
English-Indonesian crisis translation: accuracy and adequacy of Covid-19 terms translated by three MT tools
Abstract
This study focuses on one basic question: how accurate and adequate are the three MT tools, namely Google Translate, Bing and Systran, in generating Covid-19 terms? It measures mainly the accuracy and adequacy of Covid-19 terms translated by three popular MT tools between English and Indonesian. Data analysis is conducted manually through human evaluation toward translation products by using a translation rubric. The assessment includes several samples covering the level of words, sentences and paragraphs. All samples are purposively retrieved from the Coronavirus Corpus and are translated by using the three MT tools. Two raters are involved to analyze texts at sentence and paragraph levels. The raters are used to provide the credibility of translation texts analysis. Results showed that the three MT tools produce different language accuracy and adequacy in revealing COVID-19 terms. Translating noun and pronoun in particular context from English into Indonesian language still remains unclear. This may affect paragraph cohesion. Furthermore, even though these MT tools successfully translate a number of English words into Indonesian, several of the words cited are officially absent in the Great Indonesian Dictionary. This gap raises confusion for Indonesian readers whose English is not sufficient to understand the lexical meaning. In this case, the study highlights the importance of updating the words data base. As this article implements an evaluation translation method, the goal is to produce some recommendations that may be useful for several parties: reader of target language, MT’s developer, linguist and government.
Introduction
The role of translation in a crisis has gained attention among TS scholars (Federici et al., 2019; O’Brien and Federici, 2019). Previous studies had concerned MT in assisting health communication Dew et al., 2018). Dreisbach and Dreisbach (2021) illustrated the doctor-patient communication; they recognize that communication failures are due to linguistic barriers for the patients are unable to convey their symptoms in a foreign or second language. Li et al. (2020) underscored a need to go beyond English-mediated knowledge production to contend with prompt Covid-19 publicity in non-English-speaking countries and areas. Therefore, it is urgent and necessary to control the spread of covid-19 cases in international and multilingual communities by employing MT tools.
In order to meet the needs of the international community to combat COVID-19, linguists, translators and translation companies continue to develop the corpus of the corona crisis at the monolingual, bilingual and multilingual levels. For example, together with Systran, Taus has contributed to producing Corona Crisis translation models in twelve languages including English, French, Spanish, German, Italian, Chinese, and Russian (TAUS and Systran).[1] The EMEA corpus (comprising extensive documents from the European Medicines Agency) focuses on more comprehensive health (EMEA).[2] The sketch engine corpus consists of texts published as part of the covid-19 open research dataset (Sketch Engine).[3] Coronavirus Corpus from English-Corpora. The coronavirus corpus is developed based on records of the coronavirus’s social, cultural, and economic impact in 2020 and beyond (English-Corpora).[4] The public can access machine translation tools to consult information. However, such corpus is relatively less known to the public. The Corpus from Systran, can be used in the same way as Google Translate or Bing. Systran, Google Translate, and Bing from Microsoft are parallel corpora offering multilingual translations. Therefore, they can be used widely across the globe in a variety of languages. Their interface is familiar to users and easy to handle (Bowker, Ciro, 2019).
Despite the development of MT, specifically during the pandemic, there are some thorny problems in the use of MT tools (Koehn and Knowles, 2017). Several studies found that MT still failed to distinguish from synonyms, collocations, or word meanings. MT error occur frequently, such as word missing, wrong word order, incorrect punctuation, and unknown words (Chon, Shin, and Kim 2021; Stankevičiūtė, Kasperė, and Horbačauskienė, 2017). Furthermore, MT is also considered as ignoring the complexity of language, and calls for cross-disciplinary research (Vieira, O’Hagan, and O’Sullivan, 2020). The use of MT tools has also been alerted in terms of accuracy in translating safety guidelines, which may pose a potential threat to child health (Das et al., 2018). Therefore, it is significant to evaluate the product of MT tools (Asscher, Glikson, 2021; Guzmán et al., 2017).
Main part
Purpose of the Paper
This study attempts to evaluate the accuracy and adequacy of English-Indonesian translations of COVID-19 terms by using MT tools, namely, Systran, Google Translate and Bing. The evaluation can be carried out in two folds: manual evaluation and automatic evaluation (Koehn, 2010: 217; Maurya et al., 2020). Manual evaluation is evaluating the translation product which is carried out by human without machine or application support whereas automatic evaluation assesses the translation product by using a machine or an application. This present study is crucial because the result can give a shade of light on practical and theoretical probing in MT studies.
