
Machine translation in hindsight
Abstract
The paper expands on the analysis of key projects adoring the machine translation (MT) hall of fame and their role in addressing practical tasks. The most successful initiatives suggest that the fledgling MT was contingent on the level of entropy, a.k.a. random nature of natural languages: the lower the indicator, the higher the predictability of the text, and by implication the efficiency of the system. It accounts for the success of the first Georgetown-IBM experiment and Canada’s METEO-1. The letter grew into a full-fledged system that for almost a quarter of the 20th century, provided English-French-English translations of weather bulletins, boasting high language predictability. Although, in between them the 1964 ALPAC report sowed a seed of doubt of the MT validity, it never aimed at killing the research area at all. On the contrary, it highlighted technics and applications, where the technology had demonstrated promising results, including raw MT, post-edited MT, and M-AT. The authors note a cyclic nature of the development of MT-powered methods and technologies. Today’s combination of resources and the way they are used are different very little from those employed in the past century. What makes them stand apart is the maturity of MT technologies, which made it through rule-based, direct, corpus-based, and knowledge-based translation to SMT and eventually to NMT. It has been established that the improved performance comes at a cost of more elaborate and larger data sets, tagged, marked up and annotated for automated use in language models. Taking advantage of these as well as artificial intelligence (AI), the authors venture into modeling basic text processing scenarios in a bilingual environment. This results in recommendations as to future paths for the improvement of MT technologies in the hands of professional translators by fine-tuning language models individually and pursuing post-editing (PEMT) and pre-editing practices paving the way for more complex transformations and lower equivalence levels.
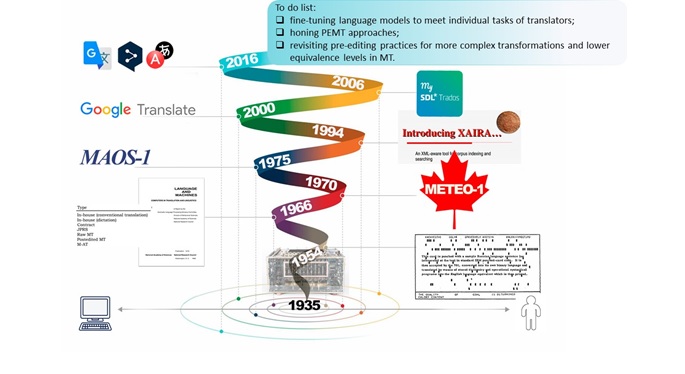
Introduction
From the first practical attempts of P. Troyansky and G. Artsrouni to automate translation, machine translation (MT) endeavors have never disappeared from the agenda of computational linguistics for a single day (Hutchins, 2004a). Prior to the era of personal computers, efforts were redirected to other fields for long periods due to the technical limitations of computers. Today, MT is one of the fastest growing areas in the field of computational linguistics and artificial intelligence (AI). With the advent of modern technologies based on neural networks and deep learning, accuracy, quality, and alternatives in MT providers have increased exponentially. For the average consumer, knowledge in this area is limited to the last dozen years. It was in this period that it became feasible to take the human out of the loop when it came to familiarizing with a text in a foreign language. Meanwhile, back in the days when computer linguistics was just taking shape, there were many milestones and working solutions, considerably ahead of their time and the state of computer technology. We believe that some of them have retained their relevance to this day, thus it is reasonable to consider the possibility of bringing them to maturity, prompted by advanced hardware. Given this, the paper will analyze the most prominent projects in the MT field to determining their applicability and viability in today’s environment. The goal calls for a phased approach covering the following tasks:
1. Shortlisting milestone projects.
2. Analyzing their application.
3. Considering pros and cons of each project.
4. Determining the primary reason for their success.
5. Testing the findings in modern hardware/software combinations.
Background
The history of MT is an endeavor to develop a fully-automatic general-purpose high-quality machine translation system (FGH-MT), which still remains elusive not least because of the creative nature of translation. However, this turns out to be relative, for “MT is completely possible in some fields like science, technology, law, and medicine (Fumani and Reza, 2007).” On the other hand, “achieving paraphrase level or dynamic equivalence between the source and target language still appears to be a far-fetched dream (Oladosu et al., 2016).” This will demand compound transformations, often resulting in a lower level of equivalence, which is the case in literary translation. Replete with inferences, such texts prove to be tough for MT. (López et al., 2010) sums it up: “The more general the domain or complex the style of the text, the more difficult it is to achieve a high-quality translation.”
The MT quality varies and depends among other things on the type of software, which breaks down into two main categories: single and hybrid approaches (Oladosu et al., 2016). The former is based on one method, rule-based, direct, corpus-based, and knowledge-based approaches to MT, while the other is a combination of the statistical method (SMT) and the rule-based approach, which includes a word-based model, a phrase-based model, a syntax-based model, and forest-based model (Gashaw and Shashirekha, 2019). Most single approaches demonstrate poor performance in large scale applications and produce a “shallower representation of knowledge resulting in lower quality (Gashaw and Shashirekha, 2019).”
In the 1990s, in the spot light of MT researches were focused on SMT projects, which sprouted from the Candide Project at IBM in the late 1980s (Brown et al., 1993). The model also marked the departure from word-based to phrase-based MT.
25 years and numerous efforts later, the MT community arrived at neural MT (NMT). This is the latest breakthrough, which received a wide-spread recognition. The quality of general translation sky-rocketed, as evidenced in accounts of the use of Google, DeepL, and Yandex (O'Brien et al., 2014). It does provide for basic translation in language pairs that do not have parallel corpus in a process called “zero-shot translation” (Costa-jussa et al., 2017).
This said, NMT has many challenges, such as “domain mismatch, size of training data, rare words, long sentences, word alignment, and beam search (Gashaw and Shashirekha, 2019).” The new model still relies on parallel corpora with the-more-the-better being still fundamental for its training, therefor ad-hoc domains remain beyond its grasp (Hurskainen, 2018).
Another significant hurdle is that the data set needs to be prepared for processing by language models. Mostly it boils down to attaching labels “showing the role of each word in a sentence” (Hurskainen, 2018). Done through mark-up, tagging, and annotation, the process still relies on manual disambiguation.
From the application perspective, machine translation remains a human-in-the-loop technology as well. True, the computer now shoulders a larger share of the burden, but the final touch still belongs to a human translator (Bharati et al., 2003). This collaboration transpires today through pre- and post-editing and computer-assisted solutions (O'Brien et al., 2014).
