
Школьный учебный текст в аспекте терминоупотребления: корпусный анализ
Aннотация
В статье излагаются методы и результаты анализа употребления терминологической лексики в современных школьных учебниках на русском языке. Основным материалом исследования является созданный исследовательский корпус, включающий тексты 207 учебников с 5-го по 11-й класс по 21 школьной дисциплине. Традиционный способ автоматического извлечения терминов, основанный на статистических показателях частотности словоупотребления, предлагается усовершенствовать с помощью создания моделей, обученных по алгоритмам Word2Vec, в основе которых лежат идеи дистрибутивной семантики. Применение этих алгоритмов, выражающее в числовом представлении сочетаемостное поведение слов и соответственно степень их семантической близости, позволило: в существенной мере устрожить результаты автоматического выделения терминов, отграничивая от них высокочастотные нетерминологические единицы; осуществить сопоставительную характеристику состава и употребления терминов в учебниках по разным предметам и разных ступеней обучения; проанализировать динамику пополнения терминологических систем внутри учебно-методических комплексов и охарактеризовать терминологические взаимосвязи между учебниками для отдельных классов. При помощи специально созданного корпуса научных статей по тем дисциплинам, которые соответствуют предметам школьного обучения, были выявлены различия в употреблении терминов в школьной и научной сферах, а также (с использованием дистрибутивно-семантической модели, предоставляемой ресурсом RusVectōrēs) в сфере общеупотребительной и научно-популярной речи. Для каждого из отмеченных аспектов анализа обнаружены значимые признаки в функционировании терминов, свойственные отдельным школьным дисциплинам или их группам. Полученные результаты оценивались в том числе в свете положений теории сложности текста и принципов дидактики и методики. Отмечены, в частности, случаи противоречия между показателями сложности текста и его предполагаемой трудности, а также неоднозначный характер взаимодействия меры сложности текста с ключевыми дидактическими началами.
Ключевые слова: Термин, Терминология, Школьный учебник, Сложность текста, Частотность слова, Векторное представление, Word2Vec, Нейронная сеть
1. Вступление
В богатой истории российского терминоведения изучение функционирования терминов в школьной учебной литературе занимает незначительное место. Достаточно отметить, что в фундаментальном энциклопедическом словаре В. А. Татаринова (Татаринов, 2006), охватывающем все достижения советской и российской науки о терминах, о специфике школьного терминоупотребления не сказано вообще ничего. Между тем терминология в школьных учебниках, измеряемая тысячами единиц и представляющая своеобразную проекцию системы научных понятий, безусловно, заслуживает внимания и в теоретическом терминоведческом аспекте, и в дидактическом плане, и в социокультурном отношении. Цель исследования, некоторые результаты которого изложены ниже, состоит в том, чтобы в известной мере восполнить указанную лакуну, используя современные методы корпусной и компьютерной лингвистики, позволяющие автоматически обрабатывать значительные массивы информации.
Известны различные методики автоматического извлечения терминов из корпусов большого объема (Korkontzelos, Ananiadou, 2014; Степанова, 2017), однако в большинстве случаев для этой цели используется статистический подход, основы которого были намечены еще в 1960-х гг. (Пиотровский, Ястребова, 1969). Этот подход зиждется на установленной закономерности, согласно которой частотность терминологических единиц в специальных текстах существенно выше, чем в текстах общеупотребительной сферы, и алгоритмически представляет собой сопоставление частотности слов в целевом корпусе, откуда необходимо извлечь термины, и референтном корпусе, который, как правило, представляет совокупность неспециальных текстов на данном языке (Kilgarriff et al., 2014). Статистический подход к автоматическому выделению терминов, реализованный в чистом виде, обычно дает не вполне надежные результаты (Cabré et al., 2001), поэтому исследователи ищут различные способы его комбинации с иными методиками (Митрофанова, Захаров, 2009; Лукашевич, Логачев, 2010; Nokel, 2012). На наш взгляд, существенное улучшение результатов автоматического выделения терминов возможно в случае комбинации статистического подхода с алгоритмами Word2Vec (continuous-bag-of-words — CBOW, skip-gram), которые реализуют основную идею дистрибутивной семантики — значение слова может быть выведено из его лексического окружения и математически определено как сумма контекстов, в которых это слово встречается (Rohde et al., 2006; Jones, Mewhort, 2007; Durda, Buchananan, 2008; Turney, Pantel, 2010). Дистрибутивно-семантические модели, обученные по алгоритмам Word2Vec и использующие для оценки смысловой близости слов их векторные представления (Mikolov et al., 2013a; Mikolov et al., 2013b; Levy, Goldberg, 2014; Brownlee, 2017), широко используются в последнее десятилетие, однако, насколько нам известно, они еще не применялись для изучения терминологического состава учебных текстов. Важнейшее преимущество этого метода перед остальными мы видим в том, что с его помощью можно наблюдать за поведением в тексте семантически связанных терминологических групп и тем самым характеризовать терминоупотребление в аспекте ключевого свойства термина — его принадлежности некоторой терминосистеме (Лейчик, 2007: 98–129).
Результаты стратификации терминологического наполнения школьных учебников, осуществленной методами корпусной и компьютерной лингвистики, могут быть небезынтересны и в аспекте теории сложности текста. Современный этап развития комплексологии отмечен все более широким использованием методов автоматической обработки и анализа текстов; обзоры см. в: (Соловьев и др., 2022; Солнышкина и др., 2022); примеры исследований: (Flor et al, 2013; Иомдин, Морозов, 2021; Glazkova et al., 2021; Sharoff, 2022). Эти методы применяются и для оценки сложности учебных текстов разных типов, которые традиционно являются одним из основных предметов интереса специалистов по комплексологии; см., например, исследования сложности школьных учебных текстов на материале корпусных данных: (Solovyev et al., 2018; Мартынова и др., 2020).
Употребление терминов считается одним из лексических показателей сложности текста (Шпаковский, 2007). При этом природа терминологических единиц такова, что на увеличение меры сложности текста они влияют в силу целого ряда своих характеристик. Термины — это, как правило, малочастотные за пределами специальных текстов слова; традиционно считается, что высокий процент низкочастотных слов увеличивает сложность текста, что в целом подтверждается и исследованиями с применением новейших технологий (Лапошина и др., 2022). Термины, даже референциально отсылая к конкретным объектам действительности, тяготеют к понятийной абстракции (Татаринов, 2006: 231–234) и тем самым увеличивают степень абстрактности текста, следовательно, и меру его сложности (Schwanenflugel, 1991; Fisher et al., 2016). Наконец термины, как правило, считаются семантически сложными словами, степень «знакомства» с которыми у неспециалиста невелика (Микк, 1981: 65). Семантическая сложность слова плохо поддается формальному измерению (Морозов, Иомдин, 2019), однако следует учитывать, что в учебном тексте термины — это именно те слова, значение которых требуется усвоить, что в данном случае оправдывает их характеристику как «незнакомых» слов.
Применительно к учебной книге или учебно-методическому комплексу важно учитывать закрепившееся в комплексологии разграничение абсолютной сложности текста как суммы его объективных характеристик и трудности текста (иначе — относительной сложности текста) как его качества, зависимого от внешних факторов, в частности от познавательных возможностей воспринимающего текст субъекта (Солнышкина, Кисельников, 2015: 86–87; Солнышкина, 2022: 20). Высокая частотность терминов увеличивает меру сложности текста в целом, но их регулярная повторяемость в тексте учебника постепенно снижает его трудность (Микк, 1981: 67). Один и тот же текстовый фрагмент, содержащий подлежащие усвоению термины и размещенный одновременно в начале и в конце учебника, обладает одинаковой мерой сложности, но, очевидно, должен предположительно оцениваться как соответственно более и менее трудный, ибо сумма знаний ученика и степень его знакомства с терминологическими единицами должны были увеличиться в ходе обучения.
В аспекте дидактики сложность и трудность учебного текста преломляются в дихотомии дидактических принципов научности и доступности: содержание школьного учебника должно так или иначе соответствовать современным научным представлениям, отражая в том числе и их терминологическую составляющую (и в этом плане оно неизбежно трудно), но при этом оно должно быть посильным для усвоения. Отклонение от реализации этих принципов в любую сторону снижает дидактическую эффективность учебника.
2. Материал и методы
2.1. Создание целевых корпусов
В основе проведенного исследования лежит ряд процедур, в частности создание исследовательских (иначе — целевых) корпусов, векторизация корпусов, кластеризация полученных данных.
Первоочередной задачей было создание целевого корпуса текстов школьных учебников. Для создания корпуса были использованы тексты 207 учебников с 5-го по 11-й класс, выпущенных издательством «Просвещение» (от издательства было получено официальное разрешение использовать тексты в исследовательских целях). Все учебники на момент включения их текстов в корпус (2020 г.) входили в формируемый Министерством просвещения федеральный перечень изданий, рекомендованных к использованию в школах. Тексты сканировались, распознавались, проходили обработку (удалялись небуквенные символы, знаки препинания, унифицировался регистр букв и др.); с помощью программных средств словоформы приводились к начальной форме, осуществлялась частеречная разметка слов. В конечном счете общий объем корпуса составил чуть более 13 965 000 словоупотреблений. Корпус был разбит на подкорпусы в соответствии со школьными дисциплинами (всего — 21): алгебра (18 учебников; всего 1 144 089 словоупотреблений), астрономия (2; 89 574), биология (21; 1 125 648), всеобщая история и история России (15; 973 498), география (8; 512 173), геометрия (8; 370 054), естествознание (2; 158 665), изобразительное искусство (8; 283 608), информатика (6; 284 683), литература (18; 3 939 054), математика (10; 525 035), математический анализ (14; 1 134 786), мировая художественная культура (2; 33 130), музыка (4; 76 241), обществознание (12; 505 822), право (2; 171 349), русский язык (18; 1 131 575), технология (4; 163 574), физика (15; 1 098 625), физическая культура (7; 301 371), химия (13; 543 283). Кроме того, каждый предметный подкорпус был разделен на составные части в соответствии с годами обучения.
