey k 60-letiyu A. K. Bayburina [Festschrift for the 60th Anniversary of A. K. Bayburin], Izd-vo Evropeyskogo universiteta v Sankt-Peterburge, St. Petersburg, Russia, 23–31. (In Russian)
Tolstoy, N. I. (1995). Yazyk i narodnaya kultura. Ocherki po slavyanskoy mifologii i etnolingvistike [Language and Folk Culture. Essays on Slavic Mythology and Ethnolinguistics], Indrik, Moscow, Russia. (In Russian)
Trubina, N. A. and Mirkushina, L. R. (2022). Transformation of Moral Values in Digital Communication, Vestnik MGPU. Seriya «Filosofskiye nauki», 3 (43), 44–56. DOI: 10.25688/2078-9238.2022.43.3.4. (In Russian)
Foucault, M. (1977). Slova i veshchi. Arkheologiya gumanitarnykh nauk [Words and Things: An Archaeology of the Human Sciences], Translated by V. P. Vizgin and N. S. Avtonomova, Progress, Moscow, Russia. (In Russian)
Khudoley, N. V. (2014). Cultural Literary Code of the Modern Russian Reader, Vestnik Kemerovskogo gosudarstvennogo universiteta kultury i iskusstv, 29–1, 155–164. (In Russian)
Tsatsanovskaya, R., Transformation of Values in the Modern World, Nauchnyy rezultat. Sotsiologiya i upravleniye, 7 (3), 4–8. DOI: 10.18413/2408-9338-2021-7-3-0-1. (In Russian)
Rapaille, C. (2006). The Culture Code, Broadway Books, New York, NY, 10–11, 22. (In English)
D’Andrade, R. G. (1984). Cultural Meaning Systems, In Shweder, R. A. and LeVine, R. A. (ed.), Cultural Theory. Essays on Mind, Self and Emotion, Cambridge University Press, Cambridge, UK; L., N.Y., New Rochelle, Melbourne, Sydney, Australia, 88–115. (In English)
Gries, S. T. (2011). Methodological and interdisciplinary stance in corpus linguistics, in Barnbrook, G., Viana, V. and Zyngier, S. (eds.), Perspectives on corpus linguistics: Connections and controversies, John Benjamins, Amsterdam, Netherlands, 81–98. (In English)
Hyatt, J. and Simons, H. (1999). "Cultural Codes – Who Holds the Key? The Concept and Conduct of Evaluation in Central and Eastern Europe", Evaluation, 5 (1), 23–41. DOI: 10.1177/13563899922208805. (In English)
CorpusMatereial
Aristova, M. A., Belyaeva, N. V., Kritarova, Zh. N. (ed.) (2022). Rodnaya literatura (russkaya). Realizatsiya FGOS osnovnogo obshchego obrazovaniya: metodicheskoye posobiye dlya uchitelya [Native Literature (Russian). Implementation of the Federal State Educational Standard for Basic General Education: A Teacher’s Guide], “Institut strategii razvitiya obrazovaniya RAO”, Moscow, Russia. (InRussian)
Dobrokhotov, A. L. (2001). Simvol “Symbol”, Novaya filosofskaya entsiklopediya: v 4 t. [New Philosophical Encyclopedia: In 4 Vol.], Vol. 3, Mysl, Moscow, Russia, 532–534. (In Russian)
Kulturnyye kody: Uchebno-metodicheskoye posobiye [Cultural Codes: Teaching Aid] (2023), MGPU; Knigodel, Moscow, Russia. (InRussian)
Lyashevskaya O. N., Sharoff S. A. Chastotnyy slovar’ sovremennogo russkogo yazyka: na materialakh Natsional’nogo korpusa russkogo yazyka [Frequency dictionary of the modern Russian language: based on the materials of the National Corpus of the Russian language]. Russian Academy of Sciences, V. V. Vinogradov Institute of Russian Language. Moscow: Azbukovnik, 2015. 1087 p. (In Russian)
Prokhorov, Yu. E. (ed.) (2007). Rossiya. Bolshoy lingvostranovedcheskiy slovar [Russia. Big Linguocultural Dictionary], AST-PRESS KNIGA, Moscow, Russia. (In Russian)
Strategiya gosudarstvennoy natsionalnoy politiki Rossiyskoy Federatsii na period do 2025 goda: itogi realizatsii i novyye vyzovy. Materialy «kruglogo stola». 29 marta 2018 goda [Strategy of the State National Policy of the Russian Federation for the Period up to 2025: Implementation Results and New Challenges. Materials of the “Round Table”, March 29, 2018] (2019), Izdaniye Gosudarstvennoy Dumy, Moscow, Russia. (In Russian)
Bayrasheva, E. R., Gatiyatullina, G. M., Gafiyatova, E. V. et al. (2020). Uchebnyy korpus russkogo yazyka [Educational Corpus of the Russian Language] [Online], Certificate of state registration of database No. 2020622254, filed 02.11.2020, published 12.11.2020, applicant: Federal State Autonomous Educational Institution of Higher Education “Kazan (Volga Region) Federal University” (FSAEI HE KFU). (In Russian)
Ministry of Education of the Russian Federation (n.d.). Federalnyy perechen uchebnikov [Federal List of Textbooks] [Online], available at: https://fpu.edu.ru/ (accessed 20.07.2025). (In Russian)
The research was supported by the RSF grant 24-28-01355 "Genre-discourse characteristics of the text as a function of lexical range".