Materials and methods
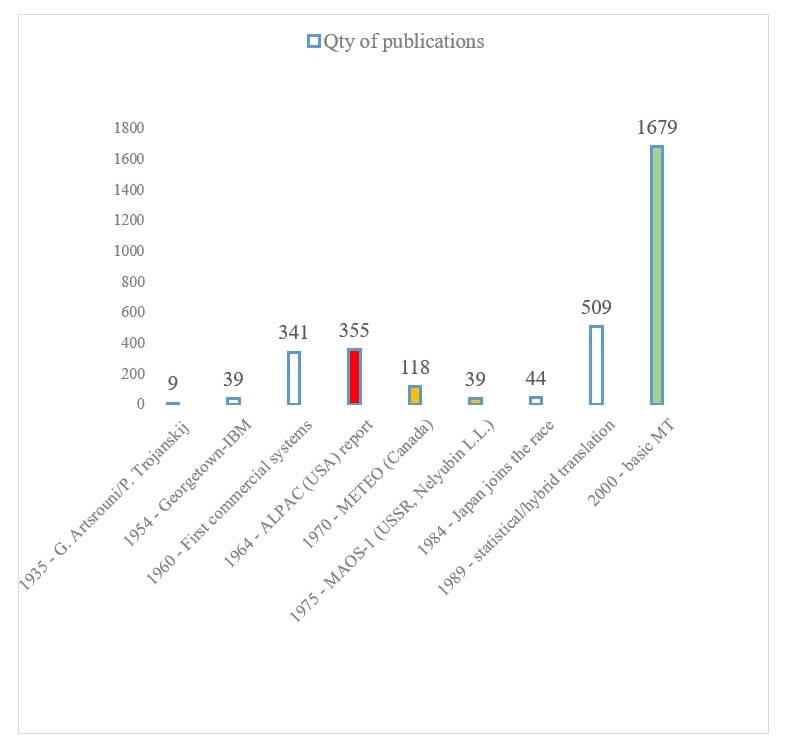
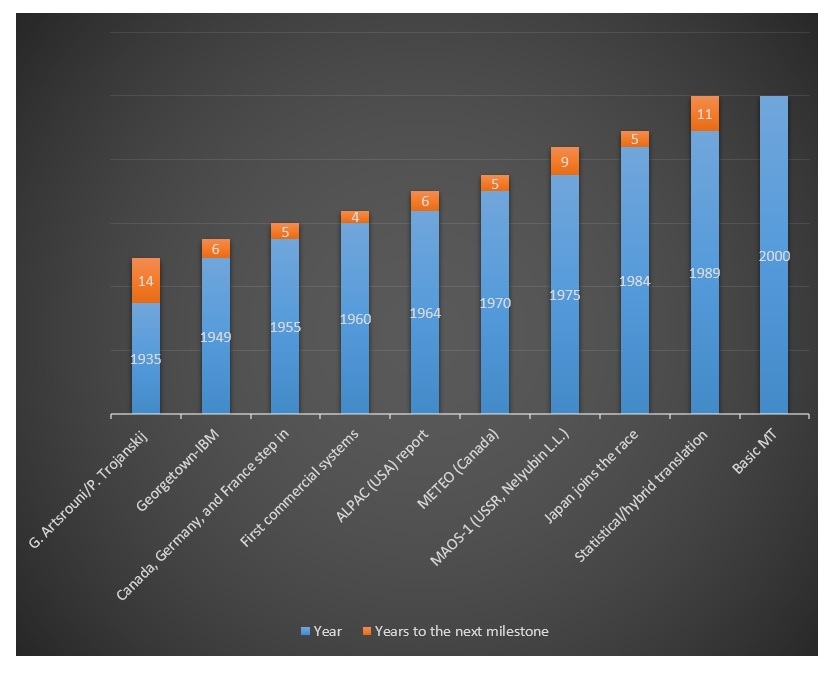
Machine translation has been on the agenda of linguists for more than half a century. Its path has been cloudless by no means. The roller-coaster trajectory, common to any research effort, was also conditioned by the limitations of the nascent computer technology, which made it impossible to fully implement the concept at certain stages (see Figure 1).
Figure 1. Density of MT researches[1]
Рисунок 1. Плотность исследований в области машинного перевода
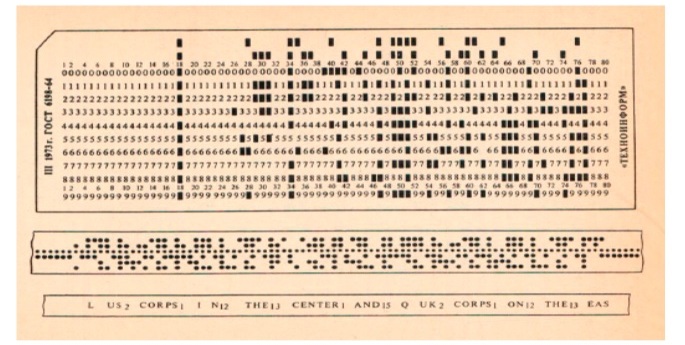
Not only did the computer's own ability to convert information to other languages seriously limit the research potential, but the ways of inputting raw data as well. In the first 30-40 years, scientists had to make do with punch cards, which took some time to prepare (see Figure 2) (Nelyubin, 1983).
Figure 2. Information on punch card, punch tape and control tape
Рисунок 2. Информация на перфокарте, перфоленте и контрольной ленте
Despite the labor-intensive process of preparing the material, MT visionaries continued to move towards their goals. The first results were a real breakthrough for their time. For example, the Georgetown-IBM experiment, a joint effort between the eponymous university and IBM in 1949-1954, managed to translate about 60 sentences with 60% accuracy. The project was based on the use of grammar rules and dictionary databases to translate from Russian into English (Daems et al., 2017). Short sentences were chosen for demonstration in line with to the level of development of the system. Another thing that stands out, however, is the area from which the text samples were taken. Most of the simple statements were about processes in organic chemistry (see Table 1) (Hutchins, 2004b).
Table 1. Sentences, selected for the demonstration of the results of the Georgetown-IBM experiment (Ornstein, 1955)
Таблица 1. Предложения для демонстрации результатов Джорджтаунского эксперимента
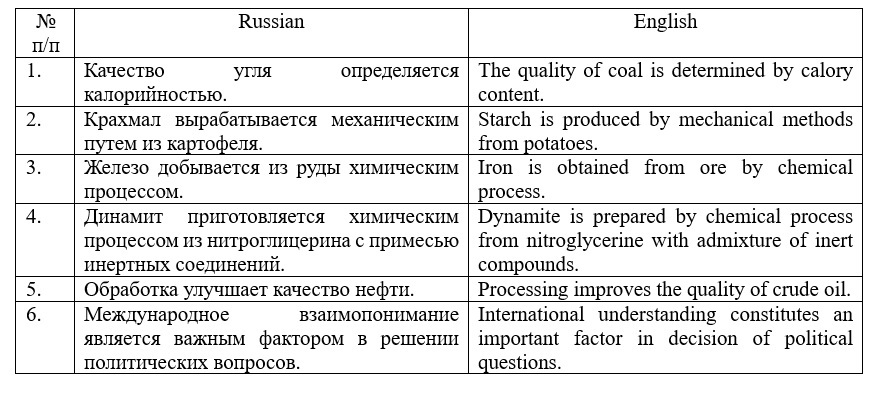
For the purpose of demonstration, general examples were selected as well. Though there were few of them so that it is not possible to draw unambiguous conclusions as to the quality of translation in comparison with technical samples. We can only note some lexical errors. For example, in line 6 of Table 1, solving and issues should be used instead of decisions and questions, respectively. The program coped better with the organic chemistry sentences. Thanks to the terminology, the developers eliminated lexical ambiguity. The direction of translation was also beneficial: the English language, into which the translation was performed, is characterized by a polysemantic vocabulary, which reduced the variability of translation of individual lexical units.
