
Школьный учебный текст в аспекте терминоупотребления: корпусный анализ
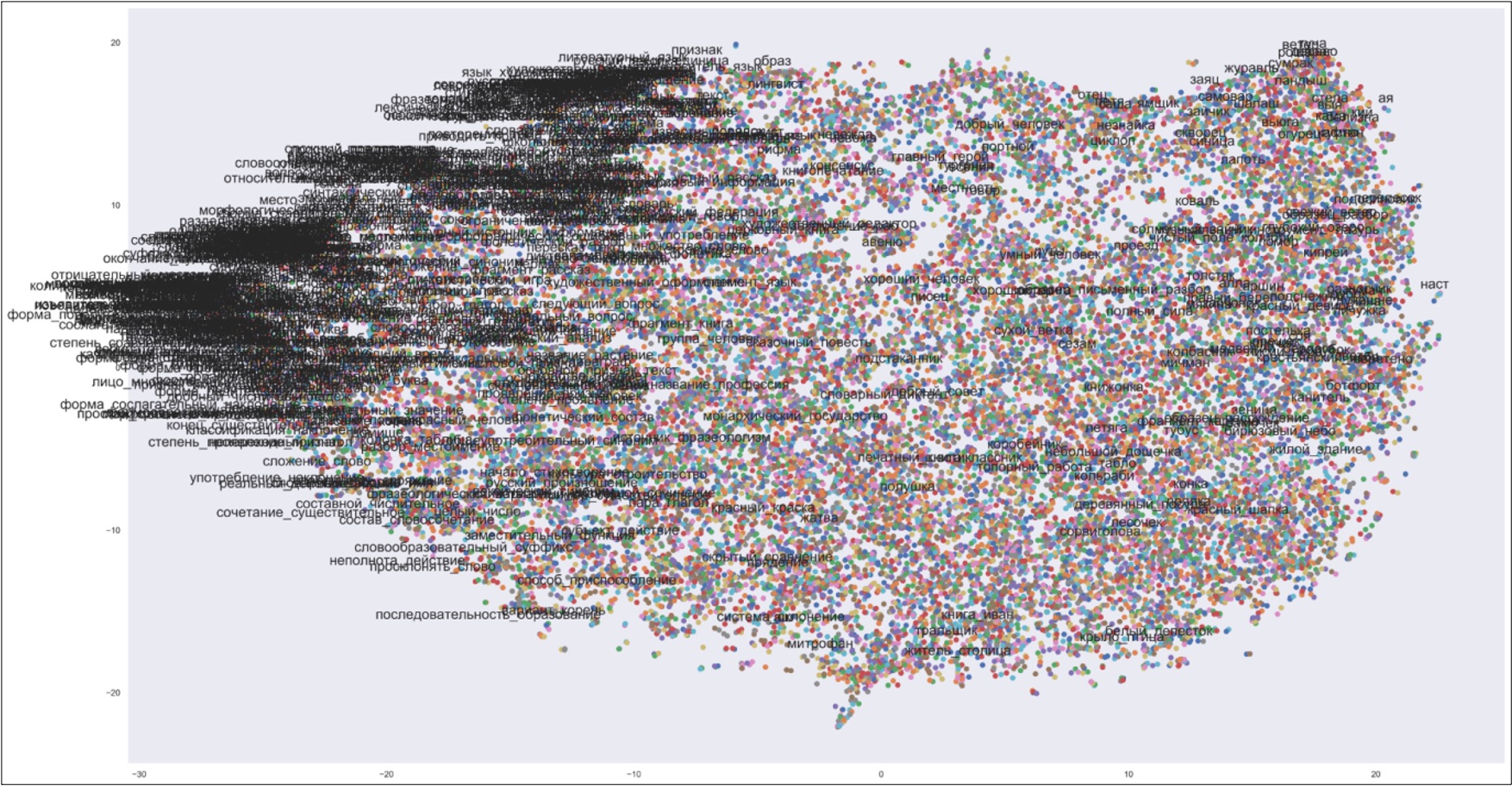
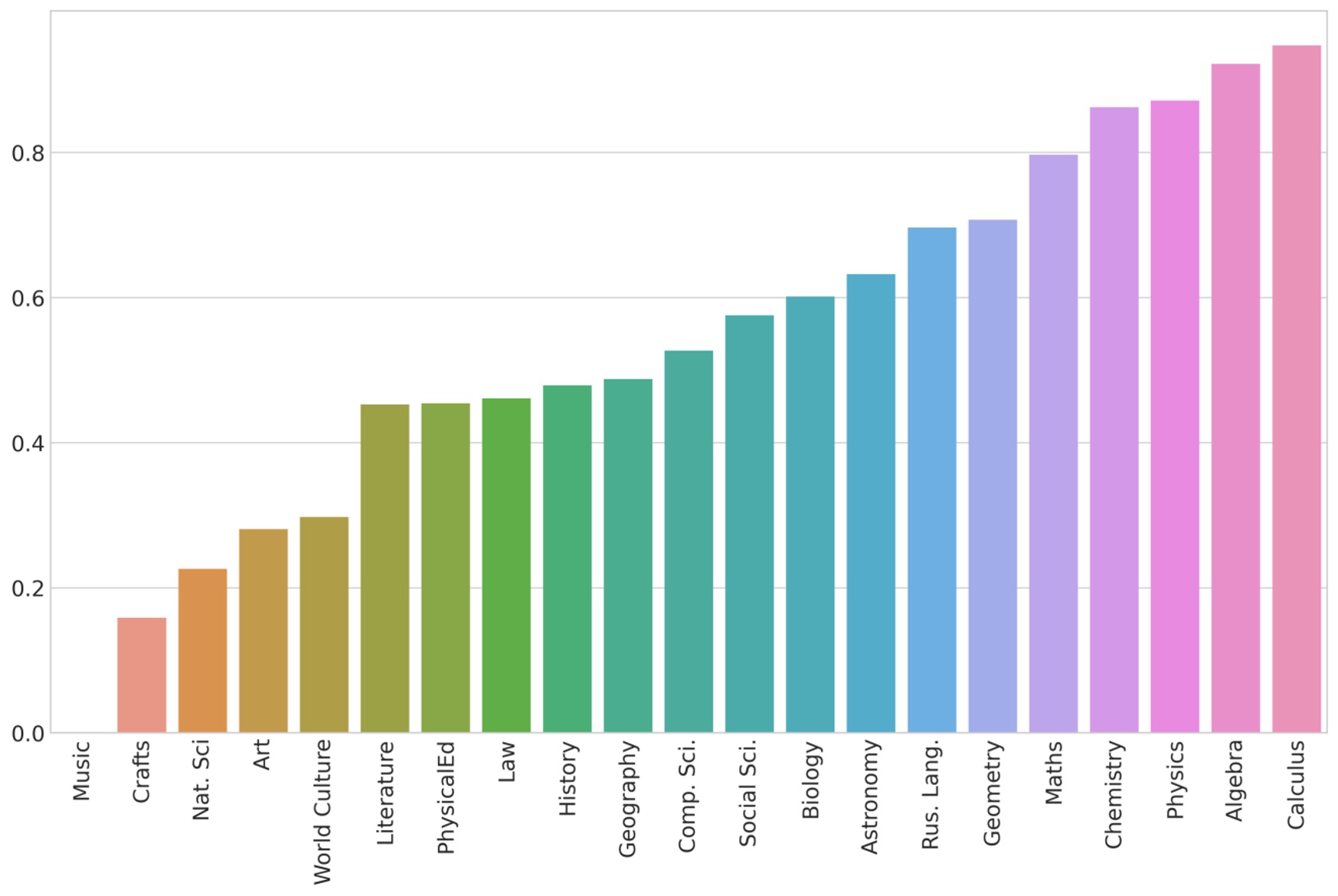
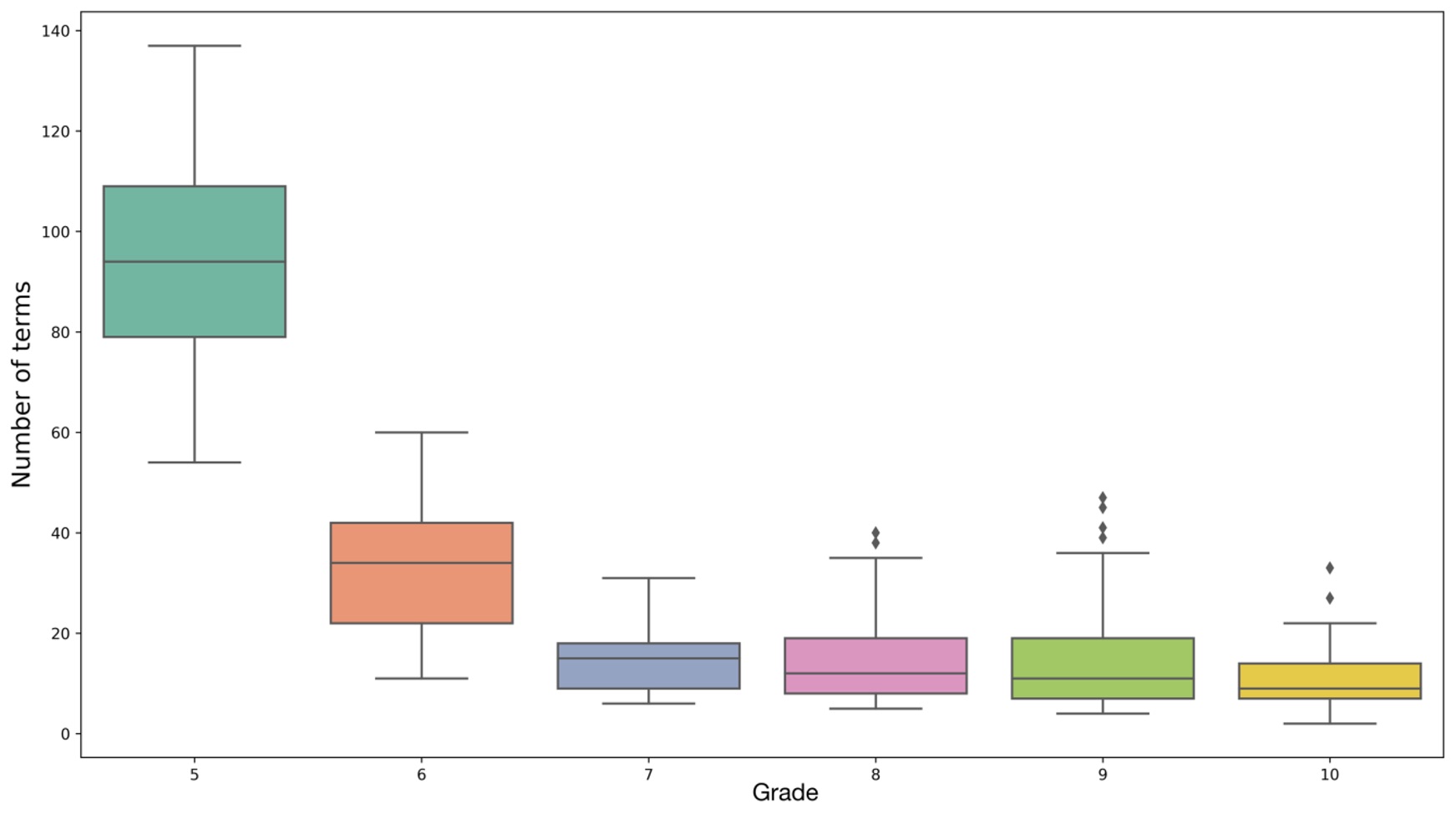
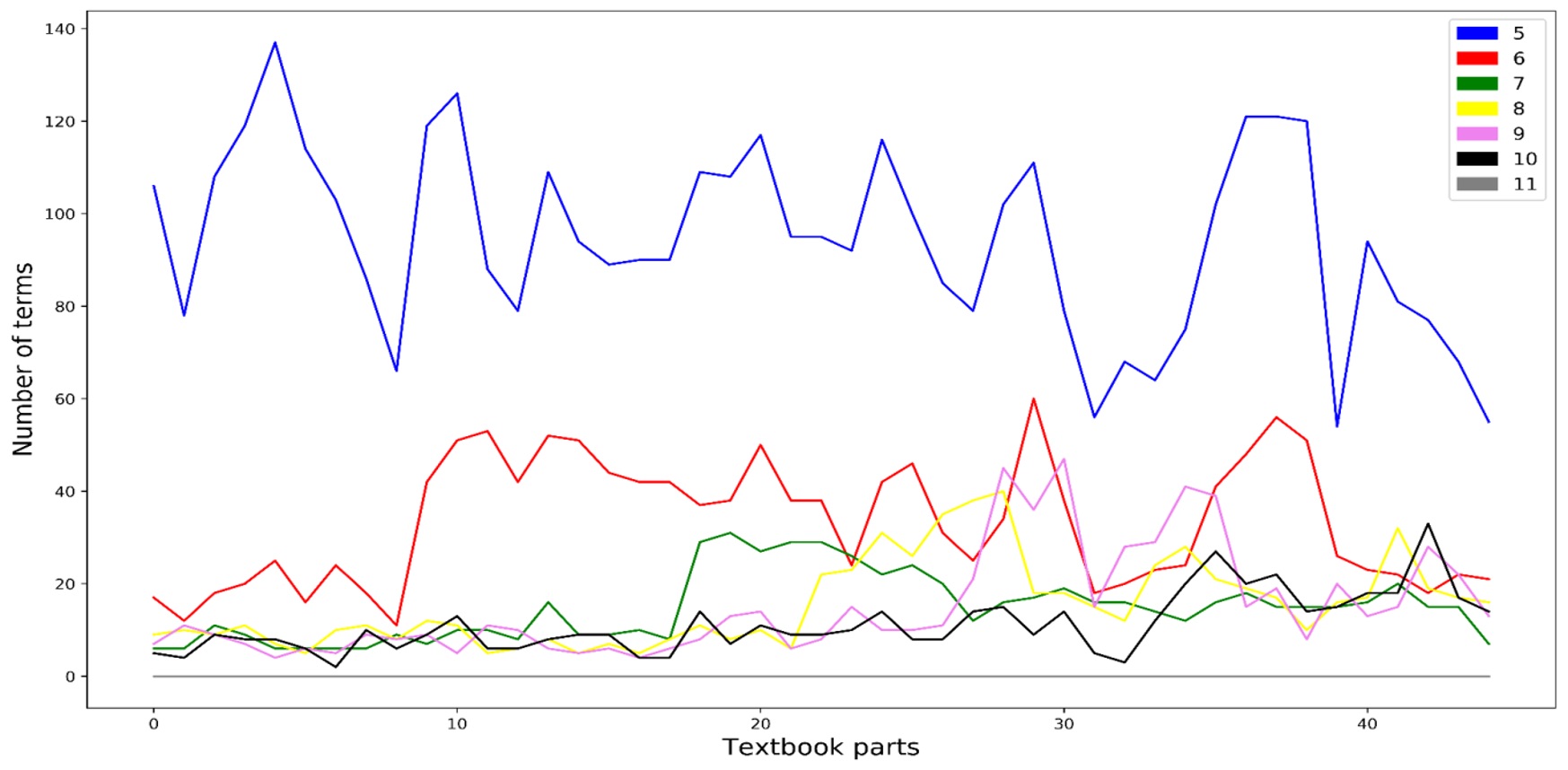
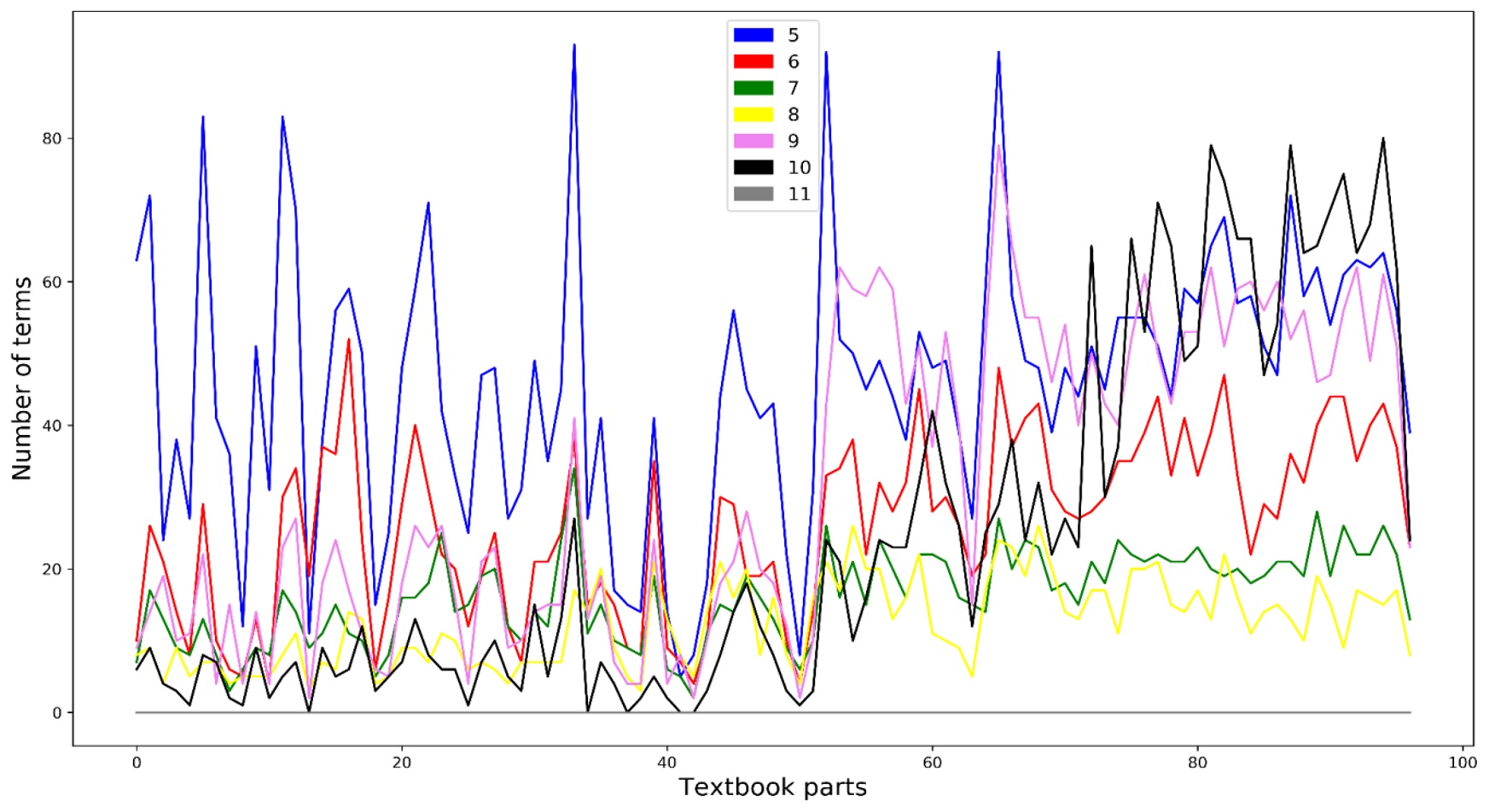
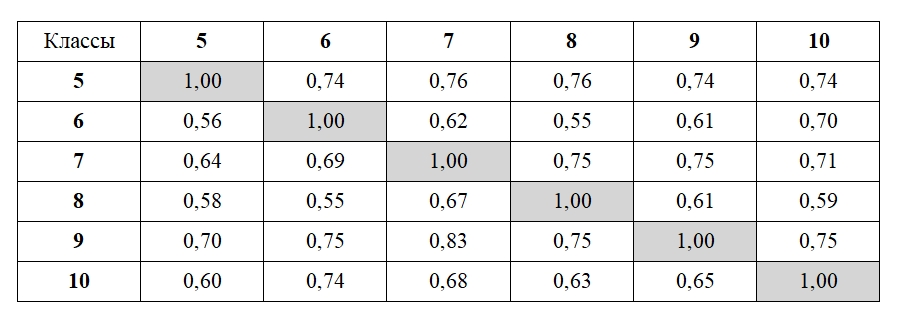
В статье излагаются методы и результаты анализа употребления терминологической лексики в современных школьных учебниках на русском языке. Основным материалом исследования является созданный исследовательский корпус, включающий тексты 207 учебников с 5-го по 11-й класс по 21 школьной дисциплине. Традиционный способ автоматического извлечения