
Terminology use in school textbooks: corpus analysis
The article presents the methods and results of the study that investigated the use of terminology in textbooks for secondary schools in Russia. The data were taken from a full-text DIY corpus of 207 textbooks for grades 5-11. The toolkit included models trained with the Word2Vec algorithms driven by the ideas of distributional semantics. The models were used to improve traditional automatic term extraction based on word frequency statistics. Numerical representation of word collocation patterns and their semantic similarity enabled the following: more effective automatic term extraction with a clear dividing line between terminology per se and high-frequency common words; comparative analysis of inventory and functioning of terms in textbooks for different school subjects and grades; analysis of the dynamics of new terms entering educational and methodological complexes and insights into terminological relations between textbooks for different grades. The study included another DIY corpus compiled of scholarly articles across the subjects taught at school. It was used to identify differences in term use in textbooks and scholarly texts as well as in non-specific and popular science contexts. The latter was facilitated by the RusVectōrēs word embedding model. The comprehensive analysis identified some patterns in term functioning relevant for particular school subjects or groups of subjects. The results were evaluated in view of the theory of text complexity, teaching methodology and didactics. The study found some contradictions between the expected and real text complexity. It also showed certain discrepancy between text complexity and basic didactic principles.
Figures


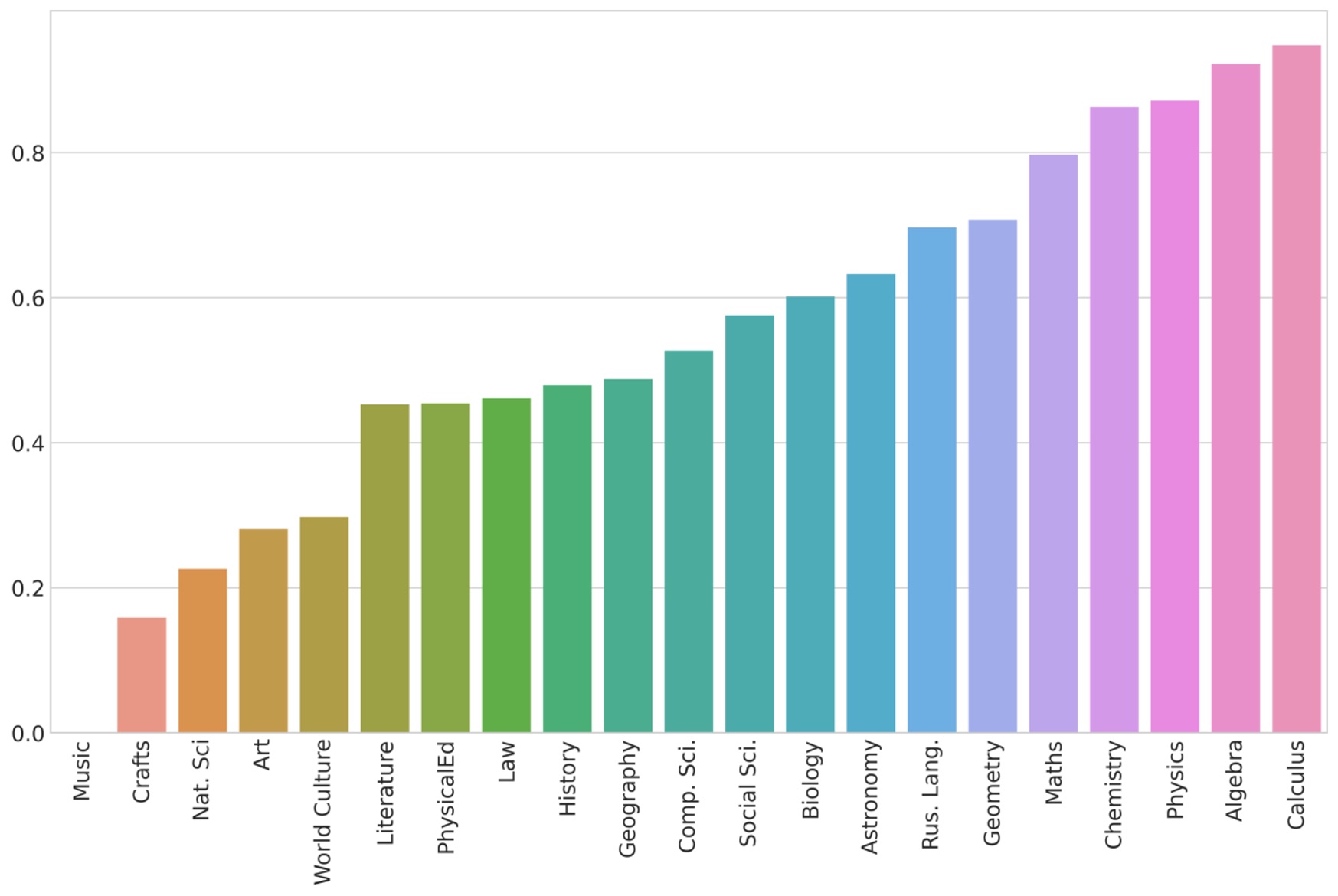


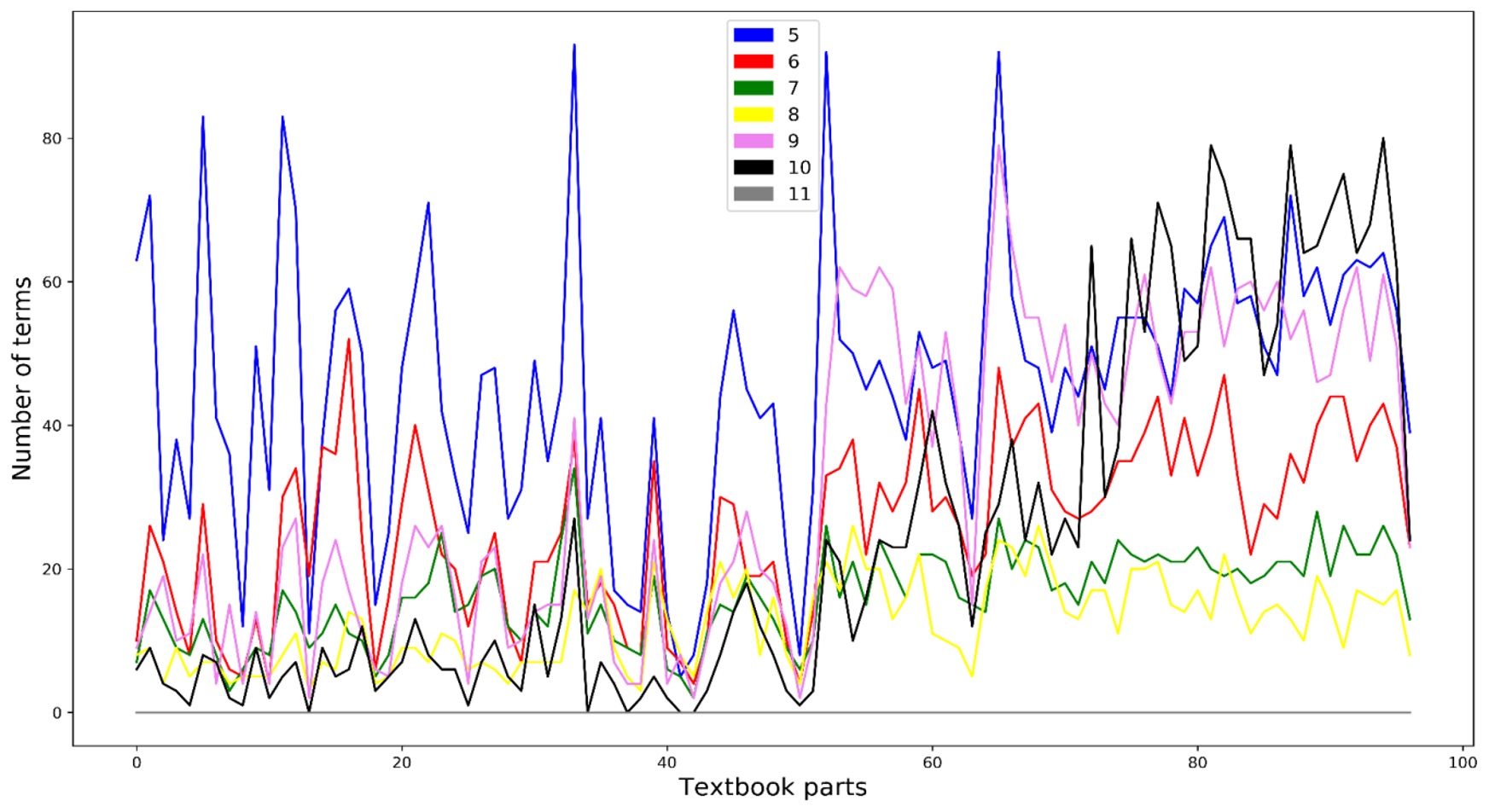

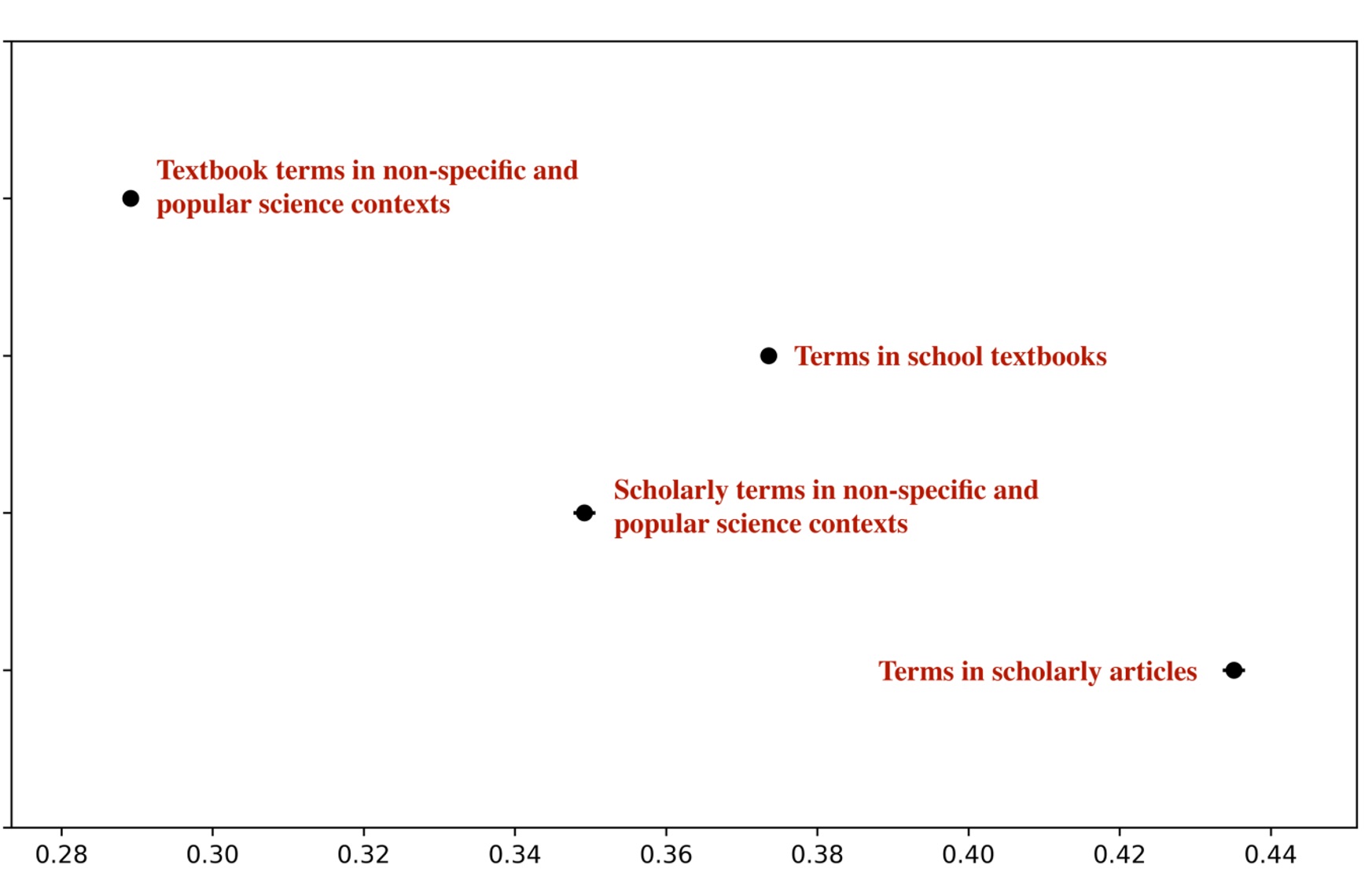
