
Метрики культурно-семантической эквивалентности для больших языковых моделей: взгляд со стороны малоресурсных языков
Мультиязычные большие языковые модели (LLM) преимущественно обучаются и оцениваются на англоязычном материале как доминирующем в датасете. Однако семантические последствия опосредования английским языком их выдачи (например, в результате перевода либо при генерации текстов) на уровне текстовых представлений до сих пор остаются недостаточно изученными за пределами поверхностных мер семантического сходства. В данной работе предлагается метрико-ориентированная методология оценки культурно-семантической целостности текстов, созданных с использованием многоязычных LLM, с особым акцентом на малоресурсные языки.
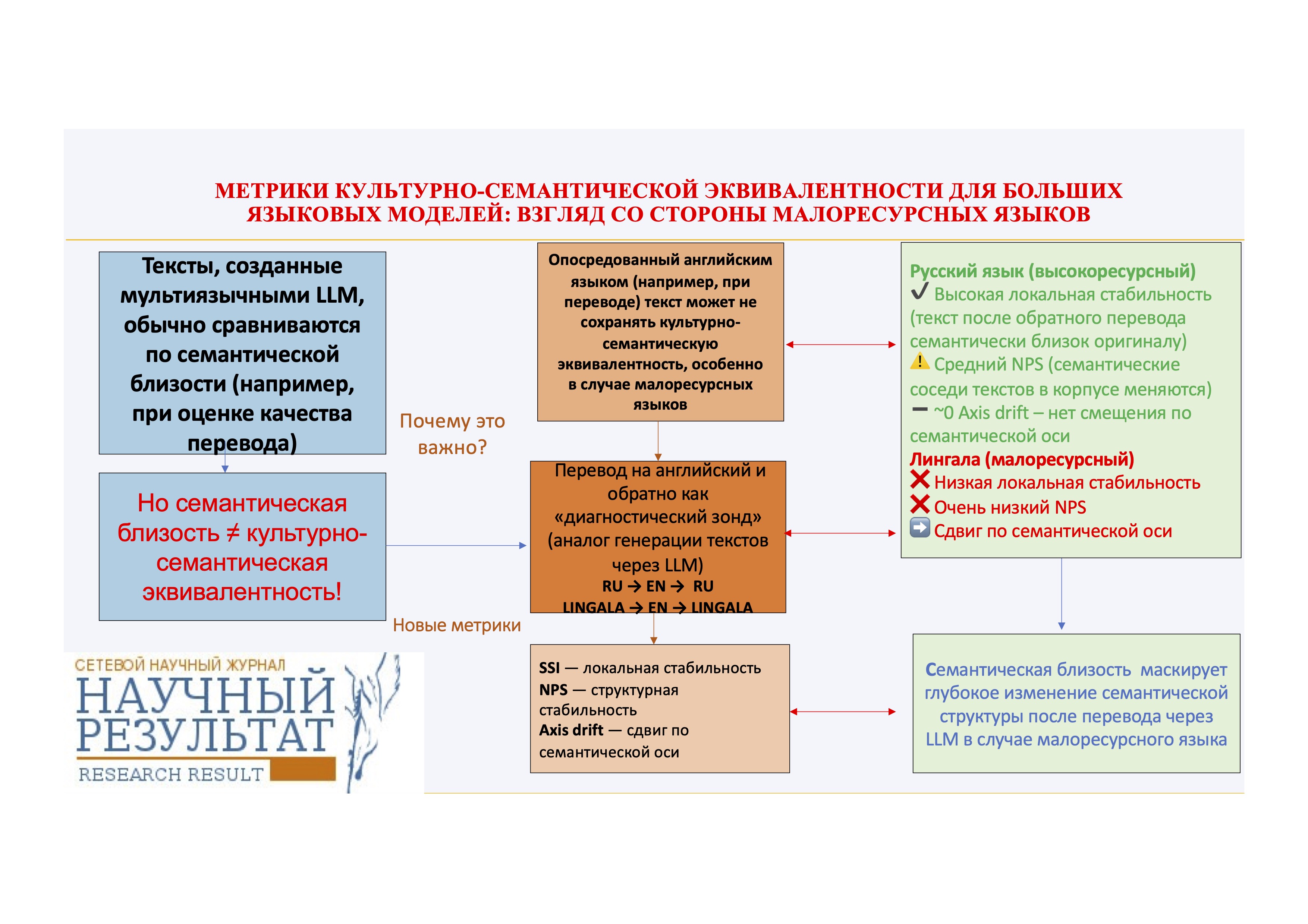
Мы предлагаем набор взаимодополняющих метрик на основе мультиязычных эмбеддингов, предназначенных для исследования эффекта влияния английского посредничества на нескольких уровнях. Используя англо-опосредованный обратный перевод с помощью LLM в качестве диагностического инструментария, мы сравниваем такое влияние на тексты на высокоресурсном (русский) и малоресурсном (лингала) языках. Тексты (оригиналы и обратные переводы) проецируются в общее семантическое пространство, а их семантическая эквивалентность оценивается с помощью трёх метрик: 1) метрики семантического автосходства (SemanticSelf-Similarity, SSI), отражающее семантическую близость текста-оригинала и текста после обратного перевода; 2) метрики сходства семантических соседей (Neighborhood Preservation Score, NPS), измеряющей стабильность локальных семантических связей; 3) метрики сдвига по семантической оси (axis-based drift), количественно описывающей семантическое смещение вдоль интерпретируемой семантической оппозиции.