Fifteen years later, still with technology lagging behind MT ideas, a second milestone project, dubbed METEO, was successfully implemented to translate weather bulletins from English into French and back (Nirenburg, 1993). In contrast to the American experiment, the Canadian system evolved to a full-fledged system, translating 80,000 words of weather reports per day until 2001.
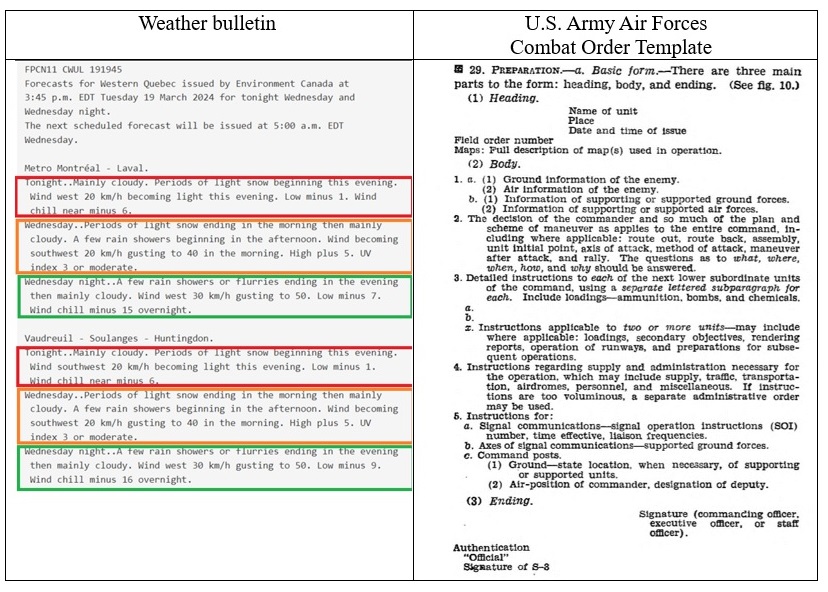
At the same time, Soviet and Russian scientist L. L. Nelyubin carried out a similar project, called MAOS-1/2/3 (Machinny Avtomatizirovanny Otraslevoy Slovar, Russian for Automated Ad-hoc Dictionary) (Nelyubin, 1975). The system provided translation of NATO military documents from English into Russian. The Canadian and Soviet experience was in many ways similar to each other and to the Georgetown-IBM experiment. The three milestones were "doomed" to success due to the lack of ambitions to create a one-stop shop in MT: the American team could not think of this, being pioneers in the field, while their colleagues from Canada and the USSR chose narrow fields to see their projects mature to useful MT tools. The second important factor was the choice of relatively limited sublanguages designed to convey messages in template documents (see Table 2).
Table 2. Sample weather bulletin[2] on the official Canadian government website and the U.S. Army Air Forces Combat Order template [3]
Таблица 2. Образцы погодной сводки на официальном сайте правительства Канады и шаблон боевого приказа военно-воздушного корпуса СВ США
This is accounted for by entropy, a measure of randomness in a situation (Weaver, 1949). First coined by Ludwig Boltzmann and J. Willard Gibbs in the statistical thermodynamics formulation in the 1870s, the term was later adopted in Information Theory by Claude Shannon and Ralph Hartley in the 1940s[4].
In linguistics it determines the probability of the next word in a sentence. For example, in Table 3 predicates (2) preceded by the aviation engine type (1) in the role of a subject (1) dictate the use of an aircraft equipped with the engine in sentence 1 or the amount of thrust it can develop in sentence 2. The level of entropy gets higher at the beginning of a sentence and drops down with every next word. For the sake of comparison, the predicates (1) alone can be followed by any other word, including a preposition. The phenomenon is at the core of the sentence builder ESL activity, where the probability of the word sequence is of the essence.
Table 3. Entropy in natural languages[5][6]
Таблица 3. Энтропия в естественном языке

Due to the complex nature of the task at hand, luck did not always favor scientists. There were protracted periods of search, which sometimes led to conclusions that further research was not worthwhile. The Georgetown-IBM experiment was followed by a decade-long lull that led to the negative recommendations by the U.S. Advisory Committee on Automatic Language Processing (ALPAC) in 1966. The report rated machine translation unsatisfactory in three areas: cost, quality and time. Experimentally it was found that familiarization with a research article on physics, translated by a machine, required 21% more time, while the degree of assimilation of the material fell by 29%. At the same time, the accuracy of information perception dropped by 10%. As a result of post-editing the indicators were improved to 11%, 13% and 3%, respectively.[7] Bringing the MT output to a satisfactory one required additional time, which sometimes reached several weeks.[8] In terms of cost-effectiveness, machines did not do better than humans, either. For example, a translation, contracted to a third party, was $50 cheaper with quality indicators approaching good compared to satisfactory MT outputs with post-editing (see Figure 3).
Figure 3. Comparative evaluation of the cost of human, machine and automated translation[9]
Рисунок 3. Сравнительная оценка стоимости перевода, выполненного человеком, машиной и в автоматизированном режиме
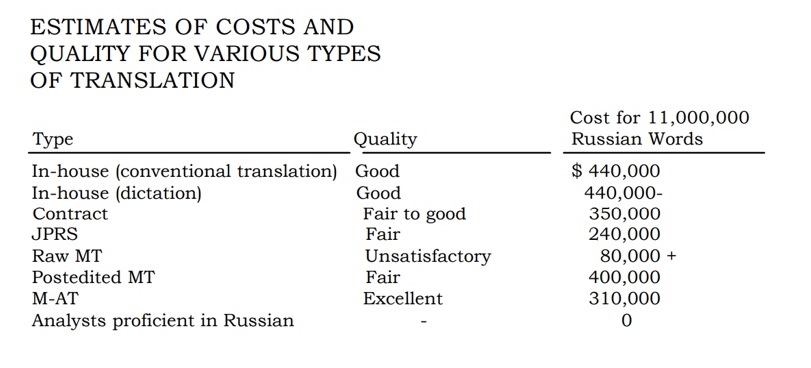
The reason for such outright criticism of the fledgling MT was accounted for by the inflated expectations. In contrast to the successful METEO and MAOS, the U.S. Air Force's Department of Foreign Technology and the National Atomic Energy Laboratory in Oak Ridge, USA, set out to fully automate the translation of research texts, which, although rich in terminology, were still highly entropic due to the use of an unlimited sublanguage. Standing out in this report is M-AT (machine-assisted translation), in which a machine was assigned the task of vocabulary management, but the translation was still performed by a human. The results of this approach were rated excellent with a 25% reduction in cost relative to conventional translation.
Negative feedbacks did not kill the MT domain, but rather prompted dips in research intensity. In the era of conventional media, it took some time for information to spread, in average 10 years for critical decisions to take its toll. For example, even the success in Canada, which had international publicity, did not bring research intensity out of the downward trend triggered by the ALPAC report (see Figure 1). The lack of a complete break in the line of MT researches is accounted for by the gradual involvement of other states, supporting their national languages. For example, Japan entered the race the lowest point of the MT popularity.
