
Выявление смыслового ядра как метод преодоления текстоидности
Aннотация
В результатах нейронного машинного перевода, призванных функционировать как текст, однако не являющихся таковым по определению, мы считаем возможным выявить некий коммуникативный центр — смысловое ядро, обладающее текстообразующим потенциалом.
Актуальность данного исследования обусловлена, с одной стороны, общедоступностью программ машинного перевода и активным повсеместным их использованием, с другой — неучетом специфики переводных текстов, порожденных искусственным интеллектом. На практике имеет место систематическое нарушение внутритекстовых связей в результатах машинного перевода — фактически, набор предложений, говоря иначе «текстоид», из которого редактору предстоит воссоздать связный соразмерный текст. Частое обращение к оригиналу позволяет точечно устранять в переводе смысловые искажения и неточности, однако в целом перевод продолжает восприниматься как плохо написанный текст с «машинным ДНК». В этом и заключается интересующая нас проблема: отсутствие эффективного способа по оценке и достижению глобальной смысловой соразмерности в переводном продукте ИИ.
Данное исследование имеет своей цельюнаметить пути для выработки эффективного, практико-ориентированного лингвистического способа по преодолению текстоидности посредством выявления смыслового ядра в результатах машинного перевода. Благодаря комплексному подходу к выбору методовисследования, а именно: абстрагирование, анализ, классификация, синтез, моделирование, измерение, — были достигнуты следующие результаты: (а) предложен способ выявления конфигурации смыслового ядра, основанный на общепринятых в лингвистике понятиях субъекта, предиката, объекта и универсальной предметно-логической типологии семантических отношений, (б) показана необходимость корректировки первоначальной формулировки-формулы ядра (в 46 % случаев), (в) определена медиана доли ядра от объема текстоида в жанре новостной заметки медицинской тематики (31 %), (г) предложены основополагающие принципы лингвистической разметки и введены условные обозначения, (д) в иллюстративных целях предложен принцип изображения смыслового ядра в виде графических формул, (е) намечены пути дальнейшего научного поиска.
Вывод: на материале 52 текстоидов показана применимость предложенного нами способа по выявлению смыслового ядра, призванного быть (а) текстообразующим содержательным концентратом, с помощью которого возможно в дальнейшем преобразовывать текстоид в текст; (б) предметно-логическим ориентиром для контроля и проверки на переводческую адекватность как отдельных мест в машинном переводе, так и отредактированного варианта в целом; (в) инструментом для толкования в текстоиде непонятных, противоречивых мест (в том числе без обращения к тексту оригинала).
Ключевые слова: Смысловое ядро, Преодоление текстоидности, Когезия, Нейронный машинный перевод, Изотопность
Введение
Широкая доступность искусственного интеллекта, высокая скорость генерации текстов, в том числе для целей межъязыкового посредничества, и значимое улучшение результатов машинного перевода, отмечаемое многими исследователям (Переходько, 2017; Беляева, 2022; Чакырова, 2013; Панасенков, 2019), — эти и некоторые другие факторы, казалось бы, указывают на то, что текстовые задачи, прежде требовавшие от исполнителя высочайшей квалификации, в наш век цифровых технологий можно практически полностью делегировать машине. «Переводчик и/или редактор, — отмечает В.В. Сдобников, — перестают обращать внимание на внутреннюю целостность и связность текста, его когерентность, его смысловую структуру, фокусируясь на отдельных предложениях и словах. В результате продукт, даже подвергшийся редакторской правке, все равно не превращается в текст, а остается текстоидом» (Сдобников, 2025: 72).
Понятие «текстоид» в Философском словаре определяется как «сетевой текст, лишенный твердой фиксации, свободно меняющий свою форму и контекст, переходящий от пользователя к пользователю…» (Цит. по: Сдобников, 2024). У лингвистов словарно-энциклопедическое толкование для данного понятия на сегодняшний день отсутствует. Тем не менее в научных статьях текстоид определяется как «незавершенная единица» (Сиротинина, 1994), «особая единица с незамкнутым смысловым контуром» (Боронин, 2016). И.М. Дзялошинский описывает признаки текстоидности следующим образом: «…Произведение состоит из фрагментов, которые написаны разными авторами, <...> не воспринимается как целостность» (Дзялошинский, 2019: 91–105).
Результат машинного перевода[1], представляющий собой совокупность текстовых фрагментов, автоматически отобранных из массива билингвальных текстов, обработанных и оформленных алгоритмами программы в последовательность предложений, мы вслед за В.В. Сдобниковым (Сдобников, 2025) также будем рассматривать как текстоид. В связи с чем возникает вопрос: каким образом возможно, с одной стороны, обеспечить полученный в результате машинного перевода текстоид внутренней целостностью и связностью, наличествующими в оригинальном тексте, а с другой — как преодолеть воздействие, оказываемое «самой организацией использования систем МП на сознание переводчика и постредактора» (там же: 75)?
Сразу отметим, что вряд ли существуют объективные причины (во всяком случае мы их не видим) сомневаться в принципиальной возможности преобразовать текстоид в текст, обеспечить внутритекстовую связность. Весомым аргументом можно считать сам факт существования такого вида профессиональной деятельности, как постмашинное редактирование, или постредактирование, цель которого — если выбран режим максимального качества (full post-editing) — состоит в получении «результата, неотличимого от человеческого перевода» (an output which is indistinguishable from human translation output[2]).
Для ответа на поставленный нами вопрос о способах обеспечения внутритекстовой связности необходимо обратиться к сущностной стороне когезии. Под когезией О.И. Гальперин понимает «особые виды связи, обеспечивающие континуум, т.е. логическую последовательность, (темпоральную и/или пространственную) взаимозависимость отдельных сообщений, фактов, действий и пр.» (Гальперин, 2006: 74). Эксперименты психолингвистов по изучению смыслового восприятия текста как логической последовательности отдельных сообщений подтверждают, что читатель воспринимает текст как единую смысловую структуру; текст в его сознании как бы сжимается: фрагменты объединяются в более крупные смысловые блоки на основе семантических доминант, которые можно представить тезисно, в виде ключевых слов (Григорян, 2024).
Существует множество работ, посвященных изучению проблемы текстовой связности[3], в том числе объективной возможности выявить в тексте некий смысловой центр, «нечто вроде фокуса, то есть чего-то такого, к чему сходятся все лучи или от чего исходят» (Гольденвейзер, 1922). Так, в докторской диссертации Д.В. Псурцева предложен подход, описывающий механизм смыслоформирования художественного текста (Псурцев, 2001). Французские лингвисты А. Греймас и Ф. Растье стоят у истоков семантической изотопии, в соответствии с которой смысл текста не есть одноплановая линейная последовательность значений: «Под изотопией мы понимаем избыточную совокупность семантических категорий, которая делает возможным целостное прочтение рассказа, прочтение, являющееся результатом отдельных частичных прочтений высказываний и следствием установления, их двусмысленности, при том, что это установление стремится к поискам путей единого прочтения» (Греймас, 1985). Финский семиотик Э. Тарасти полагает, что изотопия присуща любому тексту и «обеспечивает связность даже в условиях наивысшей дробности» (Tarasti, 2017). Помимо фундаментальных работ имеются многочисленные научные статьи, посвященные поиску смыслового центра в отдельно взятом художественном произведении (Вишнякова, 2017; Наумчик, 2020; Скращук, 2019). В учебно-методическом пособии Е.В. Гориной подробно рассматривается смысловая структура журналистского текста — каким образом информационный повод развертывается в связный текст (Горина, 2021). Однако материалом, к которому обращаются исследователи в целях комплексного анализа содержательной структуры и выявления смыслового центра, как правило выступают тексты, созданные человеком. Наше исследование, также посвященное проблемам внутритекстовой связности и развертывания текста вокруг смыслового центра, проведено на материале не текстов в традиционном смысле этого понятия, а текстоидов — в этом его новизна. Кроме того, в ходе наших изысканий предложен и описан способ по выявлению смыслового ядра текста, призванный быть подспорьем в преодолении текстоидности машинного перевода.