Результаты исследования показывают выраженную межъязыковую асимметрию. Русские тексты сохраняют высокую семантическую схожесть до и после перевода, что указывает на сохранение поверхностной семантики, однако демонстрируют лишь умеренную сохранность семантических соседей, отражающую нетривиальную структурную реорганизацию датасета. В противоположность этому тексты на языке лингала показывают резкое ухудшение как семантической схожести, так и сохранности семантических окрестностей, что свидетельствует о коллапсе реляционной семантической структуры под влиянием английского языка как промежуточного канала. Кроме того, лингала — в отличие от русского — демонстрирует небольшое, но систематическое направленное смещение вдоль рассматриваемой семантической оси. Принципиально важно, что данное направленное смещение не зависит от структурной нестабильности, что указывает на наличие нескольких различных механизмов влияния английского языка при посредничестве LLM.
Полученные результаты демонстрируют, что метрики поверхностного семантического сходства существенно недооценивают масштабы семантических искажений при обратном переводе, особенно в случае малоресурсного языка. Предложенная методика представляет собой масштабируемый диагностический инструментарий для оценки семантической эквивалентности текстов, созданных с помощью многоязычных LLM.
Литвинова Т. A., Заварзина Г. A. Метрики культурно-семантической эквивалентности для больших языковых моделей: взгляд со стороны малоресурсных языков // Научный результат. Вопросы теоретической и прикладной лингвистики. 2026. Т. 12. № 1. C. 123–145.












Пока никто не оставил комментариев к этой публикации.
Вы можете быть первым.