Еще одним специально созданным исследовательским корпусом, необходимым для изучения школьного терминоупотребления в сопоставительном аспекте (см. ниже — п. 3.2), стал корпус современных научных статей на русском языке. Он формировался согласно следующим принципам. Из наиболее цитируемых, при этом не узкоспециальных научных журналов различных областей знания извлекались статьи, опубликованные в 2016–2021 гг. Для каждой области знания отбирались от двух до пяти журналов, при этом доля статей из каждого журнала определялась мерой его цитируемости. В корпус включались тексты научных статей и научных сообщений из основных разделов журналов; учитывались основой текст статьи, ее название и аннотация. Например, из 100 с лишним журналов географической тематики, индексируемых в Российском индексе научного цитирования, было отобрано три не узкоспециальных журнала с наибольшим количеством цитирований — «География и природные ресурсы», «Вестник Московского университета. Серия 5: География» и «Известия Российской академии наук. Серия географическая». Поскольку эти журналы имеют приблизительно одинаковый индекс средней цитируемости (8,51, 9,72 и 9,00 соответственно), было принято решение использовать для формирования корпуса все три журнала примерно в равном соотношении: в корпус вошли тексты соответственно 50, 46 и 40 статей (всего 136 статей). В соответствии с областями знания корпус научных статей был разделен на подкорпусы, которые, за отдельными исключениями, соответствуют подкорпусам корпуса школьных учебников (в корпусе научных статей не выделялись школьные подкорпусы «Естествознание» и «Технология»; школьным подкорпусам «Математика», «Алгебра», «Геометрия», «Математический анализ» соответствовал единый подкорпус научных статей «Математика», точно так же школьным подкорпусам «Изобразительное искусство» и «Мировая художественная культура» соответствовал единый подкорпус научных статей «Искусство»). Тексты проходили необходимую обработку, аналогичную тем операциям, которые осуществлялись в отношении текстов школьных учебников. Объем каждого подкорпуса в корпусе научных статей составил не менее 75 % от объема аналогичного подкорпуса корпуса школьных текстов, например: география — (а) в подкорпусе корпуса научных статей около 434 000 словоупотреблений, (б) в соответствующем подкорпусе корпуса школьных учебников около 512 000 словоупотреблений; биология — (а) около 853 000 словоупотреблений и (б) около 1 126 000 словоупотреблений; история — (а) около 902 000 словоупотреблений и (б) около 973 000 словоупотреблений. Общий объем корпуса научных статей составил около 10 795 500 словоупотреблений.
Подготовленные корпусы были загружены на платформу Sketch Engine (https://www.sketchengine.eu), на которой осуществлялось автоматическое извлечение кандидатов в термины согласно охарактеризованной выше процедуре сопоставления относительной частотности слов в целевом и референтном корпусах. В качестве референтного корпуса выступал Russian Web 2011 Sample (ruTenTen11), доступный в Sketch Engine и содержащий более 900 миллионов словоупотреблений из русскоязычных интернет-текстов.
2.2. Автоматическое извлечение терминов и последующая векторизация данных
Алгоритмы извлечения однословных и неоднословных кандидатов в термины различались. Для каждой однословной лексической единицы, употребленной в соответствующем подкорпусе не менее трех раз, высчитывалась метрика keyness score по формуле: ((Lt * 1,000,000 / Ct) +1) / ((Lr * 1,000,000 / Cr) +1), где Lt — частота употребления единицы в целевом корпусе, Ct — общее количество токенов в целевом корпусе, Lr — частота употребления единицы в референтном корпусе, Cr — общее количество токенов в референтном корпусе. Однословная единица получала статус кандидата в термины, если значение метрики keyness score превышало 1; ср., например, значения метрики keyness score для слов в корпусе школьных учебников в подкорпусе «Алгебра» (7–9 классы): «многочлен» — 743.2, «множитель» — 380.4, «парабола» — 322.3; в подкорпусе «Русский язык (5 класс): «существительное» — 479.4, «падеж» — 231.4, «антоним» — 170.4; в подкорпусе «Биология» (9 класс): «фотосинтез» — 562.3, «фенотип» — 166.1, «цитоплазма» — 11.2; в корпусе научных статей в подкорпусе «Химия»: «макромолекула» — 306.5, «адсорбция» — 103.042, «полимеризация» — 67.9; в подкорпусе «Астрономия»: «полуось» — 197.4, «галактика» — 94.6, «цефеиды» — 31.3.
Вычленение неоднословных кандидатов в термины происходило в два этапа. Первоначально из всех возможных сочетаний лексем, встречающихся в соответствующем подкорпусе не менее трех раз, были выделены сочетания, характеризующиеся положительным значением метрики Log-Dice score, рассчитываемой по следующей формуле: 14 + log(2(|X⋂Y|) / (|X| + |Y|)), где |X| — абсолютная частота первого элемента сочетания в подкорпусе, |Y| — абсолютная частота второго элемента сочетания в подкорпусе, |X⋂Y| — абсолютная частота всего сочетания в подкорпусе. Затем для выделенных сочетаний была рассчитана метрика keyness score согласно приведенной выше формуле. Ср., например, значения метрики keyness score для коллокаций в корпусе школьных учебников в подкорпусе «Алгебра» (7–9 классы): «график функции» — 725.9, «натуральное число» — 200.9, «линейная функция» — 97.6; в подкорпусе «Русский язык» (5 класс): «часть речи» — 428.2, «единственное число» — 222.4, «прошедшее время» — 76.1; в подкорпусе «Биология» (9 класс): «бесполое размножение» — 240.4, «пищевая цепь» — 190.9, «генная инженерия» — 67.0; в корпусе научных статей в подкорпусе «Химия»: «элементный анализ» — 145.0, «реакционная масса» — 75.4, «буферный раствор» — 65.7; в подкорпусе «Астрономия»: «красное смещение» — 120.4, «дыра Локмана» — 81.0, «солнечный ветер» — 51.2.
Полученные списки однословных и неоднословных кандидатов в термины были упорядочены по убыванию значения метрики keyness score; для дальнейшей обработки использовались первые 1000 единиц, извлеченных из корпуса школьных учебников, и первые 2000 единиц, извлеченных из корпуса научных статей.
Одной из основных проблем при применении вышеописанной процедуры является отграничение в кругу автоматически выделенных слов и сочетаний собственно терминологической лексики от нетерминологических лексических единиц, уподобленных терминам по поведению в текстах учебников, то есть низкочастотных в референтном корпусе, но высокочастотных в целевом корпусе. Ниже такие слова будут условно называться лжетерминами. Подчеркнем условность этого наименования, ибо при автоматическом отграничении терминов от лжетерминов в состав последних по разным причинам могут попасть и собственно термины.
Для оптимизации полученных результатов использовались алгоритмы Word2Vec, на основе которых была проведена векторизация целевых корпусов и созданы и обучены дистрибутивно-семантические модели (word embedding models), которые позволяли определить меру сходства в синтагматических характеристиках автоматически выделенных единиц в каждом из созданных подкорпусов. Для каждого подкорпуса было получено две модели — для однословных единиц и для неоднословных единиц (биграмм и триграмм). Обучение моделей происходило в следующем порядке: 1) определялась частотность каждого слова в корпусе; 2) слова сортировались по частоте, редкие слова удалялись; 3) для снижения вычислительной сложности алгоритма словарь кодировался с помощью дерева Хаффмана (Huffman Binary Tree); 4) для каждого слова в корпусе строился вектор, элементы которого представляют собой обозначения количества случаев, когда данное слово оказывается в одном окне контекстов с другими наиболее частотными словами данного корпуса (параметр окнá контекстов — заданная максимальная дистанция между текущим и предсказываемым словом в предложении); 5) построенные векторы подавались на вход нейросети прямого распространения (feedforward neural network), которая обучается предсказывать либо контекст по заданному слову, либо слово по заданному контексту.
Векторное представление позволяет оценивать степень семантической близости каждой пары слов на основе косинусной меры их векторов. Для каждой парной комбинации была высчитана мера косинусной близости CS = u * v / (||u|| * ||v||), так что CS находится в пределах [0,1], где 1 обозначает идентичность векторов (что указывает на идентичность контекстов, в которых встречаются слова, а следовательно, на их предельную семантическую близость), а 0 — на их ортогональность (то есть отсутствие общих контекстов, а значит и общих сем). Ср., например, показатели косинусной близости в школьном подкорпусе «Русский язык»: для пары слов «суффикс» и «окончание» — 0.80, для пары слов «суффикс» и «груша» — 0.18.
Результаты векторизации использовались для усовершенствования итогов автоматического выделения терминов двумя разными способами — в зависимости от того, к школьному или научному целевому корпусу они применялись. Это вызвано разным характером текстов, составивших соответствующий целевой корпус: в случае с корпусом научных статей следует предполагать более однородный лексический состав текстов и их относительно сходную композицию.
В отношении единиц, автоматически выделенных из школьного корпуса, был избран способ кластеризации семантических карт. С помощью алгоритма стохастического вложения соседей с t-распределением (t-SNE) были построены соответствующие подкорпусам карты взаимного расположения терминологических кандидатов в обученных дистрибутивно-семантических моделях; из векторного пространства высокой размерности эти карты с целью визуализации полученных результатов были спроецированы в двухмерную плоскость. См. примеры подобных карт на рис. 1 и 2.