The research questions include:
- How is the meaning of Covid-19 related terms in the target language at the word level generated by the three machine translation tools?
- How is the meaning of Covid-19 related terms in the target language at the sentence level generated by the three machine translation tools?
- How is the meaning of Covid-19 related terms in the target language at the paragraph level generated by the three machine translation tools?
Materials and Methods
This paper used the evaluation translation method (Williams and Chesterman, 2011) to answer one main research question. This study aims at comparing three Machine translations through human evaluation (Koehn, 2010). At the word level, the output of source language generated by that Machine Translation is assessed manually based on correctness standards to answer the research questions. The establishment of criteria for the translation rubric is furthermore carried out to evaluate translation products (Samir, 2020). The word level is described by Non-Native Indonesia (2) if the word is not available in KBBI (The Great Indonesian Dictionary) but it can still be understood under two reasons; the issue of loanword and calque. The word is categorized Good Indonesia (3) if the word is available in KBBI database and the words are still attributed to loanword and calque. The word is categorized as flawless (4) if it is available in KBBI and dismisses the two issues. If the word scores 1, it is then categorized as Not Recognized or disfluent. The following rubric is depicted to figure out the scoring system.
Table 1. Scoring Rubric Quality of the word-level
Score | Word availability | Quality |
1 | Not recognized | Disfluent Indonesian |
2 | Not available in KBBI | Non-native Indonesian (loan, calques) |
3 | Available in KBBI | Good Indonesian (loan, calque) |
4 | Available in KBBI | Flawless |
Fluency and accuracy are further measured. The translations at the sentence and paragraph levels are scored based on the criteria shown in Table 2. This evaluation involved two raters to avoid sensitization on internal threats (Saldanha and O’Brien, 2014: 31). The raters were effective in both the source language and the target language. They were coded as Rater 1 (R1) and Rater 2 (R2). Both R1 and R2 used the following rubric proposed by Koehn (2010).
Table 2. The scoring rubric of adequacy and fluency (Phillip Koehn, 2010)
Score | Adequacy | Score | Fluency |
1 | None | 1 | Incomprehensible |
2 | Little meaning | 2 | Disfluent Indonesian |
3 | Much meaning | 3 | Non-native Indonesian |
4 | Most meaning | 4 | Good Indonesian |
Sample and Data Collection
The data were taken purposively from Google Trend for 12 past months dealing with the word query of Covid-19 in Indonesia. Google Trend provides statistics to show a particular trend with a word query on Google. The authors used the keyword "covid-19", then the Google Trend displayed the words query that most people used in the last 12 months. It was done on 9 July 2021. Three sentences and one paragraph taken from texts on Covid-19 were used as samples. In addition, the samples to evaluate the sentence and paragraph levels were taken from English-Corpora, specifically The Coronavirus Corpus. The samples were taken in different ways and depended on the context the authors chose. The authors selected samples based on words that appeared in previous samples at the word level. Three words from 20 words in Google Trend were used as a lemma and then there were searches for the lemma to get the context of the lemma in The Coronavirus Corpus.
Data Analysis
Data were analyzed by comparing the source text and target text in the info metric. The data were then described based on the accuracy and fluency in the target language and the availability of word equivalency. The score was recorded into the rubric. After the scores were recorded, the data was presented in percentage. Based on the scores, the accuracy and the fluency of the target language were then illustrated concisely.
Furthermore, to provide the credibility of the finding, specifically in examining the sentence and paragraph levels, two raters were asked to evaluate the text. If the scores were different, the raters were to share their analysis and discuss it. If the two raters still disagreed and did not reach a consensus, the authors decided to take the lowest score.
Finding and Discussion
Based on the search from Google Trend, the result shows a considerable number of words related to Covid-19. The authors limited the number of words to 10 top words with the keywords “Covid-19” and “coronavirus diseases” cut of data as of 7/9/20-7/9/21 located in Indonesia. Therefore, there are 20 words retrieved from Google Trends as data sampling. However, the authors also used words and phrases based on the Google Trend retrieval, as shown in
Table 3.