Brinkmann, J., Wendler, C., Bartelt, C. and Mueller, A. (2025). Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages // Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Pp. 6131–6150, Albuquerque, New Mexico. Association for Computational Linguistics. https://doi.org/10.18653/v1/2025.naacl-long.312
Chew, E., Chakraborti, M., Weisman, W. and Frey, S. (2025). Evaluating Machine Translation Solutions for Accessible Multi-Language Text Analysis: A Back- translation based Approach // Computational Communication Research. Vol. 7, Issue 1. https://doi.org/10.5117/CCR2025.1.5.CHEW
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G. et al. (2020). Unsupervised Cross-lingual Representation Learning at Scale // Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Pp. 8440–8451. Online. Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.747
Elmadany, A., Adebara, I. and Abdul-Mageed, M. 2024. Toucan: Many-to-Many Translation for 150 African Language Pairs // Findings of the Association for Computational Linguistics: ACL 2024. Pp. 13189–13206, Bangkok, Thailand. Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.findings-acl.781
Fan, A., Bhosale, S., Schwenk, H., Ma, Z., El-Kishky, A., et al. (2021). Beyond English-centric multilingual machine translation //
J. Mach. Learn. Res. 22, 1, Article 107. Pp. 4839–4886. https://dl.acm.org/doi/abs/10.5555/3546258.3546365
Feng, F., Yang, Y., Cer, D., Arivazhagan, N. and Wang, W. (2022). Language-agnostic BERT Sentence Embedding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Pp. 878–891. Dublin, Ireland. Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.acl-long.62
Gallegos, I. O., Rossi, R. A., Barrow, J., Tanjim, Md M., Kim, S. et al. (2024). Bias and Fairness in Large Language Models: A Survey // Computational Linguistics. Vol. 50 (3). Pp. 1097–1179. https://doi.org/10.1162/coli_a_00524
Guo, Y., Conia, S., Zhou, Z. Li, M. and Potdar, S. et al. (2025). Do Large Language Models Have an English Accent? Evaluating and Improving the Naturalness of Multilingual LLMs // Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Pp. 3823–3838, July 27 – August 1, 2025, Association for Computational Linguistics [Online], Available at: https://aclanthology.org/2025.acl-long.193.pdf (Accessed 15.03.2026).
Havaldar, S., Rai, S., Singhal, B., Liu, L., Guntuku, S. et al. (2023). Multilingual Language Models are not Multicultural: A Case Study in Emotion // Proceedings of the 13th Workshop on Computational Approaches to Subjectivity, Sentiment, and Social Media Analysis. Pp. 202–214. Toronto, Canada. Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.wassa-1.19
Lauscher, A. and Glavaš, G. (2019). Are We Consistently Biased? Multidimensional Analysis of Biases in Distributional Word Vectors // Proceedings of the Eighth Joint Conference on Lexical and Computational Semantics (SEM 2019). Pp. 85–91, Minneapolis, Minnesota. Association for Computational Linguistics. https://doi.org/10.18653/v1/S19-1010
Litvinova T., Litvinova, O., Zagorovskaya, O., Seredin, P., Sboev A. et al. (2016). "Ruspersonality": A Russian corpus for authorship profiling and deception detection // 2016 International FRUCT Conference on Intelligence, Social Media and Web (ISMW FRUCT), St. Petersburg, Russia, 2016. Pp. 1–7, https://doi.org/10.1109/FRUCT.2016.7584767
Litvinova, T. (2021). RusIdiolect: A New Resource for Authorship Studies // Antipova, T. (eds) Comprehensible Science. ICCS 2020. Lecture Notes in Networks and Systems. Vol. 186. Springer, Cham. https://doi.org/10.1007/978-3-030-66093-2_2
Liu, Y., Zhang, W., Wang, Y., Tang, J., Zhang, P. et al. (2025). Translationese-index: Using Likelihood Ratios for Graded and Generalizable Measurement of Translationese // Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing.
Pp. 12521–12538. Suzhou, China. Association for Computational Linguistics. https://doi.org/10.18653/v1/2025.emnlp-main.633
Moon, J., Cho, H. and Eunjeong L. P. (2020). Revisiting Round-trip Translation for Quality Estimation // Proceedings of the 22nd Annual Conference of the European Association for Machine Translation. Pp. 91–104. Lisboa, Portugal. European Association for Machine Translation [Online], Available at: https://aclanthology.org/2020.eamt-1.11/ (Accessed 15.03.2026).
