
Metrics for Cultural Semantic Integrity in LLMs: A Low-Resource Perspective
Multilingual large language models (LLMs) are predominantly trained and evaluated within English-centric pipelines. However, the semantic consequences of English-language mediation at the level of textual representations remain poorly understood beyond surface-level similarity measures. This paper puts forward a metric-based approach to evaluating the cultural and semantic integrity of texts produced using multilingual large language models (LLMs), with a specific focus on low-resource languages.
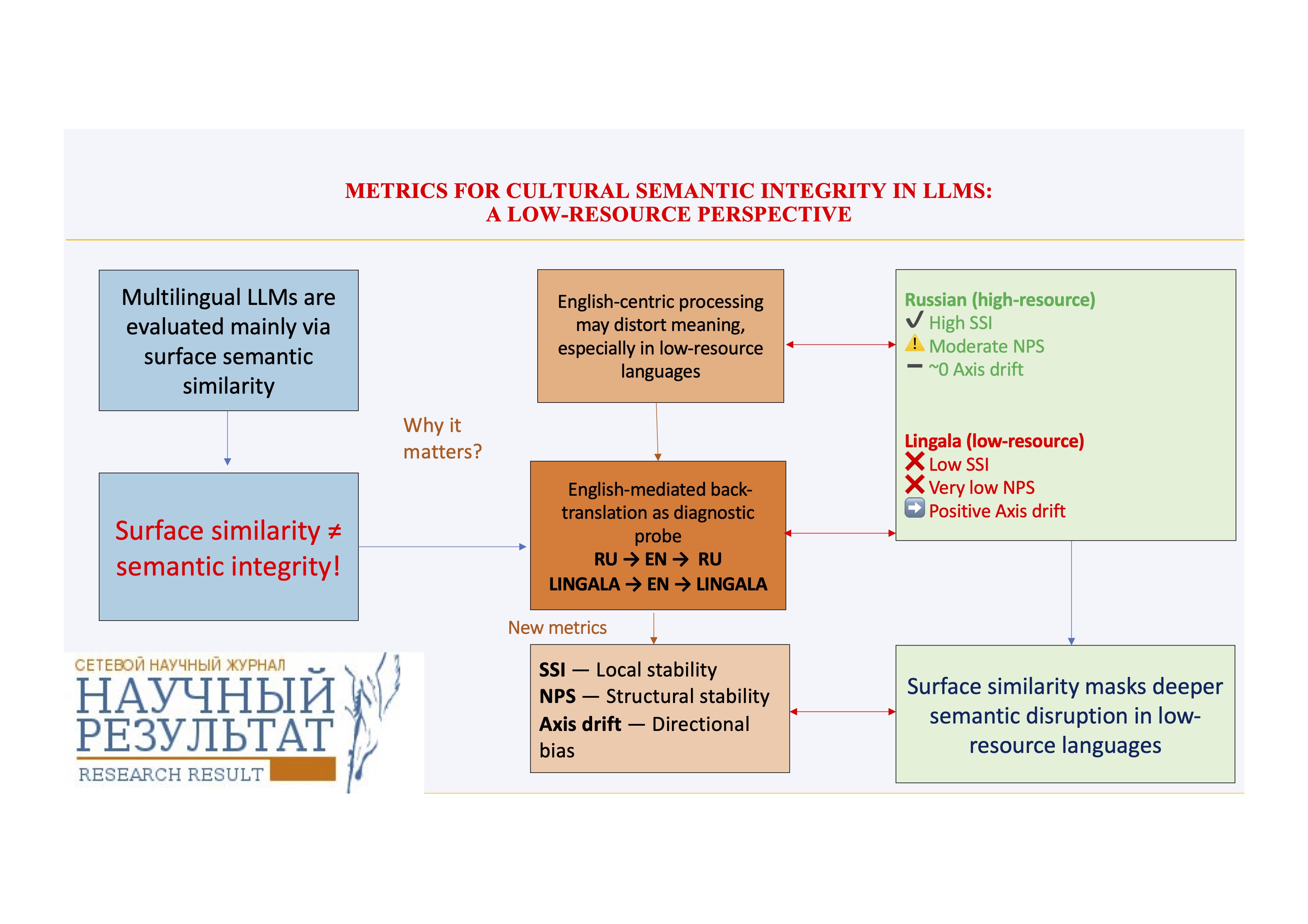
We set forth a set of complementary embedding-based metrics designed to diagnose how English mediation reshapes textual semantic representations at multiple levels. Using English-mediated back-translation via an LLM as a controlled diagnostic probe, we compare a high-resource language (Russian) with a low-resource language (Lingala). Texts are embedded into a shared semantic space, and semantic integrity is assessed using three metrics: Semantic Self-Similarity (SSI), capturing local semantic recognizability; Neighborhood Preservation Score (NPS), measuring the stability of local semantic relations; and axis-based drift, quantifying directional semantic bias along an interpretable semantic opposition.