Table 3. Comparison of words translation
Keywords | English Words/phrase | Machine Translation | ||
|---|---|---|---|---|
Google Translate | Bing | Systran | ||
Covid-19 | Covid-19 | Covid-19 | Covid-19 | Covid-19 |
| Vaccine | Vaksin | Vaksin | Vaksin |
| Symptom | Gejala | Gejala | Gejala |
| pandemic | Pandemi | Pandemi | Pandemi |
| Patient | Pasien | sabar | Pasien |
| Virus | Virus | Virus | Virus |
| Vaccination | Vaksinasi | Vaksinasi | Vaksinasi |
| Taskforce | Gugus Tugas | Gugus Tugas | Satuan Tugas |
| Isolation | Isolasi | Isolasi | Isolasi |
| Sense of smell | Indera Penciuman | Indera Penciuman | Indera Penciuman |
Corona virus disease | Preventive healthcare | Kesehatan Preventif | Perawatan Kesehatan Preventif | Profilaksis (layanan Kesehatan) |
| Distance education | Pendidikan Jarak Jauh | Pendidikan Jarak Jauh | Pendidikan Jarak Jauh |
| Polymerase chain reaction | Reaksi berantai Polimerase | Reaksi berantai Polimerase | Reaksi berantai Polimerase |
| Antibody | Antibodi | Antibodi | Antibodi |
| Skin harsh | Kulit Kasar | Kulit Keras | Keras Kulit |
| Healing | Penyembuhan | Penyembuhan | Penyembuhan |
| Rapid diagnostic test | Test diagnostic cepat | Test diagnostic cepat | Uji diagnostic cepat |
| Lockdown | Kuncitara | Penguncian | Penguncian |
| Anosmia | Keadaan kekurangan penciuman | Anosmia | Anosmia muelleri |
| Virus-infectious agent | Agen infeksi virus | Agen infeksi virus | Agen infeksi virus |
After importing the data in the form of an excel worksheet, the words were then translated automatically using three machine translation tools, as shown in Table 3. The meaning of each word was not significantly different from one MT with another MT; most MT generated similar syntax in the target language. Somehow several words were rendered differently in terms of a word class. For example, ‘patient’ in English was transformed into Indonesian as ‘pasien’ by Google Translate and Systran. The word category denotes a noun category. On the other hand, Bing translated the word ‘Patient’ as ‘Sabar’, in which the word category attributes to adjectives in Indonesian. However, Bing also translates the word Pasien alternatively as Google Translate and Systran do. That transformation was not considered an error since pasien and sabar are both correct in Indonesian. In this case, Bing emphasizes the word patient more adjectival than nominal.
Another different result produced by MT was the word order in a phrase. Skin harsh, for instance, was translated uniquely by Google Translate and Bing as kulit kasar and kulit keras respectively. The difference is that the word harsh was translated into kasar and keras. The meanings of these two words in Indonesian are different although Keras and Kasar have similarities in terms of their characteristics. Both keras and kasar denote something rough if they are correlated to the word kulit (skin). Systran, otherwise, translated it as keras kulit, in which the head of the word is different from the other two. Systran produces keras as the headword which leads to a different meaning. Therefore, the word does not meet the Indonesian “grammalities."
Furthermore, Systran translated the word test in a different form, but the meaning was the same. Google Translate converted the word lockdown differently from the other two. It was transformed to Kuncitara in Indonesian, which is still not available in the Indonesian dictionary (KBBI V), while Bing and Systran translated lockdown into Indonesian as penguncian. However, neither kuncitara nor penguncian is a popular term to show the act of limiting movement of society in the Indonesian language. People in Indonesia are more familiar with the word lockdown, in this case the most common ways of solving problems caused by the absolute lexical gap is applying the loan process in translation (Raeisi, Dastjerdi and Raeisi, 2019).
Evaluation of the word level
After translating the words and phrases into Indonesian, the words were further examined to classify the word quality based on the rubric in Table 1. The quality of words was characterized as Flawless, Good, Non-native, and disfluent/incomprehensible. The following table shows the category of word-level quality.