Results and discussions
From the very first attempt at practical implementation of MT, scientists and developers understood the centrality of the data sets needed to train systems. Therefore, the initial task was to work on quantitative indicators, which presented a certain challenge in the conditions of immature text recognition technologies. However, the analysis of the first complex MT systems pointed to the need to enhance the computer's perception of natural language. The basic perception of text in the form of groups of symbols did not provide much for text transformations, something to consider when it comes to achieving adequate translation.
In order to track the MT research trajectory in hindsight, it was decided to upgrade the MT research repository collected by John Hutchins into an ad-hoc corpus.[10] Using the AntConc[11] corpus-manager, a frequency list of the corpus of 1,058,811 tokens (18,800 words) and concordances for a group of selected key words were compiled (see Table 4). To extend the coverage of queries, all words were reduced to their base with the wild-card * replacing the endings to open options for wider variations (Gruzdev and Kodzhebash, 2023).
Table 4. Queries based on selected words (green – corpus development, yellow – corpus quality improvement, orange – corpus employment)
Таблица 4. Запросы на основе отобранных лексических единиц из частотного списка (зеленый – разработка корпуса, желтый – совершенствование качественного состава массивов, оранжевый – использование корпуса)
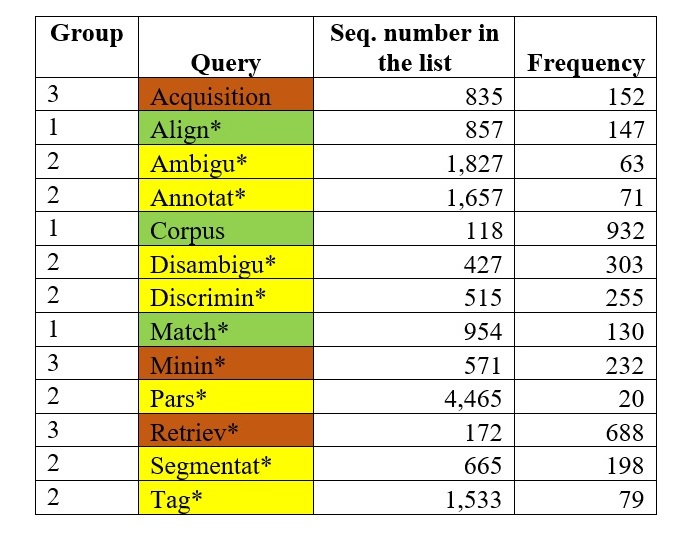
In total, three complex queries were generated: (1) corpus compilation, (2) corpus annotation, and (3) linguistic information mining. The concordances were further subjected to additional processing in MS Excel to calculate the density of word occurrences every five years, the intervals being established on the basis of the average gap between significant events over the entire research trajectory (see Figure 4). Because the corpus was compiled from the publishing data of research papers, each line contained the publishing date. We took advantage of this feature of the concordances and applied the function COUNTIF to the entire range. For example, =COUNTIF(A1:A15972;"=*1940*") counts the quantity of all papers published in 1940.
Figure 4. Milestones in the development of machine translation
Рисунок 4. Вехи в развитии машинного перевода
The results of processing the three concordances against the background of the aggregate total of MT papers per each interval have been summarized in Figure 5 for further analysis.
Figure 5. Nature of MT research in different periods
Рисунок 5. Характер исследований в области МП в разные периоды
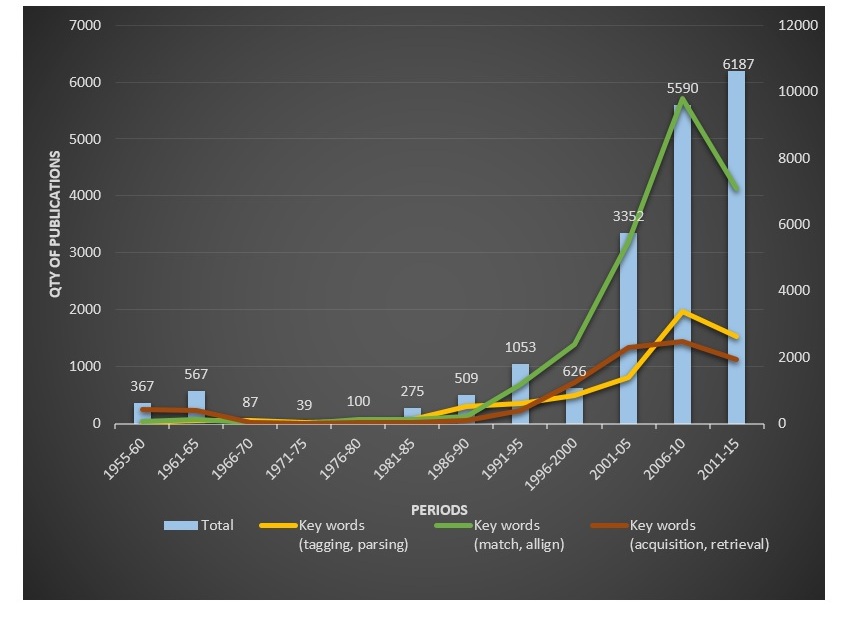
After the first corpora were created, scientists moved on to practical steps to extract the necessary linguistic information. In 1966, it became clear that the corpora still needed to be prepared to expand the horizon of applied MT researches. As a result, data mining improvement was excluded from the MT agenda for the next 20 years. Throughout the period, the corpus did not undergo major changes, being basically a large database of textual information selected according to certain criteria. By 1990, researches already had developed an idea of how corpora could be used, and computers were taught to “understand” texts. This was a watershed moment, marking the beginning of the modern phase of MT development. All three paths scrutinized in the three concordances got an impetus: development of new types of corpora, improvement of information retrieval methods and teaching computers to understand all levels of language.
By this time, a solution to bring the perception of texts by a computer closer to human abilities had taken shape. It was based on annotation and markup and encompassed the main language levels, namely: phonetic, prosodic, orthographic, semantic, morphological, syntactic, and anaphoric (Gruzdev and Kodzhebash, 2023). At the initial stage, all manipulations were done manually, but by the end of the century it had been realized that automation of the process was needed to handle multimillion-token corpora. However, by 2010 the problem had not been completely addressed with only POS (part of speech) reaching accuracy of 95% in the automatic mode (Névéol et al., 2010).
It is the markup and annotation that allows the silicon brain to correctly transfer information from one language to another. Without it, the computer has a two-dimensional picture of the text. The computer can fathom the language levels only after the information about the role of each lexical unit has been integrated into the data set. Table 5 shows an example of a sentence translation by the SMT version of Google Translate at the dawn of annotation.[12]
Table 5. Translation done by SMT Google Translate
Таблица 5. Перевод, выполненный версией Google Translate, основанной на статистистическом подходе

The author of the article, covering the example, attributed the distortion in translation to the inherent English rule of preserving the direct word order and ignorance of the grammar of the source language. Expanding on the latter, we would like to draw the attention to the lack of developed markup, primarily syntactic and anaphoric, in the SMT version of the online translator, which would let the computer correctly identify sentence members and match pronouns.
