
Semantic core identification as a method to overcome textoidness
We believe that neural machine translation results intended to function as a text always have enough potential for a semantic core (i.e. a communicative center with text-forming properties) to be found and verbalized.
The relevanceof this article is provided by two factors. On the one hand, machine translation software is widespread, easily available, and in active use; on the other hand, machine translation results have to be post-edited to the quality of a communicative text due to systematic disruption of its intra-textual connections in the machine translation results which turns out to be, in its raw, non-edited version, a set of separate sentences, in other words – a ‘textoid’ that should be fixed by an editor to function as a coherent text. Although frequent cross-checking between the original text and its translation helps eliminate occasional semantic errors and inaccuracies, the AI output in general still looks like a poor-quality text with a ‘machine DNA.’ This brings us to the core problem: now, there is no reliable method to assess and achieve global semantic coherence in AI-generated translations.
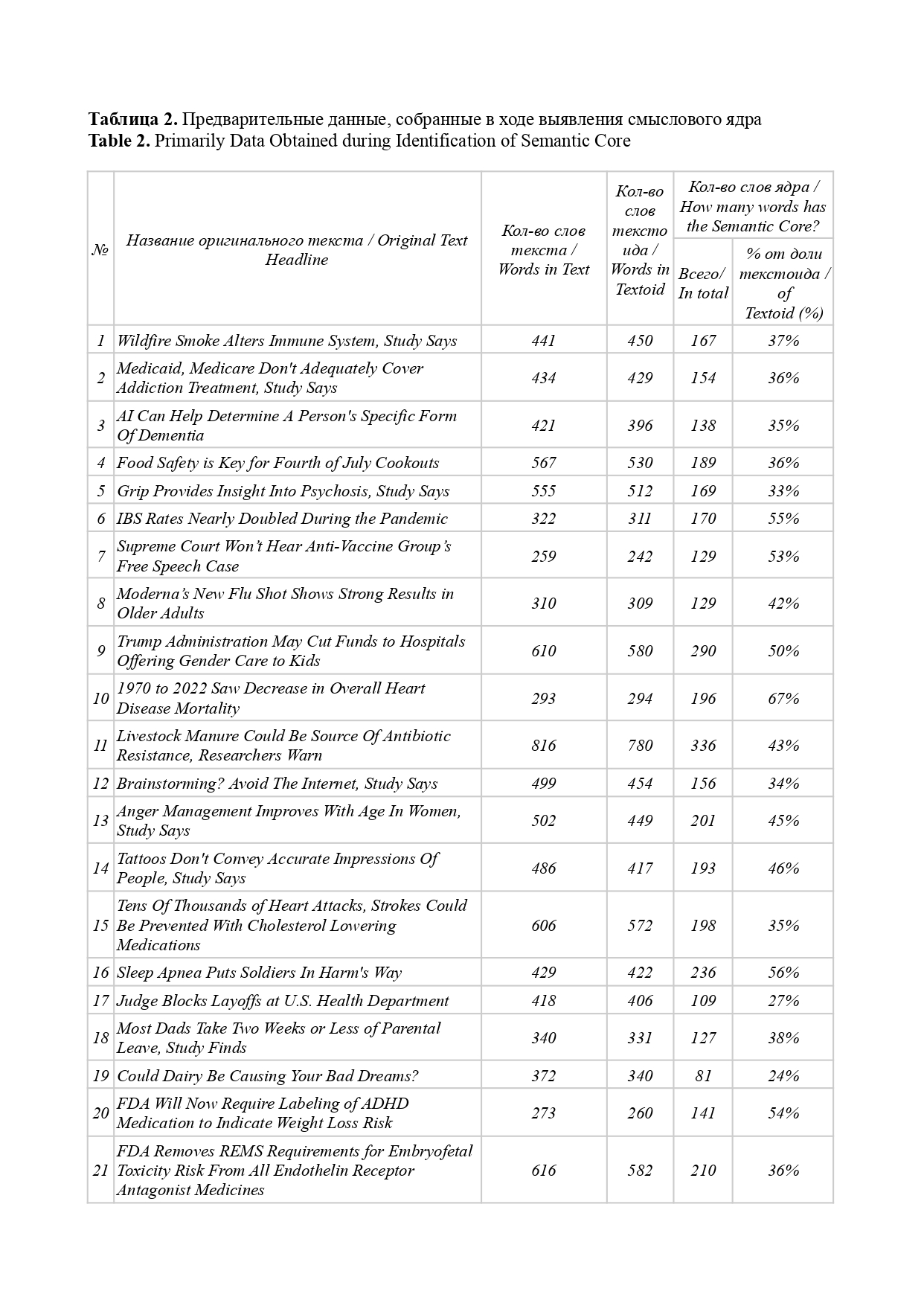
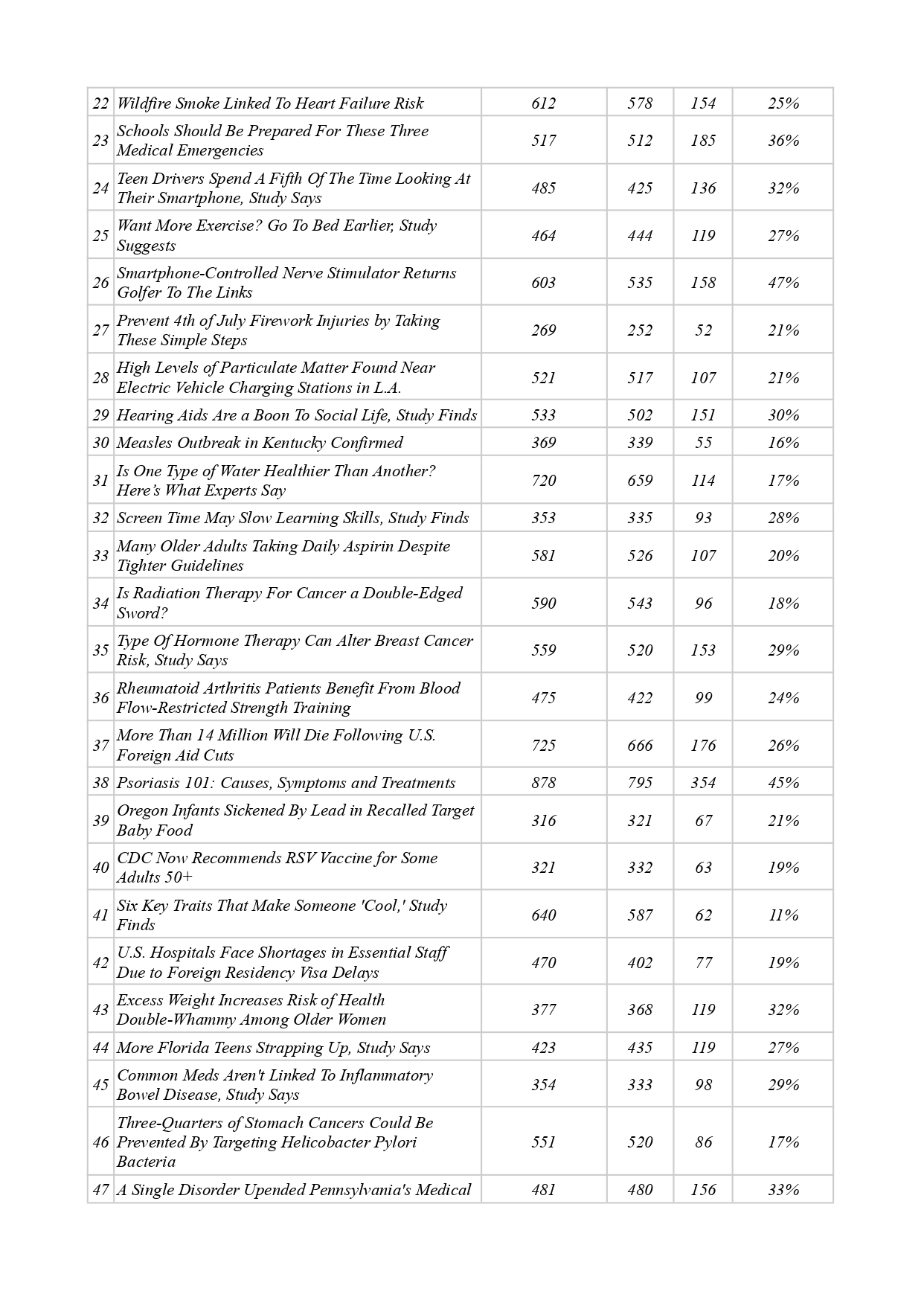
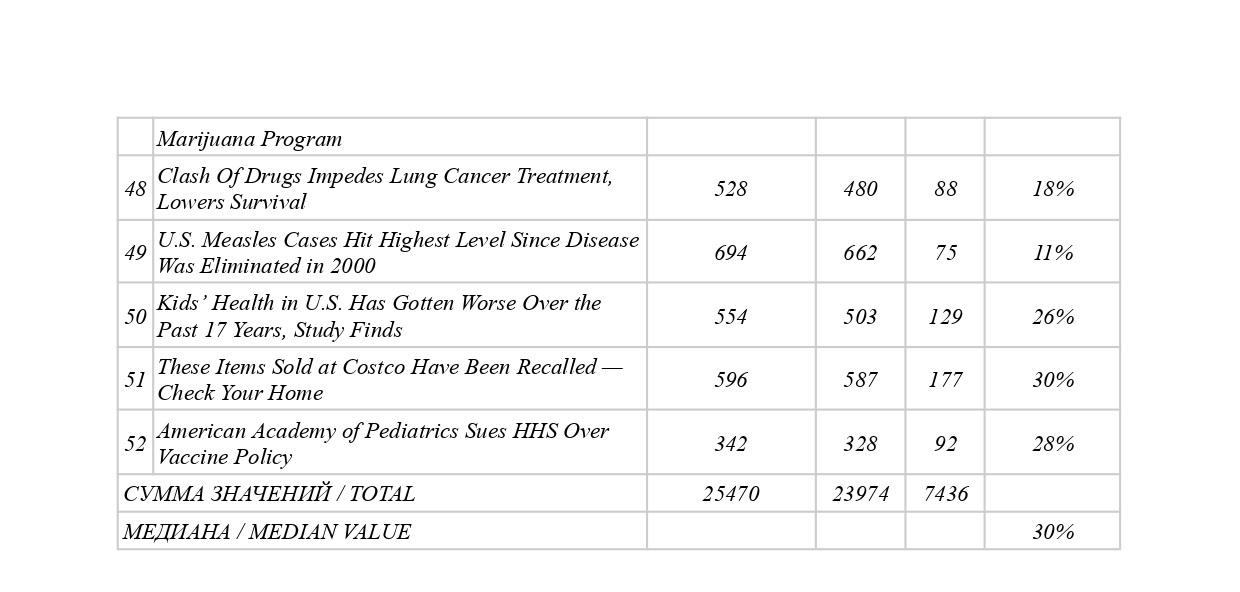
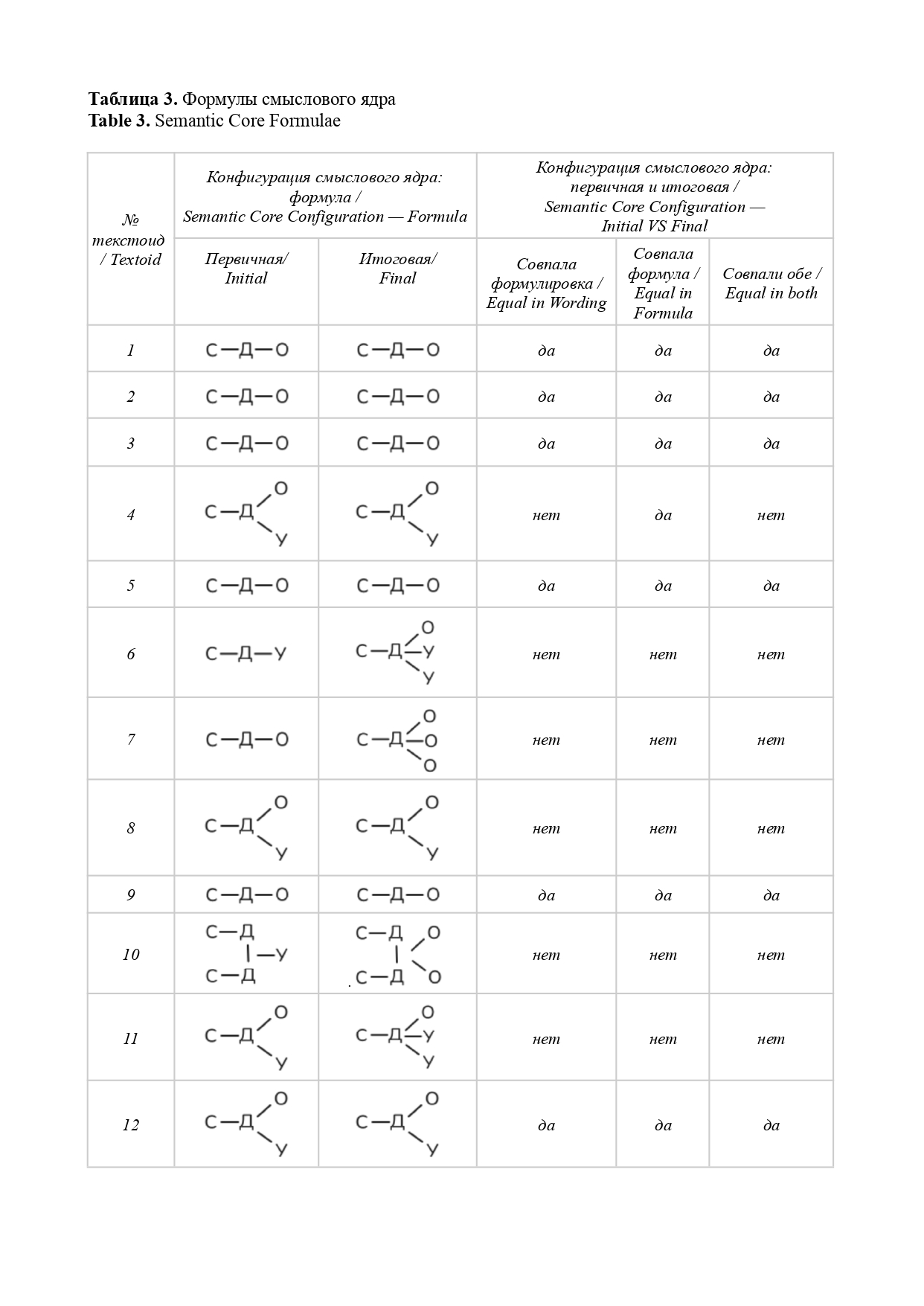
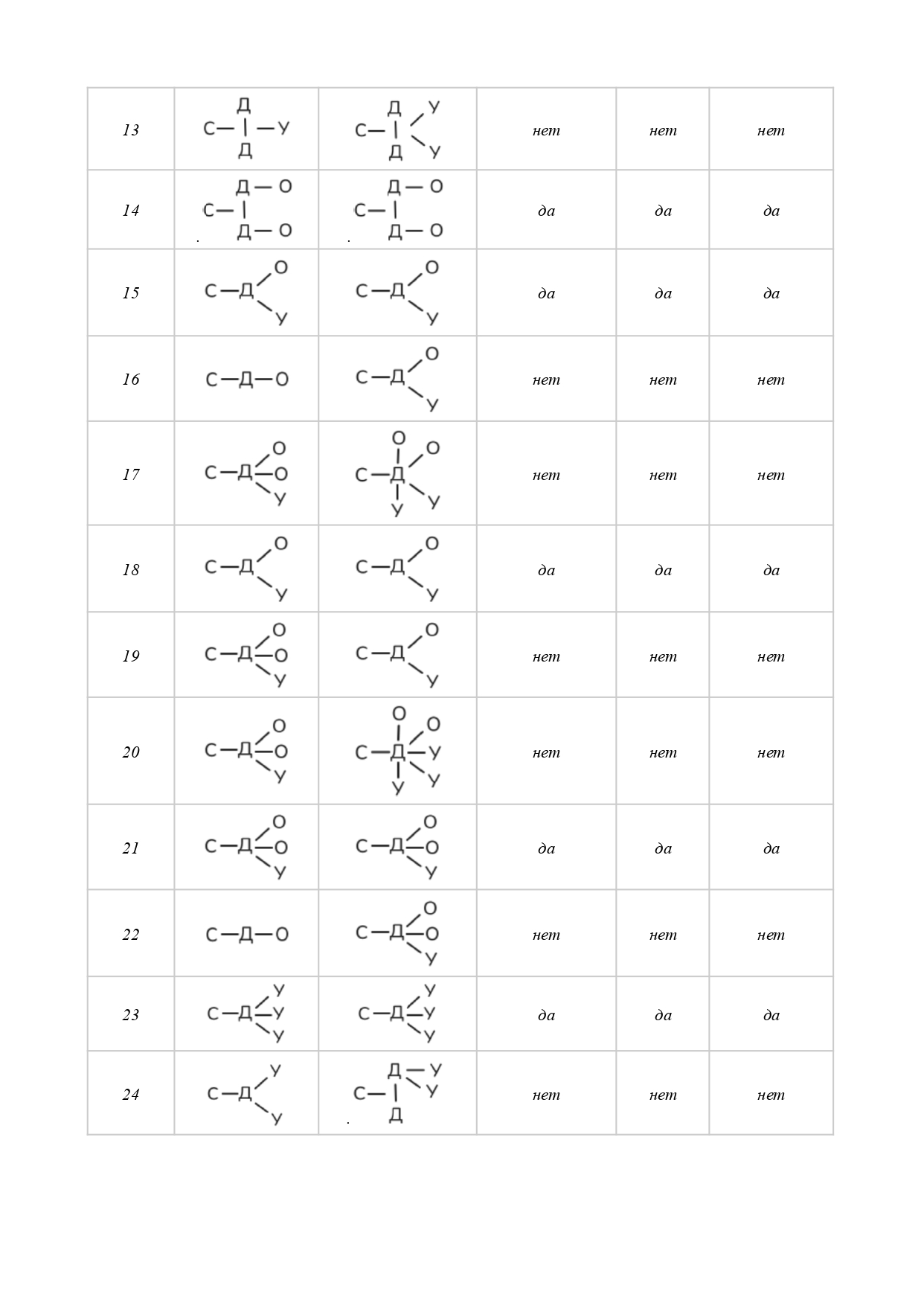
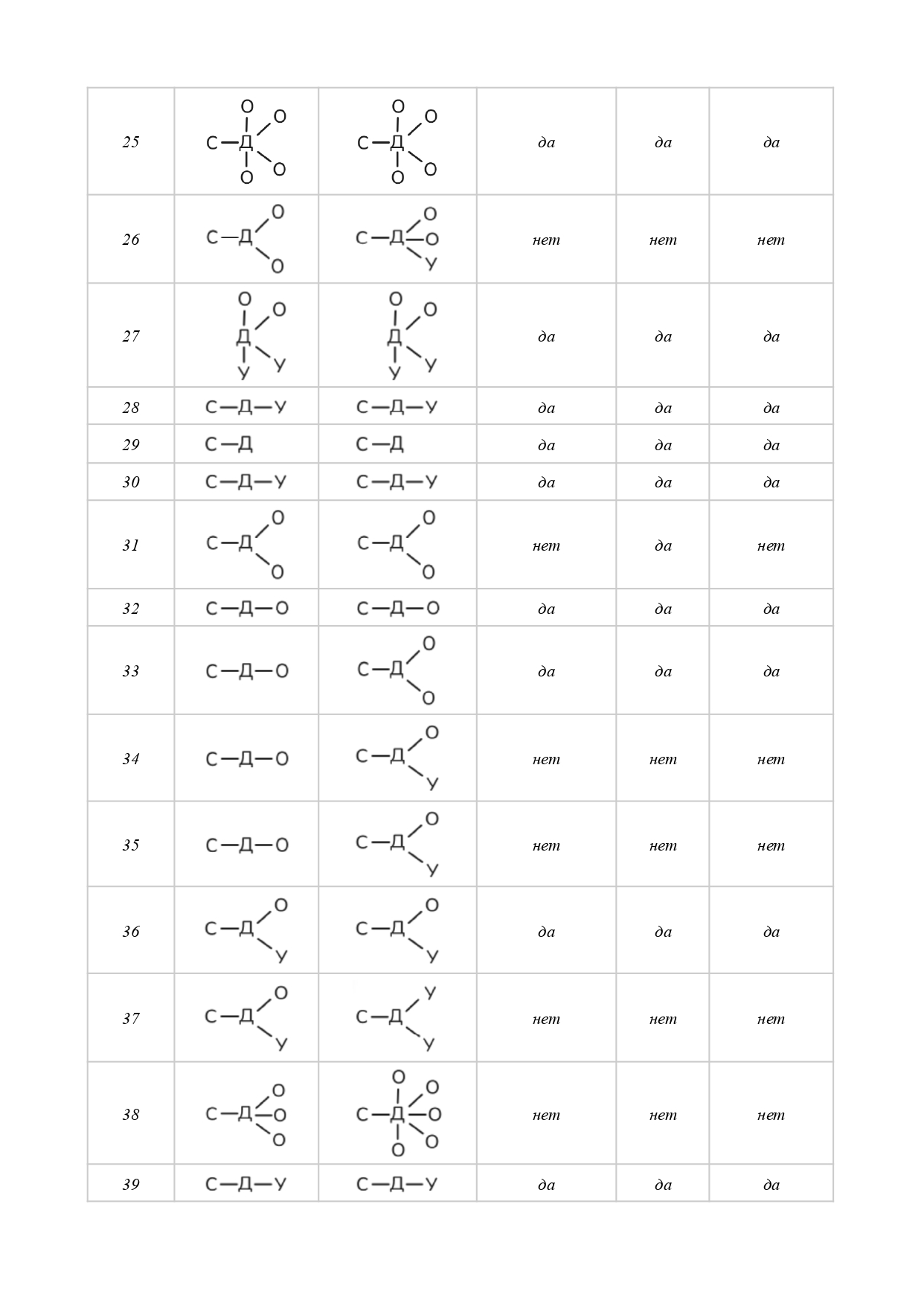
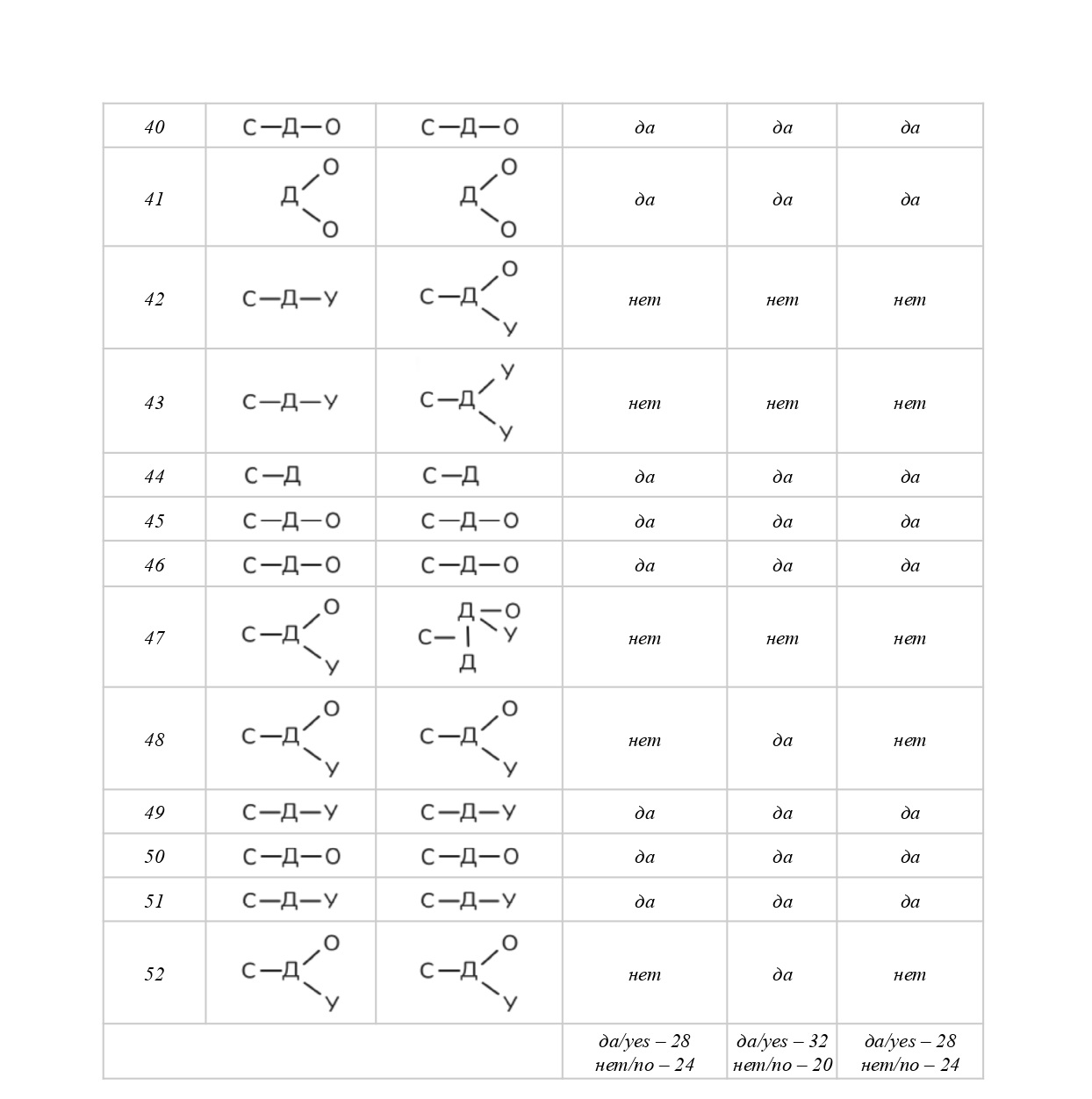