терминов, основанный на статистических показателях частотности словоупотребления, предлагается усовершенствовать с помощью создания моделей, обученных по алгоритмам Word2Vec, в основе которых лежат идеи дистрибутивной семантики. Применение этих алгоритмов, выражающее в числовом представлении сочетаемостное поведение слов и соответственно степень их семантической близости, позволило: в существенной мере устрожить результаты автоматического выделения терминов, отграничивая от них высокочастотные нетерминологические единицы; осуществить сопоставительную характеристику состава и употребления терминов в учебниках по разным предметам и разных ступеней обучения; проанализировать динамику пополнения терминологических систем внутри учебно-методических комплексов и охарактеризовать терминологические взаимосвязи между учебниками для отдельных классов. При помощи специально созданного корпуса научных статей по тем дисциплинам, которые соответствуют предметам школьного обучения, были выявлены различия в употреблении терминов в школьной и научной сферах, а также (с использованием дистрибутивно-семантической модели, предоставляемой ресурсом RusVectōrēs) в сфере общеупотребительной и научно-популярной речи. Для каждого из отмеченных аспектов анализа обнаружены значимые признаки в функционировании терминов, свойственные отдельным школьным дисциплинам или их группам. Полученные результаты оценивались в том числе в свете положений теории сложности текста и принципов дидактики и методики. Отмечены, в частности, случаи противоречия между показателями сложности текста и его предполагаемой трудности, а также неоднозначный характер взаимодействия меры сложности текста с ключевыми дидактическими началами.
Иллюстрации


Монахов С. И., Турчаненко В. В., Чердаков Д. Н. Школьный учебный текст в аспекте терминоупотребления: корпусный анализ // Научный результат. Вопросы теоретической и прикладной лингвистики. 2023. Т. 9. № 1. C. 27-49. DOI: 10.18413/2313-8912-2023-9-1-0-3