Figure 6. A translation of the sentence "Пишет вам письмо семья Дарьи" in the modern version of Google Translate
Рисунок 6. Пример перевода предложения «Пишет вам письмо семья Дарьи» в современной версии Google Translate
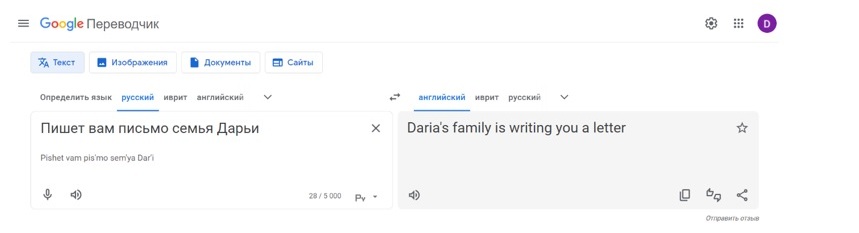
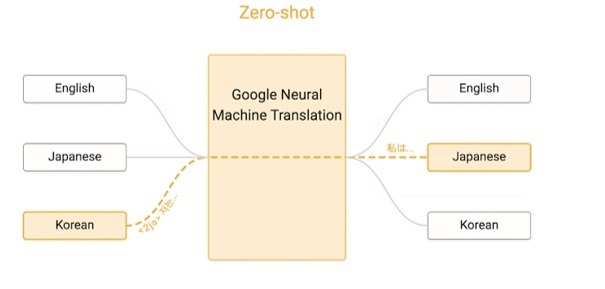
When Google switched to NMT (Neural Machine Translation), such errors were finally addressed (see Figure 6). The new model lifted the role of an intermediary language from English. Thus, the model that translates from English to Korean and from English to Italian can also communicate text from Italian to Korean without any substantial data in this language combination, i.e. perform zero-shot translation (see Figures 7, 8) (Schuster et al., 2016; Quach, 2016; Suxia Lei and You Li, 2023).
Figure 7. Translation process performed by Google through 2016
Рисунок 7. Процесс перевода, выполняемый программой Google до 2016 года
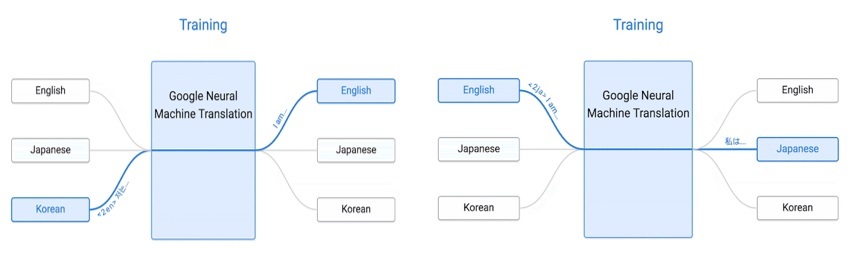
Figure 8. Translation process performed by Google after 2016
Рисунок 8. Процесс перевода, выполняемый программой Google, после 2016 года
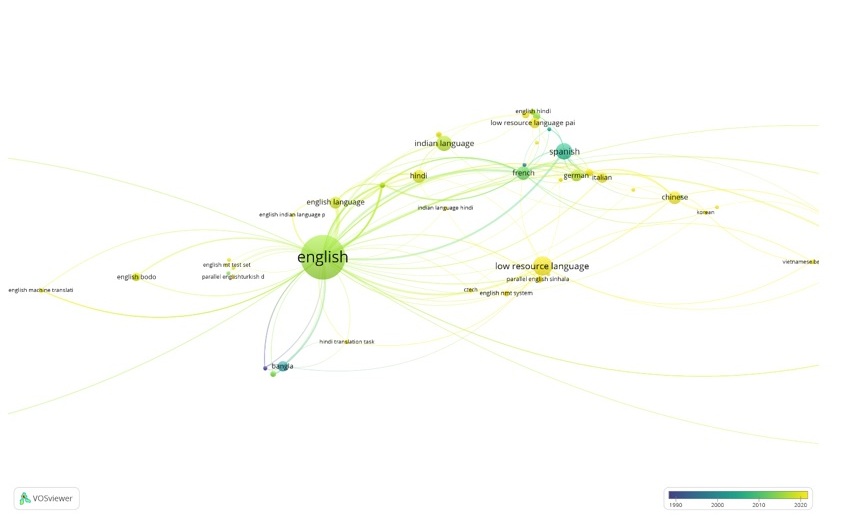
The share of MT studies for language pairs involving English is still predominant, but most of the efforts date back to 2015 (see Figure 9). Despite the introduction of the new model that can translate from scratch in any language pair, the focus has shifted to rare languages, most of them being low-resource languages. The languages lack annotated texts, speech data and other linguistic resources needed for MT development and training.[13] These are essential for adjusting language models generated by AI.
Figure 9. Language focus of MT researches[14]
Рисунок 9. Языковая ориентация исследований МП
The fact that AI was brought into the task of corpus processing and preparation has not completely exhausted the issue of automating semantic markup. The current solution is based on a multiple vector embedding approach, which already allows the hardware to "grasp" the meaning, though has a long way to go (Tripathi and Kansal, 2020). This explains the low efficiency of MT when working on fiction and poetry, where the aesthetic impact becomes paramount in text pragmatics. In order to achieve this, the most complex transformations are of the essence. However, these linguistic manipulations are contingent on understanding of the underlying meaning, exactly what we observe in Table 6[15], containing two translations of a fragment of Sonnet No. 130 by W. Shakespeare:
My mistress' eyes are nothing like the sun;
Coral is far more red than her lips' red;
If snow be white, why then her breasts are dun;
If hairs be wires, black wires grow on her head.
Table 6. Translations of Sonnet 130 by W. Shakespeare, by DeepL and S. Y. Marshak
Таблица 6. Переводы сонета 130 У. Шекспира, выполненные DeepL и С. Я. Маршаком

Simple generalization (1) and omission (4) were lost on Google Translate, let alone complex transformations – explication (2) and explication (3). Basic features of poetry – rhyme and meter – are missing in the MT output.
This said, the MT progress is more tangible in the field of technical translation. Thanks to the absolute priority given to conveying the meaning contained in research texts, MT technologies are used as a non-alternative means of translation into major foreign languages without post-editing by humans (see Figure 10).
Figure 10. MT-powered multilingual service on the Microsoft website
Рисунок 10. Мультиязычное сопровождение сайта корпорации «Майкрософт» на основе машинного перевода
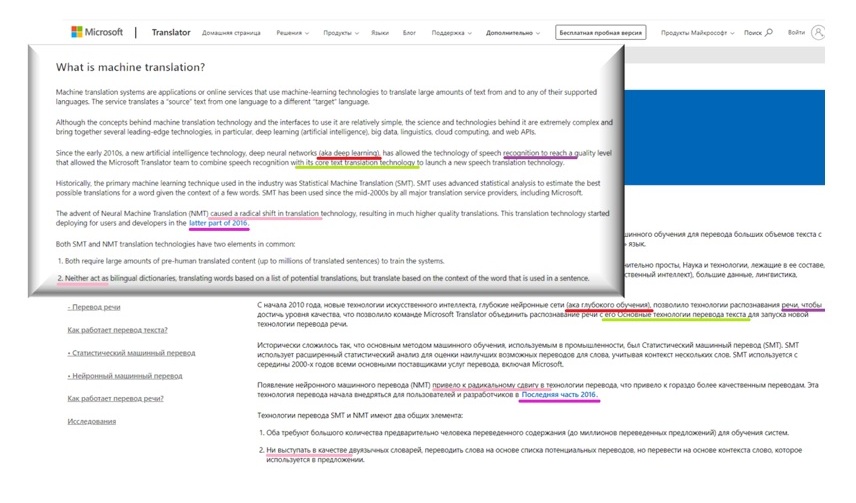
Major corporations are among those, who favor the approach. However, this is a desperate measure to catch up with the ever-growing information flow, no human can ever meet without getting into overheads. It is noteworthy that there is no distortion in the fragment, and translation inaccuracies do not interfere with the main message.
