
Сложность семантического поиска на родном и иностранном языке: анализ движений глаз
Aннотация
В статье обсуждаются актуальные проблемы распознавания слов на родном и иностранном языке. Представлены результаты экспериментального исследования, в котором русскоязычные и азербайджаноязычные испытуемые должны были решать задачу зрительного семантического поиска и обнаруживать слова русского языка в множественном массиве хаотично расположенных кириллических букв. Слова были спрятаны в буквенной матрице 15х15, они не выделялись пробелами, состояли из 6-7 букв, располагались либо горизонтально, либо вертикально; половина имела в своем составе повторяющиеся буквы, другая половина – нет. Каждая матрица включала в себя 10 слов с подсчитанным индексом эмоциональной валентности и частотности. Регистрировалось количество найденных стимулов и показатели движений глаз. Были выявлены эффекты знания языка, расположения слов в матрице, их частотности и буквенного состава. Слова, горизонтально расположенные, имеющие более высокую частотность и повторяющиеся буквы в своем составе, обнаруживались с большей вероятностью. Установленные закономерности имели сходную величину эффекта для обеих групп. Слабое влияние эмоциональной валентности было установлено только для азербайджаноязычных испытуемых. Показано, что поиск на родном языке был более результативным за счет использования более эффективных стратегий когнитивной обработки. Русскоязычные испытуемые использовали осознаваемо контролируемую стратегию, связанную с затратой ментальных ресурсов, отражающуюся в более длительных фиксациях и коротких саккадах. Азербайджаноязычные испытуемые применяли более хаотичную стратегию, охватывающую большее пространство поиска и реализующуюся за счет удлинения саккад и укорачивания фиксаций. Увеличение сложности задачи (в случае использования более низкочастотных лексем) приводила к изменению стратегий и использованию особых приемов идентификации слов, которые также различались в группах испытуемых.
Ключевые слова: Зрительный семантический поиск, Распознавание слов, Движения глаз, Родной и иностранный язык, Сложность когнитивной обработки
Введение
Проблема сложности и понимания текстов заинтересовала исследователей достаточно давно, при этом с самого начала обозначились два направления – поиск внешних объективных показателей сложности и установление ее субъективных характеристик (см. Hiebert, Pearson, 2014). В качестве объективных параметров выделяли частотность слов, состав слогов, длину предложений, ясность отельных частей текста и т.п., их количество могло доходить до 60 или даже большее индексов (Klare, 1984). Эти идеи легли в основу автоматических систем оценивания сложности текстов (Solovyev, Solnyshkina, McNamara, 2022), но многие авторы указывают на их недостатки, в частности, неоднократно подчеркивалось, что объективное определение сложности не совпадает (или недостаточно точно совпадает) с субъективными оценками читателей. Именно поэтому не оставляются попытки разработать субъективные или качественные критерии сложности текстов, для чего используются экспертные характеристики и создаются специальные стандартизированные опросники. Однако субъективные индексы отличает размытость и неопределенность. Стоит обратить внимание на то, что учащиеся сами не всегда в состоянии заполнять опросники по оценке сложности текстов и им требуется помощь учителей (Toyama, Hiebert, Pearson, 2016).
Когнитивный подход изменил взгляд на эту проблему, связав сложность поступающей информации с возможностями и характером ее обработки человеком (Gough, 1972). Сложность задачи (ее целей, содержания и контекста) здесь начинают рассматривать через призму ментальной работы. Например, в модели RAND в качестве факторов, определяющих понимание текста, кроме параметров самого текста и читающего его субъекта выделяется еще компонент познавательной деятельности, детерминированной заданными целями и осуществляющейся с помощью операций многоуровневой обработки (Snow, 2002). Способы и приемы такой активности могут быть обозначены как стратегии выполнения, эффективность которых зависят как от характеристик вербального материала, так и от знаний и опыта, а также с мотивационных установок и состояний субъекта. Процесс понимания неотделим и от социокультурного контекста, привычных социальных практик и представлений о мире.
В нашем исследовании мы постарались с помощью анализа движений глаз выявить особенности такой ментальной работы с лексическим материалом на родном и иностранном языке и описать характер тех сложностей, с которыми сталкиваются испытуемые. Задача, которую они решали, – зрительного семантического поиска – требовала обнаружить и распознать слова русского языка в хаотичном наборе кириллических символов. Способы и механизмы визуального распознавания слов являются одной из наиболее обсуждаемых тем в современной когнитивной науке (Adelman, 2012; Yap, Balota, 2015; Snell, Grainger, 2019). Предполагается, что процесс включает в себя несколько стадий от восприятия физических признаков к лексико-семантической ментальной репрезентации, от внешней формы к значению (Martin et al., 2017). С некоторыми оговорками распознавание слов можно рассматривать как единицу понимания текста. Мы осознаем, что работу с текстом нельзя свести к идентификации слов, в частности, иногда текст понимается, когда не все слова распознаны, и наоборот, распознавание всех слов не всегда приводит к полному проникновению в текст. Однако сам характер распознавания и уровни когнитивной обработки, включенные в этот процесс, могут быть соотнесены с постижением общего смысла текстового высказывания (Schotter, Payn, 2019), а выявление стратегий распознавания слов, установление связанных с этим трудностей могут лечь в основу дальнейшего анализа сложности текста с помощью движений глаз.
Технологии бесконтактной регистрации движений глаз все чаще используются для изучения процесса распознавания слов[1] (Holmqvist, Andersson, 2017). Основной объем собранных данных затрагивал процессы чтения, но здесь исследователи встречаются с рядом проблем, в частности, с тем, что у грамотных взрослых навыки чтения высоко автоматизированы, и это не позволяет вскрыть когнитивную архитектуру распознавания (Rayner, 2009; Leinenger & Rayner, 2017). В то же время, определение значений отдельно стоящих слов обычно, напротив, ограничивает количество рассматриваемых глазодвигательных параметров (Blinnikova, Izmalkova, 2016). Задача обнаружения слов в зашумленном контексте создает непривычный контекст и существенным образом затрудняет процессы считывания и распознавания лексем. В частности, она характеризуется более высоким уровнем скученности (crowding)[2], масса неразделенных проблемами букв конкурирует за ограниченные ресурсы переработки. Все это позволяет разавтоматизировать процесс чтения (Falikman, 2017) и получить больше информации о том, как выстраиваются процессы вербальной обработки и какие стратегии для этого используются.