That is why our study aims to lay the foundations of a linguistic method for overcoming textoid-quality of machine translation results by means of semantic core identification. Through a comprehensive approach that comprises such methods as abstraction, analysis, classification, synthesis, modeling, and measurement this study has achieved the following results: (a) a unique tool for semantic core identification was proposed relying on such well-known linguistic concepts as subject, predicate, and object, as well as on a basic subject-logical typology of semantic relations; (b) a need to adjust the initial core wording/formula was demonstrated in 46 % of cases; (c) the median core volume (31 %) in a textoid was determined for medical news; (d) basic principles of linguistic annotation (how to label specific linguistic, structural, or semantic features) were proposed as well as a system of notations; (e) a principle for representing the semantic core by means of graphic formulae was proposed for illustrative purposes; (f) ways for further scientific research were outlined.
Conclusion: 52 textoids were analyzed to demonstrate applicability of our method, intended to serve as a reliable linguistic tool for identifying a semantic core which, in its turn, can function as (1) a text-forming essence that can be used in converting a textoid into a text; (2) a subject-logical benchmark for controlling and verifying translation, both for specific segments of the machine translation and for the text as a whole; and (3) a tool for interpreting unclear or contradictory passages within the textoid (without direct need to check up with the source text).
Figures


Kovalchuk, A. V. (2026). Semantic core identification as a method to overcome textoidness, Research Result. Theoretical and Applied Linguistics, 12 (2), 61–83.












While nobody left any comments to this publication.
You can be first.
Belyayeva, L. N. (2022). Machine translation in modern technology of the translation process, Izvestiya Rossiyskogo gosudarstvennogo pedagogicheskogo universiteta im. A. I. Gertsena, 203, 22, available at: https://doi.org/10.33910/1992-6464-2022-203-22-30 (Accessed 02 September 2025).
Boronin, A. A. (2016). On the issue of textoids, Vestnik Moskovskogo gosudarstvennogo oblastnogo universiteta. Seriya: Lingvistika, 2, 27, available at: https://doi.org/10.18384/2310-712X-2016-2-26-32 (Accessed 02 September 2025).