In contrast to the poor experience of the U.S. Air Force Foreign Equipment Department with MT, highlighted in the 1966 ALPAC report, modern systems bring the performance to a satisfactory-to-good level without post-editing. Nevertheless, MT has not eclipsed their human counterparts, and the same translation techniques as in the U.S. report (see Figure 2) are still relevant today, but at a higher technological development level: conventional translation, STT-powered dictation translation, CAT (Computer-Assisted Translation), and PEMT (post-editing machine translation).
The practice of dictating a translation and then converting it into a text has gained new perspectives with the advent of specialized software replacing yet another player in the process, a typist. Today, the translator is no longer dependent on this additional link in the translation chain.
Automation became a plausible alternative while modern MT systems were in their infancy. This path led to the development of CAT tools, a.k.a. Translation Memory (TM). As MT reached an acceptable quality level, the two systems merged creating a cumulative effect (Quintana and Castilho, 2022). For example, Trados, one of the CAT leaders, now could outsource translation of fragments missing in the TM. As a result, all texts, regardless of their entropy, could be translated at a certain level of automation, turning the software into a true virtual translator’s workbench. Tantamount to the recognition of MT by translators, it was yet another way of putting MT into practice.
Post-editing of MT is still on the agenda and forms another alternative to the use of new technologies in professional activities. However, under today’s conditions, this approach looks more cost-effective. Given the significant improvement in the quality of MT, editing time is measured in days rather than weeks. This path led to the establishment a separate practice, known as PEMT (Post-Editing of Machine Translation).
The need for additional manipulations of the MT output is dictated by additional pragmatic tasks. For example, non-periodical publications pursue not only to spread information, but preserve and popularize the printed heritage as well, while ad-materials should emphasize the advantages of the product in an unambiguous way.
The machine is not yet capable of accomplishing these tasks due to the immature automated semantic markup, preventing MT from performing critical transformations, a part and parcel of adequate translation (see Table 7) (Volkart and Bouillon, 2022).
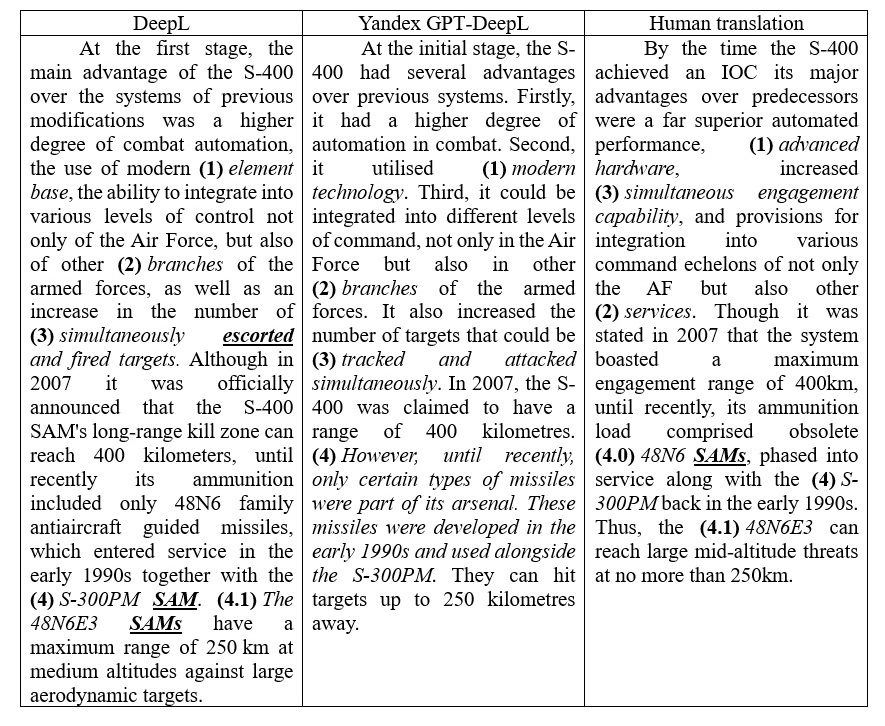
Table 7. Comparison of human and MT translations of the text S-400 Air Defense Missile System
Таблица 7. Сопоставление переводов фрагмента текста «Зенитная ракетная система С-400», выполненных человеком и системой МП
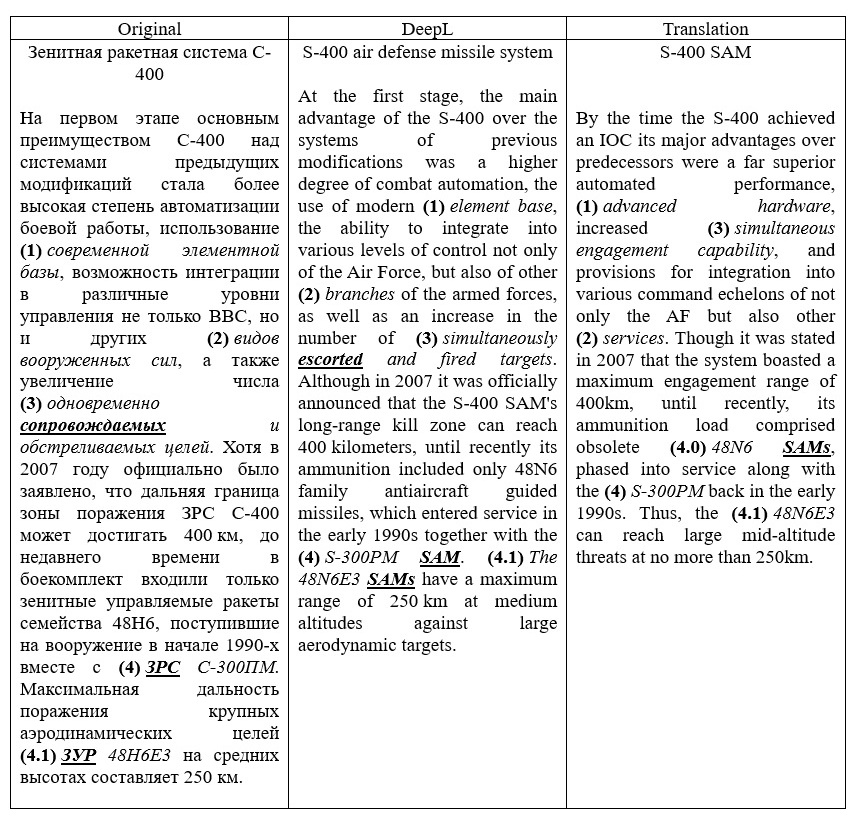
At the present stage, restricting MT to a bounded sublanguage is less relevant for improving the end quality, since the technology is now developed as a general-purpose system. Therefore, the issues of lexical polysemy and terminology have not been exhausted, which can be traced in fragments 1-3 in Table 7. For example, the term “сопровождать” in the MT version is translated to escort (provide protection, move alongside), whereas in military discourse it means to keep in sight (to track). However, the verb in question is part of a broader concept, for which there is an equivalent in English to have multiple engagement capability. Access to this lexical unit would improve the quality of the translation text Vs the original, however, the only way to implement the solution in the translation is by adopting an explication.