К машинному переводу прибегают все чаще, однако, как отмечает А.Н. Малявина, студенты «не видят ошибок в «творении машин» и не привыкли редактировать за ними тексты перевода ни с точки зрения синтаксиса и стиля, ни с позиции проверки фактической информации» (Малявина, 2024); схожие соображения о зачастую необоснованном полном доверии к машинному переводу и неспособности критически подойти к результатам ИИ высказывают Е.Г. Фонова и О.А. Шитц (Фонова, Шитц, 2025).
Не только студенты, но также и профессиональные переводчики и редакторы далеко не всегда предоставляют заказчику коммуникативно полноценный текст (Кобзева, 2018). Таким образом, актуальность выполненного нами исследования, во-первых, связана с ростом интереса к программам машинного перевода и активным их использованием и, во-вторых, определяется потребностью в действенных способах обращения аморфного, расфокусированного текстоида в связный соразмерный текст — как при обучении переводу, так и в отраслевой практике. Данное исследование имеет своей целью наметить пути для выработки лингвистического способа по преодолению текстоидности посредством выявления конфигурации смыслового ядра в результатах машинного перевода, описать его механизм, вскрыть его основные принципы.
Материал исследования
Источником текстов для настоящего исследования выбран американский медицинский вебсайт drugs.com[4], в частности его раздел Consumer News[5], где ежедневно публикуются актуальные новостные заметки, представляющие собой рерайт отраслевых пресс-релизов, газетных, журнальных, научных статей и прочих информационных жанров. Отметим, что все материалы, размещенные в указанном разделе, в обязательном порядке проходят научную редакцию, осуществляемую медицинским писателем Кармен Поуп, бакалавром фармации. Таким образом, отобранный нами материал можно охарактеризовать как англоязычные информационные тексты медицинской тематики в жанре новостной заметки, для которых верификация фактов предметной области осуществлялась отраслевым экспертом, компетентным также в вопросах языковой и жанровой нормы, что свидетельствует об их коммуникативной полноценности (исходный материал — не текстоиды, а тексты).
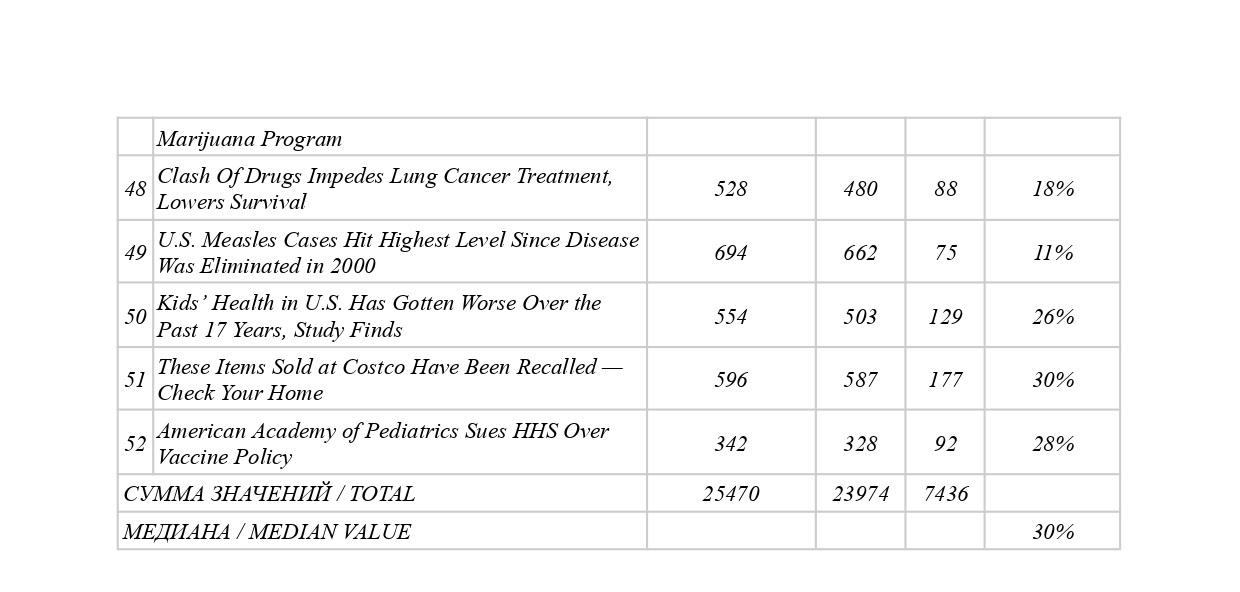
Методом сплошной выборки с сайта drugs.com выгружены 52 текста общим объемом 25.470 слов (3,4 а. л.), опубликованные с 1 июля по 8 июля 2025 года[6]. Данный временной интервал обусловлен тем, что к разработке практической части нашего исследования мы приступили 9 июля 2025 года, взяв таким образом для анализа все без исключения новостные заметки, имевшиеся в тот момент на указанном сайте за текущий календарный месяц.
Для получения их русскоязычных версий, на материале которых, собственно, и было проведено исследование, выбран машинный переводчик открытого доступа Google Translate, поскольку именно к его функционалу, по данным статистики[7], чаще всего прибегают пользователи интернета. Дата обращения к машинному переводчику для генерации всех 52 текстоидов — 9 июля 2025 года.
Методы исследования
В основу проведенного нами исследования положен комплексный подход, а именно: для выявления смыслового ядра на фоне текстоидной периферии и изучения его компонентов с их позиционными вариантами задействован метод абстрагирования; для разложения первичного смыслового ядра на компоненты и их позиционные варианты — метод анализа и классификации; для последующей корректировки смыслового ядра с целью выявления его окончательной формулировки-формулы — метод синтеза; для наглядного представления конфигурации смыслового ядра — метод моделирования; для определения основных статистических характеристик смыслового ядра (медиана доли ядра от объема текстоида и частота совпадения первичного и итогового вариантов ядра) — метод измерения. По результатам изучения 52 конфигураций смыслового ядра показана принципиальная возможность нахождения смыслового центра, выявления его конфигурации и потенциала к дальнейшему развертыванию содержательного концентрата в коммуникативно полноценный текст. Таким образом, в данном исследовании вскрываются общие принципы, руководствуясь которыми представляется возможным создавать благоприятные условия для преодоления текстоидности результатов машинного перевода.
Некоторые теоретические уточнения
Под смысловым ядром текста мы, вслед за О.И. Москальской, понимаем «обобщенный концентрат всего содержания текста» (Москальская, 1981: 17). Смысловое ядро характеризуется наличием как минимум предикативной связи, или предикативности (в нашей номинации — действие, или что́ происходит в текстовой действительности). Обязательность, неотъемлемость, непреложность данного ядерного компонента вытекает из самой природы предикативности, которая суть «общее, глобальное свойство всякого высказывания, а также свойство мысли, ее направленность на актуализацию сообщаемого» (Лингвистический энциклопедический словарь, 1990). По мере необходимости в ядре текста могут быть выделены (и, как правило, выделяются) такие компоненты, как субъект — кто или что совершает действие, объект — на кого нацелено действие, а также условие — при каких обстоятельствах выполняется действие. При формулировании опорного высказывания, призванного на роль первичного смыслового ядра текста, мы рекомендуем принимать в расчет одну из характерных черт базисной структуры предложений основного типа, обозначенную Л.М. Ковалевой как «выраженность семантической структуры предложения не только самым эксплицитным, но и самым экономным способом» (Ковалева, 1987).