Мы полагали, что нахождение лексем родного языка будет гораздо более простым делом, чем поиск на иностранном языке, что будет выражаться в большем количестве обнаруженных слов (Гипотеза 1). В исследовании принимали участие российские и азербайджанские студенты, при этом последние обучались в бакинском филиале МГУ имени М.В. Ломоносова на русском языке и знали его достаточно хорошо. Однако исследовательский вопрос заключался не только в том, чтобы установить превосходство родного языка над иностранным, но и выявить, за счет чего достигается данное преимущество, какие стратегии, способы и приемы используют группы испытуемых. Поэтому мы варьировали ряд параметров тестовых стимулов, усложняя решение задачи, и анализировали, как это будет менять процесс обнаружения и распознавания слов. При этом мы предполагали, что факторы будут по-разному влиять на результативность поиска и обнаружения слов на родном и иностранном языке (Гипотеза 2).
Одним из факторов, влияющим на распознавание слов, являются особенности их расположения на странице (Rabeson, Blinnikova, 2020). В нашем случае слова размещались в матрице либо горизонтально, либо вертикально. Горизонтальное расположение слов является привычным для всех индоевропейских и тюркских языков, поэтому мы предполагали, что и для одной, и для другой группы испытуемых более легким окажется считывание и распознавание горизонтально расположенных слов. Однако мы думали, что для русскоязычных испытуемых будет легче обнаруживать вертикально-расположенные слова, поскольку они обладают большим потенциалом поиска в целом.
Данные многочисленных источников связывают скорость и успешность распознавания с частотностью слов, их составом и длиной (Kinoshita, 2015; Yap, Balota, 2015; Blinnikova, Rabeson, Izmalkova, 2019). В нашем исследовании мы использовали слова с разным уровнем частоты встречаемости в письменных текстах и предполагали, что это будет оказывать влияние на детекцию слов, но по-разному для разных групп испытуемых. Резонно было допустить, что поиск и распознавание слов на иностранном языке более чувствителен к индексу частотности стимулов, чем поиск слов на родном языке. Что касается длины слов, то тестовые стимулы включали в себя от 6 до 7 букв, однако в матрицах встречались и короткие слова-дистракторы, которые нельзя было называть. Мы считали, что ошибочное называние коротких стимулов будет более характерно, для поиска на иностранном языке. Также мы проверяли предположение о влиянии буквенного состава на обнаружение слов. Для этого мы использовали достаточно редкий прием повтора букв (Norris,1984), полагая, что повторное использование одной и той же буквы в слове облегчит его обнаружение. Кроме объективных физических характеристик на распознавание слов гипотетически может влиять их семантика. В нашем исследовании использовались слова с разной эмоциональной окраской – положительной, отрицательной и нейтральной. Мы полагали, что положительная эмоциональность будет создавать дополнительную активацию для обнаружения и распознавания слов. Это предположение опиралось на данные о влиянии эмоциональной валентности слов на скорость их обнаружения (Kuperman et al., 2014; Gao, Shinkareva, Peelen, 2022).
Существует довольно много моделей распознавания слов (Norris, 2013; Rastle, 2016), но в итоге все выделенные механизмы идентификации сводятся к трем кластерам, в одном из которых слова конструируются и распознаются через суксессивное собирание буквенных цепочек, в другом - сохраняется возможность симультанного считывания целостной репрезентации слова[3], а в третьем распознавание опирается на выделение буквенных сочетаний (например, слогов). Можно также предположить, что освоение письменной речи приводит к переходу от побуквенного восприятия к считыванию слогов, как элементов сборки лексем, и в дальнейшем к вычленению слов целиком, как своеобразных иероглифических символов. В этом случае те, кто находится на более ранних этапах освоения языка, будут в большей степени использовать стратегии побуквенного чтения, в то время как более продвинутые носители с большей вероятностью будут опираться целостное восприятие слов. В качестве третьей гипотезы мы предполагали, что поиск и обнаружение слов на родном и иностранном языке будут отличаться используемыми стратегиями, которые можно выявить через анализ движений глаз (Гипотеза 3).
Основная часть
Цель работы заключается в сравнении результативности и стратегий зрительного семантического поиска на родном и иностранном языке.
MaterialsandMethods
Выборка: В исследовании приняло участие две группы испытуемых – студенты российских и азербайджанских университетов, всего 42 человека в возрасте от 18 до 25 лет (средний возраст – 20 лет). Группа российских испытуемых состояла из 18 человек (12 женщин и 6 мужчин), а группа азербайджанских испытуемых – из 24 человек (16 женщин и 8 мужчин). Группы были эквиваленты по возрасту и уровню образования, они отличались принадлежностью к культуре (российской и азербайджанской) и отношением к русскому языку. Для всех российских испытуемых русский язык был родным; для всех азербайджанских испытуемых русский язык был иностранным, на котором они учились в университете, изучали как минимум с первого класса школы и знали на уровне В2, С1.
Экспериментальная задача была создана на основе методики Гюго Мюнстерберга (см. Falikman, 2018), которая предполагает поиск и обнаружение слов, скрытых среди множества хаотично расположенных букв. Участникам исследования на короткое время предъявлялась буквенная матрица, в которой они должны были найти осмысленные лексические единицы. С одной стороны, такая задача имеет вид головоломки, а с другой, – представляет вариант информационного поиска, имеющего высокую значимость для современного человека. Поскольку испытуемые заранее не знали, какие слова они ищут, они должны были постоянно составлять (или выхватывать) буквенные последовательности и принимать решение – являются ли цепочки букв словами.
Стимульный материал: Для проведения эксперимента были сконструированы матрицы 15 х 15, заполненные буквами кириллицы, среди которых в каждой таблице располагалось 10 слов русского языка (см. Рисунок 1). Длина тестовых слов составляла 6 или 7 символов, они могли располагаться либо горизонтально, либо вертикально и различались частотностью употребления, наличием повторяющихся букв и семантической окраской. В матрицах иногда можно было обнаружить короткие слова или аббревиатуры из двух или трех букв, но инструкция запрещала испытуемым называть их. Половина слов имела в своем составе повторяющиеся буквы, а другая половина – нет. Частотность слов (ipm) определялась с помощью частотного словаря современного русского языка[4]. Характер семантической окраски устанавливался по показателю эмоциональной валентности, которая была специально оценена в предварительном исследовании (Блинникова, Марченко, Бадалова, 2014). Всего было подготовлено 7 матриц: одна использовалась для обучающей серии, шесть – для экспериментальной. Каждая матрица имела свой индекс частотности и эмоциональной валентности, которые вычислялись как средние значения для десяти включенных в нее слов. Экспериментальная последовательность включала две позитивных, две негативных и две нейтральных эмоционально окрашенных матриц. Одна из двух матриц в каждом блоке эмоциональной окраски имела более высокую, а другая более низкую частность.