Monakhov, S. I., Turchanenko, V. V. and Cherdakov, D. N. (2023). Terminology use in school textbooks: corpus analysis, Research Result. Theoretical and Applied Linguistics, 9 (1), 27-49. DOI: 10.18413/2313-8912-2023-9-1-0-3












While nobody left any comments to this publication.
You can be first.
Brownlee, J. (2017). Deep Learning for Natural Language Processing: Develop Deep Learning Models for your Natural Language Problems, Machine Learning Mastery Publ., Vermont, USA. (In English)
Cabré, M. T., Estopà, R. and Vivaldi, J. (2001). Automatic Term Detection: a Review of Current Systems, in Bourigault, D., Jacquemin, Ch. and L’Homme, M.-C. (eds.), Recent Advances in Computational Terminology, John Benjamins Publ., Amsterdam, Netherlands, 53–87. DOI: 10.1075/nlp.2.04cab (In English)
Durda, K. and Buchanan, L. (2008). WINDSORS: Windsor Improved Norms of Distance and Similarity of Representations of Semantics, Behavior Research Methods, 40, 705–712. DOI: 10.3758/BRM.40.3.705 (In English)
Fisher, D., Frey, N. and Lapp, D. (2016). Text Complexity: Stretching Readers with Texts and Tasks, Corwin Press, Thousand Oaks, CA, USA. (In English)
Flor, M., Klebanov, B. and Sheehan, K. (2013). Lexical Tightness and Text Complexity, Proceedings of the 2th Workshop of Natural Language Processing for Improving Textual Accessibility (NLP4ITA), Atlanta, USA, 29–38. (In English)
Glazkova, A., Egorov, Yu. and Glazkov, M. (2021). A Comparative Study of Feature Types for Age-Based Text Classification, in van der Aalst, W. et al. (eds.), Analysis of Images, Social Networks and Texts. AIST 2020. Lecture Notes in Computer Science, 12602, Springer Publ., Cham, Switzerland, 120–134. (In English)
Iomdin, B. L. and Morozov, D. A. (2021). Who Can Understand “Dunno”? Automatic Assessment of Text Complexity in Children’s Literature, Russkaya Rech’, 5, 55–68. DOI: 10.31857/S013161170017239-1 (In Russian)