Для выявления эффективного средства по преодолению текстоидности машинного перевода мы приняли решение фокусироваться только на смысловом ядре: его компонентах и позиционных вариантах, — положив в основу методологии проведенного нами исследования метод абстрагирования. Мы сознательно упрощаем картину изучаемого объекта, фокусируясь на самом главном, поскольку задача по выявлению всех смысловых нитей текста (во всяком случае на данном этапе и в рамках одной научной публикации) была бы чересчур амбициозной, малореализуемой, хотя в теоретическом, сугубо исследовательском плане, безусловно, чрезвычайно интересной.
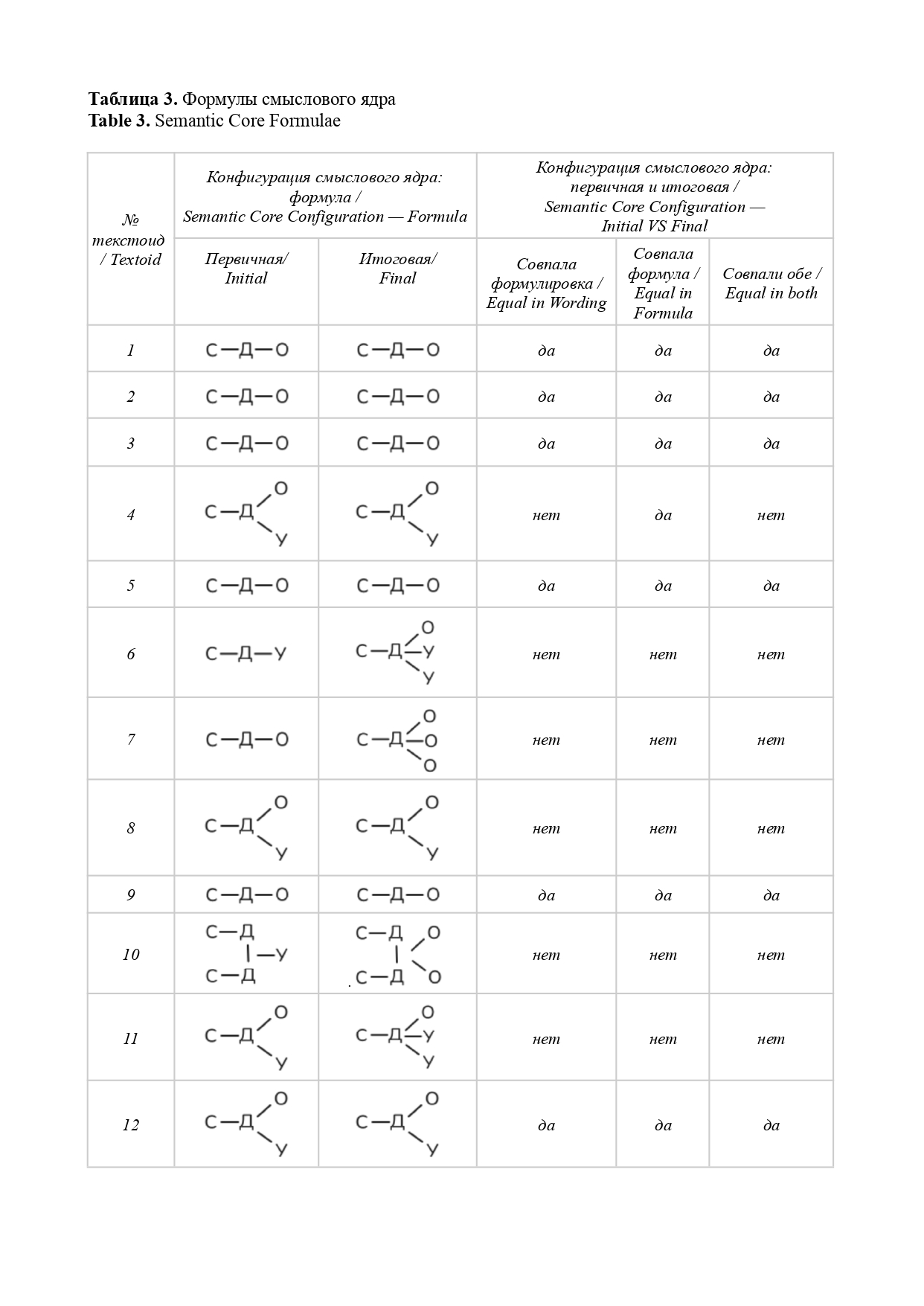
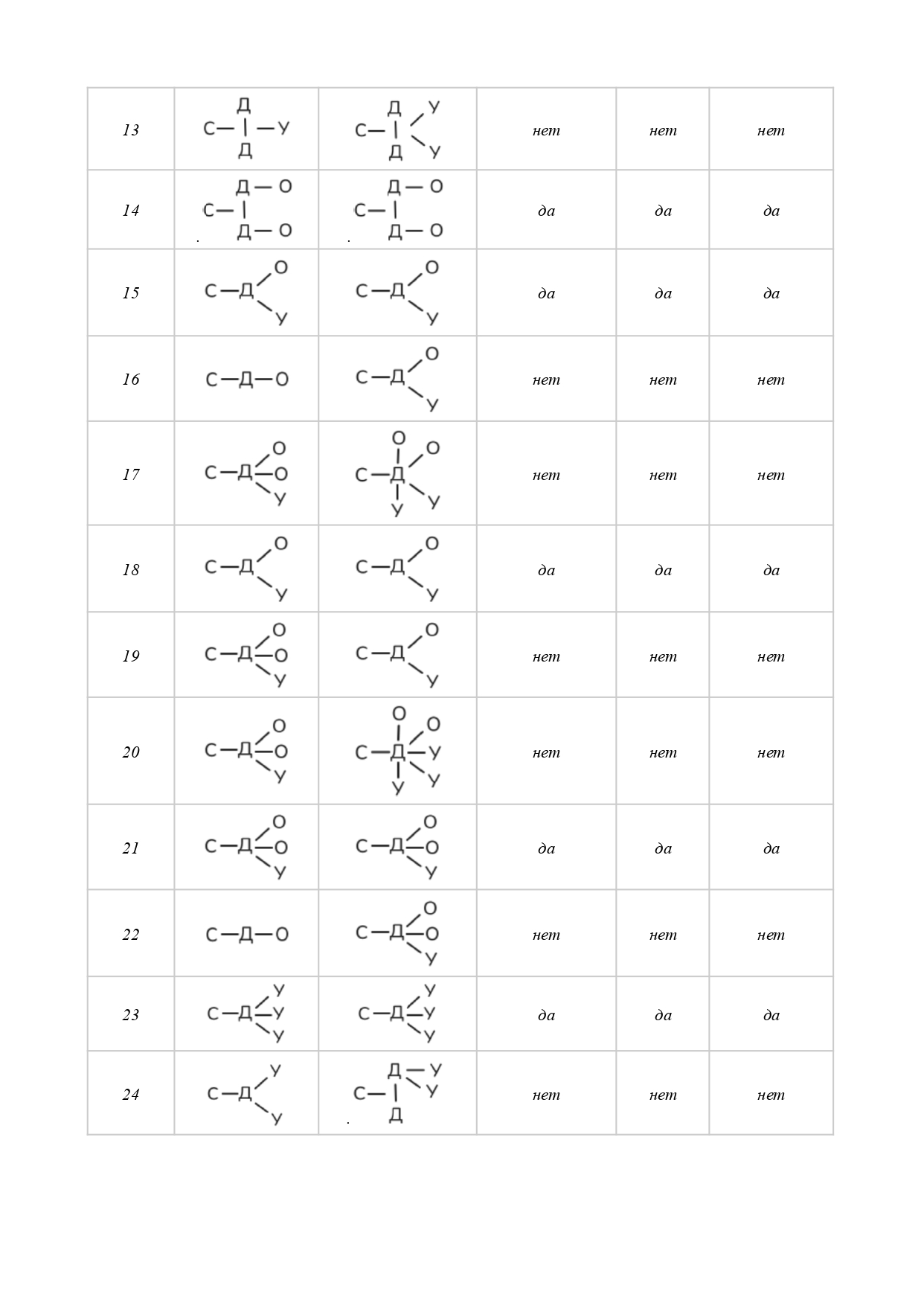
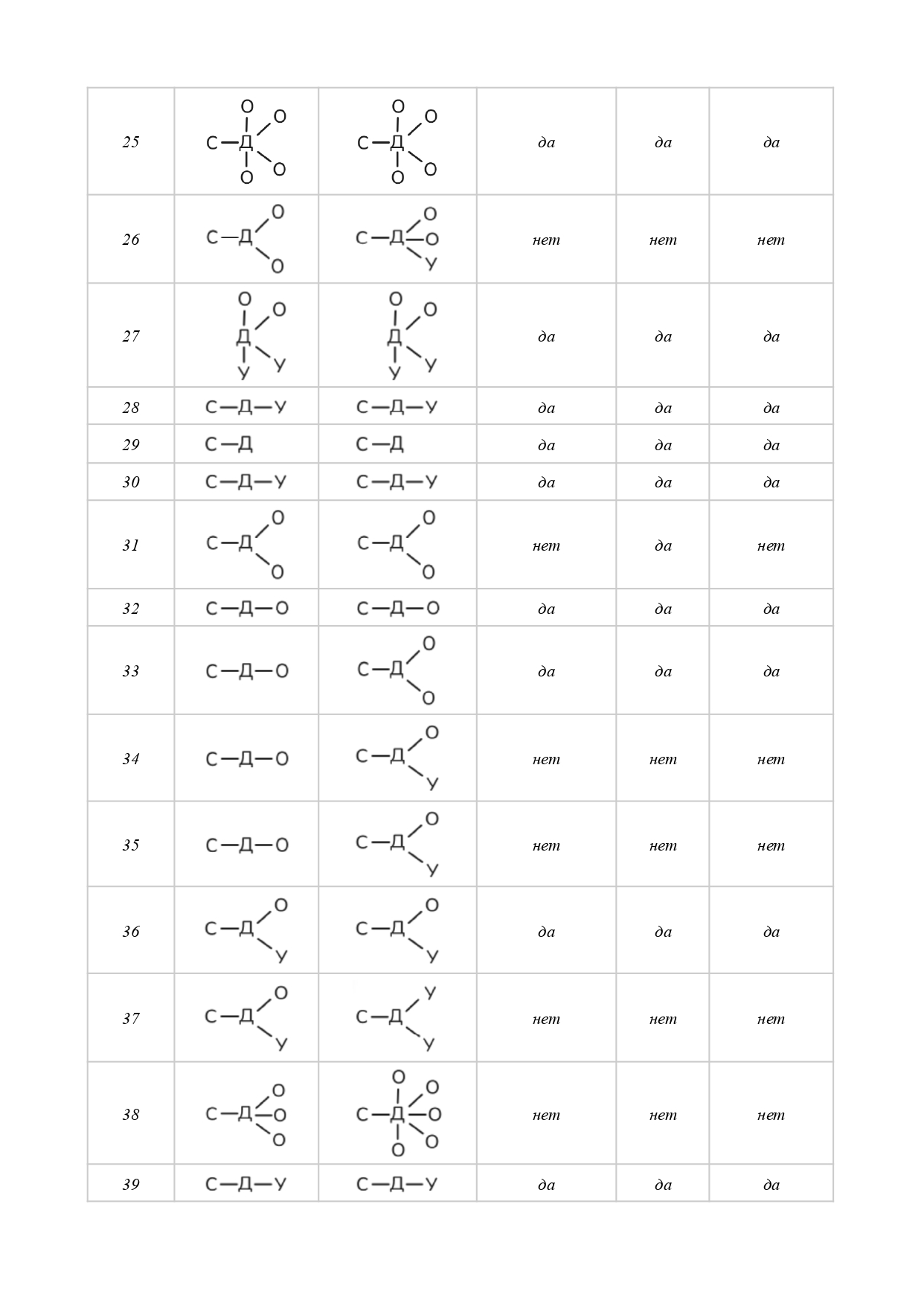