Vishnyakova, A. I. (2017). The Idea of Freedom as the Semantic Center of Dostoevsky's Novel "Notes from the House of the Dead", Science and Education, 11–15.
Galperin, I. R. (2006). Tekst kak object lingvisticheskogo issledovaniya [Text as an object of a linguistic study], KomKniga, Moscow, Russia.
Goldenveyzer, A. B. (1922). Vblizi Tolstogo [Near Tolstoy], Cooperative Publishing House, Moscow, Russia. (In Russian)
Gorina, Ye. V. (2021). Smyslovaya struktura zhurnalistskogo teksta: uchebno-metodicheskoe posobie [The Semantic Structure of Journalistic Text: A Textbook], Uralskiy federal'nyy universitet imeni pervogo Prezidenta Rossii B. N. Yeltsina, Yekaterinburg, Russia. (In Russian)
Greimas, A. (1985). V poiskakh transformatsionnykh modelei. Zarubezhnye issledovaniya po semiotike folklora [In Search of Transformational Models: International Research on the Semiotics of Folklore], Nauka, Moscow, Russia. (In Russian)
Grigoryan, V. A. (2024). Textual Conceptualization and Interpretation in Modern Linguistics, Seventeenth Annual Scientific Conference. Social Sciences and Humanities, l, 513.
Dzyaloshinskiy, I. M. (2019). Texts and textoids, or what happens to the author? PR i SMI v Kazakhstane: sbornik nauchnykh trudov [PR and Mass Media in Kazakhstan: A Collection of Scientific Papers], Almaty, Kazakhstan, 17, available at: https://publications.hse.ru/pubs/share/direct/306031376.pdf (Accessed 10 September 2025).