Рисунок 1. Пример стимульной матрицы. Представлена матрица с высокочастотными позитивно эмоционально окрашенными словами
Figure 1. Example of a stimulus matrix with high-frequency emotionally positive words

Процедура исследования: Перед началом эксперимента испытуемые заполняли протокол, где указывал свое имя, возраст, образование и давал согласие на участие в эксперименте. Затем на экране монитора предъявлялась инструкция, объяснявшая цель и условия исследования. После этого запускалась пробная серия, в ходе которой участники должны были найти все слова в предъявленной матрице без временных ограничений. В ходе выполнения пробной серии испытуемым специально напоминали, что слова могут располагаться как горизонтально, так и вертикально, но не «по диагонали» или «лесенкой». Кроме этого подчеркивалось, что они должны искать «длинные слова», состоящие из 6-7 букв, и не обращать внимания на короткие лексемы, которые можно было иногда составить из предъявленного набора букв. Далее давалась основная инструкция, проводилась калибровка аппаратуры для регистрации движений глаз и предъявлялась экспериментальная серия, состоящая из шести матриц. Время экспозиции каждой таблицы составляло 40 секунд. Перед каждой матрицей на 1 секунду предъявлялся маскировочный стимул в виде фиксационной точки. Последовательность матриц менялась от испытуемого к испытуемого. Исследование проводилось с каждым испытуемым индивидуально.
Аппаратура: Аппаратура и программное обеспечения компании «SMI Gaze & EyeTracking Systems» было использовано для создания экспериментального дизайна, воплощения процедуры исследования. Движения и фиксации взора регистрировались с помощью установки SMI RED с частотой 500 Hz, в процессе записи голова тестируемого свободно перемещалась в пространстве 40 см x 40 см х 70 см. Допустимое расстояние до монитора составляло 60 см – 80 см. Данная аппаратура обеспечивает автоматическую калибровку записывающего устройства в пределах 10 секундного интервала, отклонения не превышают 0.4°; пространственное разрешение (RMS) составляет 0.03°, а возможный временной сдвиг – 6 мс. В дополнение к записи движений глаз применялась видео- и аудиозаписью поведения и вербальных ответов испытуемых.
Измеряемые показатели: Регистрировались следующие параметры: количество правильно и неправильно обнаруженных и названных лексем. Также фиксировались показатели движений глаз: 1) длительность и количество фиксаций, амплитуда и направление саккад для всей матрицы; 2) количество, общая и средняя длительность фиксаций, количество возвратных саккад в областях интереса, в качестве которых были выделены тестовые слова.
Обработка сырых данных: Первичная обработка проводилась с помощью программного обеспечения «BeGaze» c установленным минимальным порогом фиксации в 50 мс, и максимальной дисперсией в 50 пикселей. Все подсчитанные показатели проверялись на согласованность с нормальным распределением (критерий Колмогорова-Смирнова). Значимость различий между группам оценивалась с помощью дисперсионного анализа. Для статистического анализа данных применялся пакет SPSS’22.
Результаты и обсуждение
Основные показатели результативности поиска и обнаружения слов в двух группах испытуемых. Первый этап был посвящен анализу количества обнаруженных слов в матрицах. Всего было проанализировано 252 пробы для 42 испытуемых. Результативность поиска на родном языке была значимо выше, чем на хорошо изученном иностранном языке. В среднем российские студенты находили 2,99 (SD = 1,39), а азербайджанские 1,84 (SD = 1,23) слов в каждой матрице; преимущество составляло более чем одно слово. Различия были высокозначимые (F (1, 251) = 45,09; p<0,01). Вероятность обнаружения каждого слова составляла 0,3 для российской и 0,18 для азербайджанской выборки. Такой результат был ожидаемым: в большинстве исследований решение вербальных задач на родном языке по количественным, и качественным показателям превосходит решение задач на иностранном языке (see Rayner, 2009). В матрицах нужно было находить только длинные слова, состоящие из 6 или 7 букв. Длина тестовых слов отличалась незначительно и не оказывала значимого эффекта на их обнаружение. В азербайджанской выборке испытуемые время от времени находили короткие слова дистракторы (в среднем 0,37 для матрицы), в российской выборке этого практически не происходило (в среднем 0,06 для матрицы).
Также мы сравнили достижения двух групп испытуемых в зависимости от характеристик и расположения слов в матрице. Результаты представлены в Таблице 1. Различия между обнаружением слов на родном и иностранном языке были значимыми практически для всех экспериментальных условий. Это говорит о том, что фактор родного языка является существенным, его влияние проявляется независимо от частотности, состава, длины и семантической окраски слов. Исключением из этой закономерности оказался показатель обнаружения вертикально расположенных слов, только в этом случае различия между группами были незначимы: и азербайджанские, и российские испытуемые были примерно одинаково неуспешны (данные выделены в таблицы серым цветом).
Кроме фактора родного языка были выявлены еще некоторые эффекты. Значимое влияние на поиск, обнаружение и распознавание слов оказывает фактор их расположения (F (2, 250) = 32,93; p<0,01). Горизонтально расположенные слова обнаруживаются значительно легче, чем ориентированные вертикально. Интерпретация этого факта заставляет нас обратиться к рассмотрению навыков чтения, которые и на русском, и на азербайджанском языках формируются сходным образом. Чтение и в том, и в другом случае осуществляется в виде горизонтальных смещений взора, слева направо, лексема за лексемой, строка за строкой. В экспериментах, где похожую задачу решали японские испытуемые, было продемонстрировано их превосходство в данном компоненте (Rabeson, Blinnikova, 2020).
