
Classification of Russian textbooks by grade level and topic using ReaderBench
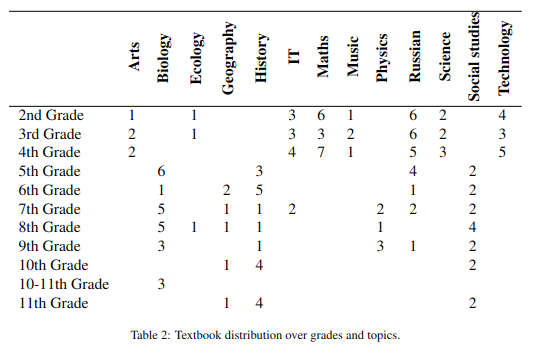
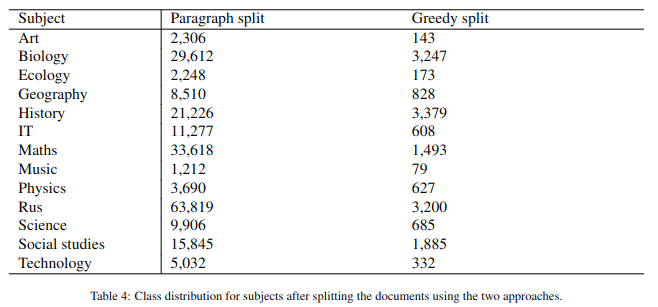
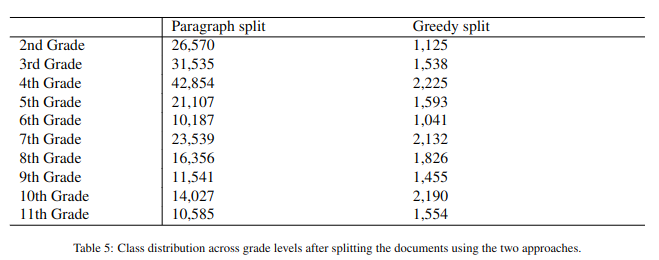
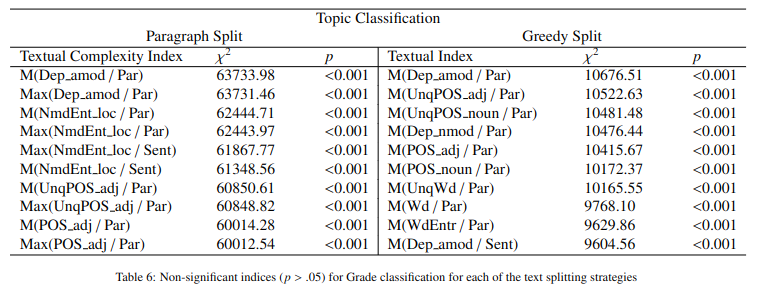
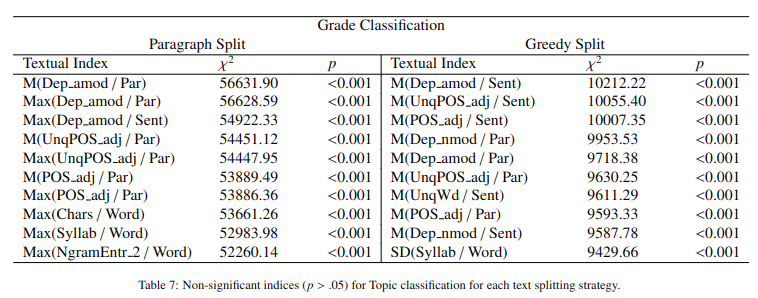
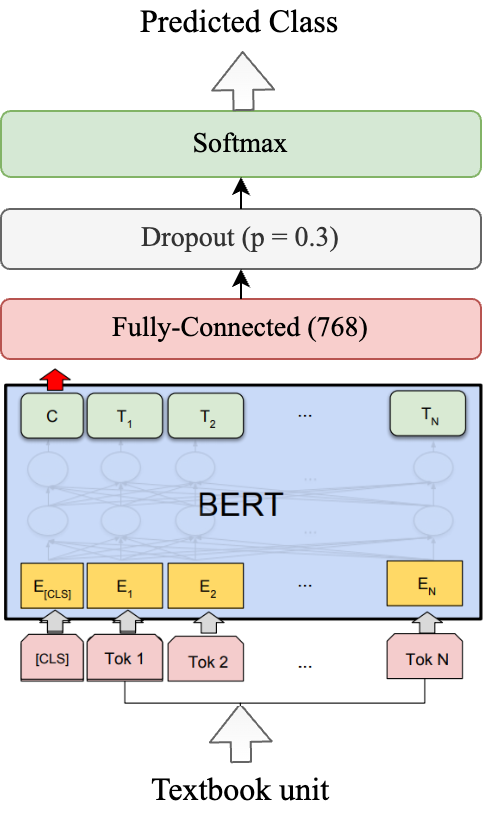
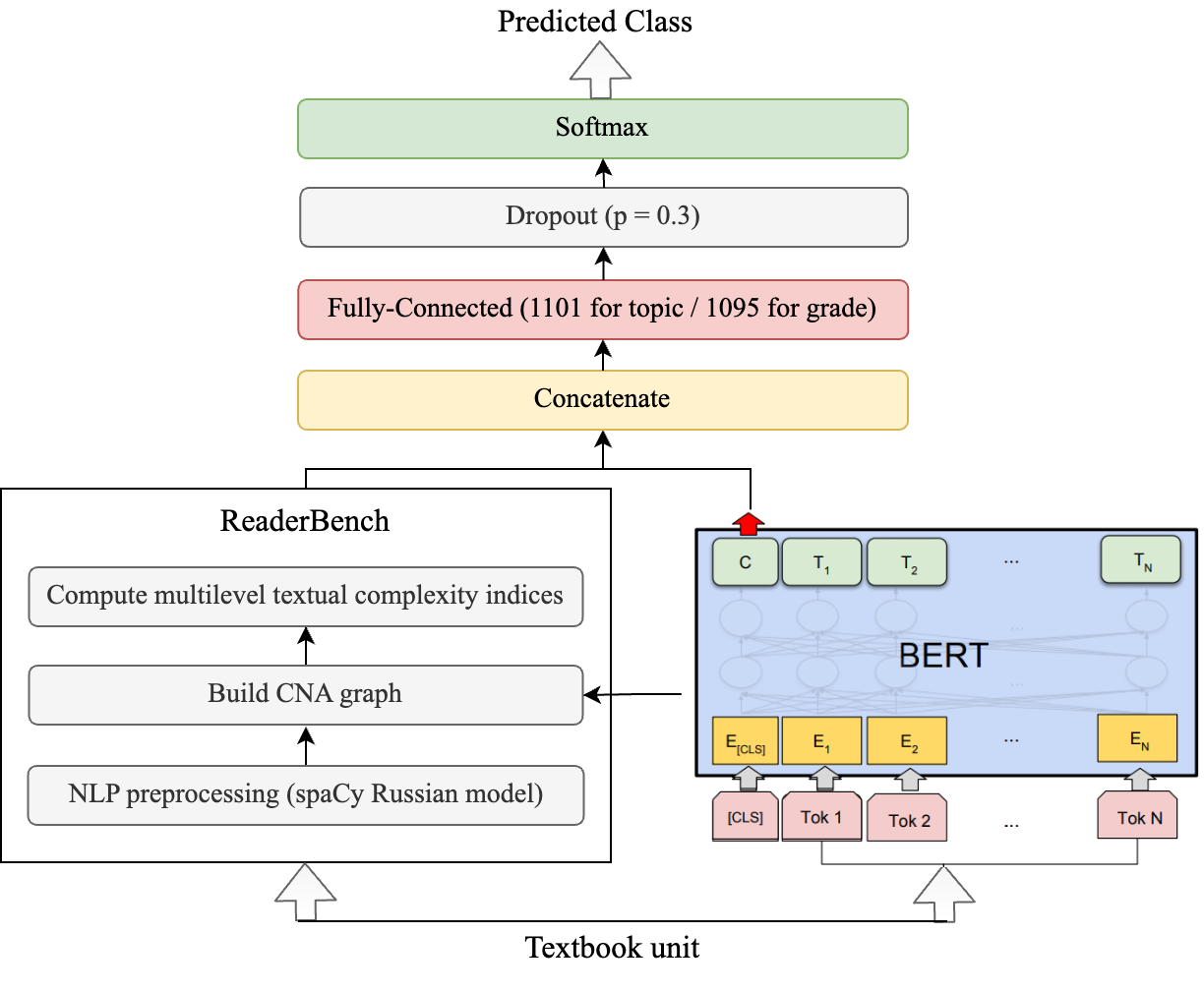
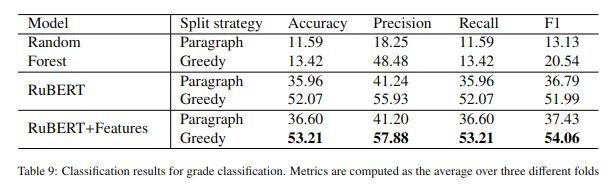
Textbooks are essential resources for classroom and offline reading, while the quality of learning materials guides the entire learning process. One of the most important