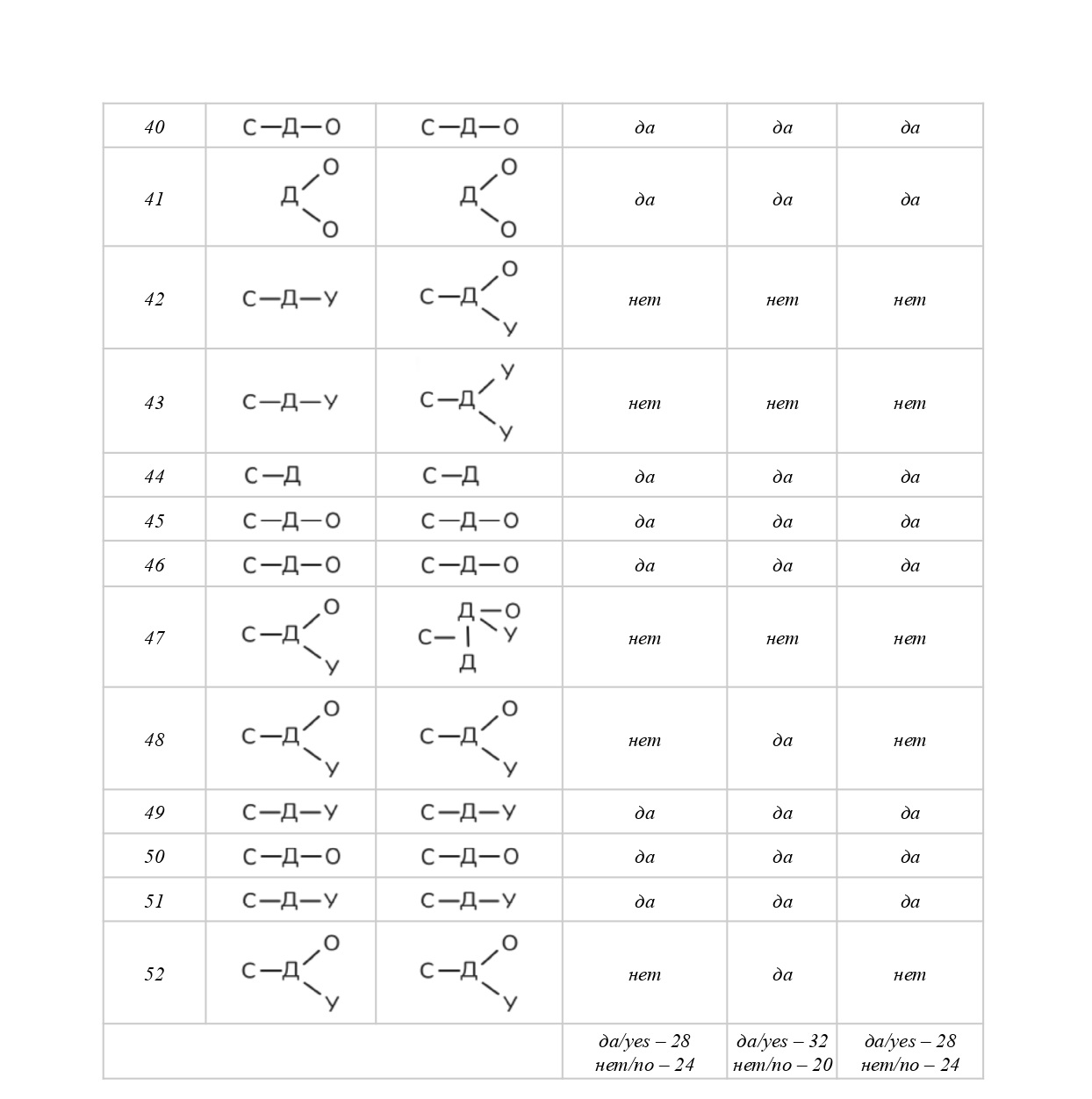
В целях экономии места и по соображениям удобства обработки массива текстоидов — материалов нашего исследования — для выделенных компонентов ядра смысла вводятся аббревиатуры-индексы с нижним подчеркиванием[8] с обеих сторон: _С_ — субъект, _Д_ — действие, _О_ — объект, _У_ — условие. Отметим, что компонентов в ядре текста может быть несколько; в таком случае к буквенному индексу добавляется цифра, например, _У1_, _У2_ или _С1_, _С2_, _С3_ и так далее (при построении формулы, в отличие от формулировки, связи между компонентами возможно изобразить, поэтому необходимость в цифровой индексации отсутствует, см. Таблицу 3). Дальнейшая разработка предложенной нами модели предполагает введение дополнительных индексных элементов.