Table 4. Evaluation of the word level
Words/phrase | Score | Category | Quality |
Covid-19 | 2 | New term | Non-native |
Vaksin | 3 | Loanword/calques | Good |
Gejala | 4 | Native | Flawless |
Pandemi | 3 | Loanword/calques | Good |
Pasien, sabar | 3 | Native | Flawless |
Virus | 3 | Loanword/calques | Good |
Vaksinasi | 3 | Loanword/calques | Good |
Gugus Tugas | 4 | Common term | Flawless |
Isolasi | 3 | Loanword/calques | Good |
Indera Penciuman | 3 | Spelling | Good |
Kesehatan Preventif | 1 | Phrase | Dis-fluent |
Pendidikan Jarak Jauh | 4 | Phrase (native) | Flawless |
Reaksi berantai Polimerase | 1 | Phrase (non-native) | Incomprehensible |
Antibodi | 3 | Loanword/calques | Good |
Kulit Kasar, keras kulit | 4 | Phrase (native) | Flawless |
Penyembuhan | 4 | Native | Flawless |
Test diagnostic cepat | 3 | New term | Good |
Kuncitara, penguncian | 4 | Native | Flawless |
Keadaan kekurangan penciuman | 4 | Native | Flawless |
Agen infeksi virus | 1 | New term | disfluent |
Based on Table 4., eight words were categorized as flawless (40%) and good (40%), three words were qualified as disfluent (15%), and only one word was classified as non-native (5%), as can be seen in Figure 1 to summarize the data.
Figure 1. Percentage the Quality of Word Level
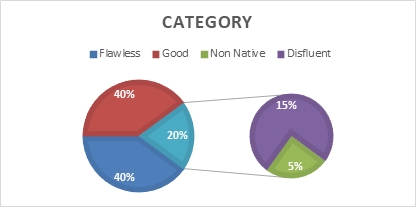
The result indicated that the accuracy of Machine Translation in configuring a source text into a target text at the word level was not the issue. Covid-19, for example, was translated in the same way as the source text, since the word arises due to a disaster setting and denotes a pronominal word. All languages around the globe will deserve it equally the same as the source text. However, Covid-19 is still not available in KBBI V (The Great Indonesian Dictionary V). Other simple phrases and words were still unavailable in KBBI V such as gugus tugas, pendidikan jarak jauh, and kuncitara. Another issue that needs to be discussed is spelling. All machine translation tools translated the phrase “a sense of smell” as indera penciuman. However, the word indera was mistakenly spelled; the word should be spelled indra according to KBBI. The phrase tes diagnosticcepat and agen infeksi virus was uncommon in the Indonesian language. Most Indonesians are familiar with the phrases rapid test rather than test diagnostic cepat and virus carrier rather than agen infeksi virus.
In this case, the authority that maintains the vocabulary database must update incoming new terms. The government also needs to release a policy to support the authority together with a linguist in developing a word-sized database (corpus).
Evaluation of the sentence level
In measuring the sentence level, the data were taken from The Coronavirus corpus available in English-Corpora. The 20 top words were selected as a lemma. They were used to search for the context of the word in the corpus. When the context was found, the authors browsed the original text and then selected one sentence for each lemma. The lemma consists of three; therefore, three sentences (S3) were retrieved from the coronavirus corpus (English-Corpora).[5] Table 5 shows the comparison of the sentence level in Three Machine Translation.
Based on the measurement rating, Google Translates rendered the three English sentences into Indonesian without any mistakes. The sentences were grammatically constructed without losing, adding, and distorting the message from the ST. The meaning could be retrieved in the fullest acceptable native language. In addition, Google Translate could justify word choice; for example, the word recommended in ST1, Google Translate produces the word merekomendasikan instead of menyarankan. The sentence was constructed in the context of academic writing. Therefore, the word merekomendasikan was more appropriate.
Bing, on the other hand, had consistently translated the two sentences with good fluency. There were some reasons; firstly, the word recommended was translated into menyarankan in ST1. It did not sound academic since the context of the sentence discussed a research situation. Secondly, inappropriate word equivalency in a phrase of ST2 occurred. The phrase “my sense of smell and taste go away” was translated as “indera penciuman dan rasanya hilang.” This Indonesian phrase could not be easily understood because the suffix -nya did not refer to a particular definite pronoun. However, the meaning conveyed in the sentence could still be understood after necessary editing. Furthermore, in ST3, Bing had successfully translated the sentence correctly to deliver meaning without distortion.
Meanwhile, Systran had an inconsistent result of measurement rating. Based on the scoring rubric, data showed that each sentence had different fluency. The ST1, for example, had been categorized as Flawless, ST2 as Non-native sentence, and ST3 categorized as Good. In ST2, Systran had yet unsuccessfully translated the phrase my sense of smell and taste go away. They were converted into saya merasakan bau dan rasa hilang that did not bring an acceptable meaning in Indonesian.