Таблица 1. Количество воспроизведенных слов в среднем по матрице и в зависимости от их расположения, частотности употребления, состава и эмоциональной валентности в двух группах испытуемых (серым цветом выделены незначимые различия)
Table 1. Number of words reproduced on average in the matrix depending on their location, frequency of use, letter set and emotional valence in two groups of subjects (Insignificant differences are highlighted in grey)
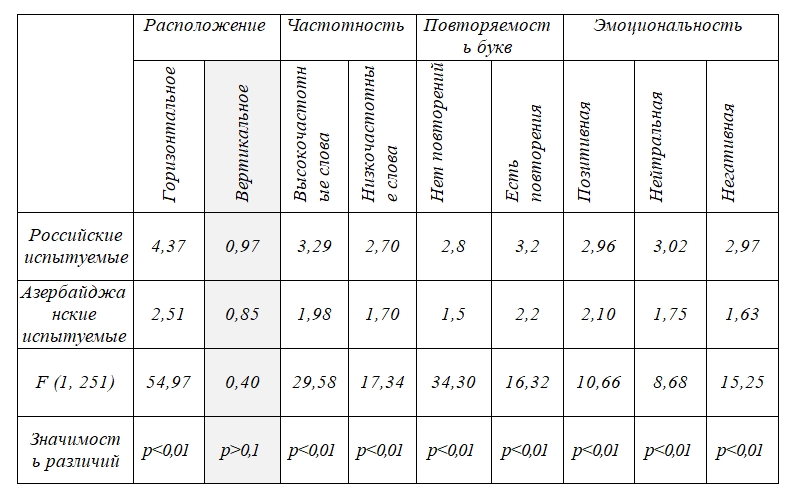
Другим значимым фактором оказался буквенный состав, который в нашем случае рассматривался через наличие повторяемых букв. Вероятность обнаружения слов, в которых буквы повторялись, была значимо выше, чем в словах, где такого не происходило (F (2, 250) = 11,44; p<0,01). В целом это подтверждает установленный ранее эффект взаимодействия распознавания слов и повторяемости букв (Norris, 1984). Влияние частотности постоянно подтверждается в экспериментах по распознаванию слов (Norris, 2013) и наши данные не были исключением: в матрицах с более высоким индексом частотности слов, стимулы находились с большей вероятностью (F (2, 250) = 5,74; p<0,05). Ни для одного из этих факторов не было установлено взаимодействия с фактором родного языка. Следовательно, и расположение, и повторяемость букв, и частотность слов оказывали одинаковое влияние на поиск и обнаружение слов как на родном, так и на иностранном языке. Такие результаты работали против нашей второй гипотезы.
Фактор семантической окраски слова не давал значимого эффекта. Из таблицы 1 можно видеть, что результаты российских испытуемых для матриц с эмоционально позитивными, негативными и нейтральными словами были практически одинаковыми. Однако для азербайджанской выборки это было не совсем так. В матрицах, включающих слова с позитивной коннотацией, азербайджанские испытуемые находили больше слов, чем в матрицах с негативной коннотацией. Различия были слабозначимыми, и мы можем их рассматривать только как тенденцию, требующей дальнейшей проверки (F (1, 143) = 2,30; p<0,1); подсчет был проведен только для азербайджанской выборки). По всей видимости, здесь проявляется эффект не столько знания языка, сколько социокультурного контекста. В ряде последних исследований было показано, что представители азербайджанской культуры в большей степени ориентированы на контекстные характеристики при восприятии разнообразных стимулов и решении задач (Арестова, Муслимзаде, 2018; Блинникова и др., 2021). В нашем случае влияние эмоциональности могло иметь только контекстный характер. Нахождение первого слова «открывало» испытуемым особенности матрицы, и они могли с большим или меньшим энтузиазмом продолжать поиск. Для русскоязычной выборки это не было значимо, но, хотя и слабо, влияло на азербайджанскую выборку.
Показатели движений глаз испытуемых относительно всей матрицы поиска. Сравнение основных показателей движений глаз в группах российских и азербайджанских испытуемых вызвало у нас удивление. Паттерн глазодвигательной активности российских студентов характеризовался более длительными фиксациями и короткими саккадами по сравнению с азербайджанцами (см. Рисунок 2 a, b). При этом межгрупповые различия были значимыми как для показателя средней длительности фиксаций (F (1, 251) = 4,41; p<0,5), так и для амплитуды саккад (F (1, 251) = 77,57; p<0,1). Полученные данные не соответствовали установленному правилу, гласившему, что развитие навыков чтения и знания языка ведет к сокращению времени фиксаций и увеличению амплитуды саккад (Rayner, 1998). У нас получалась обратная закономерность: испытуемые, лучше знающие язык, использовали более длительные фиксации и короткие саккады. Если учесть, что результативность обнаружения у русскоязычных испытуемых была выше, и не было сомнений в том, что для них задача была более простой, то эти данные могли быть интерпретированы только одним образом – русскоязычные испытуемые применяли особую стратегию, которая и приносила им успех.
Рисунок 2 а, b. Сравнение средней длительности фиксаций (a) и амплитуды саккад (b) в процессе поисковой активности на матрицах в двух группах испытуемых
Figure 2 a, b. Comparison of the average fixation duration (a) and the saccade amplitude (b) during search in matrices for two groups of subjects
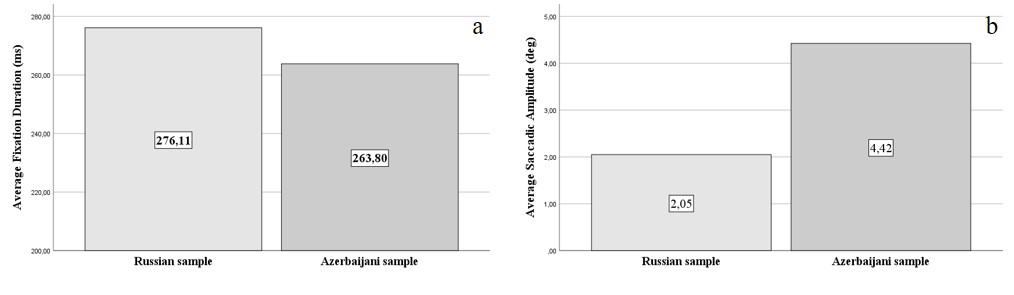
Предлагаемая задача не позволяла применять автоматизированные навыки чтения[5], и необходимо было перейти к совершенно другим способам работы с вербальным материалом. Русскоязычные испытуемые, работая с материалом родного языка, начинали применять более медленную, осознаваемо контролируемую стратегию, возможно с использованием ресурсов рабочей памяти для сохранения промежуточных результатов поиска и обнаружения слов. Это отражалось в более коротких саккадах и длительных фиксациях. Это соответствует ряду полученных ранее данных, демонстрирующих, что при усложнении текста сужается поле внимания и вербальная обработка становится более организованно последовательной (Schad, Engbert, 2012). Азербайджаноязычные испытуемые выбирали более быструю, хаотичную стратегию с достаточно поверхностной когнитивной обработкой, что приводило к удлинению сакаад и укорачиванию фиксаций.