Представить базовую схему ядра можно в виде цепочки С–Д–О–У. Порядок следования компонентов фиксирован в целях удобства статистической обработки результатов текстового массива (на данный момент — вручную, в перспективе — с использованием автоматизированного программного инструмента, вероятно, с возможностью построения 3-мерных моделей) на следующем основании: при создании формулировки-формулы (далее — вербализации) смыслового ядра мы предлагаем не принимать в расчет тема-рематические отношения между его компонентами, поскольку имеем дело, фактически, с лингвистическим конструктом, не имеющим адресата и не предназначенным для коммуникации как таковой, но существующим исключительно для внутреннего, служебного пользования.
При выявлении смыслового ядра текста предлагается видеть его центральным (неотъемлемым, обязательным и непреложным) элементом предикативную связь, с которой соотносятся все прочие наличествующие компоненты. Таким образом, в предлагаемой схеме компонент предикативности (действие) — это поливалентный логический центр смыслового притяжения, которому подчиняются все прочие компоненты ядра.
Отметим, что в тексте таких центров может оказаться несколько. В таком случае вербализация смыслового ядра проходит в соответствии со следующими принципами:
- действия соотносятся между собой: Д¹–Д²,
- остальные компоненты либо зависят от одного из действий и в таком случае в индексе имеют соответствующую цифру, например, С¹–Д¹–О¹–С²–Д²–У², либо относятся ко всем действиям и в своей маркировке имеют только базовый буквенный индекс, например С–Д¹–Д²–О, либо одни компоненты относятся ко всем действиям, другие — не ко всем, например С–Д¹–Д²–О²–У²–У.
Описание проведенного исследования
Ход выявления смыслового ядра, его компонентов и их позиционных вариантов
Выявление конфигурации смыслового ядра в целях получения инструмента для последующего создания коммуникативно полноценного текста проводилось для каждого из 52 текстоидов последовательно, в четыре этапа:
- После ознакомления с результатом машинного перевода было сформулировано первичное смысловое ядро — опорное высказывание, которое в сжатой форме призвано выразить то самое главное, о чем сообщается, судя по результатам машинного перевода, в тексте оригинала и/или будет сообщаться в коммуникативно полноценном тексте на переводящем языке[9]. Зачастую приемлемый вариант содержался в заголовке и/или в первом абзаце («лиде») текстоида, в таком случае он заимствовался без изменений либо с незначительными модификациями в 32 случаях из 52 (62 %). Отметим, что решение о приемлемости сообщения в заголовке/лиде на роль опорного высказывания и о необходимых модификациях принималось нами строго после того, как был прочитан весь текстоид. Такой подход показателен для тех случаев, когда сформулированное нами опорное высказывание не ограничивалось информацией только из заголовка/лида — в 38 % текстоидов.
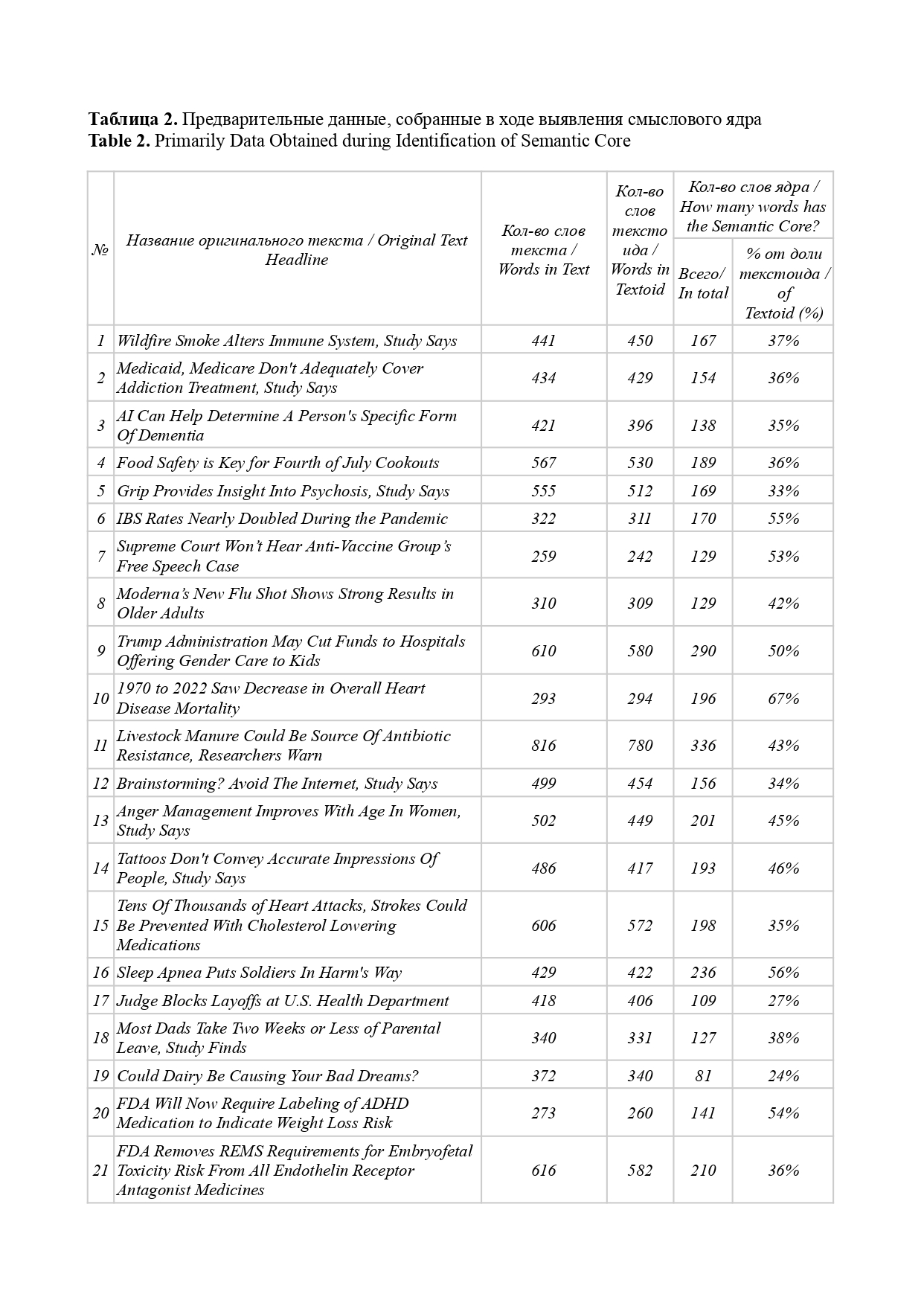
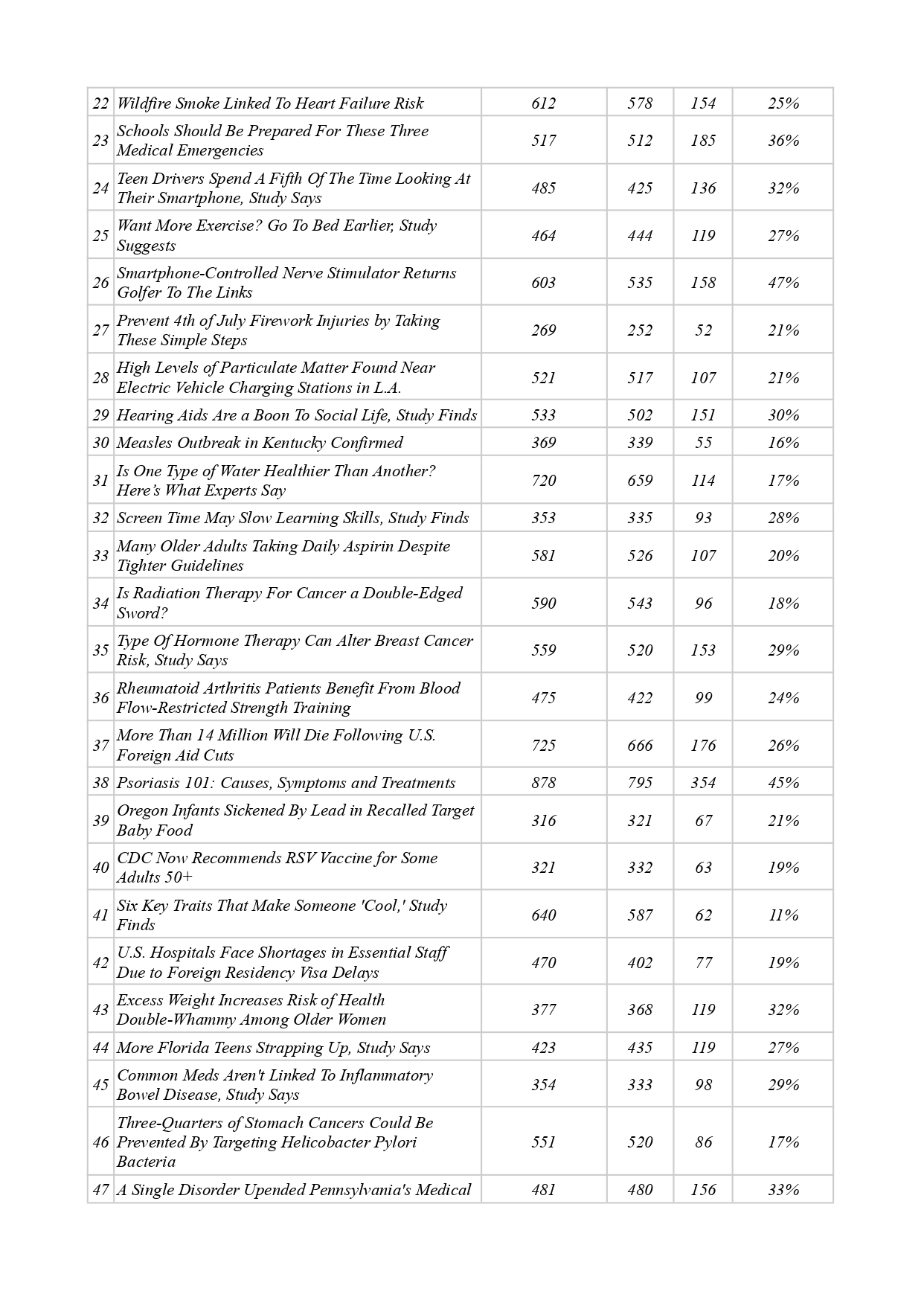
- С целью уточнить черновой вариант формулировки-формулы смыслового ядра, исследуемый текстоид был размечен — мы отыскали в нем компоненты смыслового ядра с их позиционными вариантами, маркировав содержащие их слова и словосочетания соответствующим индексом, по необходимости внеся корректировки в опорное высказывание. Из 25470 слов всего массива текстоидов на смысловое ядро пришлось 7436 (31 %) — в разделе «Приложение» см. Таблицу 2.
- Маркированные фрагменты текстоида с помощью метода классификации были распределены по группам в соответствии с присвоенным индексом — на этом этапе каждый компонент смыслового ядра становится как бы центром притяжения своих позиционных вариантов и состоит с ними, по нашим наблюдениям, прежде всего в предметно-логических отношениях тождества (напр., лексические повторы, равновесные синонимы и перифразы) или включения (напр., гипонимы, гиперонимы). Отметим, что проблематика отношений между ядерным компонентом и его позиционными вариантами, а также принципы их выделения требуют дальнейшей разработки.