Рисунок 1. Семантическая карта распределения кандидатов в термины. Подкорпус «Алгебра» (9 класс)
Figure 1. Semantic map representing the distribution of term candidates. Subcorpus Algebra (grade 9)

Рисунок 2. Семантическая карта распределения кандидатов в термины. Подкорпус «Русский язык» (6 класс)
Figure 2. Semantic map representing the distribution of term candidates. Subcorpus Russian (grade 6)
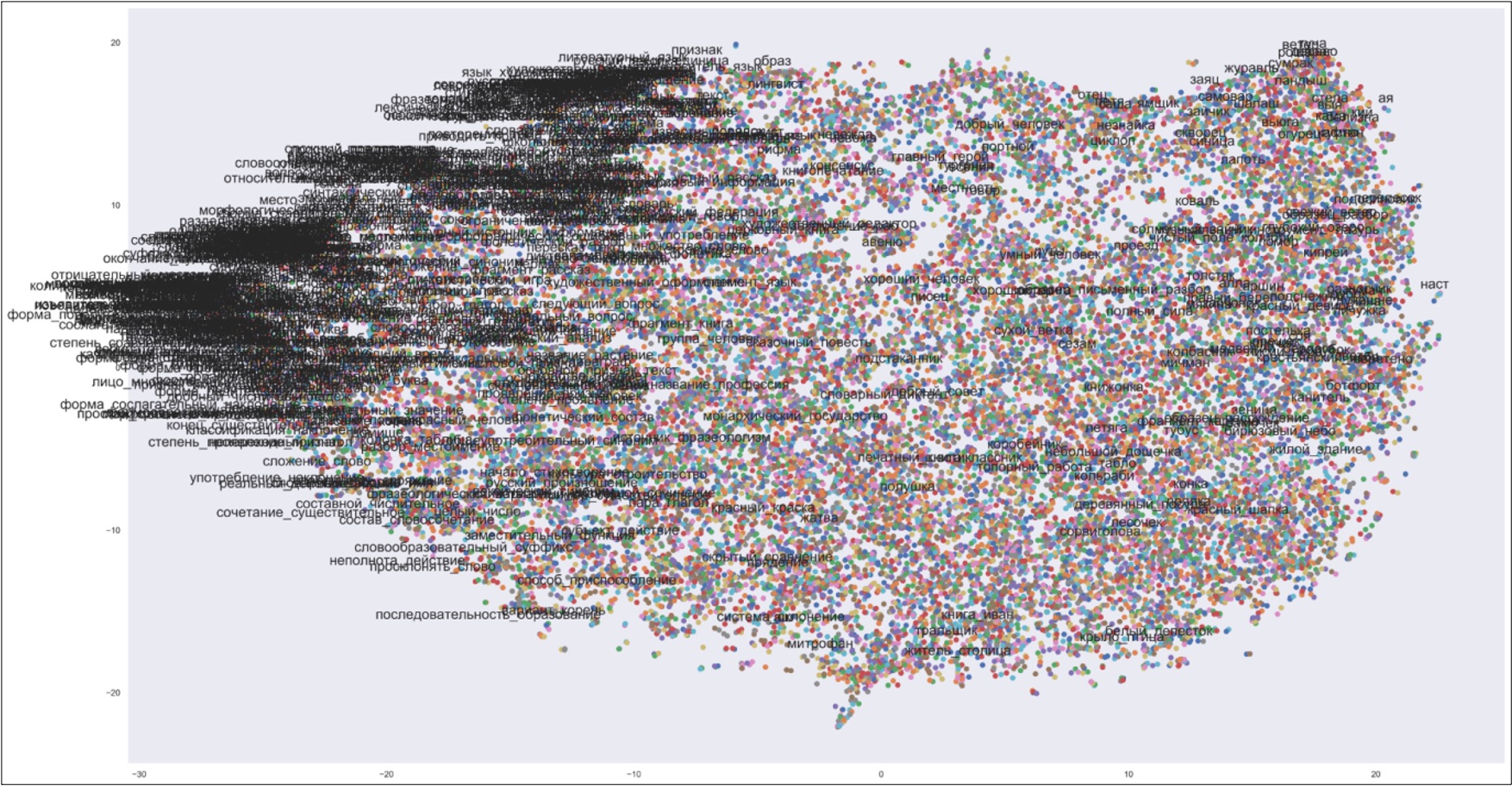
Допускалась высокая вероятность того, что собственно термины образуют на картах черно́ты — кластеры, объединенные небольшой косинусной дистанцией; лжетермины, напротив, предположительно рассеяны на остальном пространстве карты. С помощью метода вычисления k-средних (k-means) была осуществлена кластеризация точек на плоскости по их координатам и маркировка каждого из полученных кластеров как содержащего термины или как содержащего лжетермины. В каждой семантической карте выделялось 20 кластеров, по которым распределялись все имеющиеся точки. При маркировке кластеров принимались во внимание следующие факторы: 1) удельная доля слов, встречающихся внутри кластера и в качестве самостоятельных единиц, и в составе биграмм и триграмм (предполагается, что для кластеров, содержащих термины, характерна более высокая степень повторяемости слов); 2) удельная доля неоднословных единиц внутри кластера (предполагается, что в кластерах, содержащих термины, количество неоднословных единиц больше, так как уровень точности при автоматическом выделении терминологических сочетаний выше, чем при выделении однословных терминов); 3) удельная доля кандидатов в термины внутри кластера, которые соответствуют терминам, наличествующим в Федеральных государственных образовательных стандартах (предполагается, что для кластеров, содержащих термины, характерно большее число подобных совпадений). С учетом этих факторов высчитывалась единая метрика, значение которой для каждого кластера варьируется от 1 (с высокой вероятностью кластер содержит термины) до 7200 (с высокой вероятностью кластер содержит лжетермины). Ср., например, фрагменты полученных списков для подкорпуса «Русский язык» (9 класс): значение метрики «1» — «русский_язык», «синтаксис», «фонетика», «орфография», «история_язык», «слово», «неологизм», «морфема», «этимология», «старославянский_язык», «значение», «древнерусский_язык», «современный_русский_язык», «славянский_язык», значение метрики «3600» — «ветер», «дерево», «осина», «оса», «колокольчик», «ель», «соловей», «ямщик», «рябина», «пирог», «туман», «гром», «туча», «роса»; для подкорпуса «География» (7 класс): значение метрики «4.6» — «воздушный_масса», «форма_рельеф», «котловина», «высотный_поясность», «высотный_пояс», «землетрясение», «кристаллический_фундамент», «платформа», «муссон», значение метрики «16.8» — «причина_образование», «французский_язык», «карта_приложение», «сочетание_фактор», «карта_евразия», «деление_земля», «бразильский_карнавал», «благосостояние_население», «главный_занятие».
Для усовершенствования результатов автоматического выделения терминов из корпуса научных статей был использован другой способ. Автоматически выделенные кандидаты в термины были иерархически упорядочены по мере их семантического удаления от условного центра лексической системы общеупотребительного языка. За этот центр было принято высчитанное среднее значение О всех векторных представлений, содержащихся в обученной на материале Национального корпуса русского языка дистрибутивно-семантической модели, предоставляемой сервисом RusVectōrēs (Kutuzov, Kuzmenko, 2017). (1) Векторное представление каждого кандидата в термины Сi в исходном списке {LСj}, так что Сi ∈ {LСj}, сопоставлялось с О, а именно высчитывалось косинусное расстояние между векторами θ(Сi) = cos(Сi, О); (2) кандидату с наибольшим косинусным расстоянием θ присваивался индекс 1 как наиболее вероятному термину, после чего он удалялся из списка, так что Сi => K1 и K1 ∈ {KС} ∉ {LСj+1}, если θ(Сi) = argmax(θi … θn); (3) шаги 1–2 повторялись для Сi+1 ∈ {LСj+1} до тех пор, пока список не опустевал, так что {LСn} = ∅ и {KС} = {LСj}. Наконец среди множества иерархически упорядоченных индексов {i … n} в списке {KС} выбирался такой индекс k (i < k < n), чтобы подмножество кандидатов {Kk … Kn} можно было исключить из списка {KС} как составленное из наименее вероятных терминов. На данном этапе исследования выбор соответствующей точки отсечки для каждой дисциплины производился экспертным решением. Ср., например, 15 первых и последних кандидатов в термины из выстроенного подобным образом списка для предметной области «Русский язык»: кандидаты с 15 первыми индексами — «экспликация», «предикативность», «именование», «модус», «денотат», «интенция», «лексема», «актант», «пресуппозиция», «дескрипция», «модальность», «семантика», «референция», «предикат», «пропозиция»; кандидаты с 15 последними индексами — «мальчик», «варвара», «петя», «наци», «бенефициант», «господин», «скотина», «парная», «зеница», «макар», «жучок», «обида», «скука», «тополь», «червяк».
После применения к изначально выделенному материалу описанных операций количество однословных и неоднословных единиц, отнесенных к терминам, составило для корпуса школьных учебников 26 328; распределение по подкорпусам: алгебра — 1 526, астрономия — 456, биология — 2 324, всеобщая история и история России — 2 491, география — 1 635, геометрия — 570, естествознание — 198, изобразительное искусство — 808, информатика — 682, литература — 2 306, математика — 903, математический анализ — 635, мировая художественная культура — 215, музыка — 46, обществознание — 2 286, право — 404, русский язык — 2 633, технология — 406, физика — 2 836, физическая культура — 1 161, химия — 1 807. Для корпуса научных статей количество однословных и неоднословных единиц, отнесенных к терминам, составило 15 247; распределение по подкорпусам: астрономия — 1 060, биология — 1 157, география — 1 112, информатика — 896, искусствознание — 1 182, история — 891, литературоведение — 1 101, математика — 753, музыковедение — 955, обществознание — 1 116, право — 1 169, русский язык / лингвистика — 945, физика — 999, физическая культура — 892, химия — 1 019.
3. Результаты и обсуждение
3.1. Термины и высокочастотная нетерминологическая лексика
Векторизация данных позволяет улучшить результаты автоматического извлечения терминов и создает основу как для интерпретации терминоупотребления в школьных учебных текстах, так и для дальнейших операций, направленных на изучение его особенностей.
В первую очередь следует обратить внимание на факт автоматического выделения в текстах школьных учебников существенного числа лжетерминов — единиц, относительная частотность которых в целевом корпусе превышает общеязыковые показатели, но отсеянных в результате векторизации. Тематическая характеристика лжетерминов, как и их количество, различается в предметных подкорпусах. Состав лексико-семантических групп, в которые входят лжетермины в учебниках по разным дисциплинам, может стать предметом обсуждения в рамках методики школьного обучения и общей дидактики.
Для ряда дисциплин денотативная соотнесенность лжетерминов очевидным образом определяется тем аспектом реальности, который является предметом описания в соответствующих школьных учебниках; ср., например, фрагмент обширного ряда наименований растительных организмов, высокочастотных в целевом подкорпусе по биологии: «абрикос, акация, арахис, астра, бегония, белена, бузина, вишня, георгин, горох, дуб, дурман, ель, земляника, ива, капуста, картофель, кипарис, кислица, клевер, кукуруза, ландыш, лещина, липа, лиственница, люпин, люцерна, малина, можжевельник, нарцисс, одуванчик, ольха, орешник, орхидея, осина, осока, пальма, папоротник, пеларгония, пихта, подорожник, подсолнечник, пшеница, пырей, редис, редька, репа, рыжик, рябина, саксаул, сирень, слива, сосна, томат, тополь, тюльпан, фасоль, фиалка, фикус, хлопчатник, хризантема, цикорий, шиповник, эвкалипт, яблоня, ясень, ячмень».
В то же время в иных предметных подкорпусах наличие некоторых ярко выделяющихся групп лжетерминов объясняется скорее сложившейся методической традицией. Так, в подкорпусе «Литература» (10–11 класс) привлекает внимание автоматически выделяемая группа абстрактных существительных с соответствующими суффиксами, относящихся к стилистическим пластам высокой или сугубо книжной лексики: «безверие, возмездие, высокий_предназначение, дарование, духовный_возрождение, жертвенность, искание, искренность, личный_достоинство, мечтание, мироздание, мироощущение, миросозерцание, нравственный_чувство, обличение, поэтический_вдохновение, предчувствие, преображение, прозрение, простодушие, раздумье, самопожертвование, скитание, сострадание, сочувствие, страдание, счастие, тщеславие, человечность, чужбина». Очевидно, что эти слова автоматически попадают в списки кандидатов в термины, поскольку регулярно используются в учебниках для интерпретации художественного смысла произведений или особенностей биографий авторов.