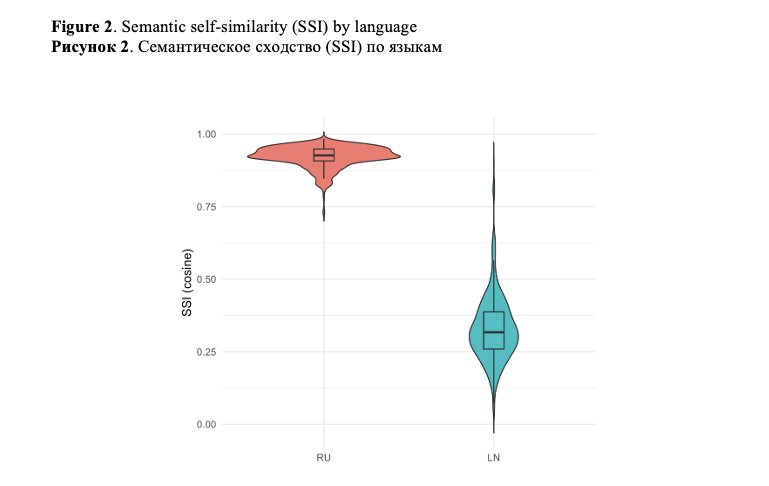
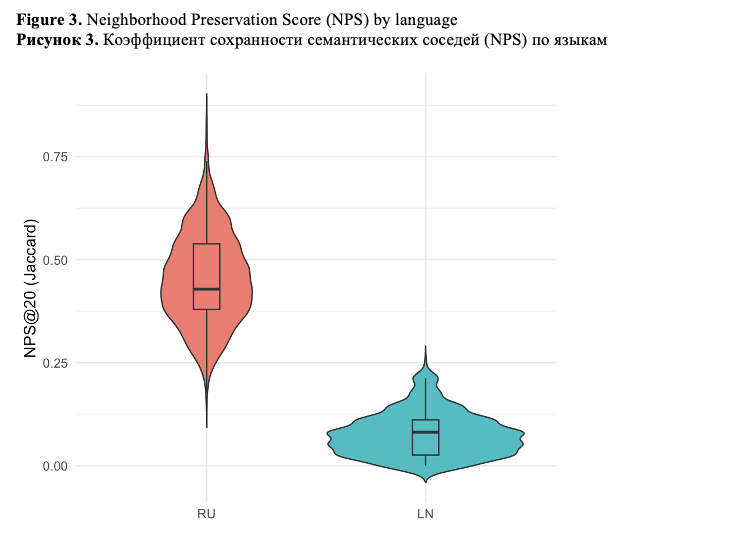
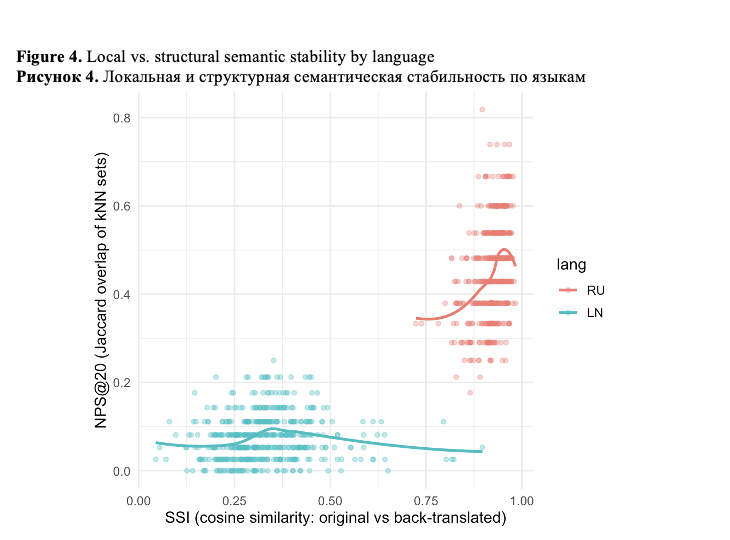
The results reveal a pronounced cross-linguistic asymmetry. Russian texts maintain high semantic self-similarity, indicating strong surface-level semantic preservation, but display only moderate neighborhood preservation, reflecting nontrivial structural reorganization. In contrast, Lingala texts show severe degradation in both semantic self-similarity and neighborhood preservation, indicating a collapse of relational semantic structure under English mediation. Additionally, Lingala – but not Russian – exhibits a small yet systematic directional drift along the examined semantic axis. What is of importance is that this directional bias is independent of structural instability, which is indicative of multiple, distinct mechanisms of English-centric effect.