- Наконец, каждый перечень позиционных вариантов мысленно был соотнесен, фактически «синтезирован», со своим ядерным компонентом с целью его возможной окончательной корректировки. Выполненный на данном этапе позиционно-компонентный синтез необходим для окончательного уточнения конфигурации смыслового ядра, чтобы соотнести финализированную формулировку-формулу с текстоидом и убедиться в ее полной пригодности на роль «обобщенного концентрата». (Итоговый вариант вербализованного смыслового ядра, полученный по результатам 3-го и 4-го этапов, отличался от первичного смыслового ядра 1-го этапа в 46% случаев.)
Так, к примеру, в текстоиде № 9 мы выделили смысловое ядро «Трамп_С_ прекратит финансирование_Д_ больниц, оказывающих гендерную терапию детям_О_», вопреки содержанию заголовка «может сократить финансирование», где выбранный машиной глагол означает «уменьшить в количестве, объеме», тогда как далее по тексту видим позиционные варианты предиката, сводимые к идее именно запрещения (здесь и далее полужирный шрифт наш. — А.К.): …Может прекратить федеральное финансирование …Изучают возможность заблокировать федеральное финансирование Medicaid или страхового покрытия …Также рассматривают возможность полного исключения <…> из программы Medicaid …Уже прекратило финансирование …Усилий по ограничению …Могут ограничивать доступ.
Поскольку поиск позиционных вариантов для компонентов смыслового ядра предполагает, по сути, построение парадигматического ряда, его элементы в соотнесении друг с другом рассматриваются как проявления единого целого; не заметить логическую несоразмерность (в данном случае — смысловую ошибку) в таких условиях невозможно.
Более того, в некоторых случаях традиционное поступательное сопоставление перевода с оригиналом (сверху вниз по тексту, от предложения к предложению) не помогает заметить проблему в силу значительной отдаленности контекстуальных синонимов друг от друга. Так, в текстоиде № 1 в 4-м абзаце сообщается: …Dozens of genes related to allergies and asthma, — тогда как в 10-м абзаце уточняется: …changes in 133 genes related to allergies and asthma. В машинном переводе десятки генов и 133 гена соответственно. Сохраняя логику автора, которая нам видится в стремлении сообщить примерное число генов, исчисляемое десятками («дюжинами» в оригинале), взамен найденной в текстоиде счетной единицы мы предложили бы вариант: более сотни генов. Без намеренного сопоставления позиционных вариантов по тексту заметить подобного рода несоразмерности, думается, можно лишь в силу случайности.
Результаты
Проведенное в рамках данного исследования изучение принципов выделения смыслового ядра, его конфигураций и основополагающих свойств на материале текстоидных новостных заметок медицинской тематики, полученных в результате обращения к нейронному машинному переводчику Google Translate, позволило получить следующие развернутые результаты:
Во-первых, нами предложен и апробирован оригинальный способ обнаружения конфигурации смыслового ядра, в основу которого поставлены классические категории лингвистики (субъект, объект, предикат) и фундаментальная предметно-логическая типология семантических отношений (отношения тождества: лексические повторы, равновесные синонимы и перифразы, — и отношения включения: гипонимы, гиперонимы). Такой подход позволяет системно и воспроизводимо выделять те элементы текста, которые несут основную смысловую нагрузку, независимо от вариативности поверхностного лексико-грамматического оформления.