Table 5. Comparison of Machine Translation results *(ST = Source text
NO | MT/Sentence | Sentences | Fluency | |
|---|---|---|---|---|
Rater1 | Rater2 | |||
ST1* |
| We recommend that researchers conduct randomized clinical trials to prospectively evaluate the benefits of convalescent plasma in patients with blood cancer and severe COVID-19, |
|
|
| Google Translate | Kami merekomendasikan para peneliti untuk melakukan uji klinis acak untuk mengevaluasi secara prospektif manfaat plasma konvalesen pada pasien dengan kanker darah dan COVID-19 yang parah, | Flawless | Flawless |
| Bing | Kami menyarankan agar para peneliti melakukan uji klinis acak untuk secara prospektif mengevaluasi manfaat plasma konvalesen pada pasien dengan kanker darah dan COVID-19 yang parah, | Good | Good |
| Systran | Kami merekomendasikan para peneliti untuk melakukan uji klinis acak untuk mengevaluasi secara prospektif manfaat plasma konvalesen pada pasien dengan kanker darah dan COVID-19 yang parah | Flawless | Flawless |
ST2 | English sentence | I wake up in the morning, I don't feel very well, my sense of smell and taste go away, I get a sore throat, " Dr. Fauci said in an interview. |
|
|
| Google Translate | Saya bangun di pagi hari, saya merasa tidak enak badan, indera penciuman dan perasa saya hilang, saya sakit tenggorokan, "kata Dr Fauci dalam sebuah wawancara. | Flawless | Flawless |
| Bing | Saya bangun di pagi hari, saya merasa tidak enak badan, indera penciuman dan rasanya hilang, saya sakit tenggorokan, " kata Dr. Fauci dalam sebuah wawancara | Good | Good |
| Systran | Saya bangun pagi, saya tidak merasa sehat, saya merasakan bau dan rasa hilang, saya sakit tenggorokan," kata Dr. Fauci dalam wawancara | Non-Native | Non-native |
ST3 | English sentence | Most people infected with the COVID-19 virus will experience mild to moderate respiratory illness and recover without special treatment. |
|
|
| Google Translate | Sebagian besar orang yang terinfeksi virus COVID-19 akan mengalami penyakit pernapasan ringan hingga sedang dan sembuh tanpa memerlukan perawatan khusus. | Flawless | Flawless |
| Bing | Kebanyakan orang yang terinfeksi virus COVID-19 akan mengalami penyakit pernapasan ringan hingga sedang dan pulih tanpa memerlukan perawatan khusus. | Flawless | Flawless |
| Systran | Kebanyakan orang yang terjangkit virus COVID-19 akan mengalami penyakit pernapasan ringan hingga moderat dan pulih tanpa memerlukan perawatan khususs | Good | Good |
Even though readers could still grasp the meaning, they still need effort to understand the texts. Additionally, compared to the two other MTs, Systran still required improvement when translating ST3; the issue was word choice; the word moderate was translated into moderate instead of sedang. The word sedang was more appropriate to make the flow of the word sound more natural in Indonesian.
Figure 2. Lemma from Coronavirus Corpus
Category of the paragraph level
In assessing the Machine Translation at the paragraph level, the authors took the context of a lemma from the Coronavirus Corpus as shown in Figure 2. Each lemma linked to the web page provided in the corpus to capture the context from the text. The text is taken from the websites Centers for Disease Control and Prevention (English-Corpora).[6]
Table 6. Sample Paragraph


They were translated using Machine Translations to compare the result of its translation. Table 6 shows the fluency of paragraphs in each machine translation.
The finding reveals that the three Machine Translations translated the languages correctly. They perform good fluency that make readers understand the text easily. However, there is an issue with the translation of the subject pronoun "they" in that paragraph. Indonesians are not familiar with using "mereka" to refer to an inanimate subject. The example is shown in the sentences below.