Jones, M. N. and Mewhort, D. J. K. (2007). Representing Word Meaning and Order Information in a Composite Holographic Lexicon, Psychological Review, 114, 1–37. DOI: 10.1037/0033-295X.114.1.1 (In English)
Kilgarriff, A., Jakubíček, M., Kovář, V. et al. (2014). Finding Terms in Corpora for Many Languages with the Sketch Engine, Proceedings of the Demonstrations at the 14th Conference the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 53–56. DOI: 10.3115/v1/E14-2014 (In English)
Korkontzelos, I. and Ananiadou, S. (2014). Term Extraction, in Mitkov, R. (ed.), Oxford Handbook of Computational Linguistics, Oxford University Press, Oxford, UK, 991–1012. (In English)
Kutuzov, A. and Kuzmenko, E. (2017). WebVectors: A Toolkit for Building Web Interfaces for Vector Semantic Models, in Ignatov, D. et al. (ed.), Analysis of Images, Social Networks and Texts. AIST 2016. Communications in Computer and Information Science, 661, Springer Publ., Cham, Switzerland, 155–161. (In English)
Laposhina, A. N., Lebedeva, M. U. and Berlin Khenis, A. (2022). Word Frequency and Text Complexity: An Eye-tracking Study of Young Russian Readers, Russian Journal of Linguistics, 26 (2), 493–514. DOI: 10.22363/2687-0088-30084. (In Russian)
Laposhina, А. N., Veselovskaya, Т. S., Lebedeva, M. U. and Kupreshchenko, O. F. (2019). Lexical Analysis of the Russian Language Textbooks for Primary School: Corpus Study, Computational Linguistics and Intellectual Technologies: papers from the Annual International Conference “Dialogue”, Moscow, Russia, 18 (25), 351–363. (In Russian)
Leichik, V. M. (2007). Terminovedenie: predmet, metody, struktura [Terminology Studies: Subject, Methods, Structure], LKI Publishing House, Moscow, Russia. (In Russian)
Levy, O. and Goldberg, Y. (2014). Linguistic Regularities in Sparse and Explicit Word Representations, Proceedings of the Eighteenth Conference on Computational Natural Language Learning, Baltimore, USA, 171–180. DOI: 10.3115/ v1/W14-1618 (In English)