Во-вторых, в ходе проверки выявлена статистически значимая необходимость корректировки первоначальной формулировки-формулы ядра (в 46 % случаев), что убедительно указывает на правильность нашего изначального исследовательского стремления избегать жестких, однократно применяемых схем для адекватного описания смыслового устройства текстоида и подтверждает необходимость как минимум двухэтапности в процессе вербализации итогового варианта смыслового ядра.
В-третьих, мы определили медиану доли протяженности смыслового ядра по отношению к общему объему текстоида. Для исследуемого жанра — новостной заметки медицинской тематики — данный показатель составил 31 %. Иными словами, около трети объема текстоида приходится на компоненты ядра и их позиционные варианты, оставшиеся 69 % — на смысловую периферию. Это говорит о том, что, с одной стороны, самые главные (текстообразующие) сведения повторяются многократно, оформлены различными лексико-грамматическими способами и характеризуются заведомо высокой избыточностью; с другой стороны, треть словесного материала может быть свернута в одно-единственное ключевое высказывание, которое являет собой инструмент по проверке и восстановлению связей как в ядре, так и на периферии.
В-четвертых, с целью обеспечения воспроизводимости результатов и возможности последующего сопоставления данных, полученных по разным текстам различными исследователями, нами разработаны и предложены основополагающие принципы лингвистической разметки и задана система условных обозначений (которые, как отмечено в ограничениях ниже, требуют последующей разработки).
В-пятых, в иллюстративных и дидактических целях, а также для наглядного представления структурных особенностей конфигурации смыслового ядра нами предложен принцип изображения смыслового ядра в виде графических формул. Данный принцип предполагает аббревиатурную индексацию с указанием связей между различными компонентами, что позволяет компактно представить даже самые сложные ядерные конфигурации.
И, наконец, в-шестых, на основе полученных результатов, а также с учетом выявленных ограничений, намечены дальнейшие направления научного поиска:
• Изучение различных конфигураций смыслового ядра, выявление их свойств, создание типологии связей между ядерными компонентами и их позиционными вариантами.
• Определение степени применимости смыслового ядра как инструмента обеспечения внутритекстовой связности и соразмерности в текстоидах различных стилей и жанров.
• Разработка практико-ориентированного варианта предложенного нами способа по выявлению и применению смыслового ядра.
• Выявление в текстоиде всей содержательной структуры, в которую погружено смысловое ядро, и ранжирование ее по степени релевантности с присвоением соответствующего информационного ранга (к примеру, смысловое ядро — это информация наивысшего ранга, тогда как метаданные (в частности, выходные сведения: автор текста, дата, место публикации) — это информация самого низшего ранга).
• Автоматизация некоторых действий по вербализации смыслового ядра и всей смысловой структуры текста, возможно, за счет создания компьютерной программы, призванной облегчить сбор и обработку информации и представить ее в наглядном виде. (Важно пояснить: именно «облегчить сбор и обработку информации», а не освободить от когнитивных усилий на этапе осмысления внутритекстовых связей, принципиально не делегируя этот вид работы машине. Осмысление как результат умственной деятельности, присущей только живому человеческому существу, на наш взгляд, и есть то самое фундаментальное непреложное условие для преодоления текстоидности).
Кроме того, полученную для каждого текстоида формулировку-формулу — его смысловое ядро в своем окончательном, уточненном варианте — возможно (но необязательно) оформить в виде ключевого сообщения, что мы и сделали для первых десяти текстоидов (см. Таблицу 1). Под «ключевым сообщением» мы понимаем высказывание, как правило, более развернутое по сравнению со смысловым ядром и, в отличие от него, рассчитанное на потенциального адресата, то есть построенное с учетом общепринятых норм актуального членения предложения. На практике такой коммуникативно полноценный вариант смыслового ядра может быть использован в качестве информационного сообщения (имея в виду под «информационным сообщением» жанр новостной журналистики).


Заключение. Выводы и ограничения исследования
Предложенный нами способ позволяет выделить в расфокусированном текстоиде смысловое ядро, которое, как мы полагаем, может претендовать на статус лингвистического инструмента для преодоления коммуникативной неполноценности машинного перевода, обусловленной в первую очередь нарушением внутритекстовых связей и семантической соразмерности. Наша уверенность в его дальнейшей практической пригодности основана на том, что метод смыслового ядра позволяет выявить и вербализовать тот самый центр, где происходит «объединение всех составляющих его [текст — А.К.] предложений вокруг одной темы» (Москальская, 1981: 19), в чем, по утверждению О.И. Москальской, и проявляется смысловая целостность текста (там же).
Итак, по итогам исследования, конфигурация смыслового ядра выявлена для всех 52 текстоидов (в разделе «Приложение» см. Таблицу 3). Это позволило нам убедиться, что во всех случаях в результате целенаправленной умозрительной работы по анализу магистральных внутритекстовых связей с целью осмысления машинного перевода как содержательной целостности и, как следствие, создания условий для преодоления его текстоидности мы способны синтезировать для себя и других такой смысловой концентрат, который может служить: (а) предметно-логическим ориентиром для контроля и проверки смысловой соразмерности отдельных лексико-синтаксических единиц анализа в машинном переводе как относительно друг друга (причем удаленность их контекстуальных проявлений не является при таком подходе фактором, осложняющим редакторскую проверку), так и относительно смысловой структуры текстоида в целом, претендующем на статус текста; (б) инструментом для толкования в текстоиде непонятных, невразумительных, противоречивых мест при создании равноценной замены тексту оригинала — замены формально близкой либо неблизкой, сообразно стратегии перевода, (в) основанием, на котором развертывается коммуникативно полноценный текст, не обязательно претендующий на статус перевода (в том числе рерайтинг).
Однако следует отметить и некоторые ограничения. Во-первых, наше исследование проводилось на материале новостных заметок — жанр, в котором текст призван сообщить о событии, послужившем информационным поводом, то есть с четко выраженным смысловым центром, на который нанизываются подробности и для которого в принципе характерны многократные повторы. Напротив, жанры более эклектичные, такие как, например, слайды презентации к докладу или оболочка компьютерной программы, предполагают значительно большую имплицитность связей, повышенную самодостаточность и равновесность текстовых элементов. Тем не менее вряд ли имеются основания отрицать принципиальную возможность даже в таких случаях выделить текстообразующий смысловой центр, хотя в силу обозначенных выше причин (имплицитность, самодостаточность, равновесность единиц анализа) такой центр окажется либо слишком громоздким при слишком малой периферии и потому, предположительно, малоэффективным как инструмент по проверке и обеспечению связности и соразмерности частей в составе целого, либо, наоборот, слишком емким и потому недостаточно представленным своими позиционными вариантами в анализируемом материале.
Во-вторых, принципы лингвистической разметки, обозначенные нами лишь в общих чертах, не раскрываются в виде отчетливого, практико-ориентированного алгоритма, что отрицательно сказывается на таких важных исследовательских характеристиках, как воспроизводимость и методическая ориентированность. Круг вопросов, рассмотренных в данной публикации, вынужденно ограничен общей постановкой проблемы текстоидности как неотъемлемого, неизбежного свойства машинных переводов и обоснованием наличия у семантически расфокусированного продукта ИИ потенциала к выделению переводчиком-редактором тектообразующего логического центра, претендующего на роль инструмента верификации связности и соразмерности частей в составе текста как единого целого. Думается, предложенный нами способ, даже с учетом намеченной на ближайшее будущее его теоретической и методической разработки в целях повышения практической применимости, в известной мере непреодолимо субъективен, поскольку основан на выделении в тексте смыслового центра, то есть фактически его интерпретацию, которая неотделима от таких процедур, как: информационный отбор, расстановка приоритетов, оценка авторского намерения, учет коммуникативной ситуации, — то есть процессов, в той или иной степени субъективных в силу самой природы коммуникативного акта.