The given examples of inaccuracies will only make it difficult to grasp the information in a fast manner, while fragment 4 may well be misleading. According to DeepL’s translation both the S-300PM and the 48N6E3 are missiles (SAM stands for Surface-to-Air missiles), not a system and missile, respectively. Due to the MT limitations in performing semantic analysis, we assume that one efficient way to circumvent the problem is to go for text pre-editing. In the early days of MT, this was a common practice for reducing text to a simple, computer-legible form (Tomasello, 2020). Like post-editing, all preparatory manipulations with the text were performed manually, which led to the increase in time consumed by the task, rendering the only at the time MT advantages negligible at best. Given the growing popularity of chatbots in solving complex tasks without human’s intervention, we went for testing the AI capabilities in simplifying the source text for subsequent machine translation (see Figure 11).
Figure 11. Pre-editing of the source text by Yandex GPT
Рисунок 11. Упрощение исходного текста с помощью Yandex GPT

Compared to the original, the edited text became more compact, all complex sentences were reduced to a number of simple ones (see Table 8), and fragments 1 and 3 were rehashed, cutting chances of ambiguity. Fragment 4 underwent a major transformation, which resulted in the omission of precision information. Technically, this transformation refers to an omission, but it was uncalled for.
Table 8. Comparison of the original with its simplified version produced by Yandex GPT
Таблица 8. Сопоставление оригинала с его упрощенной версией после обработки в Yandex GPT
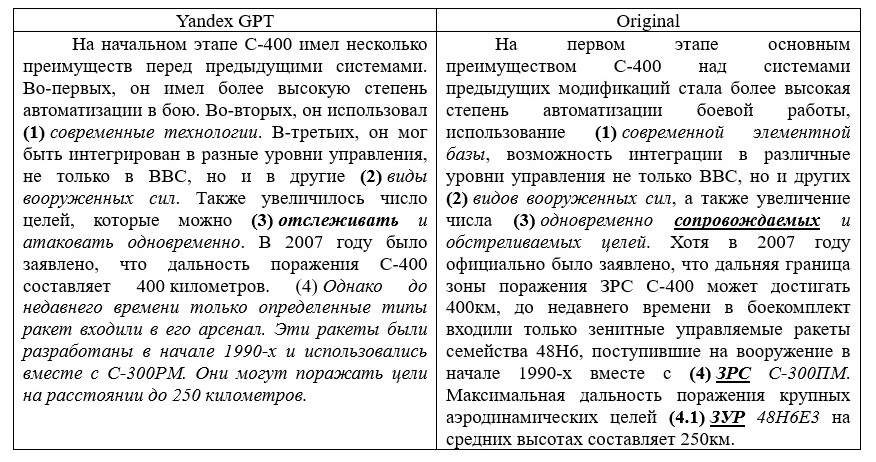
The translation of the edited text inherited only one inaccuracy in fragment 2, which survived AI-powered pre-editing (see Table 9). We attribute it to the fact that the lexical unit refers to a non-alternative term in this context. As expected, fragment 4 sustained the logic of the original at the expense of the precision information.
Table 9. Comparison of the human translation with MT of the original and its simplified version
Таблица 9. Сопоставление перевода, выполненного человеком, с машинными переводами оригинала и его упрощенной версией
The obtained results suggest that complex transformations should be carried out in the original text prior to its machine translation. In addition to eliminating complexities, pre-editing is recommended for correcting misprints and errors, as well as removing ambiguity, both being equally detrimental to the MT output.
Figure 12. Current trends in the MT development[16]
Рисунок 12. Современные тенденции в области развития МП
At the current stage of MT development, the main trends have undergone all but minor changes (see Figure 12). Corpora and their architecture are still relevant for training language models, which are gaining prominence in feasibility studies testing their suitability for fine-tuning MT for specific translation domains. Information processing for corpora expansion is no longer on the list, since it is now possible to convert speech to text in addition to optical recognition of graphical materials. Annotation and corpus markup systems have made a significant progress; however, both have a long way to go before they mature.
Conclusions
As a result of analyzing the most successful MT projects and their impact on modern realities, we have arrived at a number of significant conclusions. First, MT was successfully put to use far before computers became widespread. The effectiveness of the technology depends on the users' understanding of current limitations. Before 1990, there were a few of them, all of which were fully taken into account by the developers of METEO-1. Second, the MT evolvement traces a spiral trajectory. All of the MT applications noted in the 1966 ALPAC report are still relevant today. Third, modern MT has already been recognized by professional interpreters as a full-fledged tool, as evidenced by the PEMT emergence. Fourth, not all the issues in this area have been solved. One of the most urgent is semantic markup, designed to teach the computer to comprehend the text. This drawback does not allow, among other things, to improve the quality of translation of technical texts. We believe that a feasible solution is the implementation of such an advantage of specialized literature as low entropy. This approach calls for training language models, which is already possible at the current stage of MT development. Fifth, due to the improvement in the MT quality, giant enterprises have started to abandon post-editing, a major hindrance curbing the translation rate. However, aesthetic impact on the reader, high fidelity and contextualized translation are still beyond the MT grasp. Therefore, AI-powered pre- and post-editing practices should be utilized. Sixth, deep transformations and lower levels of equivalence are not attainable when applying MT to raw texts. Technologies should be led to desired translation solutions in pre-editing. As for future steps, it is advisable to delve into language models and their training, PEMT technologies as the most efficient way of translation in the conditions of rapid growth of information flow, as well as ways of adjusting equivalence and transformations when addressing translation problems in MT.
[1] Machine Translation Archive, available at https://aclanthology.org/www.mt-archive.info/srch/authors.htm (as of March 2017).
[2] Public Text Bulletins, retrieved from https://www.weather.gc.ca/forecast/public_bulletins_e.html
[3] FM 1-75 Army Air Forces Field Manual, Combat Orders. 1942-06-16.
[4] Entropy in thermodynamics and information theory, retrieved from https://en.wikipedia.org/wiki/Entropy_in_thermodynamics_and_information_theory
[5] GTF engine: Powering the Airbus A320neo, Airbus A220, and the Embraer E-Jets, retrieved from https://www.mtu.de/engines/commercial-aircraft-engines/narrowbody-and-regional-jets/gtf-engine-family/
[6] Pratt & Whitney PW1000G, retrieved from https://en.wikipedia.org/wiki/Pratt_%26_Whitney_PW1000G
[7] ALPAC (1966) Languages and machines: computers in translation and linguistics, 34.
[8] ALPAC (1966) Languages and machines: computers in translation and linguistics, 21.
[9] ALPAC (1966) Languages and machines: computers in translation and linguistics, 80.
[10] Machine Translation Archive, available at https://aclanthology.org/www.mt-archive.info/srch/authors.htm (as of March 2017).