Еще более показательна картина в подкорпусе «Русский язык» на всех ступенях обучения с 5 по 9 класс. В составе лжетерминов здесь в большом количестве обнаруживаются слова и сочетания, являющиеся элементами пейзажных описаний или характеристики природных явлений; ср., например, фрагмент подобного ряда: «аист, былинка, верба, ветер, воробей, восход_солнце, вьюга, глубокий_озеро, голубой_небо, гроза, гром, дождик, долгий_зима, дубрава, дымок, ель, жаворонок, журавль, заяц, зимний_утро, зяблик, ива, изморозь, изморось, иней, камыш, крапива, кукушка, лазурь, ландыш, лесной_озеро, лесной_поляна, лесок, липа, лиса, листопад, метель, наст, начало_осень, облачко, овраг, озимь, орешник, оса, осина, осока, перелесок, песок, пичужка, подосиновик, подснежник, поздний_осень, пороша, пригорок, проталина, ракита, родной_природа, роса, роща, рябина, свежий_ветер, синий_небо, синица, сирень, скворец, снегирь, снежный_буря, сова, соловей, старый_дуб, стужа, сумрак, туман, туча, фиалка, холодный_ветер, чаща, чибис, шалаш, шмель». Установлено, что доминирование темы природы характерно и для лексического наполнения учебников по русскому языку для младших классов (Лексический состав…, 2019). Следует отметить, что именно для пособий по русскому языку формирование тематически сбалансированной, эмоционально актуальной и стилистически разнообразной речевой среды учебника имеет принципиальное значение, поскольку непосредственным образом связано с дидактическими целями учебного предмета. В связи с этим и вопреки силе методической традиции можно полагать, что ощущаемая интуитивно, но теперь и математически подтвержденная тематическая однородность языкового материала, предлагаемого для лингвистического анализа в учебниках по русскому языку, дидактически малоэффективна.
Представляет интерес количественное соотношение терминов и лжетерминов в кругу высокочастотной лексики в различных предметных подкорпусах. По этому показателю школьные дисциплины образуют градацию с относительно отчетливым противопоставлением учебников по точным и естественным наукам учебникам по гуманитарным предметам. Первые отмечены преобладанием собственно терминологической лексики, в то время как для вторых характерна значительная доля лжетерминов (см. рис. 3). Следует отметить не вполне ожидаемое положение на этой шкале подкорпуса «Русский язык», по степени терминологической насыщенности сближающегося с подкорпусами точных и естественных дисциплин, что указывает на весьма обширный терминологический аппарат, используемый в учебниках по русскому языку (ср. место на этой шкале предмета «Литература», который, казалось бы, образует вместе с предметом «Русский язык» единство в отношении словесности как предмета изучения).
Рисунок 3. Доля терминов от общего числа высокочастотной лексики в подкорпусах корпуса школьных учебников
Figure 3. Share of terms in the total number of high-frequency words in the textbook subcorpora
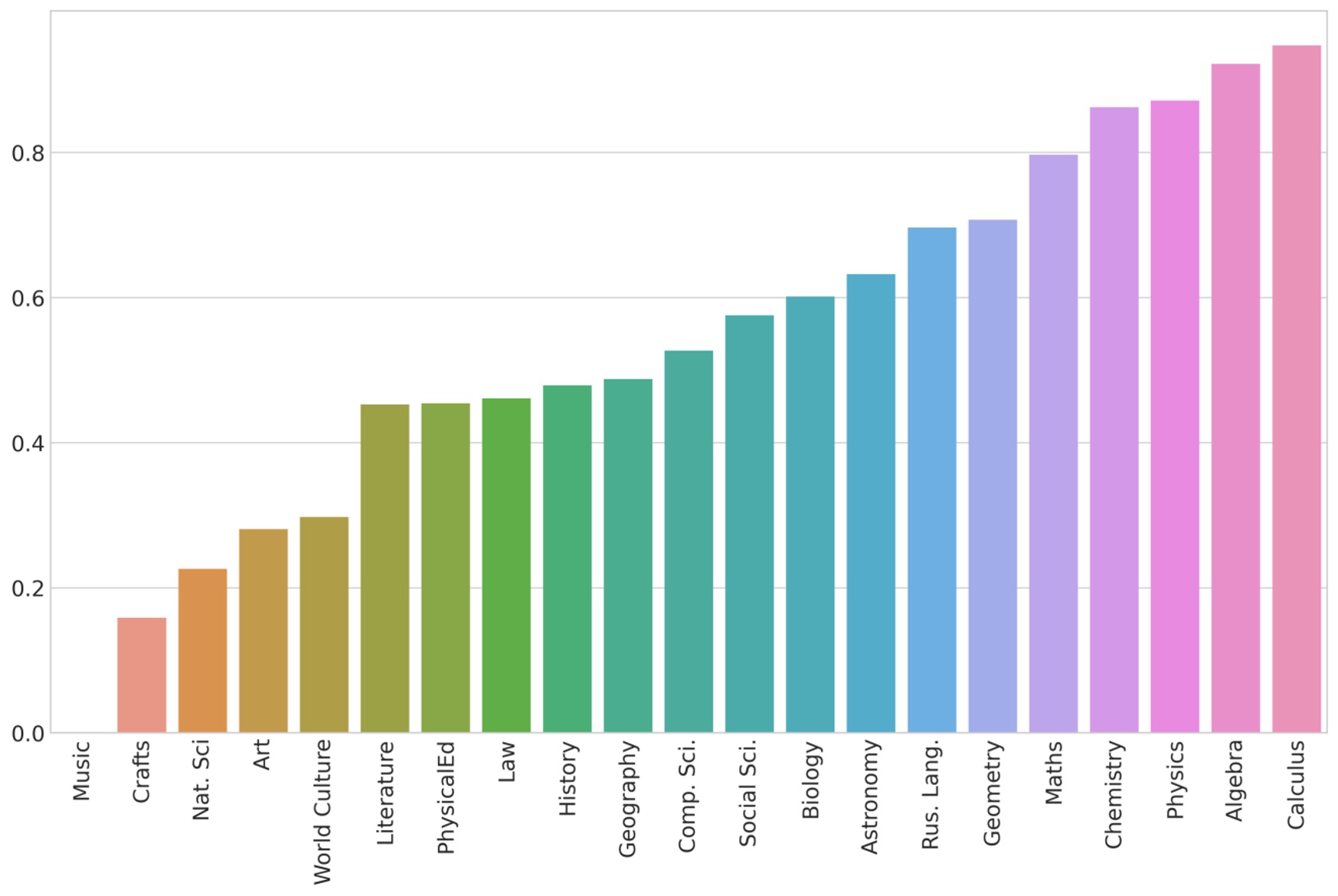
Интерпретация распределения, приведенного на рис. 3, не вполне тривиальна. Согласно использованным алгоритмам выделение терминологической лексики среди высокочастотных лексических единиц в учебнике обеспечивается (а) регулярным употреблением терминов в тексте, причем (б) таким употреблением, которое в синтагматическом плане сходно с употреблением терминологических единиц той же тематической группы. Несоблюдение первого из этих требований может привести к невыделению единицы в составе высокочастотной лексики в целевом корпусе, несоблюдение второго — к зачислению термина в группу лжетерминов.
Показательно в этом отношении парадоксальное на первый взгляд положение на данной шкале подкорпуса «Естествознание» (код Natsci), который формировался на основе учебников базового уровня для старшей школы, объединяющих сведения по физике, астрономии, химии, биологии. Малая доля терминов в этом подкорпусе, отграниченных от лжетерминов в ходе кластеризации семантических карт, объясняется не только облегченным терминологическим составом текста, но и самим характером употребления терминов: вынужденно беглый обзор проблематики соответствующих научных областей приводит к резкому ослаблению частотности терминологических единиц и отсутствию подобия в контекстуальном поведении терминологических групп.
Другим примером может служить подкорпус «Музыка». При кластеризации соответствующих семантических карт количество выделенных терминов оказывается здесь очень мало по сравнению с другими предметными подкорпусами, что свидетельствует о том, что группы терминов, автоматически выделенные при помощи метрики keyness score (в частности, названия музыкальных жанров — «кантата», «симфония», «сюита» и др.), не обнаруживают сходства в своем текстовом поведении и в конечном счете не попадают в число терминов.
Подобные ситуации возможны и в какой-либо части предметного подкорпуса, включающего лексику конкретного учебно-методического комплекса. Так, в учебно-методическом комплексе «Русский язык. 5–11 классы», созданном под общей редакцией Л. А. Вербицкой (М.; СПб.: Просвещение, 2019), в учебнике для 5 класса встречается сочетание «орфографический_правило», которое не определяется как термин именно в этом учебнике, но распознается в качестве такового в учебниках для 6 и 7 классов, где оно встречается с достаточной частотой и, что более важно, является частью терминологического кластера, включающего в себя такие единицы, как «орфограмма», «правописание_гласный», «правописание_приставка», «правописание_слово», «правописание_суффикс», «ударение», «условие_выбор_буква» и др.
Безусловно, высокие показатели присутствия терминологической лексики среди высокочастотных лексических единиц в учебнике указывают на значительную степень сложности соответствующих учебных текстов. С другой стороны, абсолютная сложность учебного текста, вызванная обилием терминов, в известном смысле компенсируется в плане трудности его усвоения благодаря регулярному и контекстуально систематизированному употреблению терминологических групп, образующих некоторое смысловое целое. И напротив — употребление терминов, не обнаруживающее должной меры частотности и/или контекстуального сходства с употреблением близких по смыслу единиц, может вызывать трудности при усвоении текста, хотя и уменьшает степень его абсолютной сложности.