Lukashevich, N. V. and Logachev, Yu. M. (2010). Combining Features for Automatic Term Extraction, Numerical Methods and Programming, 11 (4), 108–116. (In Russian)
Martynova, E. V., Solnyshkina, M. I., Merzlyakova, A. F. and Gizatulina, D. Yu. (2020). Lexical Parameters of the Academic Text (Based on the Texts of the Academic Corpus of the Russian Language), Philology and Culture, 3, 72–80. DOI: 10.26907/2074-0239-2020-61-3-72-80 (In Russian)
Mikk, Ya. A. (1981). Optimizatsiya slozhnosti uchebnogo teksta: V pomoshch' avtoram i redaktoram [Optimizing the complexity of educational text: To help authors and editors], Prosveshchenie, Moscow, Russia. (In Russian)
Mikolov, T., Sutskever, I., Chen, K. et al. (2013a). Distributed Representations of Words and Phrases and their Compositionality, Advances in Neural Information Processing Systems 26, 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, USA, 3136–3144. (In English)
Mikolov, T., Yih, W. T and Zweig, G. (2013b). Linguistic Regularities in Continuous Space Word Representations, Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, USA, 746–751. (In English)
Mitrofanova, O. A. and Zakharov, V. P. (2009). Automatic Analysis of Terminology in the Russian Text Corpus on Corpus Linguistics, Computational Linguistics and Intellectual Technologies: papers from the Annual International Conference “Dialogue”, Bekasosvo, Russia, 8 (15), 321–328. (In Russian)
Monakhov, S. I., Turchanenko, V. V. and Cherdakov, D. N. (2022). Terminology in Textbooks and Research Articles: Cluster Analysis of Corpus Data, Proceedings of 6th International Conference “Informatization of Education and E-learning Methodology: Digital Technologies in Education”, Krasnoyarsk, Russia, 3, 228–233. (In Russian)