Ранее уже были описаны когнитивные стратегии, которые применяются при распознавании слов. Д.Балота и Д.Силер (Balota, Sieler, 1999) выделили две такие стратегии – одна обеспечивает быструю обработку знакомого материала (fast-acting familiar-based process) а другая применяется в менее знакомых ситуациях и опирается на медленную обработку с подключением процессов осознанного внимания. В наших предыдущих исследованиях мы также выделили две сходные стратегии, которые соответствовали фокальной и амбиентной обработке, описанной Б. М. Величковским. Фокальная обработка обеспечивает выход на более глубокие уровни анализа информации и проявляется в более долгих фиксациях в сочетании с более короткими саккадами, Амбиентная обработка более поверхностна и направлена на более широкий охват наличной информации, она проявляется в сочетании более коротких фиксаций с протяженными саккадами (Velichkovsky et al., 2005). Знаменательно, что мы обнаружили сходные различия в стратегиях обработки образного материала между азербайджанской и российской выборками (Blinnikov et al., 2022).
Анализ показателей глазодвигательной активности для областей интереса (AOI). В качестве областей интереса были выделены тестовые слова. Анализ глазодвигательных показателей в тех зонах подтвердил выбор стратегий испытуемых. Для азербайджаноязычных испытуемых было характерно меньшее количество менее длительных фиксаций в областях интереса, где в итоге они проводили меньше времени (dwell time). Русскоязычные испытуемые продолжали использовать более медленную стратегию поиска, обнаружения и распознавания слов, задерживаясь на более долгий срок в областях интереса, но оказываясь и более успешными. Кроме длительности фиксаций группы отличались еще и показателем возвратов в области интересов, который был значимо выше в русскоязычной выборке вне зависимости от того было в итоге обнаружено слово или нет (см. Таблицу 2).
Таблица 2. Основные показатели движений глаз испытуемых в областях интереса для обнаруженных и необнаруженных стимулов (серым цветом выделены незначимые различия)
Table 2. Main indices of eye movements of subjects in the areas of interest for detected and non-detected stimuli (Insignificant differences are highlighted in grey)
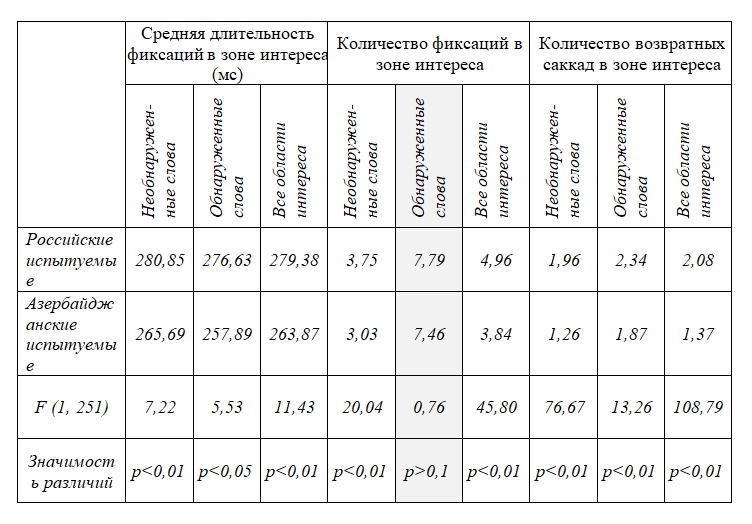
Тот факт, что русскоязычные испытуемые с упорством возвращались в зоны расположения тестовых стимулов еще до того, как они были обнаружены, свидетельствует о том, что перед окончательной идентификацией слова возникает предощущение его существования, и это неявное чувство заставляет возвращаться к интуитивно выделенной области[6]. Похожие данные были ранее получены в работе Б.М.Величковского и его сотрудников (Velichkovsky et al., 1995). Их испытуемые должны были сравнивать ряды стимулов, расположенных по обе стороны экрана, с целью обнаружения различий. Было установлено, что сканирование пространства протекало без регрессионных саккад до появления первичной догадки о расхождении в списках. После этого выделенные критические области начинали пристально изучаться с помощью возвратных движений глаз до окончательного установления отличающихся элементов. Феномены такого рода были описаны и в обосновании модели «захвата цели» (Zelinsky, 2008), где предполагается, что управление поисковыми движениями осуществляется поэтапно: сначала выделяются значимые участки с высокой вероятностью обнаружения целей, а затем они «прочесываются» более тщательно.
По всей вероятности, испытуемые, для которых русский зык является родным, обладают большими возможностями опираться на неявные репрезентации объекта, создавать «карты потенциальных целей» и использовать их для решения задач. Возникновение таких предвосхищающих конструктов ведет, с одной стороны, к большим временным затратам (что отражается в увеличении длительности фиксаций), а с другой, – к желанию вернуться в область потенциального стимула (что ведет к возрастанию числа регрессионных движений глаз). Это подтверждалось тем, что для русскоязычных испытуемых количество фиксаций относительно каждой клетки в этих областях была значимо выше, чем количество фиксаций относительно клеток матрицы, в которых не было слов. Для азербайджаноязычных испытуемых таких закономерностей установлено не было. Существование и механизмы использования подобных имплицитных репрезентаций ранее обсуждалось в ряде работ (Craik, Rose, Gopie, 2015; Flusser, Kautsky, Šroubek, 2007). Вполне возможно, что механизм создания некой вероятностной репрезентации действует и в более естественной ситуации чтения, создавая потенциальное поле для распознавания слов (см., например, Hyönä, 2021).
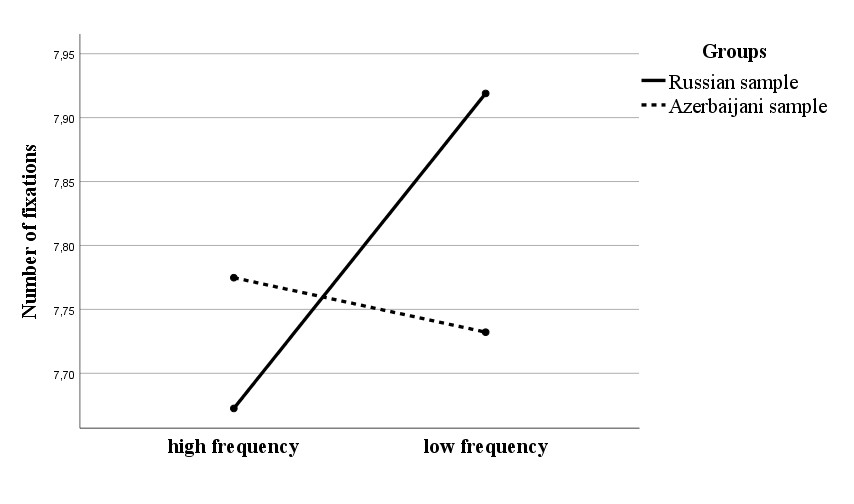
Различия в показателях движений глаз в зависимости от сложности идентификации лексем. На основе результативности распознавания слов мы сделали вывод о том, что ряд условий задавали значимо более высокую сложность задаче, чем другие. Так мы установили, что более высокий индекс частотности, наличие повторяющихся букв, горизонтальное расположение повышают вероятность обнаружения и распознавания слов. Мы решили проверить, влияют ли эти факторы на параметры движения глаз испытуемых так же как они влияют на результативность. Наиболее интересные результаты были получены для показателя средней длительности (Рисунок 3) и количества (Рисунок 4) фиксаций в зонах интереса, включающих идентифицированные слова (всего 527 случаев). Проведя двухфакторный дисперсионный анализ, мы обнаружили эффекты влияния фактора родного языка и уровня частотности слов на показатель средней длительности фиксаций в зоне интереса идентифицированных слов, а также взаимодействия двух факторов.