3.2. Терминологические связи
В свете сказанного большое значение имеют терминологические связи и между разными частями одного учебника, и между разными учебниками в составе одного учебно-методического комплекса. Эти связи реализуют основополагающие для любого текста принципы проспекции и ретроспекции, которые в методике традиционно обозначаются как «опережающее обучение» и «повторение и закрепление пройденного». В первую очередь интересно оценить динамику накопления терминов и удельный вес того вклада, который учебники каждой ступени обучения вносят в формирование терминосистемы соответствующей учебной дисциплины. Алгоритмически решение этой задачи строилось так: 1) каждый учебно-методический комплекс был разбит на отрезки, соответствующие длине одного тематического раздела, в среднем по 1000 словоупотреблений каждый; 2) в каждом из этих отрезков было сосчитано количество терминов и терминологических сочетаний, относящихся к ранее выделенным терминосистемам разных ступеней обучения; 3) для каждого класса было подсчитано общее количество новых терминов, которые соответствующий учебник вносит в общую терминосистему учебно-методического комплекса; 4) для каждого тематического отрезка учебно-методического комплекса было подсчитано количество терминов из терминосистем всех представленных ступеней обучения.
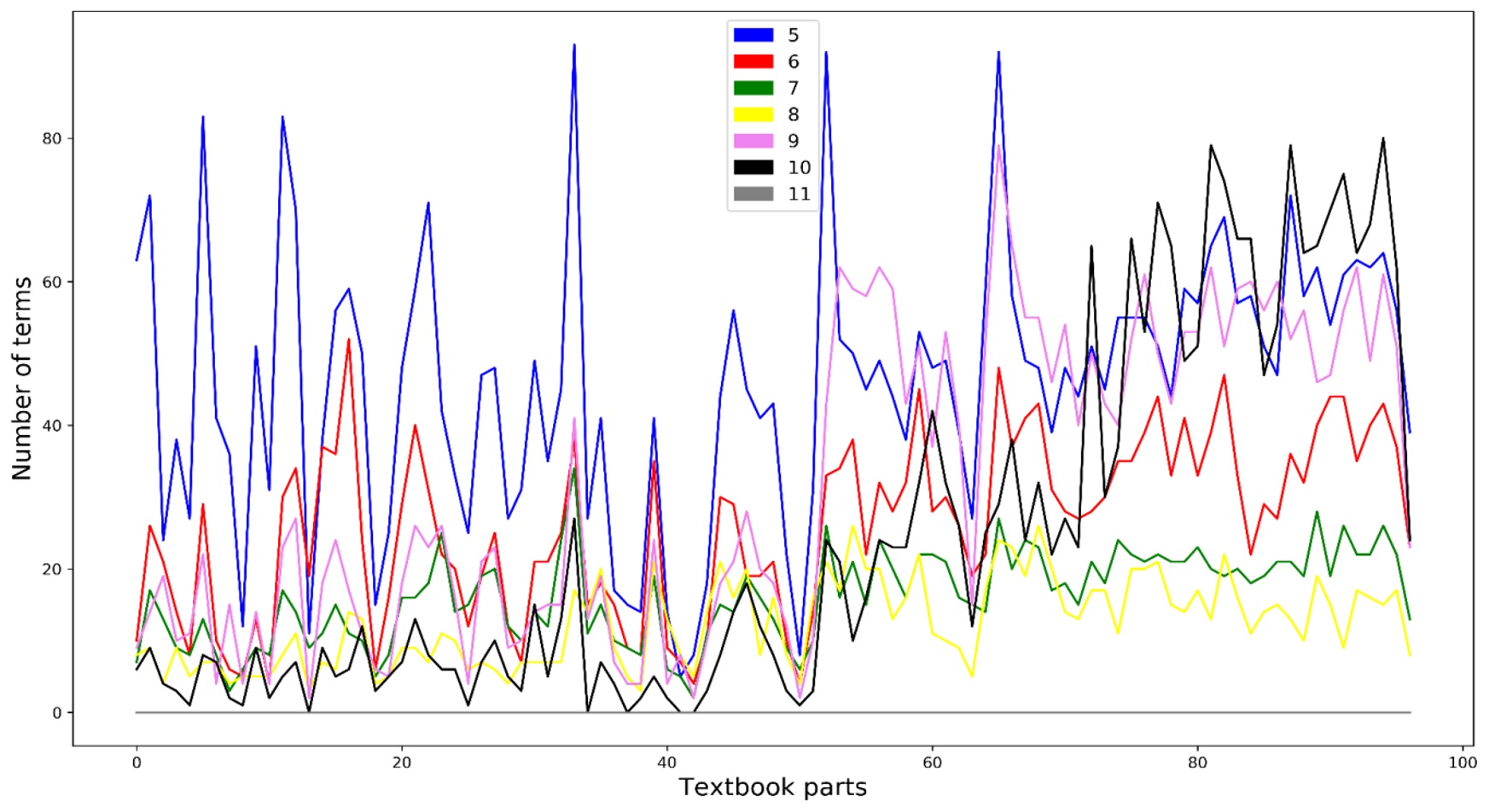
Ниже приведен пример динамики пополнения терминосостава в учебно-методическом комплексе «Русский язык» под ред. Л. А. Вербицкой: на рис. 4 показана доля новых терминов на каждой ступени обучения, на рис. 5 — изображена та же динамика с указанием на распределение терминоупотребления в разных частях учебника для каждого класса (учебники для 10–11 классов обозначены совместно цифрой 10).
Рисунок 4. Динамика пополнения терминосостава в учебно-методическом комплексе «Русский язык» под ред. Л. А. Вербицкой
Figure 4. The dynamics of new terms entering the terminology system of the teaching methodological package Russian Language edited by L. Verbitskaya
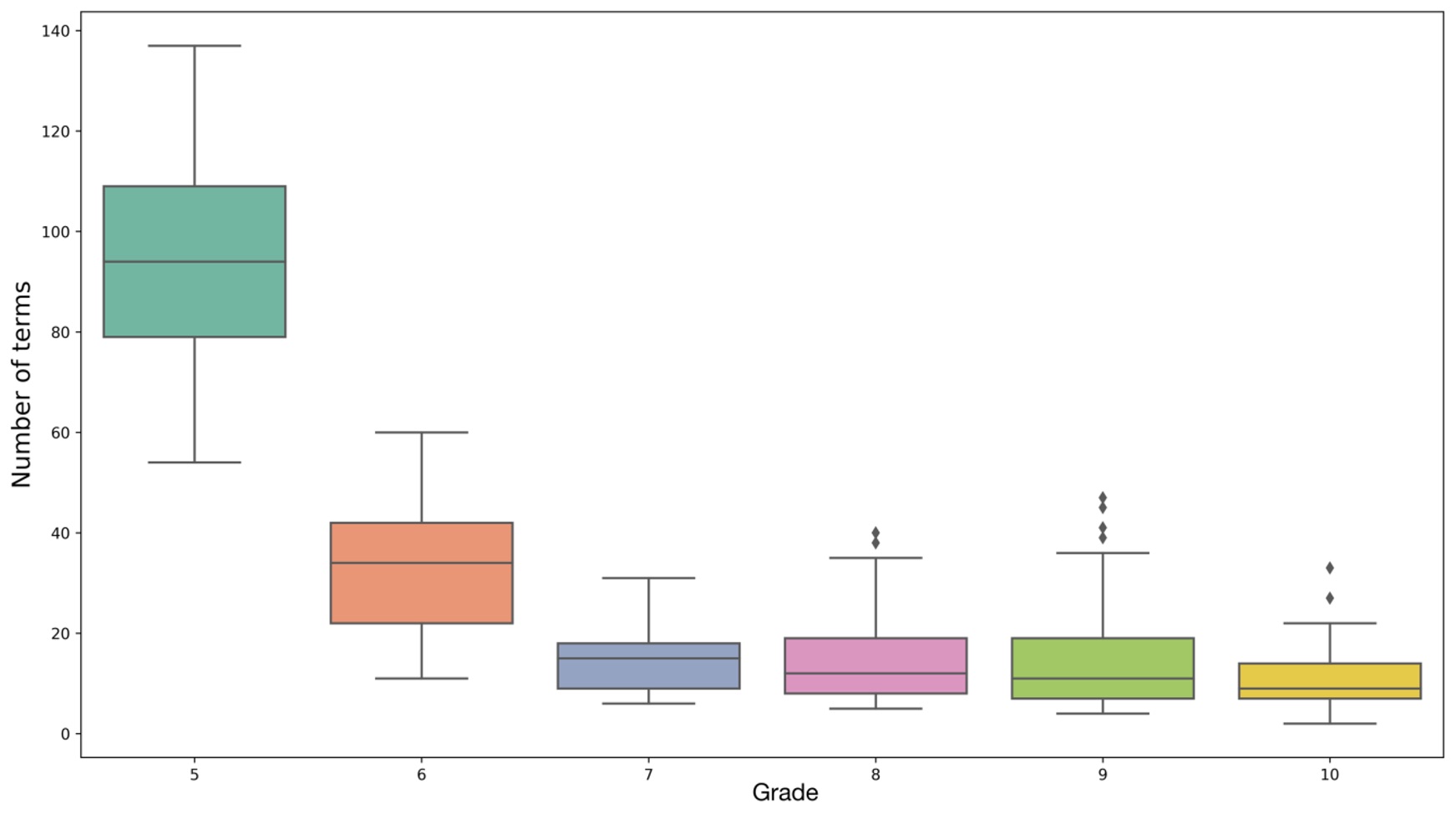
Рисунок 5. Динамика пополнения терминосостава в учебно-методическом комплексе «Русский язык» под ред. Л. А. Вербицкой с указанием на терминоупотребление в разных частях учебника
Figure 5. The dynamics of new terms entering the terminology system of the teaching methodological package Russian Language edited by L. Verbitskaya with the distribution of terms in different parts of textbooks for different grades
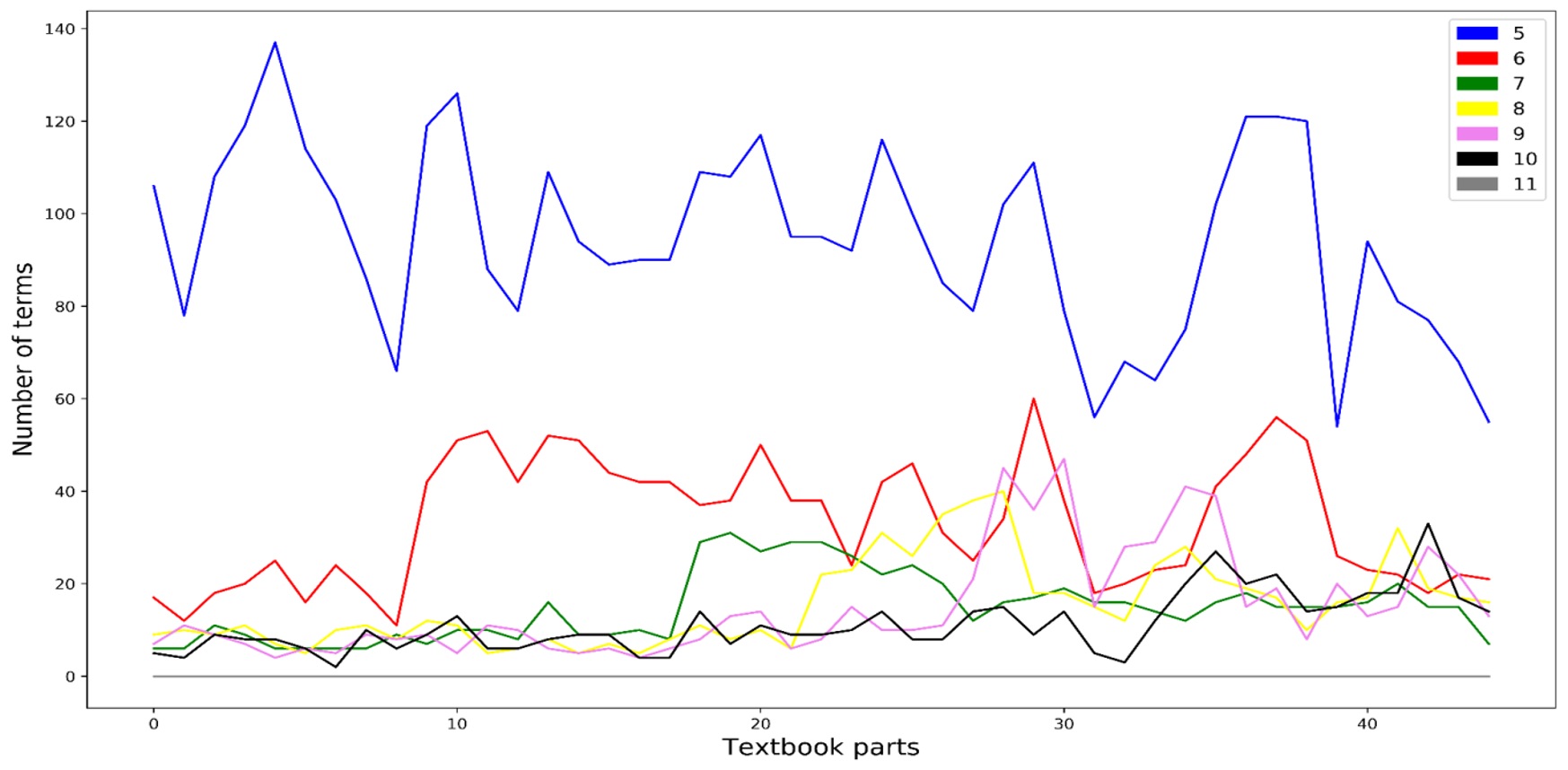
Как видно, учебник для 5 класса с большим отрывом лидирует по количеству терминов, представленных в каждом из выделенных отрезков учебно-методического комплекса. Иными словами, в основных чертах терминологическая картина данной области знания складывается уже на раннем этапе обучения, возвращение к ней происходит на всех последующих ступенях обучения. Учебники же для старших классов почти не вводят новой терминологии, что объясняется их нацеленностью в первую очередь на систематизацию и повторение.