Kobzeva, O. V. (2018). Violation of Linguistic Norms in Translation in В1-С1 Students, Vestnik Kemerovskogo gosudarstvennogo universiteta, 4, available at: https://doi.org/10.21603/2078-8975-2018-4-211-222 (Accessed 03 October 2025).
Kovaleva, L. M. (1987). Problema strukturno-semanticheskogo analiza prostoi glagolnoi konstruktsii v sovremennom anglijskom yazyke [The Problem of Structural and Syntactic Analysis of the Simple Verb Constructions in Temporary English], Izd-vo Irkutstkogo un-ta, Irkutsk, Russia. (In Russian)
Malyavina, A. N. (2024). Teaching Post-editing to Translaton Students, Aktualnyye problemy lingvistiki i metodiki prepodavaniya inostrannykh yazykov, 35.
Moskalskaya, O. I. (1981). Grammatika teksta (posobie po grammatike nemetskogo yazyka dlya institutov i fakultetov inostrannykh yazykov) [Text Grammar (German Grammar Manual for Institutes and Faculties of Foreign Languages)], Vyssh. shkola, Moscow, Russia, available at: https://www.phantastike.com/linguistics/grammatika_teksta/djvu/view/ (Accessed 15 September 2025) (In Russian)
Naumchik, O. S. (2020). The Image of a Mirror as the Semantic Center of Neil Gaiman's Short Story Collection "Smoke and Mirrors", Vestnik Baltiyskogo federalnogo universiteta im. I. Kanta. Seriya: Filologiya, pedagogika, psikhologiya, 1, 80–87.
Panasenkov, N. A. (2019). Experience of teaching linguistics students - how to post-edit machine-generated translation (based on English-to-Russian translations via Google Translate, Yandex Translate and Promt systems), Pedagogicheskoye obrazovaniye v Rossii, 1, available at: https://doi.org/10.26170/po19-01-08 (Accessed 07 September 2025).
Perekhodko, I. V. (2017). Assessing the quality of computer translation, Vestnik Orenburgskogo gosudarstvennogo universiteta, 2 (202), 93.
Psurtsev, D. V. (2001). The Meaning-Forming Aspect of Figurative-Associative Components of a Fiction Text (Based on English-Language Fiction), Ph.D. dissertation, Moscow State Linguistic University, Moscow, Russia.
Sdobnikov, V. V. (2025). AI in Translation: How to Use it Effectively, Nauchnyi dialog, 14(3), available at: https://doi.org/10.24224/2227-1295-2025-14-3-62-80 (Accessed 01 September 2025).
Sdobnikov, V. V. (2024). Artificial Intelligence in Translation: Clarification of Concepts, Voyenno-filologicheskiy zhurnal, 4, 42.
Sirotinina, O. B. (1994). Texts, textoids, discourses in the zone of colloquial speech, Chelovek. Tekst. Kultura. Yekaterinburg, 109.
Skrashchuk, Ye. I. (2019). The Semantic Dominant of V. A. Soloukhin's Short Story "Back Alley", Dni nauki studentov Vladimirskogo gosudarstvennogo universiteta imeni Aleksandra Grigoryevicha i Nikolaya Grigoryevicha Stoletovykh: Sbornik materialov nauchno-prakticheskikh konferentsiy [Days of Science for Students of Vladimir State University named after A. G. and N. G. Stoletov: Collection of Materials from Scientific and Practical Conferences], Vladimir, Russia 2311–2319.
Fonova, Ye. G., Shitts, O. A. (2025). On the Issue of Professional Competencies of Translators in the Age of Artificial Intelligence, Vestnik Tomskogo gosudarstvennogo pedagogicheskogo universiteta, 1(237), available at: https://doi.org/10.23951/1609-624X-2025-1-148-156 (Accessed 01 September 2025).
Chakyrova, Yu. I. (2013). Is post-editing a blessing or a curse? Industriya perevoda, 1, 137.
Tarasti, E. (2017). The Semiotics of A. J. Greimas: A European Intellectual Heritage Seen from the Inside and the Outside. Sign Systems Studies, 45(½), available at: https://doi.org/10.12697/SSS.2017.45.1-2.03 (Accessed 19 May 2026). (In English)
Corpus Material
Linguistic Encyclopedic Dictionary (1990), available at: https://tapemark.narod.ru/les/392d.html (Accessed 03 September 2025).