[11] Anthony, L. (2020). AntConc (3.5.9) [Computer Software]. Tokyo, Japan: Waseda University, retrieved from https://www.laurenceanthony.net/software (Accessed 15 February 2022).
[12] Google Translate Translation methodology. Available from https://wiki.edunitas.com/IT/114-10/Google-Translator_2167_eduNitas.html
[13] POEditor Low-resource languages: A localization challenge, retrieved from https://poeditor.com/blog/low-resource-languages/
[14] Based on a Lens selection of 1094 MT papers covering a period of 1990-2015, registering the most intensive MT development spike (key words: MT, machine translation, annotation, tagging, NLP, natural language processing, parsing, corpora, corpus, parallel corpus, comparable corpus, rule-based, neural MT, NMT).
[15] Shakespeare, W. Sonnet 130, rendered into Russian by S. Marshak, retrieved from https://engshop.ru/shekspir-sonet-130-na_anglieskom/
[16] Based on a Lens selection of 1560 MT papers covering a period of 1990-2020 (key words: MT, machine translation, annotation, tagging, NLP, natural language processing, parsing, corpora, corpus, parallel corpus, comparable corpus, rule-based, neural MT, NMT).












Reference lists
Bharati, A., Chaitanya, V., Kulkarni, A. and Sangal, R. (2003). Anusaaraka: Machine Translation in Stages, ArXiv, cs.CL/0306130. (In English)
Brown, P. F., Della Pietra, S. A., Della Pietra, V. J. and Mercer, R. L. (1993). The Mathematics of Statistical Machine Translation: Parameter Estimation, Computational Linguistics, 19 (2), 263–311. (In English)
Costa-jussa, M., Escolano, C. and Fonollosa, J. (2017). Byte-based Neural Machine Translation, Proceedings of the First Workshop on Subword and Character Level Models in NLP, 154-158. DOI: 10.18653/v1/W17-4123 (In English)
Daems, J., Vandepitte, S., Hartsuiker, R. and Macken, L. (2017). Translation Methods and Experience: A Comparative Analysis of Human Translation and Post-editing with Students and Professional Translators, META, 62 (2), 245–270. https://doi.org/10.7202/1041023ar (In English)
Fumani, F. Q. and Reza, M. (2007). Ambiguity in Machine Translation, Ketabdari Va Etella'resaani, 9, 21-38. (In English)
Gashaw, I. and Shashirekha, H. L. (2019). Amharic-Arabic Neural Machine Translation, Computer Science & Information Technology (CS & IT), 55-68. https://doi.org/10.5121/csit.2019.91606(In English)
Gruzdev, D. Yu. and Kodzhebash, D. O. (2023). POS-powered queries for neat and lean concordances in ad-hoc corpora analysis, Teoreticheskaya i prikladnaya lingvistika [Theoretical and Applied Linguistics], 9 (4), 35‒48. https://doi.org/10.22250/24107190_2023_9_4_35(In English)
Hurskainen, A. (2018). Can machine translation assist in Bible translation?, SALAMA – Swahili Language Manager: Technical reports on LT, 62, Helsinki. (In English)
Hutchins, J. (2004a). Two precursors of machine translation: Artsrouni and Trojanskij, International Journal of Translation, 16 (1), 11-31. (In English)
Hutchins, J. (2004b). The first public demonstration of machine translation: the Georgetown-IBM system, 7th January 1954. (In English)
Volkart, L. and Bouillon, P. (2022). Studying Post-Editese in a Professional Context: A Pilot Study, Proceedings of the 23rd Annual Conference of the European Association for Machine Translation, Ghent, Belgium. European Association for Machine Translation, 71–79 (In English)
López, V. F., Corchado, J. M., De Paz, J. F., Rodríguez, S. and Bajo, J. (2010). A SomAgent statistical machine translation, Applied Soft Computing, 11 (2). https://doi.org/10.1016/j.asoc.2010.08.018(In English)
Nelyubin, L. L. (1975). Informacionno-statisticheskie i inzhenerno-lingvisticheskie osobennosti yazyka i teksta v usloviyah speckommunikacii [Information-statistical and engineering-linguistic features of language and text in conditions of special communication], D. Sc. Thesis, Applied linguistics, Leningrad. (In Russian)
Nelyubin, L. L. (1983). Translation and applied linguistics, Vysshaya Shkola Publishers, Moscow, USSR. (In Russian)
Névéol A., Dogan R. and lu Zh. (2010). Semi-automatic semantic annotation of PubMed queries: A study on quality, efficiency, satisfaction, Journal of biomedical informatics, 44. 310-8. DOI: 10.1016/j.jbi.2010.11.001. (In English)
Nirenburg, S. (ed.) (1993). Progress in machine translation, IOS Press, Amsterdam, Netherlands. (In English)
O'Brien, S. Balling, L. W., Carl, M., Simard, M. and Specia, L. (eds.) (2014). Post-editing of Machine Translation: Processes and Applications, Cambridge Scholars Publishing. (In English)
Oladosu, J., Esan, A., Adeyanju, I., Adegoke, B., Olaniyan, O. and Omodunbi, B. (2016). Approaches to Machine Translation: A Review, FUOYE Journal of Engineering and Technology, 1 (1), 120–126. https://doi.org/10.46792/fuoyejet.v1i1.26(In English)
Ornstein, J. (1955). Mechanical Translation: New Challenge to Communication, Science, 22 (3173), 745-748. DOI: 10.1126/science.122.3173.745 (In English)
Quach, K. (2016). Google's neural network learns to translate languages it hasn't been trained on: First time machine translation has used true transfer learning, The Register, available at: https://www.theregister.com/2016/11/17/googles_neural_net_translates_languages_not_trained_on/ (Accessed 10 June 2024). (In English)
Quintana, R. C. and Castilho, S. (2022). A review of the Integration of Machine Translation in CAT tools, Proceedings of the International Conference “New Trends in Translation and Technology NeTT 2022”, Rhodes Island, Greece, 214–221 (In English)
Tripathi, S. and Kansal, V. (2020). Machine Translation Evaluation: Unveiling the Role of Dense Sentence Vector Embedding for Morphologically Rich Language, International Journal of Pattern Recognition and Artificial Intelligence, 34 (1), 2059001. https://doi.org/10.1142/S0218001420590016(In English)
Schuster, M., Johnson, M. and Thorat, N. (2016). Zero-Shot Translation with Google’s Multilingual Neural Machine Translation System, AI Blog, available at: https://ai.googleblog.com/2016/11/zero-shot-translation-with-googles.html (Accessed 10 June 2024). (In English)
Schuster M. Zero-Shot Translation with Google’s Multilingual Neural Machine
Suxia Lei and You Li. (2023). English Machine translation System Based on Neural Network Algorithm, Procedia Computer Science, 228, 409-420. https://doi.org/10.1016/j.procs.2023.11.047(In English)
Tomasello, L. (2020). Neural Machine Translation and Artificial Intelligence: What Is Left for the Human Translator?, Master’s degree theses, University of Padua, Italy. (In English)
Weaver, W. (1949). The Mathematics of Communication, Scientific American, 181 (1), 11-15. (In English)