Сопоставляя с этими результатами аналогичную визуализацию пополнения терминосостава в учебно-методическом комплексе по литературе В. Я. Коровиной и др. (5–9 классы), В. И. Коровина и др. (10–11 классы) (М.: Просвещение, 2013), можно отметить, что учебники по литературе для старшей школы формируют терминосистему, в значительной степени новую в отношении той, что была сформирована на предыдущих ступенях обучения (см. рис. 6). Различия между учебниками для старшей школы по русскому языку и литературе в отношении их вклада в пополнение терминосостава объясняются в числе прочего тем, первые являются учебниками базового уровня, тогда как вторые — профильного.
Рисунок 6. Динамика пополнения терминосостава в учебно-методическом комплексе по литературе В. Я. Коровиной и др. (5–9 классы), В. И. Коровина и др. (10–11 классы) с указанием на терминоупотребление в разных частях учебника
Figure 6. The dynamics of new terms entering the terminology system of the teaching methodological package Literature edited by V. Korovina et al. (grades 5–9) and V. Korovin et al. (grades 10–11) with the distribution of terms in different parts of textbooks for different grades
Распределение терминов по терминологическим кластерам разных ступеней обучения позволяет проанализировать также, насколько тесно связаны между собой отдельные учебники в рамках одного учебно-методического комплекса. Алгоритмически этот анализ был выстроен следующим образом:
1) для каждого термина учебной дисциплины t был определен набор терминологических кластеров {T5, T6, T7, T8, T9, T10-11}, к которым данный термин относится на соответствующей ступени обучения;
2) для каждой пары определенных терминологических кластеров была высчитана мера пересечения относящихся к ним терминов Ti ∩ Tj, i ≠ j;
3) полученные для каждого термина меры были сведены в общую матрицу следующего вида (на примере термина «морфема» в учебно-методическом комплексе по русскому языку под ред. Л. А. Вербицкой):
Таблица 1. Доля общих терминов в кластерах, содержащих термин «морфема», в учебно-методическом комплексе по русскому языку под ред. Л. А. Вербицкой
Table 1. General terms share in clusters with the term морфема (morpheme) in the educational and methodological complex Russian Language edited by L. Verbitskaya
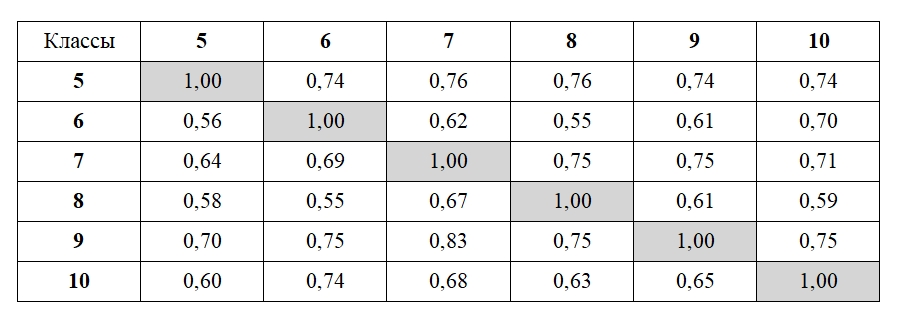
Матрица читается по строкам; цифры в ячейках, варьирующиеся в пределах [0,1], обозначают долю терминов в кластере, к которому отнесен термин t в учебнике Ti, совпадающих с терминами в кластере, к которому отнесен термин t в учебнике Tj;
4) из получившейся матрицы выбиралось максимальное значение — два максимально тесно связанных кластера в разных учебниках (в приведенной выше таблице это 0.83 — доля терминов в кластере, к которому отнесен термин «морфема», в учебнике для 9 класса, совпадающих с терминами в кластере, к которому отнесен термин «морфема», в учебнике для 7 класса);
5) пара учебников Ti и Tj, характеризующихся максимальной степенью пересечения записывалась в словарь forward_classes, если i < j, и в словарь backward_classes, если i > j; таким образом, словарь forward_classes содержал случаи катафорических повторов (терминосистема, представленная на более ранней ступени обучения, входит в состав расширенной терминосистемы, представленной на более поздней ступени обучения), тогда как словарь backward_classes содержал случаи анафорических повторов (терминосистема, представленная на более поздней ступени обучения, воспроизводит терминосистему, представленную на более ранней ступени обучения);
6) данные, полученные для отдельных терминов, входящих в состав учебно-методического комплекса, суммировались по парам классов.
Например, в учебно-методическом комплексе по русскому языку под ред. Л. А. Вербицкой наблюдается следующая иерархия соответствий классов (в круглых скобках до двоеточия даются порядковые номера ступеней обучения, при этом 10 и 11 классы обозначены совместно цифрой 10; цифра после двоеточия представляет собой количество уникальных терминов, показавших для данной пары учебников максимальную степень пересечения содержащих их кластеров; показатели упорядочены от большего к меньшему):
1) forward_classes — {(5, 6): 48, (7, 8): 46, (7, 10): 35, (5, 10): 26, (6, 10): 22, (7, 9): 21, (5, 8): 19, (8, 9): 19, (9, 10): 13, (5, 9): 9, (8, 10): 8, (5, 7): 7, (6, 9): 6, (6, 8): 4, (6, 7): 1},
2) backward_classes — {(10, 6): 62, (10, 9): 51, (9, 7): 44, (8, 6): 44, (7, 6): 36, (10, 8): 17, (10, 7): 10, (6, 5): 10, (7, 5): 8, (9, 8): 6, (8, 7): 6, (10, 5): 5, (9, 6): 5, (8, 5): 3, (9, 5): 1}.
Следует вывод, что в данном учебно-методическом комплексе наиболее тесно связаны между собой — в плане тематического развития — учебники для 5 и 6 классов, с одной стороны, и учебники для 7 и 8 классов, с другой стороны (наименее связаны учебники для 6 и 7 классов). В плане же повторения пройденного наиболее тесно связаны между собой учебники для 10 и 6 классов, с одной стороны, и учебники для 10 и 9 классов, с другой стороны (наименее связаны учебники для 9 и 5 классов).
3.3. Терминоупотребление в различных сферах
Еще одним результатом векторизации целевых корпусов (корпуса школьных учебников и корпуса научных статей) стала возможность проведения разноаспектного сопоставительного анализа употребления терминов в различных сферах. Ниже будет охарактеризован только один из аспектов подобного сопоставления, а именно сопоставление функционирования терминов в сфере школьной и научной литературы с терминоупотреблением в сфере общеупотребительного языка, в том числе в научно-популярных текстах[1].
Для решения поставленной задачи использовалась предоставляемая ресурсом RusVectōrēs модель ruwikiruscorpora-superbigrams_skipgram_300_2_2018, обученная на 600 миллионах словоупотреблений из Национального корпуса русского языка и Википедии за декабрь 2017 г. (далее — модель RusVectōrēs). Это единственная модель, в которой склеены все возможные биграммы продуктивных типов, независимо от их частотных характеристик. Способность модели распознавать биграммы является необходимым качеством, так как исследуемый нами терминологический состав включает как однословные, так и неоднословные терминологические единицы.