Пока никто не оставил комментариев к этой публикации.
Вы можете быть первым.
Иомдин Б. Л., Морозов Д. А. Кто поймет «Незнайку»? Автоматическое определение сложности текстов для детей // Русская речь. 2021. № 5. С. 55–68. DOI: 10.31857/S013161170017239-1
Лапошина А. Н., Лебедева М. Ю., Берлин Хенис А. А. Влияние частотности слов текста на его сложность: экспериментальное исследование читателей младшего школьного возраста методом айтрекинга // Russian Journal of Linguistics. 2022. Т. 26. № 2. С. 493–514. DOI: 10.22363/2687-0088-30084
Лейчик В. М. Терминоведение: предмет, методы, структура. М.: ЛКИ, 2007. 256 с.
Лексический состав текстов учебников русского языка для младшей школы: корпусное исследование / Лапошина А. Н., Веселовская Т. С., Лебедева М. Ю., Купрещенко О. Ф // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной международной конференции «Диалог» (Москва, 29 мая — 1 июня 2019 г.). Вып. 18 (25). М., 2019. C. 351–363.
Лукашевич Н. В., Логачев Ю. М. Комбинирование признаков для автоматического извлечения терминов // Вычислительные методы и программирование. 2010. Т. 11. Вып. 4. С. 108–116.
Мартынова Е. В., Солнышкина М. И., Мерзлякова А. Ф., Гизатулина Д. Ю. Лексические параметры учебного текста (на материале текстов учебного корпуса русского языка) // Филология и культура. 2020. № 3 (61). С. 72–80.