На Рисунке 3 можно видеть, что при возрастании сложности задачи в ситуации распознавания менее частотных слов происходят изменения в характере обработки информации и в одной, и в другой группе испытуемых. Результаты двухфакторного дисперсионного анализа продемонстрировали значимость фактора языковой группы (F (2, 525) = 4,84; p<0,05) и взаимодействия фактора языковой группы и частотности слов (F (2, 525) = 6,74 ; p=0,01). У азербайджанских студентов фиксируется увеличение средней длительности фиксаций при практически неизменном количестве фиксаций. Такой результат является типичным в ситуациях усложнения условий задачи и усиления когнитивной нагрузки (ссылка). В данном случае при работе с низкочастотными словами азербайджанским испытуемым требуется больше времени для нахождение ментальной репрезентации более редкого стимула.
Рисунок 3. Различия в средней длительности фиксаций в области интереса идентифицированных слов в зависимости от фактора частотности и уровня знания языка
Figure 3. Differences in the average fixation duration in the area of interest with identified words depending on the frequency factor and language knowledge
Результаты российской выборки являются в некотором роде парадоксальными: повышение сложности приводит к появлению более коротких фиксаций и, следовательно, к более быстрой обработке. Эти результаты можно понять и объяснить, только с учетом общей стратегии, которую применяют испытуемые, и наличия у них возможности опираться на предварительные смутные репрезентации.
Рисунок 4. Различия в количестве фиксаций в области интереса идентифицированных слов в зависимости от фактора частотности и уровня знания языка
Figure 4. Differences in the number of fixations in the area of interest with identified words depending on the frequency factor and language knowledge

Если в случае высокочастотных слов для подтверждения возникающих предположений о наличии слова они могут использовать так называемые «чанки», информационные блоки[7], опирающиеся на сочетания букв, то в случае низкочастотных слов проверка требует побуквенного перебора. Это подтверждается и тем, что уменьшение длительности фиксаций при работе в усложненных условиях сочетается в русскоязычной выборке с возрастанием количества фиксаций (см. Рисунок 4), хотя уровень различий был не очень высоким (F (2, 525) = 2,21; p = 0,01).
Заключение
В результате проведенного исследования был установлен ряд существенных фактов. Прежде всего, были получены сведения о возможностях поиска и обнаружения слов среди множества хаотично расположенных букв, на родном и иностранном языке. Задача, которую мы предложили испытуемым, была очень сложной по сравнению, прежде всего, с задачами чтения: в пространстве обнаружения слов отсутствовали привычные маркеры начала и конца лексемы, слова располагались как горизонтально, так и вертикально, велико было давление интерферирующих стимулов. В таких условиях успешность испытуемых была не очень высокой: вероятность обнаружения слова на родном языке равнялась 0,29, а на иностранном 0,18. При этом русскоязычные испытуемые значимо превосходили азербайджаноязычных по количеству найденных слов.
Были выявлены и дополнительные факторы влияния на результативность зрительного семантического поиска. Наибольший эффект оказывал фактор расположения слов: горизонтально расположенные слова идентифицировались с большим успехом, чем вертикально расположенные слова. При этом если в обнаружении горизонтально расположенных слов русскоговорящие испытуемые почти в два раза превосходили азербайджаноговорящих испытуемых, то в извлечении вертикально расположенных слов группы значимо не отличались. Хотя задача не позволяла использовать навыки чтения в полном объеме, они все-таки выступали опорой для организации поиска. Был выявлен и эффект частотности: слова с большей частотой встречаемости успешнее идентифицировались. Эта закономерность проявлялась для поиска слов как на родном, так и на иностранном языке и свидетельствовала о наличии единых механизмов распознавания слов в разных условиях. Кроме этого было продемонстрировано влияние фактора повтора букв: если слова включали повторяющиеся символы, они отыскивались с большей вероятностью. По всей видимости, в предлагаемой задаче расположение двух одинаковых букв в достаточной близости друг от друга является хорошей подсказкой для обнаружения тестовых стимулов.
Не удалось установить влияние эмоциональной валентности на результативность обнаружения слов. Мы полагали, что положительно эмоционально окрашенные слова будут распознаваться с большей вероятностью, но этот эффект очень слабо проявлялся только для азербайджанской выборки. Для русскоязычных испытуемых этот фактор был абсолютно незначим; процент обнаруженных слов для матриц с разной эмоциональной валентностью был примерно одинаковым. Такие различия могут быть связаны с культурными детерминантами. Восточные культуры, к которым по некоторым данным тяготеет и азербайджанская, более чувствительны к контексту, в отличии от западных культур, к которым ближе оказываются российские испытуемые. В нашем случае эмоциональная валентность могла оказывать влияние только через создание своеобразного контекста некоторого эмоционального поля, и оказалось, что для представителей азербайджанской культуры это имеет значение.
Мы обнаружили, что в заданных сложных условиях распознавания слов испытуемые, осуществляющие поиск на родном и иностранном языке, применяют разные стратегии. Этот вывод мы сделали на основе анализа показателей движений глаз. Привычные навыки чтения здесь дают сбой, и, возможно, осознание этого факта приводят русскоязычных испытуемых, работающих с материалом родного языка, к переходу к более осознанно контролируемым медленным стратегиям вычленения и идентификации лексем. При этом азербайджаноязычные испытуемые, решающие задачу на иностранном языке, шли совершенно другим путем, их стратегия носила более стихийный и поверхностный характер, а поисковые движения были более хаотичными. Пока трудно ответить на вопрос, почему исследуемые выборки обращались к таким разным стратегиям, оказывали ли здесь влияние факторы знания языка или культурные традиции. Ответ на этот вопрос придется искать в будущих исследованиях.