Дальнейшие действия были таковы:
1) была создана и обучена на материале объединенного корпуса школьных учебников и научной периодики новая дистрибутивно-семантическая модель Word2Vec, с размерностью векторов эмбеддинга равной 300 (далее — модель Корпуса). Это было необходимо, поскольку первоначально созданная модель имела размерность 32 и была несопоставима с моделью RusVectōrēs;
2) были отобраны векторные представления всех терминов объединенного корпуса, которые встречаются в словаре модели RusVectōrēs;
3) эти векторные представления были разделены на четыре группы: distance_textbooks_wiki (векторные представления терминов школьных учебников в модели RusVectōrēs), distance_textbooks (векторные представления терминов школьных учебников в модели Корпуса), distance_articles_wiki (векторные представления терминов научной периодики в модели RusVectōrēs), distance_articles (векторные представления терминов научной периодики в модели Корпуса);
4) внутри каждой из четырех групп были получены все возможные парные комбинации отнесенных к этой группе векторных представлений терминов и для каждой парной комбинации высчитана мера косинусной близости CS = u * v / (||u|| * ||v||), так что CS находится в пределах [0,1], где 1 обозначает идентичность векторов, а 0 — их ортогональность;
5) полученные для всех четырех групп данные были подвергнуты однофакторному дисперсионному анализу (ANOVA), чтобы определить соотношение систематической (межгрупповой) дисперсии к случайной (внутригрупповой) дисперсии в измеряемых данных. Высчитанная для каждой из четырех групп мера CSMi, i = 1,2,3,4 — среднее арифметическое всех парных мер косинусной близости — дает общее представление о том, насколько термины данной группы в среднем близки друг к другу в векторном пространстве, то есть в какой степени они образуют семантически спаянную группу;
6) для всех анализируемых областей знания были обнаружены статистически значимые отличия четыре групп мер косинусной близости. Поскольку дисперсионный анализ сам по себе не дает возможности ответить на вопрос, какие именно группы отличаются друг от друга, по его завершении были проведены апостериорные сравнения — попарные сравнения изучаемых групп с помощью критерия Тьюки.
Таким образом, при обобщении данных получаем четыре числовых показателя, характеризующих текстовое поведение: (а) терминов в школьных учебниках, (б) терминов в научной периодике, (в) терминов школьных учебников в общеупотребительной, научно-популярной сферах, (г) терминов научной периодики в общеупотребительной, научно-популярной сферах. Пример результатов, полученных для области знания «Русский язык / Лингвистика», дан на рис. 7: здесь видно, как степень семантической спаянности лингвистических терминов падает в направлении, во-первых, от специальных научных текстов к учебной литературе, а во-вторых, от учебной и научной сферы употребления языка к общеупотребительной и научно-популярной.
Рисунок 7. Сопоставление мер косинусной близости, указывающее на степень семантической спаянности терминов области знания «Русский язык / Лингвистика» в различных сферах употребления
Figure 7. Comparison of cosine similarity measures as indicators of semantic coherence of terms from the subject area Russian Language / Linguistics in different domains

Анализ данных по всем областям знания позволяет объединить их в четыре группы — в зависимости от обнаруженной закономерности:
0 < CSMdistance_textbooks_wiki < CSMdistance_articles_wiki < CSMdistance_textbooks < CSMdistance_articles < 1 — «Искусствознание», «География», «Информатика», «Музыковедение», «Физическая культура», «Русский язык / Лингвистика», «Обществознание»;
0 < CSMdistance_articles_wiki < CSMdistance_textbooks_wiki < CSMdistance_articles < CSMdistance_textbooks < 1 — «Астрономия», «История», «Право», «Литература»;
0 < CSMdistance_articles < CSMdistance_textbooks < CSMdistance_articles_wiki < CSMdistance_textbooks_wiki < 1 — «Биология»;
0 < CSMdistance_textbooks < CSMdistance_articles < CSMdistance_textbooks_wiki < CSMdistance_articles_wiki < 1 — «Химия», «Математика», «Физика».
Закономерным кажется то, что в модели RusVectōrēs термины научной периодики в большинстве сфер знания имеют более высокие показатели средней косинусной близости, чем термины школьных учебников, что говорит о том, что актуальная школьная терминология в целом обладает меньшим потенциалом автономной системности, чем собственно научная. Другой вывод является более неожиданным и в то же время более показательным. Чтобы обозначить его в более явном виде, целесообразно сократить число уровней с четырех до двух, объединив distance_textbooks_wiki и distance_articles_wiki, с одной стороны, и distance_textbooks и distance_articles, с другой. Тогда получаем:
0 < CSMdistance_textbooks+articles_wiki < CSMdistance_textbooks+articles < 1 —«Искусствознание», «География», «Информатика», «Музыковедение», «Физическая культура», «Русский язык / Лингвистика», «Обществознание», «Астрономия», «История», «Право», «Литература»;
0 < CSMdistance_textbooks+articles < CSMdistance_textbooks+articles_wiki < 1 — «Биология», «Химия», «Математика», «Физика».
Таким образом, выделяются ключевые сферы знания, относимые к точным и естественным наукам (биология, химия, физика, математика), которые противопоставлены остальным дисциплинам, в частности наукам общественно-гуманитарного цикла. Термины первой группы в модели RusVectōrēs характеризуются более высокими показателями средней косинусной близости, чем термины второй группы. Это свидетельствует о том, что термины точных и естественных наук при употреблении вне сферы учебной и научной литературы сохраняют и даже упрочивают свою семантическую близость, выступают как относительно цельная смысловая группа. Можно было бы сказать, что они сопротивляются давлению иной коммуникативной среды и жестко отсекают нетипичные для них сочетаемостные связи, замыкаясь в кругу регулярно повторяющихся контекстов. Термины общественных и гуманитарных наук, напротив, попадая в сферу общеупотребительного языка, теряют сходство в своём текстовом поведении и предстают как семантически распылённое облако. Они свободнее употребляются в контекстах, нетипичных для их терминологической природы, и быстрее детерминологизируются. Эти особенности текстового поведения терминов двух указанных групп в чуждой коммуникативной сфере в некотором роде объективируют понятие «знакомости» слова, которое с давних пор употребляется для оценки степени сложности текста, но, как правило, отвергается как ненадежный критерий в силу его субъективности. Термины точных и естественных наук, даже при употреблении за пределами специальных или учебных текстов, сохраняют свою групповую смысловую герметичность, что препятствует их стихийному семантическому и коммуникативному освоению. Термины общественных и гуманитарных наук, напротив, быстрее становятся «знакомыми», прежде всего в силу их более свободного употребления в лексически разнообразных контекстах.
Несоответствия отмеченным закономерностям (см., например, полученные данные для дисциплин «География», «Информатика», «Астрономия», а с другой стороны — для дисциплин «История», «Право», «Литература») требуют специального рассмотрения, от которого мы в данном случае отвлекаемся, ограничившись следующим замечанием. Причины, которые вызывают числовые отклонения от общей картины терминоупотребления, могут быть разными для разных сфер знания. Они могут быть связаны с комплексной природой дисциплины (например, география сочетает в себе черты естественных и общественных наук), или с малым объемом информации, обусловленным слабой представленностью дисциплины в школьном преподавании (это касается, например, астрономии), или, наконец, с существенной разнородностью автоматически выделенного терминологического состава определенной дисциплины, включающего большое число нетерминологических единиц. В последнем случае выявленные нарушения обнаруживаемых закономерностей носят диагностический характер и указывают на необходимость дальнейшего совершенствования методик автоматического вычленения терминов и машинного анализа характеристик их употребления.
4. Заключение
Использованные методы исследования терминоупотребления, основанные на принципах дистрибутивной семантики и алгоритмах Word2Vec, учитывают неслучайное, регулярное употребление терминов в сходных лексических контекстах. Тем самым появляется возможность анализировать текстовое поведение терминов как элементов терминосистем, образованных семантически связанными группами лексических единиц. В свою очередь это позволяет не только усовершенствовать результаты автоматического вычленения терминов из целевых корпусов, опирающегося на традиционный статистический подход, но и проследить на больших текстовых объемах за функционированием терминов в разных сферах знания. В отношении современных школьных учебников становится возможным, в частности, сопоставить терминологическую насыщенность учебных пособий по разным предметам — имея в виду как раз систематическое употребление терминологических групп; охарактеризовать состав высокочастотной нетерминологической лексики; рассмотреть динамику пополнения терминосистем как в пределах группы учебно-методических комплексов или одного из них, так и внутри конкретной учебной книги определенной ступени обучения; сопоставить в разных аспектах закономерности терминоупотребления в школьной, научной и неспециальной областях.
Полученные результаты могут представлять интерес для специалистов по автоматическому анализу текстов, по общей дидактике и методике отдельной области знания, по комплексологии.
Отметим, что эти результаты в одном случае могут вполне коррелировать с устоявшимися интуитивными представлениями о характере учебных текстов по той или иной дисциплине, но в другом — существенно уточнять их. Так, получает математическое обоснование общераспространенное представление о «сложности» и «строгости» точных и естественных наук. Подчеркнем, что в аспекте терминоупотребления эти качества обеспечиваются не просто обилием слов специальной семантики, но их жесткой контекстуальной и семантической сплоченностью, степень которой сохраняется и даже возрастает при употреблении вне основной сферы их бытования. С другой стороны, учебники по русскому языку и литературе, хотя и имеют, как считается, во многом общий предмет описания, существенно отличаются и степенью терминологической насыщенности, и мерой системности терминоупотребления, и особенностями пополнения терминологического состава при переходе от основной школы к старшей.
Обширность терминологического поля, частотность терминологической или нетерминологической лексики, безусловно, коррелируют с мерой сложности школьных учебных текстов. Однако объективные лексические показатели сложности вступают здесь в очень непростые и порой противоречивые отношения как с мерой трудности, так и с принципами дидактической эффективности школьного учебника. Например, выявленное лексико-тематическое однообразие языкового материала в школьных учебниках по русскому языку снижает меру сложности, как и меру трудности текста (лексическое разнообразие — один из факторов, повышающих меру сложности), и так или иначе способствует реализации дидактического принципа доступности. Между тем этот же фактор отрицательно влияет на формирование мотивации к обучению и противоречит дидактическим требованиям к современному учебнику обеспечить психологическое соответствие учебного материала возрастным и индивидуальным особенностям школьников. Нерегулярный и контекстуально разрозненный характер терминоупотребления во многих учебниках общественно-гуманитарного цикла снижает меру сложности текста, но при этом противоречит дидактическим принципам преемственности, последовательности и систематичности обучения, что отнюдь не способствует снижению меры трудности. Безусловно, дальнейшие исследования лексической сложности школьного учебного текста должны опираться и на оценку композиции как конкретной учебной книги, так и учебно-методического комплекса в целом, ибо характеристика соотношения сложности и трудности невозможна без учета динамики обновления терминологического состава и взаимодействия впервые вводимых и уже известных из предыдущего изложения терминов.