These findings indicate that surface similarity metrics considerably underestimate semantic disruption, particularly for low-resource languages. The suggested framework provides a scalable diagnostic toolkit for assessing semantic integrity in multilingual LLM representations and is directly applicable to the analysis and evaluation of LLM-generated texts beyond translation-based scenarios. Although we are validating the framework using Russian and Lingala, the proposed metrics are intended for use with other low-resource languages and in multilingual settings.
Figures

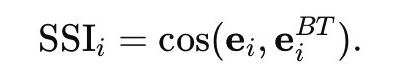 (1)
(1)
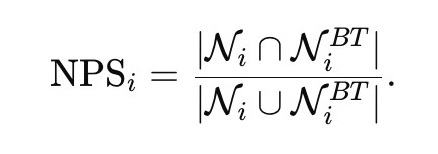 (2)
(2)
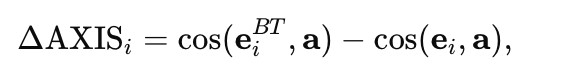
Litvinova, T. A., Zavarzina, G. A. (2026). Metrics for Cultural Semantic Integrity in LLMs: A Low-Resource Perspective, Research Result. Theoretical and Applied Linguistics, 12 (1), 123–145.












While nobody left any comments to this publication.
You can be first.
Brinkmann, J., Wendler, C., Bartelt, C. and Mueller, A. (2025). Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 6131–6150, Albuquerque, New Mexico. Association for Computational Linguistics. https://doi.org/10.18653/v1/2025.naacl-long.312(In English)
Chew, E., Chakraborti, M., Weisman, W. and Frey, S. (2025). Evaluating Machine Translation Solutions for Accessible Multi-Language Text Analysis: A Back-translation based Approach, Computational Communication Research, vol. 7, issue 1. https://doi.org/10.5117/CCR2025.1.5.CHEW(In English)
Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G. et al. (2020). Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 8440–8451, Online. Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.747(In English)
Elmadany, A., Adebara, I. and Abdul-Mageed, M. (2024). Toucan: Many-to-Many Translation for 150 African Language Pairs. In Findings of the Association for Computational Linguistics: ACL 2024, 13189–13206, Bangkok, Thailand. Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.findings-acl.781(In English)
Fan, A., Bhosale, S., Schwenk, H., Ma, Z., El-Kishky, A., et al. (2021). Beyond English-centric multilingual machine translation. J. Mach. Learn. Res. 22, 1, Article 107, 4839–4886. https://dl.acm.org/doi/abs/10.5555/3546258.3546365(In English)
Feng, F., Yang, Y., Cer, D., Arivazhagan, N. and Wang, W. (2022). Language-agnostic BERT Sentence Embedding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 878–891, Dublin, Ireland. Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.acl-long.62(In English)
Gallegos, I. O., Rossi, R. A., Barrow, J., Tanjim, Md M., Kim, S. et al. (2024). Bias and Fairness in Large Language Models: A Survey. Computational Linguistics, 50 (3): 1097–1179. https://doi.org/10.1162/coli_a_00524(In English)
Guo, Y., Conia, S., Zhou, Z. Li, M. and Potdar, S. et al. (2025). Do Large Language Models Have an English Accent? Evaluating and Improving the Naturalness of Multilingual LLMs In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 3823–3838, July 27 – August 1, 2025, Association for Computational Linguistics [Online], Available at: https://aclanthology.org/2025.acl-long.193.pdf (Accessed 15.03.2026). (In English)
Havaldar, S., Rai, S., Singhal, B., Liu, L., Guntuku, S. et al. (2023). Multilingual Language Models are not Multicultural: A Case Study in Emotion. In Proceedings of the 13th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, 202–214, Toronto, Canada. Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.wassa-1.19(In English)
Lauscher, A. and Glavaš, G. (2019). Are We Consistently Biased? Multidimensional Analysis of Biases in Distributional Word Vectors. In Proceedings of the Eighth Joint Conference on Lexical and Computational Semantics (SEM 2019), 85–91, Minneapolis, Minnesota. Association for Computational Linguistics. https://doi.org/10.18653/v1/S19-1010(In English)
Litvinova T., Litvinova, O., Zagorovskaya, O., Seredin, P., Sboev A. et al. (2016). "Ruspersonality": A Russian corpus for authorship profiling and deception detection, 2016 International FRUCT Conference on Intelligence, Social Media and Web (ISMW FRUCT), St. Petersburg, Russia, 2016, 1–7. https://doi.org/10.1109/FRUCT.2016.7584767(In English)
Litvinova, T. (2021). RusIdiolect: A New Resource for Authorship Studies. In: Antipova, T. (eds) Comprehensible Science. ICCS 2020. Lecture Notes in Networks and Systems, vol 186. Springer, Cham. https://doi.org/10.1007/978-3-030-66093-2_2(In English)