Полученные результаты дали нам возможность говорить о том, что обнаружение слов среди массива хаотично расположенных букв включает в себя имплицитную обработку вербальных стимулов и создание предварительных неявных репрезентаций слов, которые либо обретают явную форму, либо нет. Это проявляется, в частности, в том, что фиксации и саккады «тяготеют» к зонам интереса, в которых располагаются «спрятанные» слова, даже если они не распознаются. Наши данные продемонстрировали, что подобная имплицитная обработка в большей степени доступна испытуемым, решающим задачу на родном языке. Об этом говорит ряд установленных закономерностей. В частности, русскоязычные испытуемые чаще возвращались в область скрытых стимулов и в итоге идентифицировали слова, это во многом было основой их успеха. Кроме этого, ряд данных показал, что перед называнием слова, носители русского языка, скорее перепроверяли предварительные предположения, чем внезапно извлекали слова. Испытуемые, знающие русский как иностранный, не обладают такими возможностями в полном объеме. Они стараются «наткнуться» и «выхватить» слова из хаотичной канвы букв, но взгляд их в большинстве случае проскальзывает мимо тестовых стимулов, им не удается эффективно использовать буквенные сочетания («чанки») и опираться на предварительно создаваемые неявные репрезентации, что, в конечном итоге, ограничивает возможности обнаружения и распознавания букв.
[1] Ряд исследователей утверждают, что движения глаз не просто сопровождают распознавание слов, но и являются необходимым условием этого процесса. Так при неподвижном взоре испытуемым нужно больше времени для называния слов и вынесения лексического решения (Schotter, Payn, 2019).
[2] В последнее время проблема ограничений переработки информации, связанной с скученностью буквенных элементов, рассматривается как одна из центральных в определении сложности процессов чтения и распознавания лексического материала (Grainger, Dufau, Ziegler, 2016).
[3] В современных моделях постулируется, что в этом случае используется параллельная обработка букв (Grainger, Dufau, Ziegler,2016).
[4] Ляшевская О. Н., Шаров С. А. (2009) Частотный словарь современногорусского языка (на материалах Национального корпуса русского языка), издательский центр «Азбуковник», Москва.
[5] К сходному выводу пришли и другие исследования. М. Фаликман показала, что использование подобной задачи разрушает автоматизированные системы считывания слов (Falikman, 2017).
- Ранее нам уже удалось показать при решении той же самой задачи, что саккады и фиксации не были распределены равномерно по матрице, они группировались вокруг как обнаруженных, так и необнаруженных слов (Grigorovich, Blinnikova, Izmalkova, 2014).
[7] О роли «чанков» в запоминании и распознавании слов см. статью Д. Норриса и К. Калма (Norris, Kalm, 2021).












Список литературы
Арестова О. Н., Муслимзаде П. З.Культурное своеобразие процессов общения (на примере азербайджаноязычных и русскоязычных жителей г. Баку) // Вопросы психологии. 2018. № 3. С. 87–94.
Блинникова И. В., Марченко О. П., Бадалова Ф. Поиск эмоционально окрашенных слов в буквенной матрице // Когнитивное моделирование: Труды Второго Международного форума по когнитивному моделированию / Под ред. В. Д. Соловьева, В. Н. Полякова, С. И. Масаловой. В 2-х частях. 2014. Ч. 1. С. 31–36.
Блинникова И. В., Блинников Г. Б., Бобков А. Н., Алиева А. Э. Кросс-культурные различия в оценках эмоциогенных изображений: Сравнение российской и азербайджанской выборок // Вестник РГГУ. 2021. № 1. С. 15–25. DOI: 10.28995/2073-6398-2021-1-28-50
Adelman J. S. (ed.) Visual Word Recognition. Volume 2: Meaning and Context, Individuals and Development. Hove: Psychology Press, 2012. 264 p.
Balota D. A., Spieler D. H. Word frequency, repetition, and lexicality effects in word recognition tasks: Beyond measures of central tendency // Journal of Experimental Psychology: General. 1999. V. 128 (1). P. 32–55. https://psycnet.apa.org/doi/10.1037/0096-3445.128.1.32
Blinnikov G., Rabeson M., Blinnikova I. Cross-cultural differences in strategies of complex images visual search // Perception. 2022. V. 51 (Supl.1). P. 42.
Blinnikova I., Izmalkova A. Eye movement evidence of cognitive strategies in SL vocabulary learning// Smart Innovation, Systems and Technologies 2016. V. 57. P. 311–323. https://link.springer.com/chapter/10.1007/978-3-319-39627-9_27
Blinnikova I., Rabeson M., Izmalkova A. Eye movements and word recognition during visual semantic search: differences between expert and novice language // Psychology in Russia: State of the Art. 2019. V. 12 (1). P. 129–146. https://doi.org/10.11621/pir.2019.0110
Craik F. I., Rose N. S., Gopie N. Recognition without awareness: Encoding and retrieval factors // Journal of Experimental Psychology: Learning, Memory, and Cognition. 2015. V. 41 (5). P. 1271–1281. DOI: 10.1037/xlm0000137
Falikman M. Visual search in large letter arrays containing words: Are words implicitly processed during letter search? // Journal of Vision. 2017. V. 17 (10). P. 76. https://doi.org/10.1167/17.10.76
Flusser J., Kautsky J., Šroubek F. Object Recognition by Implicit Invariants // In: W. G. Kropatsch, M .Kampel, A. Hanbury (eds.) Computer Analysis of Images and Patterns: Lecture Notes in Computer Science (4673). Berlin, Heidelberg: Springer, 2007. P. 856-863. https://link.springer.com/chapter/10.1007/978-3-540-74272-2_106
Gao C., Shinkareva S. V., Peelen M. V. Affective valence of words differentially affects visual and auditory word recognition // Journal of Experimental Psychology: General. 2022. V. 151 (9). P. 2144–2159. https://doi.org/10.1037/xge0001176
Gough P. B. Theoretical models and processes of reading // In: J. F. Kavanagh, I. G. Mattingly (eds.), Language by Ear and by Eye. Cambridge: MIT Press, 1972. P. 661-685.
Grainger J., Dufau S., Ziegler J. C. A Vision of Reading // Trends in Cognitive Sciences. 2016. V. 20 (3). P. 171–179. DOI: 10.1016/j.tics.2015.12.008
Grigorovich S., Blinnikova I., Izmalkova A. Strategies of space scan in the process of visual semantic search // In: S. V. Doloviev, V. N. Poliakov, S. I. Masalova (eds.) Cognitive Modeling. Rostov-on-Don: Southern Federal University Press, 2014. P. 49–53.