Изложенные результаты являются частью итогов проводимого исследования, направленного в конечном счете на формирование базы данных русской терминологической лексики, соответствующей содержанию среднего образования. Разработанные программные коды на языке Python позволяют воспроизвести все описанные алгоритмы на материале любого учебно-методического комплекса или иного терминологически насыщенного корпуса текстов. Все материалы и результаты исследования, включая корпусы текстов, таблицы терминов, программные коды, дистрибутивно-семантические модели, графики и семантические карты, помещены в научное хранилище открытого доступа[2].
[1] Другим важным аспектом такого сопоставления является сравнение семантических карт терминоупотребления в школьных учебниках и в текстах научной периодики, которое демонстрирует существенные отличия между этими двумя сферами бытования терминов, прежде всего в аспекте актуализации терминов того или иного раздела некоторой области знания, см. об этом (Монахов и др., 2022).
Благодарности
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 19-29-14032 мк «Изучение терминологических подсистем современных школьных учебников на русском языке с помощью моделей анализа семантики естественных языков Word2Vec и нейронных сетей».












Список литературы
Иомдин Б. Л., Морозов Д. А. Кто поймет «Незнайку»? Автоматическое определение сложности текстов для детей // Русская речь. 2021. № 5. С. 55–68. DOI: 10.31857/S013161170017239-1
Лапошина А. Н., Лебедева М. Ю., Берлин Хенис А. А. Влияние частотности слов текста на его сложность: экспериментальное исследование читателей младшего школьного возраста методом айтрекинга // Russian Journal of Linguistics. 2022. Т. 26. № 2. С. 493–514. DOI: 10.22363/2687-0088-30084
Лейчик В. М. Терминоведение: предмет, методы, структура. М.: ЛКИ, 2007. 256 с.
Лексический состав текстов учебников русского языка для младшей школы: корпусное исследование / Лапошина А. Н., Веселовская Т. С., Лебедева М. Ю., Купрещенко О. Ф // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной международной конференции «Диалог» (Москва, 29 мая — 1 июня 2019 г.). Вып. 18 (25). М., 2019. C. 351–363.
Лукашевич Н. В., Логачев Ю. М. Комбинирование признаков для автоматического извлечения терминов // Вычислительные методы и программирование. 2010. Т. 11. Вып. 4. С. 108–116.
Мартынова Е. В., Солнышкина М. И., Мерзлякова А. Ф., Гизатулина Д. Ю. Лексические параметры учебного текста (на материале текстов учебного корпуса русского языка) // Филология и культура. 2020. № 3 (61). С. 72–80.
Микк Я. А. Оптимизация сложности учебного текста: В помощь авторам и редакторам. М.: Просвещение, 1981. 119 с.
Митрофанова О. А., Захаров В. П. Автоматизированный анализ терминологии в русскоязычном корпусе текстов по корпусной лингвистике // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной международной конференции «Диалог» (Бекасово, 27–31 мая 2009 г.). Вып. 8 (15). М., 2009. С. 321–328.
Монахов С. И., Турчаненко В. В., Чердаков Д. Н. Школьная и научная терминология: корпусное исследование и кластеризация // Информатизация образования и методика электронного обучения: цифровые технологии в образовании. Материалы VI Международной научной конференции. Красноярск, 2022. Ч. 3. С. 228–233.
Морозов Д. А., Иомдин Б. Л. Критерии семантической сложности слова // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной международной конференции «Диалог» (Москва, 29 мая — 1 июня 2019 г.). Вып. 18 (25). М., 2019. Дополнительный том. С. 119–131.
Пиотровский Р. Г., Ястребова С. В. Статистическое опознание термина // Статистика текста / гл. ред. Р. Г. Пиотровский. Т. 1. Минск: Белорусский государственный университет, 1969. С. 249–259.
Солнышкина М. И. Определение уровня лексической сложности текстов: современное состояние проблемы // Сборник научных трудов X Юбилейной международной научно-практической конференции «Учитель. Ученик. Учебник (в контексте глобальных вызовов современности)», 19–20 ноября 2021. М., 2022. C. 20–24.
Солнышкина М. И., Макнамара Д., Замалетдинов Р. Р. Обработка естественного языка и изучение сложности дискурса // Russian Journal of Linguistics. 2022. Т. 26. № 2. С. 317–341. DOI: 10.22363/2687-0088-30171
Солнышкина М. И., Кисельников А. С. Сложность текста: этапы изучения в отечественном прикладном языкознании // Вестник Томского государственного университета. Филология. 2015. № 6 (38). C. 86–99. DOI: 10.17223/19986645/38/7
Соловьев В. Д., Солнышкина М. И., Макнамара Д. С. Компьютерная лингвистика и дискурсивная комплексология: парадигмы и методы исследований // Russian Journal of Linguistics. 2022. Т. 26. № 2. С. 275–316. DOI: 10.22363/2687-0088-30161
Степанова Д. В. Анализ методов автоматического выделения терминов из научно-технических текстов // Актуальные проблемы современной прикладной лингвистики. Минск: Минский государственный лингвистический университет, 2017. С. 62–67.
Татаринов В. А. Общее терминоведение: Энциклопедический словарь. М.: Московский Лицей, 2006. 528 с.
Шпаковский Ю. Ф. Оценка трудности восприятия и оптимизация сложности учебного текста (на материале текстов по химии): Автореф. … канд. филол. наук. Минск, 2007. 21 с.
Brownlee J. Deep Learning for Natural Language Processing: Develop Deep Learning Models for your Natural Language Problems. Vermont: Machine Learning Mastery Publ., 2017. 414 p.
Cabré M. T., Estopà R., Vivaldi J. Automatic Term Detection: A Review of Current Systems // Recent Advances in Computational Terminology / Bourigault D., Jacquemin Ch., L’Homme M.-C. (eds.). Amsterdam: John Benjamins Publ., 2001. Pp. 53–87. DOI: 10.1075/nlp.2.04cab
Durda K., Buchanan L. WINDSORS: Windsor Improved Norms of Distance and Similarity of Representations of Semantics // Behavior Research Methods. 2008. Vol. 40. Pp. 705–712. DOI: 10.3758/BRM.40.3.705
Fisher D., Frey N., Lapp D. Text Complexity: Stretching Readers with Texts and Tasks. Thousand Oaks, CA: Corwin Press, 2016. 216 p.
Flor M., Klebanov B., Sheehan K. Lexical Tightness and Text Complexity // Proceedings of the 2th Workshop of Natural Language Processing for Improving Textual Accessibility (NLP4ITA). Atlanta, 2013. Pp. 29–38.
Glazkova A., Egorov Yu., Glazkov M. A Comparative Study of Feature Types for Age-Based Text Classification // Analysis of Images, Social Networks and Texts. AIST 2020. Lecture Notes in Computer Science. Vol. 12602 / van der Aalst W. et al. (eds.). Cham: Springer Publ., 2021. Pp. 120–134.
Jones M. N., Mewhort D. J. K. Representing Word Meaning and Order Information in a Composite Holographic Lexicon // Psychological Review. 2007. Vol. 114. Pp. 1–37. DOI: 10.1037/0033-295X.114.1.1
Kilgarriff A., Jakubíček M., Kovář V. et al. Finding Terms in Corpora for Many Languages with the Sketch Engine // Proceedings of the Demonstrations at the 14th Conference the European Chapter of the Association for Computational Linguistics, 26–30 April, 2014. Gothenburg, 2014. Рр. 53–56. DOI: 10.3115/v1/E14-2014.
Korkontzelos I., Ananiadou S. Term Extraction // Oxford Handbook of Computational Linguistics / Mitkov R. (ed.). Oxford: Oxford University Press, 2014. Pp. 991–1012.
Kutuzov A., Kuzmenko E. WebVectors: A Toolkit for Building Web Interfaces for Vector Semantic Models // Analysis of Images, Social Networks and Texts. AIST 2016. Communications in Computer and Information Science. Vol. 661 / Ignatov D. et al. (eds.). Cham: Springer Publ., 2017. Pp. 155–161.
Levy O., Goldberg Y. Linguistic Regularities in Sparse and Explicit Word Representations // Proceedings of the Eighteenth Conference on Computational Natural Language Learning / Morante R., Yih S. W-t. (eds.). Proceedings of the Eighteenth Conference on Computational Natural Language Learning. Stroudsburg: Association for Computational Linguistic Publ., 2014. Pp. 171–180. DOI: 10.3115/v1/W14-1618
Mikolov T., Sutskever I., Chen K. et al. Distributed Representations of Words and Phrases and their Compositionality // Advances in Neural Information Processing Systems 26. 27th Annual Conference on Neural Information Processing Systems 2013. Red Hook: Curran Associates Publ., 2013. Pp. 3136–3144.
Mikolov T., Yih W. T., Zweig G. Linguistic Regularities in Continuous Space Word Representations // Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2013. Pp. 746–751.
Nokel M. A., Bolshakova E. I., Loukachevitch N. V. Combining Multiple Features for Single-word Term Extraction // Компьютерная лингвистика и интеллектуальные технологии: По материалам ежегодной международной конференции «Диалог» (Бекасово, 30 мая — 3 июня 2012 г.). Вып. 11 (18). М., 2012. С. 490–501.
Rohde D. L., Gonnerman L. M., Plaut D. C. An Improved Model of Semantic Similarity Based on Lexical Co-Occurrence // Communications of the ACM. 2006. Vol. 8. Pp. 627–633.
Schwanenflugel P. J. Why are Abstract Concepts Hard to Understand? // The Psychology of Word Meanings / Schwanenflugel P. J. (ed.). Hillsdale: Lawrence Erlbaum Associates Inc., 1991. Pp. 223–250.
Sharoff S. What Neural Networks Know about Linguistic Complexity // Russian Journal of Linguistics. 2022. Т. 26. № 2. С. 371–390. DOI: 10.22363/2687-0088-30178
Solovyev V. D., Ivanov V. V., Solnyshkina M. I. Assessment of Reading Difficulty Levels in Russian Academic Texts: Approaches and Metrics // Journal of Intelligent & Fuzzy Systems. 2018. Vol. 34 (2). Pp. 3049–3058. DOI:10.3233/JIFS-169489
Turney P. D., Pantel, P. From Frequency to Meaning: Vector Space Models of Semantics // Journal of Artificial Intelligence Research. 2010. Vol. 37. Pp. 141–188. DOI: 10.1613/jair.2934