Narayan, M.A., Pasmore, J., Sampaio, E., Raghavan, V., Maity, S. et al. (2025). Mitigating Bias in Large Language Models Through Culturally-Relevant LLMs // 2025 IEEE International Symposium on Ethics in Engineering, Science, and Technology (ETHICS), Evanston, IL, USA, 2025, Pp. 1–7, https://doi.org/10.1109/ETHICS65148.2025.11098204
Nekoto, W., Marivate, V., Matsila, T., Fasubaa, T., Fagbohungbe, T. et al. (2020). Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages // Findings of the Association for Computational Linguistics: EMNLP 2020, Pp. 2144–2160, Online. Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.findings-emnlp.195
Nie, S., Fromm, M., Welch, C., Görge, R., Karimi, A. et al. (2024). Do Multilingual Large Language Models Mitigate Stereotype Bias? // Proceedings of the 2nd Workshop on Cross-Cultural Considerations in NLP, 2024. Pp. 65–83. Association for Computational Linguistics [Online], Available at: https://aclanthology.org/2024.c3nlp-1.6.pdf (Accessed 15.03.2026).
NLLB Team. Scaling neural machine translation to 200 languages. (2024). Nature. Vol. 630. Pp. 841–846, https://doi.org/10.1038/s41586-024-07335-x
Papadimitriou, I., Lopez, K. and Jurafsky, D. (2023). Multilingual BERT has an accent: Evaluating English influences on fluency in multilingual models // Findings of the Association for Computational Linguistics: EACL 2023. Pp. 1194–1200, Dubrovnik, Croatia. Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-eacl.89
Papineni, K., Roukos, S., Ward, T. and Zhu, W.-J. (2002). BLEU: A method for automatic evaluation of machine translation // Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Pp. 311–318. https://doi.org/10.3115/1073083.1073135
Pawar, S., Park, J., Jin, J., Arora, A., Myung, J. et al. (2025). Survey of Cultural Awareness in Language Models: Text and Beyond // Computational Linguistics. Vol. 51 (3). Pp. 907–1004. https://doi.org/10.1162/COLI.a.14
Rashid, Q., Liemt, E., Shih, T., Ebinama, A., Ramos, K. et al. (2025). Amplify Initiative: Building A Localized Data Platform for Globalized AI, ArXiv, abs/2504.14105 https://doi.org/10.48550/arXiv.2504.14105 .
Rei, R., Craig, S., Farinha, A.C. and Lavie, A. (2020). COMET: A Neural Framework for MT Evaluation // Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Pp. 2685–2702. Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.emnlp-main.213
Sun, K. and Wang, R. (2024). Textual Similarity as a Key Metric in Machine Translation Quality Estimation // ArXiv, arXiv:2406.07440v1 [cs.CL], https://doi.org/10.48550/arXiv.2406.07440
Tonja, A.L., Azime, I.A., Belay, T. D., Yigezu, M. G., Moges, A. Ah M. et al. (2024). EthioLLM: Multilingual Large Language Models for Ethiopian Languages with Task Evaluation // Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). Pp. 6341–6352, Torino, Italia. ELRA and ICCL [Online], Available at: https://aclanthology.org/2024.lrec-main.561/ (Accessed 15.03.2026).
Wang, Y. and Lin, Z. (2025). Revisiting Round-Trip Translation with LLMs and Agentic Translation // 2025 IEEE 5th International Conference on Software Engineering and Artificial Intelligence (SEAI), Pp. 172-178. https://doi.org/10.1109/SEAI65851.2025.11108752
Xu, Y., Hu, L., Zhao, J., Qiu, Z., Ye, Y. and Gu, H. (2025). A Survey on Multilingual Large Language Models: Corpora, Alignment, And Bias // Frontiers of Computer Science. Vol. 19, 1911362. https://doi.org/10.1007/s11704-024-40579-4
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q. and Artzi, Y. (2019). BERTScore: Evaluating Text Generation with BERT // ArXiv, abs/1904.09675. https://doi.org/10.48550/arXiv.1904.09675
Исследование выполнено при поддержке Министерства просвещения Российской Федерации в рамках государственного задания в сфере науки (тема № QRPK-2025-0013).