Hiebert E.H., Pearson P. D. Understanding Text Complexity: Introduction to the Special Issue // The Elementary School Journal. 2014. V. 115 (2). P. 153–160. https://doi.org/10.1086/678446
Holmqvist K., Andersson R. Eye tracking: A comprehensive guide to methods, paradigms and measures. Lund: Lund Eye-Tracking Research Institute, 2017. 560 p.
Hyönä J., Heikkilä T. T., Vainio S., Kliegl R. Parafoveal access to word stem during reading: An eye movement study // Cognition. 2021. V. 208. Article 104547. https://doi.org/10.1016/j.cognition.2020.104547
Kinoshita S. Visual word recognition in the Bayesian Reader framework // In: A.Pollatsek, R. Treiman (eds.) Oxford Handbook of Reading. Oxford: Oxford University Press, 2015. P. 63–75. https://psycnet.apa.org/record/2015-46178-005
Klare G. R. Readability. In: P. D. Pearson, R. Barr, M. Kamil, P. Mosenthal (eds.) Handbook of reading research. Volume 1. New York: Longman, 1984. P. 681–744.
Kuperman V., Estes Z., Brysbaert M., Warriner A. B. Emotion and language: Valence and arousal affect word recognition // Journal of Experimental Psychology: General. 2014. V. 143 (3), P. 1065. DOI: 10.1037/a0035669
Latanov A. V., Anisimov V. N., Chernorizov A. M. Eye movement parameters while reading show cognitive processes of structural analysis of written speech // Psychology in Russia: State of the Art. 2016. V. 9 (2). P. 129-137. DOI: 10.11621/pir.2016.0210
Leinenger M., Rayner K. What we know about skilled, beginning, and older readers from monitoring their eye movements // In: J. A. León, I. Escudero (eds.) Reading Comprehension in Educational Settings. Amsterdam: John Benjamins, 2017. P. 1–27. DOI: 10.1075/swll.16.01lei
Martin R. C., Tan Y., Newsome M. R., Vu H. Language and Lexical Processing // Reference Module in Neuroscience and Biobehavioral Psychology. Amsterdam: Elsevier, 2017. P. 631–643. DOI:10.1016/B978-0-12-809324-5.03078-9
McNamara D. S. (ed.) Reading Comprehension Strategies: Theories, Interventions, and Technologies. New York: Psychology Press, 2007. 536 p.
Norris D. The Effects of Frequency, Repetition and Stimulus Quality in Visual Word Recognition // Quarterly Journal of Experimental Psychology. 1984. V. 36. P. 507–518.
Norris D. Models of visual word recognition // Trends in Cognitive Sciences. 2013. V. 17 (10). P. 517–524. https://doi.org/10.1016/j.tics.2013.08.003
Norris D., Kalm K. Chunking and data compression in verbal short-term memory // Cognition. 2021. V. 208. Article 104534. https://doi.org/10.1016/j.cognition.2020.104534
Rabeson M., Blinnikova I. Cross-cultural research of strategies and efficiency in visual semantic search // European Proceedings of Social and Behavioural Sciences. 2020. V. 94. P. 636–645. DOI: 10.15405/epsbs.2020.11.02.78
Rastle K. Visual Word Recognition // In: G. Hickok, S. L. Small (eds.) Neurobiology of Language. Amsterdam: Academic Press. 2016. P. 255–264.
Rayner K. Eye movements in reading and information processing: 20 years of research // Psychological bulletin. 1998. V. 124 (3). P. 372. https://doi.org/10.1037/0033-2909.124.3.372
Rayner K. Eye movements and attention in reading, scene perception, and visual search // The quarterly journal of experimental psychology. 2009. V. 62 (8). P. 1457–1506. DOI: 10.1080/17470210902816461
Schad D. J., Engbert R. The zoom lens of attention: Simulating shuffled versus normal text reading using the SWIFT model // Visual Cognition. 2012. V. 20 (4–5). P. 391–421. https:// doi.org/10.1080/13506285.2012.670143
Schotter E. R., Payne B. R. Eye Movements and Comprehension Are Important to Reading // Trends in Cognitive Sciences. V. 23 (10). P. 811–812. https://doi.org/10.1016/j.tics.2019.06.005
Slavova V. Language, concept formation and child language acquisition – an information modeling approach. Sofia: Academic Publishing House of the Bulgarian Academy of Sciences, 2022. 160 p.
Snell J., Grainger J. Readers Are Parallel Processors. Trends in Cognitive Sciences. 2019. V. 23 (7). P.537–546. https://doi.org/10.1016/j.tics.2019.04.006
Snow C. Reading for Understanding: Toward an R&D Program in Reading Comprehension. Santa Monica, CA: RAND Corporation, 2002. 184 p.
Solovyev V., Solnyshkina M., McNamara D. Computational linguistics and discourse complexology: Paradigms and research methods // Russian Journal of Linguistics. 2022. V. 26 (2). P. 275–316. https://doi.org/10.22363/2687-0088-30161
Staub A., White S. J., Drieghe D., Hollway E. C., Rayner, K. Distributional effects of word frequency on eye fixation durations // Journal of Experimental Psychology: Human Perception and Performance. 2010. V. 36 (5). P. 1280–1293. https://doi.org/10.1037/a0016896
Toyama Y., Hiebert E. H., Pearson P. D. An Analysis of the Text Complexity of Leveled Passages in Four Popular Classroom Reading Assessments // Educational Assessment. 2017. V. 22. P. 139–170. https://doi.org/10.1080/10627197.2017.1344091
Velichkovsky B. M., Challis B. H., Pomplun M. Arbeitsgedächtnis und Arbeit mit dem Gedächtnis: Visuell-räumliche und weitere Komponenten der Verarbeitung // Zeitschrift für Experimentelle Psychologie, 1995. V. 42 (4). P. 672–701.
Velichkovsky B. M., Joos M., Helmert J. R., Pannasch S. Two visual systems and their eye movements: Evidence from static and dynamic scene perception // Proceedings of the XXVII conference of the cognitive science society. 2005. P. 2283–2288.
Yap M. J., Balota D. A. Visual word recognition // In: A. Pollatsek. R. Treiman (eds.) The Oxford handbook of reading. Oxford: Oxford University Press, 2015. P. 26–43.
Zelinsky G. J. A theory of eye movements during target acquisition // Psychological Review. 2008. V. 115. P. 787–835. DOI: 10.1037/a0013118