Микк Я. А. Оптимизация сложности учебного текста: В помощь авторам и редакторам. М.: Просвещение, 1981. 119 с.
Митрофанова О. А., Захаров В. П. Автоматизированный анализ терминологии в русскоязычном корпусе текстов по корпусной лингвистике // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной международной конференции «Диалог» (Бекасово, 27–31 мая 2009 г.). Вып. 8 (15). М., 2009. С. 321–328.
Монахов С. И., Турчаненко В. В., Чердаков Д. Н. Школьная и научная терминология: корпусное исследование и кластеризация // Информатизация образования и методика электронного обучения: цифровые технологии в образовании. Материалы VI Международной научной конференции. Красноярск, 2022. Ч. 3. С. 228–233.
Морозов Д. А., Иомдин Б. Л. Критерии семантической сложности слова // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной международной конференции «Диалог» (Москва, 29 мая — 1 июня 2019 г.). Вып. 18 (25). М., 2019. Дополнительный том. С. 119–131.
Пиотровский Р. Г., Ястребова С. В. Статистическое опознание термина // Статистика текста / гл. ред. Р. Г. Пиотровский. Т. 1. Минск: Белорусский государственный университет, 1969. С. 249–259.
Солнышкина М. И. Определение уровня лексической сложности текстов: современное состояние проблемы // Сборник научных трудов X Юбилейной международной научно-практической конференции «Учитель. Ученик. Учебник (в контексте глобальных вызовов современности)», 19–20 ноября 2021. М., 2022. C. 20–24.
Солнышкина М. И., Макнамара Д., Замалетдинов Р. Р. Обработка естественного языка и изучение сложности дискурса // Russian Journal of Linguistics. 2022. Т. 26. № 2. С. 317–341. DOI: 10.22363/2687-0088-30171
Солнышкина М. И., Кисельников А. С. Сложность текста: этапы изучения в отечественном прикладном языкознании // Вестник Томского государственного университета. Филология. 2015. № 6 (38). C. 86–99. DOI: 10.17223/19986645/38/7
Соловьев В. Д., Солнышкина М. И., Макнамара Д. С. Компьютерная лингвистика и дискурсивная комплексология: парадигмы и методы исследований // Russian Journal of Linguistics. 2022. Т. 26. № 2. С. 275–316. DOI: 10.22363/2687-0088-30161
Степанова Д. В. Анализ методов автоматического выделения терминов из научно-технических текстов // Актуальные проблемы современной прикладной лингвистики. Минск: Минский государственный лингвистический университет, 2017. С. 62–67.
Татаринов В. А. Общее терминоведение: Энциклопедический словарь. М.: Московский Лицей, 2006. 528 с.
Шпаковский Ю. Ф. Оценка трудности восприятия и оптимизация сложности учебного текста (на материале текстов по химии): Автореф. … канд. филол. наук. Минск, 2007. 21 с.
Brownlee J. Deep Learning for Natural Language Processing: Develop Deep Learning Models for your Natural Language Problems. Vermont: Machine Learning Mastery Publ., 2017. 414 p.
Cabré M. T., Estopà R., Vivaldi J. Automatic Term Detection: A Review of Current Systems // Recent Advances in Computational Terminology / Bourigault D., Jacquemin Ch., L’Homme M.-C. (eds.). Amsterdam: John Benjamins Publ., 2001. Pp. 53–87. DOI: 10.1075/nlp.2.04cab
Durda K., Buchanan L. WINDSORS: Windsor Improved Norms of Distance and Similarity of Representations of Semantics // Behavior Research Methods. 2008. Vol. 40. Pp. 705–712. DOI: 10.3758/BRM.40.3.705
Fisher D., Frey N., Lapp D. Text Complexity: Stretching Readers with Texts and Tasks. Thousand Oaks, CA: Corwin Press, 2016. 216 p.
Flor M., Klebanov B., Sheehan K. Lexical Tightness and Text Complexity // Proceedings of the 2th Workshop of Natural Language Processing for Improving Textual Accessibility (NLP4ITA). Atlanta, 2013. Pp. 29–38.