factors to be considered is their readability and comprehensibility. Therefore, the correct pairing of textbook complexity and student grade level is paramount. This article analyzes automated classification methods for Russian-language textbooks on two dimensions, namely the topic of the text and its complexity reflected by its corresponding school grade level. The studied corpus is a collection of 154 textbooks from the Russian Federation from the second to the eleventh grade levels. Our analysis considers machine learning techniques on the textual complexity indices provided by the open-source multi-language framework ReaderBench and BERT-based models for the classification tasks. Additionally, we explore using the most predictive ReaderBench features in conjunction with contextualized embeddings from BERT. Our results argue that incorporating textual complexity indices improves the classification performance of BERT-based models on our dataset split using 2 strategies. More specifically, the F1 score for topic classification improved to 92.63%, while the F1 score for school grade-level classification improved to 54.06% for the Greedy approach in which multiple adjacent paragraphs are considered a single text unit up until reaching the maximum length of 512 tokens imposed by the language model.
Figures




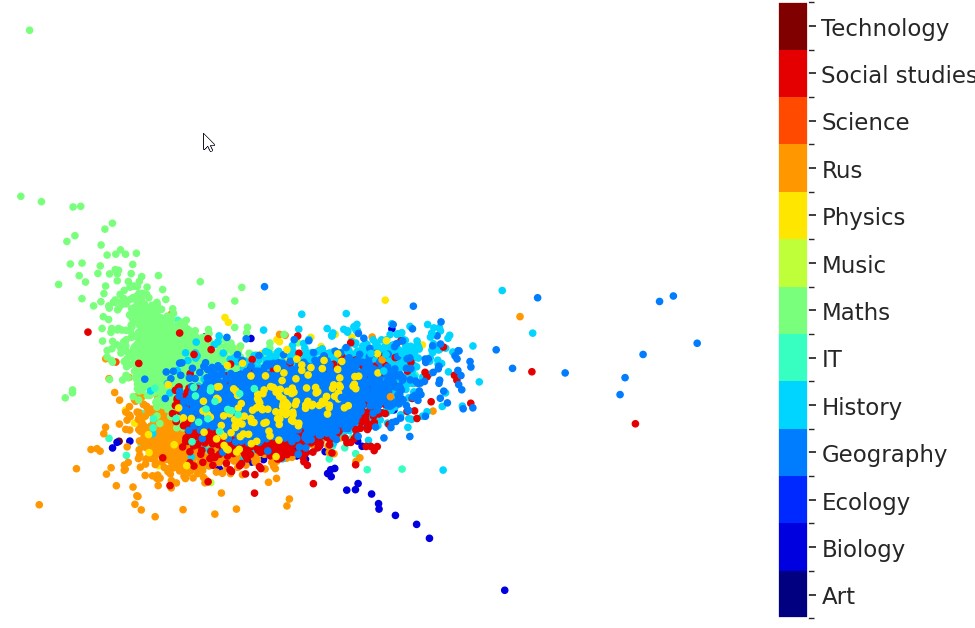


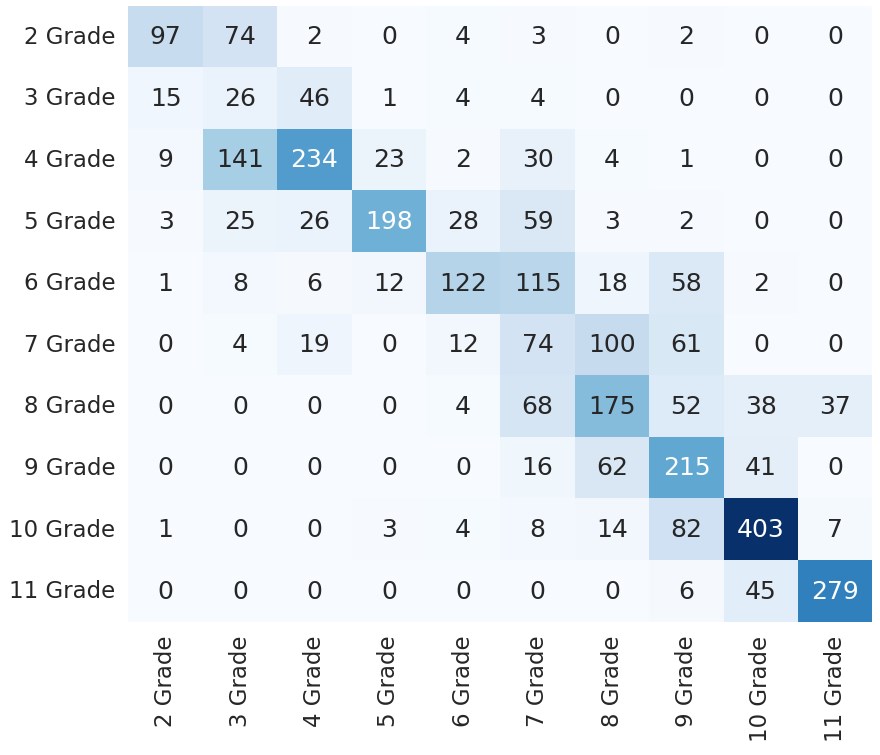
Paraschiv, A., Dascalu, M. and Solnyshkina, M. I. (2023). Classification of Russian textbooks by grade level and topic using ReaderBench, Research Result. Theoretical and Applied Linguistics, 9 (1), 50-63. DOI: 10.18413/2313-8912-2023-9-1-0-4












While nobody left any comments to this publication.
You can be first.