Table 7. Sample Lexical Cohesion Issue
ST | These side effects may affect their ability to do daily activities, but they should goaway in a few days. |
Google, Bing, Systran | Efek samping ini dapat mempengaruhi kemampuan mereka untuk melakukan aktivitas sehari-hari, tetapi mereka akan (hilang, pergi, tersingkir) dalam beberapa hari. |
Suggested Translation | Efek samping ini dapat mempengaruhi kemampuan anak-anak dalam melakukan aktivitas sehari-hari, tetapi seharusnya efek samping vaksin tersebut akan hilang dalam beberapa hari. |
Based on the example above, several questions arise. We can see that the pronoun can be a problem for machine translation that may affect paragraph cohesion. It is crucial to ensure the words and sentences stick together that make the message of the paragraph more succinct and easier to read. Therefore, the above example suggests that the possessive object pronoun ‘their’ is recommended to be translated as anak-anak (Children). It is intended to avoid confusion which context the pronoun refer to, since the two words denote a pronoun and a noun in the previous sentence; denoting an animate subject (Children) and an inanimate object (side effects). Both of them are also plural forms. In addition, the word they in the second clause should be translated as efek sampingvaksin (side effect) instead of mereka. It is uncommon in Indonesian when the subject pronoun they is used to denote an inanimate subject/object.
Adding further analysis, the machine translation converted the phrase go away in a different variant in Indonesian. Google Translate transformed it as hilang, while Bing renders the word as pergi, and Systran translated it as tersingkir. The most acceptable meaning in that context is the translation produced by Google Translate. However, the translation generated by Bing and Systran can still be understood. Another unique word that brings a different meaning contextually was the translation of the word get as shown in the following clause:
Your child cannot get COVID-19 from any COVID-19 vaccine.
The word get was translated as tertular (get infected) by Goole Translate. Bing and Systran, otherwise, translated it respectively as mendapatkan (get) and memperoleh (get), which raise confusion for Indonesians. Besides that, the last two words were considered uncommon if translated from the context of the sentence. For this reason, the paragraph translated by Machine translation was qualified as Good. Even though Google Translate performed better than the other two, it is still categorized as Good since the lexical cohesion, such as noun, pronoun and verb phrase, remain problematic.
Concerning the Covid-19 pandemic, this corona crisis accelerated the need for linguists and language authorities worldwide to accommodate multilingualism and multiculturalism. As can be seen in the word-level quality, almost all medical terms are borrowed or calqued in the target language. In terms of the acceptability of meaning in the target language, those words were accepted. However, people who might not be familiar with them would remain confused.
Among other valuable points, this present study deserves several limitations that can be improved in future studies. Firstly, insufficient elaboration toward the finding. The authors focus mainly on words, sentences, and the paragraph level dealing with Covid-19 diseases. Future studies can add one more category, such as text or discourse in various genres. Secondly, this study used only one technique in evaluating translation products, and future research can triangulate the evaluation by using automatic assessment besides human evaluation. Thirdly, the sample size is minimal; future research can gain more data, such as providing larger word sizes, more sentences, and paragraphs to provide credibility and dependability.
Conclusion
This present study portrayed the quality of target language translated by machine translation tools and gave several issues to research in the future. This research has helped pave the way for researchers and translation companies to improve machine translation development. New terms related to Covid-19 diseases have been investigated. Google Translate, Bing and Systrans were presumably seen as alternative ways of translating terms corresponding to the Covid-19 disease. However, machine translation remains problematic in denoting nouns or pronouns. On the other hand, KBBI's database needs to be updated to provide more incoming new terms explicitly dealing with a crisis such as the Covid-19 diseases. In this case, the bodies involved in the creation of the dictionary databases need special assistance from the Indonesian government to support and overcome this potential problem.