Glazkova A., Egorov Yu., Glazkov M. A Comparative Study of Feature Types for Age-Based Text Classification // Analysis of Images, Social Networks and Texts. AIST 2020. Lecture Notes in Computer Science. Vol. 12602 / van der Aalst W. et al. (eds.). Cham: Springer Publ., 2021. Pp. 120–134.
Jones M. N., Mewhort D. J. K. Representing Word Meaning and Order Information in a Composite Holographic Lexicon // Psychological Review. 2007. Vol. 114. Pp. 1–37. DOI: 10.1037/0033-295X.114.1.1
Kilgarriff A., Jakubíček M., Kovář V. et al. Finding Terms in Corpora for Many Languages with the Sketch Engine // Proceedings of the Demonstrations at the 14th Conference the European Chapter of the Association for Computational Linguistics, 26–30 April, 2014. Gothenburg, 2014. Рр. 53–56. DOI: 10.3115/v1/E14-2014.
Korkontzelos I., Ananiadou S. Term Extraction // Oxford Handbook of Computational Linguistics / Mitkov R. (ed.). Oxford: Oxford University Press, 2014. Pp. 991–1012.
Kutuzov A., Kuzmenko E. WebVectors: A Toolkit for Building Web Interfaces for Vector Semantic Models // Analysis of Images, Social Networks and Texts. AIST 2016. Communications in Computer and Information Science. Vol. 661 / Ignatov D. et al. (eds.). Cham: Springer Publ., 2017. Pp. 155–161.
Levy O., Goldberg Y. Linguistic Regularities in Sparse and Explicit Word Representations // Proceedings of the Eighteenth Conference on Computational Natural Language Learning / Morante R., Yih S. W-t. (eds.). Proceedings of the Eighteenth Conference on Computational Natural Language Learning. Stroudsburg: Association for Computational Linguistic Publ., 2014. Pp. 171–180. DOI: 10.3115/v1/W14-1618
Mikolov T., Sutskever I., Chen K. et al. Distributed Representations of Words and Phrases and their Compositionality // Advances in Neural Information Processing Systems 26. 27th Annual Conference on Neural Information Processing Systems 2013. Red Hook: Curran Associates Publ., 2013. Pp. 3136–3144.
Mikolov T., Yih W. T., Zweig G. Linguistic Regularities in Continuous Space Word Representations // Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2013. Pp. 746–751.
Nokel M. A., Bolshakova E. I., Loukachevitch N. V. Combining Multiple Features for Single-word Term Extraction // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной международной конференции «Диалог» (Бекасово, 30 мая — 3 июня 2012 г.). Вып. 11 (18). М., 2012. С. 490–501.
Rohde D. L., Gonnerman L. M., Plaut D. C. An Improved Model of Semantic Similarity Based on Lexical Co-Occurrence // Communications of the ACM. 2006. Vol. 8. Pp. 627–633.
Schwanenflugel P. J. Why are Abstract Concepts Hard to Understand? // The Psychology of Word Meanings / Schwanenflugel P. J. (ed.). Hillsdale: Lawrence Erlbaum Associates Inc., 1991. Pp. 223–250.
Sharoff S. What Neural Networks Know about Linguistic Complexity // Russian Journal of Linguistics. 2022. Т. 26. № 2. С. 371–390. DOI: 10.22363/2687-0088-30178
Solovyev V. D., Ivanov V. V., Solnyshkina M. I. Assessment of Reading Difficulty Levels in Russian Academic Texts: Approaches and Metrics // Journal of Intelligent & Fuzzy Systems. 2018. Vol. 34 (2). Pp. 3049–3058. DOI:10.3233/JIFS-169489
Turney P. D., Pantel, P. From Frequency to Meaning: Vector Space Models of Semantics // Journal of Artificial Intelligence Research. 2010. Vol. 37. Pp. 141–188. DOI: 10.1613/jair.2934
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 19-29-14032 мк «Изучение терминологических подсистем современных школьных учебников на русском языке с помощью моделей анализа семантики естественных языков Word2Vec и нейронных сетей».