[1] Здесь и далее: нейронный машинный перевод.
[2] ISO 18587: 2017 (en) Translation Services – Post-Editing of machine translation output – Requirements (2017). P. 8. URL: https://www.iso.org/standard/62970.html (дата обращения: 02.10.2025).
[3] Поисковый запрос «когезия» в электронной библиотеке eLibrary в названии публикаций, аннотации и ключевых словах дает 1845 научных работ (03.09.2025).
[4] Электронный ресурс. Режим доступа: http://drugs.com (дата обращения: 09.07.2025).
[5] Электронный ресурс. Режим доступа: https://www.drugs.com/medical-news.html (дата обращения: 09.07.2025).
[6] Для целей воспроизводимости проведенного нами исследования на случай исчезновения отобранных текстов с сайта drugs.com оригиналы новостных заметок, выгруженные 9 июля, хранятся бессрочно на файлообменнике автора данного исследования по адресу: https://clck.ru/3Ntvrx.
[7] По данным облачной переводческой платформы Smartling. Электронный ресурс. Режим доступа: https://www.smartling.com/blog/google-translate-vs-deepl#:~:text=What%20is%20Google%20Translate%2C%20and,are%20often%20lost%20in%20translation (дата обращения: 15.09.2025).
[8] Нижнее подчеркивание мы предлагаем использовать при разметке текстов как способ указать на начало и окончание индекса, то есть для обозначения его границ в целях облегчения внутритекстового поиска и автоматизированной обработки больших массивов информации. В иных случаях, в частности при вербализации смыслового ядра текста, нижнее подчеркивание представляется избыточным и не используется.
[9] Несмотря на то, что предлагаемый нами способ призван решать проблемы связности и логической соразмерности (то есть работает на переводческую адекватность), мы не ставим себе задачи предложить инструмент по достижению смыслового и когезийного тождества перевода и оригинала. Наша задача скромнее (но в то же время глобальнее) — дать инструмент по превращению текстоида в текст. Мы надеемся, что наибольшую пользу из наших идей впоследствии извлекут именно практикующие переводчики и редакторы, хотя затронутая проблема принадлежит не столько переводоведению, сколько лингвистике текста.












Список литературы
Беляева Л. Н. Машинный перевод в современной технологии процесса перевода // Известия Российского государственного педагогического университета им. А. И. Герцена, 2022. № 203. URL: https://doi.org/10.33910/1992-6464-2022-203-22-30 (дата обращения: 02.09.2025).
Боронин А. А. К вопросу о текстоидах // Вестник Московского государственного областного университета. Серия: Лингвистика, 2016. № 2. URL: https://doi.org/10.18384/2310-712X-2016-2-26-32 (дата обращения: 02.09.2025).
Вишнякова А. И. Идея свободы как смысловой центр организации романа Ф.М. Достоевского "Записки из Мертвого Дома" // Наука и образование. 2017. С. 11–15.
Гальперин И. Р. Текст как объект лингвистического исследования. Москва: ООО "КомКнига", 2006.
Гольденвейзер А. Б. Вблизи Толстого. М.: Кооперативное издательство, 1922. С. 296.
Горина Е. В. Смысловая структура журналистского текста: Учебно-методическое пособие. Екатеринбург: Уральский федеральный университет имени первого Президента России Б. Н. Ельцина, 2021. 123 с.
Греймас А. В поисках трансформационных моделей. Зарубежные исследования по семиотике фольклора. Москва: "Наука", 1985. С. 89–108.
Григорян В. А. Концептуализация и интерпретация текста в современной лингвистике // Социально-гуманитарные науки. 2024. С. 513.
Дзялошинский И. М. Тексты и текстоиды, или что происходит с автором? // PR и СМИ в Казахстане: сборник научных трудов, 2019. № 17. URL: https://publications.hse.ru/pubs/share/direct/306031376.pdf (дата обращения: 10.09.2025).
Кобзева О. В. Нарушение норм литературного языка при переводе (уровень языковой компетенции В1-С1) // Вестник Кемеровского государственного университета. 2018. № 4. URL: https://doi.org/10.21603/2078-8975-2018-4-211-222 (дата обращения: 03.10.2025).
Ковалева Л. М. Проблема структурно-семантического анализа простой глагольной конструкции в современном английском языке. Иркутск: Изд-во Иркутсткого ун-та, 1987. С. 15.
Малявина А. Н. Обучение постредактированию будущих переводчиков // Актуальные проблемы лингвистики и методики преподавания иностранных языков. 2024. С. 35.
Москальская О. И. Грамматика текста (пособие по грамматике немецкого языка для ин-тов и фак. иностр. яз.). М.: Высш. школа. 1981. URL: https://www.phantastike.com/linguistics/grammatika_teksta/djvu/view/ (дата обращения: 15.09.2025).
Наумчик О. С. Образ зеркала как смысловой центр сборника рассказов Нила Геймана "Дым и зеркала" // Вестник Балтийского федерального университета им. И. Канта. Серия: Филология, педагогика, психология. 2020. № 1. С. 80–87.
Панасенков Н. А. Опыт обучения студентов-лингвистов постредактированию машинного перевода (на материале англо-русского перевода с помощью систем «Google translate», «Яндекс переводчик» и «Promt») // Педагогическое образование в России, 2019. № 1. URL: https://doi.org/10.26170/po19-01-08 (дата обращения: 07.09.2025).
Переходько И. В. Оценка качества компьютерного перевода // Вестник Оренбургского государственного университета. 2017. № 2(202). С. 93.
Псурцев Д. В. Смыслоформирующий аспект образно-ассоциативных компонентов художественного текста (на материале англоязычной художественной литературы): Дис. … к-та филол. наук. М., 2001. 187 с.
Сдобников В. В. Искусственный интеллект в переводе: условия эффективного использования // Научный диалог, 2025. № 3. URL: https://doi.org/10.24224/2227-1295-2025-14-3-62-80 (дата обращения: 01.09.2025).
Сдобников В. В. Искусственный интеллект в переводе: уточнение понятий // Военно-филологический журнал. 2024. № 4. С. 42.
Сиротинина О. Б. Тексты, текстоиды, дискурсы в зоне разговорной речи // Человек. Текст. Культура. Екатеринбург. 1994. С. 109.
Скращук Е. И. Смысловая доминанта рассказа В. А. Солоухина "подворотня" // Дни науки студентов Владимирского государственного университета имени Александра Григорьевича и Николая Григорьевича Столетовых: Сборник материалов научно-практических конференций. 2019. С. 2311–2319.
Фонова Е. Г., Шитц О. А. К вопросу о профессиональных компетенциях переводчиков в эпоху искусственного интеллекта // Вестник Томского государственного педагогического университета, 2025. № 1(237). URL: https://doi.org/10.23951/1609-624X-2025-1-148-156 (дата обращения: 01.09.2025).
Чакырова Ю. И. Постредактирование — благодать или проклятие? // Индустрия перевода. 2013. № 1. С. 137.
Tarasti E. The Semiotics of A. J. Greimas: A European Intellectual Heritage Seen from the Inside and the Outside. Sign Systems Studies. 2017. URL: https://doi.org/10.12697/SSS.2017.45.1-2.03 (дата обращения: 19.05.2026).
Материалы исследования
Лингвистический энциклопедический словарь. М.: Сов. энциклопедия, 1990. URL: https://tapemark.narod.ru/les/392d.html (дата обращения: 03.09.2025).