Morozov, D. A. and Iomdin, B. L. (2019). Criteria of Semantic Complexity of Words, Computational Linguistics and Intellectual Technologies: papers from the Annual International Conference “Dialogue”, Moscow, Russia, 18 (25), 119–131. (In Russian)
Nokel, M. A., Bolshakova, E. I. and Loukachevitch, N. V. (2012). Combining Multiple Features for Single-word Term Extraction, Computational Linguistics and Intellectual Technologies: papers from the Annual International Conference “Dialogue”, Bekasosvo, Russia, 11 (18), 1, 490–501. (In English)
Piotrovsky, R. G. and Yastrebova, S. V. (1969). Statistical Term Recognition, in Piotrovskij, R. G. (ed.), Statistika teksta [Text statistics], Belorusskij gosudarstvennyj universitet, Minsk, Belarus, 1, 249–259. (In Russian)
Rohde, D. L., Gonnerman, L. M. and Plaut, D. C. (2006). An Improved Model of Semantic Similarity Based on Lexical Co-Occurrence, Communications of the ACM, 8, 627–633. (In English)
Schwanenflugel, P. J. (1991). Why are Abstract Concepts Hard to Understand?, in Schwanenflugel, P. J. (ed.), The psychology of word meanings, Lawrence Erlbaum Associates Inc., Hillsdale, USA, 223–250. (In English)
Sharoff, S. (2022). What Neural Networks Know about Linguistic Complexity, Russian Journal of Linguistics, 26 (2), 371–390. DOI: 10.22363/2687-0088-30178 (In English)
Shpakovsky, Yu. F. (2007). Estimation of Perception Difficulty and Optimization of the Educational Text Complexity (on the Material of Texts in Chemistry), Abstract of Ph.D. dissertation, Linguistics, Minsk State Linguistic University, Minsk, Belarus. (In Russian)
Solnyshkina, M. I. (2022). Measuring Text Complexity: State of the Art, Collection of Scientific Papers X Jubilee International Scientific Conference “Teacher. Student. Textbook (in the Context of Global Challenges of Modern Times)”, Moscow, Russia, 20–24. (In Russian)