Bansiong, A. J. (2019). Readability, content, and mechanical feature analysis of selected commercial science textbooks intended for third grade Filipino learners, Cogent Education, 6, 1706395. DOI: 10.1080/2331186X.2019.1706395(In English)
Batinic, D., Birzer, S., Zinsmeister, H. (2017). Automatic classification of Russian texts for didactic purposes, Trudy meždunarodnoj konferencii “Korpusnaja lingvistika”, Sankt-Peterburg, Russia, 9-15. (In English)
Beníčková, Z., Vojíř, K. and Held, L., (2021). A comparative analysis of text difficulty in Slovak and Canadian science textbooks, Chemistry-Didactics-Ecology-Metrology, 26 (1-2), 89–97. DOI: 10.2478/cdem-2021-0007 (In English)
Bosco, G. L., Pilato, G. and Schicchi, D. (2021). Deepeva: A deep neural network architecture for assessing sentence complexity in Italian and English languages, Array, 12, 100097. (In English)
Brown, P. F., Della Pietra, S. A., Della Pietra, V. J., Lai, J. C. and Mercer, R. L. (1992). An estimate of an upper bound for the entropy of English, Computational Linguistics, 18, 31–40. (In English)
Chatzipanagiotidis, S., Giagkou, M. and Meurers, D. (2021). Broad linguistic complexity analysis for Greek readability classification, Proceedings of the 16th Workshop on Innovative Use of NLP for Building Educational Applications, 48–58. (In English)
Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, E., Wang, X., Dehghani, M., Brahma, S. et al. (2022). Scaling instruction- finetuned language models, arXiv preprint arXiv:2210.11416. https://doi.org/10.48550/arXiv.2210.11416(In English)
Churunina, A., Solnyshkina, M., Gafiyatova, E. and Zaikin, A. (2020). Lexical features of text complexity: the case of Russian academic texts, SHS Web of Conferences, 88, 01009. https://doi.org/10.1051/shsconf/20208801009(In English)
Corlatescu, D., Ruseti, S. and Dascalu, M. (2022). Readerbench learns Russian: Multilevel analysis of Russian text characteristics, Russian Journal of Linguistics, 26 (2), 342–370. https://doi.org/10.22363/2687-0088-30145(In English)
Crossley, S. A., Greenfield, J. and McNamara, D. S. (2008). Assessing text readability using cognitively based indices, Tesol Quarterly, 42, 475–493. https://doi.org/10.1002/j.1545-7249.2008.tb00142.x(In English)
Dascalu, M., Gutu, G., Ruseti, S., Paraschiv, I. C., Dessus, P., McNamara, D. S., Crossley, S. A. and Trausan-Matu, S. (2017). ReaderBench: a multi-lingual framework for analyzing text complexity, Data Driven Approaches in Digital Education: 12th European Conference on Technology Enhanced Learning, EC-TEL 2017, Tallinn, Estonia, 495–499. https://doi.org/10.1007/978-3-319-66610-5_48(In English)
Dascalu, M., McNamara, D. S., Trausan-Matu, S. and Allen, L. (2018). Cohesion network analysis of CSCL participation, Behavior Research Methods, 50, 604–619. https://doi.org/10.3758/s13428-017-0888-4(In English)
Ivanov, V. V. (2022). Sentence-level complexity in Russian: An evaluation of BERT and graph neural networks, Frontiers in Artificial Intelligence, 5. https://doi.org/10.3389/frai.2022.1008411 (In English)
Khine, M. S. (2013). Analysis of science textbooks for instructional effectiveness, in Khine, M. S. (ed.), Critical Analysis of Science Textbooks: Evaluating instructional effectiveness, Springer, Dordrecht, Netherlands, 303-310. http://doi.org/10.1007/978-94-007-4168-3_15(In English)
Kincaid, J. P., Fishburne Jr, R. P., Rogers, R. L. and Chissom, B. S. (1975). Derivation of new readability formulas (Automated Readability Index, Fog count and Flesch Reading Ease formula) for navy enlisted personnel, Institute for Simulation and Training, 56. (In English)
Kruskal, W. H. and Wallis, W. A. (1952). Use of ranks in one-criterion variance analysis, Journal of the American statistical Association, 47, 583–621. https://doi.org/10.2307/2280779(In English)
Kuratov, Y. and Arkhipov, M. (2019). Adaptation of deep bidirectional multilingual transformers for Russian language, arXiv preprint arXiv:1905.07213. https://doi.org/10.48550/arXiv.1905.07213(In English)