Reference lists
Asscher, O. and Glikson, E. (2021). Human evaluations of machine translation in an ethically charged situation, New Media and Society, available at: https://doi.org/10.1177/14614448211018833 (Accessed 6 July 2021). (In English)
Bowker, L. and Buitrago Ciro L. (2019). Machine Translation and Global Research: Towards Improved Machine Translation Literacy in the Scholarly Community, Emerald Publishing, Bingley, UK. (In English)
CDC (2021). Safety of Covid-19 Vaccines, available at: https://www.cdc.gov/coronavirus/2019-ncov/vaccines/safety/safety-of-vaccines.html (Accessed 9 July 2021). (In English)
Chon, Y. v., Shin D. and Kim G. E. (2021). Comparing L2 Learners’ Writing against Parallel Machine-Translated Texts: Raters’ Assessment, Linguistic Complexity and Errors. System, 96. https://doi.org/10.1016/j.system.2020.102408 (In English)
Das, P., Kuznetsova, A., Zhu, M. and Milanaik, R. (2018). Dangers of Machine Translation: The Need for Professionally Translated Anticipatory Guidance Resources for Limited English Proficiency Caregivers, Clinical Pediatrics, 58, 2, 247-249. https://doi.org/10.1177/0009922818809494 (In English)
Dew, K. N., Turner, A. M., Choi, Y. K., Bosold, A. and Kirchhoff, K. (2018). Development of machine translation technology for assisting health communication: A systematic review, Journal of Biomedical Informatics, 85, 56-67. https://doi.org/10.1016/j.jbi.2018.07.018 (In English)
Dreisbach, J. L. and Mendoza-Dreisbach, S. (2021). Unity in Adversity: Multilingual Crisis Translation and Emergency Linguistics in the COVID-19 Pandemic, The Open Public Health Journal, 14, 1, 94–97. http//doi.10.2174/1874944502114010094 (In English)
EMEA (2021). The European Medicines Agency, available at: https://opus.nlpl.eu/EMEA.php (Accessed 9 July 2021). (In English)
English-Corpora (2021). The Coronavirus Corpus, available at: https://www.english-corpora.org/corona/ (Accessed 9 July 2021). (In English)
Federici, F., O’Hagan, M., O’Brien, S. and Cadwell, P. (2019). Crisis Translation Training Challenges Arising from New Contexts of Translation, Cultus, 12, 246-279, available at: https://discovery.ucl.ac.uk/id/eprint/10085446/ (Accessed 9 July 2021). (In English)
Guzmán, F., Joty, S., Màrquez, L. and Nakov, P. (2017). Machine translation evaluation with neural networks, Computer Speech and Language, 45, 180-200, available at https://arxiv.org/abs/1710.02095 (Accessed 10 July 2021). (In English)
Koehn, P. (2010). Statistical Machine Translation, Cambridge University Press, Cambridge, UK. (In English)
Koehn, P. and Knowles, R. (2017). Six Challenges for Neural Machine Translation. Proceedings of the First Workshop on Neural Machine Translation, 28-39. http://doi.10.18653/v1/W17-3204 (In English)
Li, J., Xie, P., Ai, B. and Li, L. (2020). Multilingual communication experiences of international students during the COVID-19 Pandemic, Multilingua, 39, 5, 529-539 https://doi.org/10.1515/multi-2020-0116 (In English)
Maurya, K. K., Ravindran, R. P., Anirudh, C. R. and Murthy, K. N. (2020). Machine Translation Evaluation: Manual Versus Automatic – A Comparative Study, Advances in Intelligent Systems and Computing, 1079, 541–553. https://doi.org/10.1007/978-981-15-1097-7_45 (In English)
O’Brien, S. and Federici, F. M. (2019). Crisis translation: considering language needs in multilingual disaster settings, Disaster Prevention and Management: An International Journal, 29, 2, 129-143. https://doi.org/10.1108/DPM-11-2018-0373 (In English)
Raeisi, M., Dastjerdi, H. V. and Raeisi, M. (2019). Strategies used in the translation of scientific texts to fill the lexical gap, Research Result. Theoretical and Applied Linguistics, 5, 3, 116-123. (In English)
Saldanha, G. and O’Brien, S. (2014). Research Methodologies in Translation Studies, Routledge, New York, US. (In English)
Samir, A.-Y. M. (2020). Translation Quality Assessment Rubric: A Rasch Model-Based Validation, International Journal of Language Testing, 10, 2,101-128. (In English)
Sketch Engine (2021). Sketch Engine: Learn How Language Works, available at: https://www.sketchengine.eu (Accessed 9 July 2021). (In English)
Stankevičiūtė, G., Kasperė, R. and Horbačauskienė, J. (2017). Issues in Machine Translation, International Journal on Language, Literature and Culture in Education, 4, 1, 75-88. (In English)
TAUS and Systran (2021). Powering Automated Translation in Time of Corona Crisis, available at: https://www.systransoft.com/systran/news-and-events/specialized-corona-crisis-corpus-models/ (Accessed 9 July 2021). (In English)
Vieira, L. N., O’Hagan, M. and O’Sullivan, C. (2020). Understanding the societal impacts of machine translation: a critical review of the literature on medical and legal use cases, Information, Communication and Society, 24, 11, 1515-1532. https://doi.org/10.1080/1369118X.2020.1776370 (In English)
Williams, J. and Chesterman, A. (2011). The Map: A Beginer’s Guide to Doing Research in Translation, Routledge Taylor and Francis, Group London, UK. (In English)