Solnyshkina, M. I. and Kiselnikov, A. S. (2015). Text Complexity: Study Phases in Russian Linguistics, Tomsk State University Journal of Philology, 6 (38), 86–99. DOI: 10.17223/19986645/38/7 (In Russian)
Solnyshkina, M. I., McNamara, D. and Zamaletdinov, R. R. (2022). Natural Language Processing and Discourse Complexity Studies, Russian Journal of Linguistics, 26 (2), 317–341. DOI: 10.22363/2687-0088-30171 (In Russian)
Solovyev, V. D., Ivanov, V. V. and Solnyshkina, M. I. (2018). Assessment of Reading Difficulty Levels in Russian Academic Texts: Approaches and Metrics, Journal of Intelligent & Fuzzy Systems, 34 (2), 3049–3058. DOI: 10.3233/JIFS-169489 (In English)
Solovyev, V. D., Solnyshkina, M. I. and McNamara, D. (2022). Computational Linguistics and Discourse Complexology: Paradigms and Research Methods, Russian Journal of Linguistics, 26 (2), 275–316. DOI: 10.22363/2687-0088-30161 (In English)
Stepanova, D. V. (2017). Analiz metodov avtomaticheskogo vydeleniya terminov iz nauchno-tekhnicheskih tekstov [Analysis of Methods for Automatic Terms Extraction from Scientific and Technical Texts], Aktual'nye problemy sovremennoj prikladnoj lingvistiki [Current problems of modern applied linguistics], Minskij gosudarstvennyj lingvisticheskij universitet, Minsk, 62–67. (In Russian)
Tatarinov, V. A. (2006). Obshchee terminovedenie: Entsiklopedicheskij slovar' [Terminology Studies: Encyclopedic Dictionary], Moskovskij Litsej, Moscow, Russia. (In Russian)
Turney, P. D. and Pantel, P. (2010). From Frequency to Meaning: Vector Space Models of Semantics, Journal of Artificial Intelligence Research, 37, 141–188. DOI: 10.1613/jair.2934 (In English)
The reported study was funded by the Russian Foundation for Basic Research, Project number 19-29-14032 mk “Study of terminological subsystems of modern school textbooks in Russian with the help of word embedding models Word2Vec and neural networks”.