Lu, Z., Du, P. and Nie, J. Y. (2020). VGCN-BERT: augmenting BERT with graph embedding for text classification, Advances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 12035, 369–382. https://doi.org/10.1007/978-3-030-45439-5_25(In English)
Norris, J. M. and Ortega, L. (2009). Towards an organic approach to investigating CAF in instructed SLA: The case of complexity, Applied linguistics, 30 (4), 555–578. https://doi.org/10.1093/applin/amp044(In English)
Sakhovskiy, A., Solovyev, V. and Solnyshkina, M. (2020). Topic modeling for assessment of text complexity in Russian textbooks, 2020 Ivannikov Ispras Open Conference (ISPRAS), Moscow, Russia, 102–108. https://doi.org/10.1109/ISPRAS51486.2020.00022(In English)
Santucci, V., Santarelli, F., Forti, L. and Spina, S., (2020). Automatic classification of text complexity, Applied Sciences, 10, 7285. https://doi.org/10.3390/app10207285(In English)
Shannon, C. E. (1948). A mathematical theory of communication, The Bell System Technical Journal, 27 (3), 379–423. https://doi.org/10.1002/j.1538-7305.1948.tb01338.x(In English
Shapiro, S. S. and Wilk, M. B. (1965). An analysis of variance test for normality (complete samples), Biometrika, 52 (3/4), 591–611. https://doi.org/10.2307/2333709(In English)
Solovyev, V., Ivanov, V. and Solnyshkina, M. (2018). Assessment of reading difficulty levels in Russian academic texts: Approaches and metrics, Journal of Intelligent & Fuzzy Systems: Applications in Engineering and Technology, 34 (5), 3049–3058. https://doi.org/10.3233/JIFS-169489(In English)
Solovyev, V. D., Ivanov, V V. and Akhtiamov, R. B. (2019). Dictionary of abstract and concrete words of the Russian language: a methodology for creation and application, Research in Applied Linguistics, 10, 218–230. https://doi.org/10.22055/RALS.2019.14684(In English)
Solovyev, V., Solnyshkina, M., Gafiyatova, E., McNamara, D. and Ivanov, V. (2019). Sentiment in academic texts, Proceedings of the 24th Conference of Open Innovations Association FRUCT, IEEE Computer Society, Moscow, Russia, 408–414. https://doi.org/10.23919/FRUCT.2019.8711900(In English)
Solovyev, V., Ivanov, V. and Solnyshkina, M. (2020a). Thesaurus-based methods for assessment of text complexity in Russian, Advances in Computational Intelligence: 19th Mexican International Conference on Artificial Intelligence, MICAI 2020, Proceedings, Part II, Mexico City, Mexico, 152–166. https://doi.org/10.1007/978-3-030-60887-3_14(In English)
Solovyev, V. D., Solnyshkina, M., Andreeva, M., Danilov, A. and Zamaletdinov, R. (2020b). Text complexity and abstractness: Tools for the Russian language, Proceedings of the International Conference “Internet and Modern Society” (IMS-2020), St. Petersburg, Russia, 75–87. (In English)
Swanepoel, S. (2010). The assessment of the quality of science education textbooks: Conceptual framework and instruments for analysis, Ph.D. Thesis, University of South Africa, Pretoria, South Africa. (In English)
Wakefield, J. F. (2006). Textbook usage in the United States: The case of US history, International Seminar on Textbooks, Santiago, Chile, Online Submission. (In English)
Xanthopoulos, P., Pardalos, P. M. and Trafalis, T. B. (2013). Linear discriminant analysis, Robust Data Mining, Springer, 27–33. (In English)
Zipitria, I., Sierra, B., Arruarte, A. and Elorriaga, J. A. (2012). Cohesion grading decisions in a summary evaluation environment: A machine learning approach, Proceedings of the Annual Meeting of the Cognitive Science Society, 34, 2615–2620. (In English)
This work was supported by a grant of the Ministry of Research, Innovation and Digitalization, Project CloudPrecis, Contract Number 344/390020/06.09.2021, MySMIS code: 124812, within POC. We thank the Research Lab Text Analytics at Kazan Federal University for assisting in compiling the corpus of academic texts and cooperating to conduct the research.