Liu, Y., Zhang, W., Wang, Y., Tang, J., Zhang, P. et al. (2025). Translationese-index: Using Likelihood Ratios for Graded and Generalizable Measurement of Translationese. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 12521–12538, Suzhou, China. Association for Computational Linguistics. https://doi.org/10.18653/v1/2025.emnlp-main.633(In English)
Moon, J., Cho, H. and Eunjeong L. P. (2020). Revisiting Round-trip Translation for Quality Estimation. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, 91–104, Lisboa, Portugal. European Association for Machine Translation. https://aclanthology.org/2020.eamt-1.11/(In English)
Narayan, M.A., Pasmore, J., Sampaio, E., Raghavan, V., Maity, S. et al. (2025). Mitigating Bias in Large Language Models Through Culturally-Relevant LLMs. In 2025 IEEE International Symposium on Ethics in Engineering, Science, and Technology (ETHICS), Evanston, IL, USA, 2025, 1–7. https://doi.org/10.1109/ETHICS65148.2025.11098204(In English)
Nekoto, W., Marivate, V., Matsila, T., Fasubaa, T., Fagbohungbe, T. et al. (2020). Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages. In Findings of the Association for Computational Linguistics: EMNLP 2020, 2144–2160, Online. Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.findings-emnlp.195(In English)
Nie, S., Fromm, M., Welch, C., Görge, R., Karimi, A. et al. (2024). Do Multilingual Large Language Models Mitigate Stereotype Bias? In Proceedings of the 2nd Workshop on Cross-Cultural Considerations in NLP, 2024, 65–83. pages 65–83 August 16, 2024. Association for Computational Linguistics [Online], Available at: https://aclanthology.org/2024.c3nlp-1.6.pdf (Accessed 15.03.2026). (In English)
NLLB Team. Scaling neural machine translation to 200 languages. (2024). Nature 630, 841–846. https://doi.org/10.1038/s41586-024-07335-x(In English)
Papadimitriou, I., Lopez, K. and Jurafsky, D. (2023). Multilingual BERT has an accent: Evaluating English influences on fluency in multilingual models. In Findings of the Association for Computational Linguistics: EACL 2023, 1194–1200, Dubrovnik, Croatia. Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-eacl.89(In English)
Papineni, K., Roukos, S., Ward, T. and Zhu, W.-J. (2002). BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 311–318. https://doi.org/10.3115/1073083.1073135(In English)
Pawar, S., Park, J., Jin, J., Arora, A., Myung, J. et al. (2025). Survey of Cultural Awareness in Language Models: Text and Beyond, Computational Linguistics 51 (3): 907–1004. https://doi.org/10.1162/COLI.a.14(In English)
Rashid, Q., Liemt, E., Shih, T., Ebinama, A., Ramos, K. et al. (2025). Amplify Initiative: Building A Localized Data Platform for Globalized AI, ArXiv, abs/2504.14105 https://doi.org/10.48550/arXiv.2504.14105(In English)
Rei, R., Craig, S., Farinha, A.C. and Lavie, A. (2020). COMET: A Neural Framework for MT Evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2685–2702, Online. Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.emnlp-main.213(In English)
Sun, K. and Wang, R. (2024). Textual Similarity as a Key Metric in Machine Translation Quality Estimation, ArXiv, arXiv:2406.07440v1 [cs.CL]. https://doi.org/10.48550/arXiv.2406.07440(In English)
Tonja A.L., Azime, I.A., Belay, T. D., Yigezu, M. G., Moges, A. Ah M. et al. (2024). EthioLLM: Multilingual Large Language Models for Ethiopian Languages with Task Evaluation. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 6341–6352, Torino, Italia. ELRA and ICCL [Online], Available at: https://aclanthology.org/2024.lrec-main.561/ (Accessed 15.03.2026). (In English)
Wang, Y. and Lin, Z. (2025). Revisiting Round-Trip Translation with LLMs and Agentic Translation. 2025 IEEE 5th International Conference on Software Engineering and Artificial Intelligence (SEAI), 172–178. https://doi.org/10.1109/SEAI65851.2025.11108752(In English)
Xu, Y., Hu, L., Zhao, J., Qiu, Z., Ye, Y. and Gu, H. (2025). A Survey on Multilingual Large Language Models: Corpora, Alignment, And Bias. Frontiers of Computer Science, 19, 1911362. https://doi.org/10.1007/s11704-024-40579-4(In English)
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q. and Artzi, Y. (2019). BERTScore: Evaluating Text Generation with BERT. ArXiv, abs/1904.09675. https://doi.org/10.48550/arXiv.1904.09675(In English)
The study is supported by the Ministry of Education of the Russian Federation within the framework of the state task in the field of science (topic number QRPK-2025-0013).